
Linux 虚拟内存参数配置
一、 问题出发点:
Jun 1 10:30:21 audit1 kernel: swapper: page allocation failure. order:1, mode:0x20
Jun 1 10:30:21 audit1 kernel: Pid: 0, comm: swapper Tainted: G --------------- T 2.6.32-431.20.3.el6.x86_64 #1
Jun 1 10:30:21 audit1 kernel: Call Trace:
Jun 1 10:30:21 audit1 kernel: <IRQ> [<ffffffff8112f80a>] ? __alloc_pages_nodemask+0x74a/0x8d0
Jun 1 10:30:21 audit1 kernel: [<ffffffff8116e242>] ? kmem_getpages+0x62/0x170
Jun 1 10:30:21 audit1 kernel: [<ffffffff8116ee5a>] ? fallback_alloc+0x1ba/0x270
Jun 1 10:30:21 audit1 kernel: [<ffffffff8116ebd9>] ? ____cache_alloc_node+0x99/0x160
Jun 1 10:30:21 audit1 kernel: [<ffffffff8116fb5b>] ? kmem_cache_alloc+0x11b/0x190
Jun 1 10:30:21 audit1 kernel: [<ffffffff8144cde8>] ? sk_prot_alloc+0x48/0x1c0
Jun 1 10:30:21 audit1 kernel: [<ffffffff8144dff2>] ? sk_clone+0x22/0x2e0
Jun 1 10:30:21 audit1 kernel: [<ffffffff8149f9c6>] ? inet_csk_clone+0x16/0xd0
Jun 1 10:30:21 audit1 kernel: [<ffffffff814b9293>] ? tcp_create_openreq_child+0x23/0x470在监控中,发现messages日志中出现failure报错信息,发现如上内存堆栈报错。
二、 虚拟内存介绍:
1.虚拟内存
毋庸置疑,虚拟内存绝对是操作系统中最重要的概念之一。我想主要是由于内存的重要“战略地位”。CPU太快,但容量小且功能单一,其他 I/O 硬件支持各种花式功能,可是相对于 CPU,它们又太慢。于是它们之间就需要一种润滑剂来作为缓冲,这就是内存大显身手的地方。
而在现代操作系统中,多任务已是标配。多任务并行,大大提升了CPU 利用率,但却引出了多个进程对内存操作的冲突问题,虚拟内存概念的提出就是为了解决这个问题。
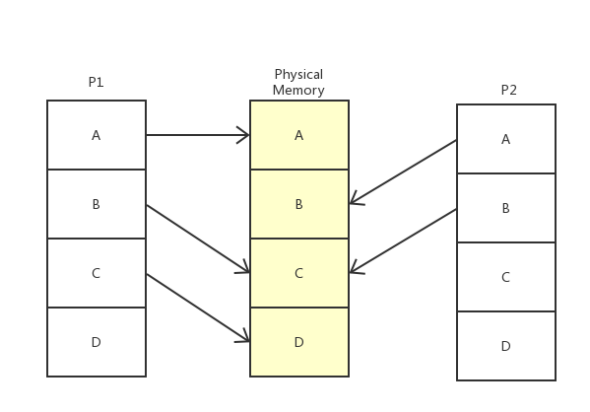
上图是虚拟内存最简单也是最直观的解释。
操作系统有一块物理内存(中间的部分),有两个进程(实际会更多)P1 和 P2,操作系统偷偷地分别告诉 P1 和 P2,我的整个内存都是你的,随便用,管够。可事实上呢,操作系统只是给它们画了个大饼,这些内存说是都给了 P1 和 P2,实际上只给了它们一个序号而已。只有当 P1 和 P2 真正开始使用这些内存时,系统才开始使用辗转挪移,拼凑出各个块给进程用,P2 以为自己在用 A 内存,实际上已经被系统悄悄重定向到真正的 B 去了,甚至,当 P1 和 P2 共用了 C 内存,他们也不知道。
操作系统的这种欺骗进程的手段,就是虚拟内存。对P1 和 P2 等进程来说,它们都以为自己占用了整个内存,而自己使用的物理内存的哪段地址,它们并不知道也无需关心。
2.分页和页表
虚拟内存是操作系统里的概念,对操作系统来说,虚拟内存就是一张张的对照表,P1 获取 A 内存里的数据时应该去物理内存的 A 地址找,而找 B 内存里的数据应该去物理内存的 C 地址。
我们知道系统里的基本单位都是Byte 字节,如果将每一个虚拟内存的 Byte 都对应到物理内存的地址,每个条目最少需要 8字节(32位虚拟地址->32位物理地址),在 4G 内存的情况下,就需要 32GB 的空间来存放对照表,那么这张表就大得真正的物理地址也放不下了,于是操作系统引入了 页(Page)的概念。
