混沌工程与落地实践
1. 混沌产生
1.1 混沌学科的产生
在讲混沌之前,我们可以先思考一下混沌、混沌工程和我们线上服务之间的关联。
我们经常听到的故事是,一只在亚马逊河流中的蝴蝶,煽动了几下翅膀,就能在美国引起一场龙卷风。这个故事背后隐藏着一个重要的学科,那就混沌。
早在 20 世纪 60 年代,洛伦兹就发现了混沌现象。他是一个数学家,但是从事气象学研究,使用数学模型研究天气时发现,初始值的微小变化,会导致结果的巨大差异。对初值极其敏感,是判断为混沌状态的重要特征。之后,又经过十几年的发展和研究,才将初值敏感的特征命名为蝴蝶效应,被人们所熟知。
1.2 混沌工程的产生
而我们谈的混沌工程,实际上指的是来自 2008 年 Netflix 的工程实践。
在 Netflix 上云的过程中,他们发现了一个问题,上云之后,服务的稳定性会下降。原因在于,网络、机器、存储等,都是不可控的。
因此,他们开发了一个工具,叫做 Chaos Monkey,主动破坏云服务,来发现系统的弱点,从而提高系统的稳定性。
目前,这是一个上万 star 的开源项目, https://github.com/Netflix/chaosmonkey 。
犹如一只进入了数据中心的猴子,他会随机破坏系统,你会发现系统的脆弱点,也会从故障中学习到处理经验。
1.3 微服务与混沌的关系
目前互联网应用以微服务为主,微服务的特点是,服务之间的依赖关系非常复杂。那么,微服务具不具备混沌的特征呢?
以下是我总结的异同点。
相同点:
- 复杂非线性连接
- 敏感依赖性,一个微服务的变化会影响关联的其他微服务,与混沌敏感依赖初始条件类似
- 可能产生巨大的累计误差,与蝴蝶效应类似
不同点: - 不确定性,微服务 < 典型混沌系统
- 微服务强调独立性,而混沌系统强调互相依赖
计算机系统是确定性的系统,程序代码是提前编写好的,运行结果是有预期的。但现实中,计算机系统真的是确定的吗?不是的,磁盘损坏、内存位翻转、网络中断,程序运行的物理世界是不确定的。此外,微服务的资源并不是独占的,高密度的部署下,CPU、内存、网络等资源都是共享的,服务与服务之间也是相互影响的。这里将其统称为程序运行的环境因素。
从计算机系统 + 环境的角度看,我们的线上系统、微服务程序具备混沌的特征。
2. 混沌工程-提供技术手段
2.1 进行混沌工程实验的必要性
我们所处的基础设施环境、软件架构越来越复杂,故障已经不可避免。从经典的架构看,IaaS 层可能会有服务宕机、网络抖动;PaaS 层可能会有数据库宕机、负载不均、CPU 抢占;SaaS 层可能会遇到 OOM、CPU 限流、连不上数据库等故障。
实际上,复杂度已经远超个人能够全盘掌控的程度。我们与其等待故障,不如主动出击去制造故障。
"我怀疑是 CPU 不够"、"我怀疑是网络有问题"、 "我怀疑连不上数据库"、”我怀疑....“
当我们怀疑某个不确定性因素的时候,不用仅仅停留在猜想阶段,而是需要一次混沌工程实验。
2.2 平台集成的混沌功能
主要分为两个部分:
- chaos-agent
通用基础设施的故障注入,场景非常通用,因此,我选择了从 chaos-mesh 中剥离的故障探针。这样在 IaaS、K8s 层面的故障注入,都可以直接使用,而对于自身业务特性的,比如内部 DB PaaS 的故障注入、IDC 专线的故障注入,需要自行开发探针。 - chaos-controller-mgr
自研基于 K8s 的 Operator,定义了两个对象 Network 和 Stress,提供三种故障注入能力。没有直接使用 chaos-mesh 的控制平面有两点考虑,一个是风险控制,chaos-mesh 的控制器需要处理太多注入类型,避免使用不当导致事故;另一个是为了便于与自研的探针相结合,使用一个控制平面就能够统一基础与业务的故障注入。
2.3 功能介绍
目前已经在测试集群部署,提供了三种故障注入能力。
- CPU 加压
- 网络丢包
- 网络断网
2.4 注入原理
控制平面的工作流:
- 提交故障注入请求
- controller 处理请求,找到 Pod 所在的节点的 agent 调用 RPC
- agent 找到容器所在的空间,在节点上写入故障
- 定时时间到或暂停注入,清理故障
注入原理:
CPU - Stress 命令进入进程空间注入 网络 - Iptables、IpSet 命令劫持网络空间流量,通过 TC 控制。
3. 混沌工程的时间-价值在哪里
3.1 能带来的收益
混沌工程能够揭露生产系统中未知的缺陷,提高系统的稳定性。
这里需要明确的一点是,如果已经确定混沌实验会出现问题,说明现有的系统并没有任何容错或者应对机制,那么这种实验也就没有任何意义。
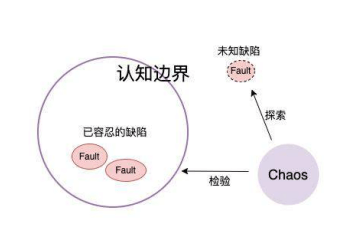
如果基于认知边界进行划分,可以将缺陷分为两类:
- 已知缺陷,包括已经容忍的、已知但未修复的缺陷,比如单点、网络抖动等
- 未知缺陷,包括未知的、有认知偏差的缺陷,比如潜在的 Bug、自认为而与事实不符的缺陷等
对于认知边界内的缺陷,使用混沌实验,可以用于复现缺陷、辅助修复缺陷、检验缺陷得到修复。
对于认知边界外的缺陷,使用混沌实验,是探索性的。我们通过混沌实验,可以发现一些被忽略、被遗漏的缺陷。
3.2 混沌工程实施的步骤
为了方便大家去落地与具体操作,这里给出一个简单的实施步骤。
- 定义稳态指标吞吐量、错误率、延时百分位等
- 期望假设按照相关人员对系统的认知,评估表现
- 执行混沌实验通过一定的手段,将故障注入系统
- 观察稳态指标是否符合预期,记录数据
- 恢复实验,总结恢复现场,修复发现的问题,继续实验
在这个基础上,我们在每次实施混沌实验时,都会有个规范。理想情况下,应该是混沌平台提供这样的能力,让大家能够管理故障、记录现象、制定应对策略、复盘总结等,辅助整个混沌工程实验的生命周期。
但目前内部还没有开发这样的平台,因此强烈建议大家先按照这个流程用文档的形式先记录下来,后续再整理到平台上。
3.3 成熟度模型 CEMM
对于混沌工程和稳定性,信通院有提出一个标准 CEMM,对标 3 级来建设我们的混沌工程平台。简单说几点:
混沌实验的结果能够反馈应用的健康状况指标。这就要求,我们要将混沌工程实验融入到应用的生命周期中,建立评价机制。让应用必须经过混沌工程实验的检验才能上线。
自助式创建实验,自动运行实验。其实我们已经达到要求。但目前的实验形式比较简陋,缺乏对完整实验过程的管理。
可通过实验工具持续收集实验结果,但需要人工分析和解读。在我开发混沌注入的功能之前,我们就在人工的进行各种混沌工程实验,但缺少自动化和工具的支持。经过经验的积累,下一步,强烈建议加强工具的支持,故障注入工具、指标收集工具、结果分析工具、异常处理工具、故障恢复工具等。
3.4 应用的韧性
在研究各种混沌工程实践时,我还接触到一个有意思的概念,应用的韧性。

刚接触到这个概念时,总感觉很熟悉,但又很难说清楚。因此,我想了一个形象的比喻,如上图的不倒翁,应用可以左摇右摆,但是依然能保持平衡。这就要求,应用能够应对各种不稳定、不确定性、突发的状况时,能够自愈。经过短暂地波动之后,能够迅速地恢复平衡状态。
对应用不倒翁的定位,需要做以下的设计:
- 冗余设计
重要的中间件,两地三中心,允许其中至少一个断连 - 过载保护
当请求激增时,能够采用限流、拒绝服务等措施保护整体不受损 - 服务降级能力
在服务能力不够的情况下,能有有所取舍,保障重点服务不受影响 - 去中心化设计
不允许出现中心化的节点
这些具体的要求,对于我们的业务应用是有落地路径的。我们可以按照这个要求,去评估并改造我们的应用。
4. 后续计划-落地携手共建
- 建立应用质量标准并达成共识
我们对异常要有感知能力。能感知,才能应对,以及后续进行更多的动作。如果应用异常了,都没人关注,肯定是不行的。
除了感知异常,还要能容忍一定的异常。应用不应该一丢包就 Crash 掉,应该具有一定的容错能力。
- 常态化探索性的混沌工程实验
在前段时间,我们已经在测试集群,进行了持续的随机混沌工程实验。随机抽取应用,随机选择故障注入类型、故障注入参数,发现了不少问题。
- 平台与业务共建韧性改造方案
混沌工程平台侧希望能够持续的跟进一些应用韧性改造的 Case,将其作为经典案例,予以推广。这些沉淀下来的方案,就是适合我们当前基础设施、业务形态对于韧性改造的最佳实践。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞1
添加新评论0 条评论