在系统启动时,操作系统将整个物理内存以4K 为单位,划分为各个页。之后进行内存分配时,都以页为单位,那么虚拟内存页对应物理内存页的映射表就大大减小了,4G 内存,只需要 8M 的映射表即可,一些进程没有使用到的虚拟内存,也并不需要保存映射关系,而且Linux 还为大内存设计了多级页表,可以进一页减少了内存消耗。操作系统虚拟内存到物理内存的映射表,就被称为页表。
3.内存寻址和分配
我们知道通过虚拟内存机制,每个进程都以为自己占用了全部内存,进程访问内存时,操作系统都会把进程提供的虚拟内存地址转换为物理地址,再去对应的物理地址上获取数据。CPU 中有一种硬件,内存管理单元 MMU(Memory Management Unit)专门用来将翻译虚拟内存地址。CPU 还为页表寻址设置了缓存策略,由于程序的局部性,其缓存命中率能达到 98%。
以上情况是页表内存在虚拟地址到物理地址的映射,而如果进程访问的物理地址还没有被分配,系统则会产生一个缺页中断,在中断处理时,系统切到内核态为进程虚拟地址分配物理地址。
4.zone
内存管理的相关逻辑都是以zone为单位的,这里zone的含义是指内存的分区管理。Linux将内存分成多个区,主要有直接访问区(DMA)、一般区(Normal)和高端内存区(HighMemory)。内核对内存不同区域的访问因为硬件结构因素会有寻址和效率上的差别。如果在NUMA架构上,不同CPU所管理的内存也是不同的zone。
5.NUMA
NUMA中,虽然内存直接访问在CPU上,但是由于内存被平均分配在了各个CPU上。只有当CPU访问自身直接访问内存对应的物理地址时,才会有较短的响应时间(后称Local Access)。而如果需要访问其他CPU attach的内存的数据时,就需要通过互联通道访问,响应时间就相比之前变慢了(后称Remote Access)。所以NUMA(Non-Uniform Memory Access)就此得名。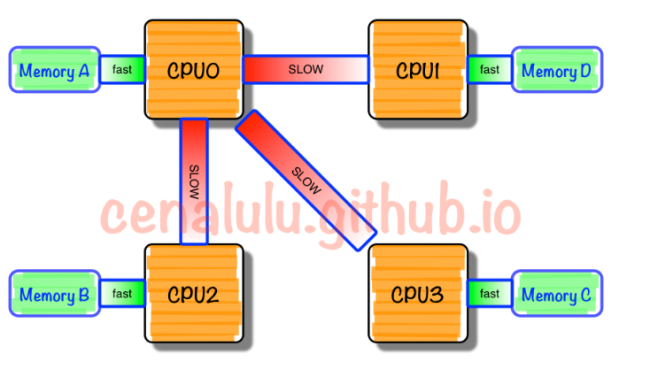
三、分析:
1.红帽官方解释(Root Cause):
在RHEL 6.4之前,kswapd不会尝试释放连续页面。当系统中没有其他碎片整理内存时,这可能导致GFP_ATOMIC分配请求反复失败。 使用RHEL 6.4和更高版本时,如果需要,kswapd将压缩(碎片整理)可用内存。
请注意,分配失败仍然可能发生。例如,当出现较大的GFP_ATOMIC分配突发时,kswapd可能难以跟上。 但是,这些分配最终应该会成功。
2.红旗邮件回复:
建议设置如下内核参数:
1、vm.min_free_kbytes
系统默认:
[root@localhost ~]# cat /proc/sys/vm/min_free_kbytes
45056
[root@node1 log]# sysctl -a |grep vm.min
vm.min_free_kbytes = 45056
建议设置为:
vm.min_free_kbytes = 450560
即增大该值的设置。
2、vm.zone_reclaim_mode
系统默认为0:
[root@localhost ~]# sysctl -a |grep vm.zone_reclaim_mode vm.zone_reclaim_mode = 0
建议设置vm.zone_reclaim_mode = 1到/etc/sysctl.conf文件。
具体如下:
#vim /etc/sysctl.conf #打开该文件,追加或修改为如下设置(其他参数不变);
vm.min_free_kbytes = 450560
vm.zone_reclaim_mode = 1
设置之后,保存退出。
写入到该文件中的参数,执行sysctl -p可即时生效。 下次重启将读取该文件的设置。3. Virtual Memory相关参数介绍:
3.1.vm.swappiness
控制换出运行时内存的相对权重。swappiness参数值可设置范围在0到100之间。低参数值会让内核尽量少用交换,更高参数值会使内核更多的去使用交换空间。默认值为60(参考网络资料:当剩余物理内存低于40%(40=100-60)时,开始使用交换空间)。对于大多数操作系统,设置为100可能会影响整体性能,而设置为更低值(甚至为0)则可能减少响应延迟。
swappiness的值的大小对如何使用swap分区是有着很大的联系的。先前,人们建议把vm.swapiness设置为0,它意味着“除非发生内存益处,否则不要进行内存交换”。直到Linux内核3.5-rcl版本发布,这个值的意义才发生了变化。这个变化被一直到其他的发行版本上,包括RedHat企业版内核2.6.32-303。在发生变化之后,0意味着“在任何情况下都不要发生交换”。所以现在建议把这个值设置为1。swappiness=100的时候表示积极的使用swap分区,并且把内存上的数据及时的搬运到swap空间里面。
推荐值:vm.swappiness = 10
3.2.vm.min_free_kbytes
用于强制Linux VM保留最小数量的千字节。VM使用该数字为系统中的每个低内存区域计算水位线[WMARK_MIN]值。 每个lowmem区域根据其大小成比例地获得许多保留的空闲页面。需要一些最小的内存来满足PF_MEMALLOC分配; 如果将此值设置为小于1024KB,则系统将被破坏,并在高负载下易于死锁。设置得太高将立即使您的机器OOM。
这个参数本身决定了系统中每个zone的watermark[min]的值大小,然后内核根据min的大小并参考每个zone的内存大小分别算出每个zone的low水位和high水位值。
从上面的解释中主要有如下两个点:
1.代表系统所保留空闲内存的最低限
2.用于计算影响内存回收的三个参数watermark[min/low/high]
用于计算影响内存回收的三个参数: watermark[min/low/high]
在系统空闲内存低于 watermark[low] 时,开始启动内核线程 kswapd 进行内存回收,直到该 zone 的空闲内存数量达到 watermark[high] 后停止回收。
如果上层申请内存的速度太快,导致空闲内存降至 watermark[min] 后,内核就会进行 direct reclaim (直接回收),即直接在应用程序的进程上下文中进行回收,再用回收上来的空闲页满足内存申请,因此实际会阻塞应用程序,带来一定的响应延迟,而且可能会触发系统 OOM 。这是因为 watermark[min] 以下的内存属于系统的自留内存,用以满足特殊使用,所以不会给用户态的普通申请来用。
三个watermark的计算方法:
watermark[min] = min_free_kbytes换算为 page 单位即可,假设为 min_free_pages 。
watermark[low] = watermark[min] * 5/4
watermark[high] = watermark[min] * 3/2Defines a percentage value. Writeout of dirty data begins in the background (via pdflush) when dirty data comprises this percentage of total memory. The default value is 10. For database workloads, Red Hat recommends a lower value of 3.
Setting min_free_kbytes too high will cause system hangs,especially in i386 arch, using less than 5% of total memory can avoid it, so choose %5 of free memory or 2% of total memory.
推荐值:vm.min_free_kbytes = <内存值>*2% (上限5G)
3.3.vm.zone_reclaim_mode
zone_reclaim_mode模式是在2.6版本后期开始加入内核的一种模式,可以用来管理当一个内存区域(zone)内部的内存耗尽时, 是从其内部进行内存回收还是可以从其他zone进行回收的选项。
在申请内存时,内核在当前zone内没有足够内存可用的情况下,会根据zone_reclaim_mode的设置来决策是从下一个zone找空闲内存还是在zone内部进行回收。
这个值为0时表示可以从下一个zone找可用内存,非0表示在本地回收。
默认情况下,zone_reclaim模式是关闭的。这在很多应用场景下可以提高效率,比如文件服务器,或者依赖内存中cache比较多的应用场景。
如果确定应用场景是内存需求大于缓存,而且尽量要避免内存访问跨越NUMA节点造成的性能下降的话,则可以打开zone_reclaim模式。
此时页分配器会优先回收容易回收的可回收内存(主要是当前不用的page cache页),然后再回收其他内存。
(如果读写量很大,则应该关闭,命中率较低,因为缓存意义不大。
目前mongoDB的官方文档推荐,是关闭NUMA,关闭vm.zone_reclaim_mode。)
打开本地回收模式的写回可能会引发其他内存节点上的大量的脏数据写回处理。( 首次打开,会引发脏数据写回,该操作时间和应用协商好,建议重启服务 );
如果一个内存zone已经满了,那么脏数据的写回也会导致进程处理速度收到影响,产生处理瓶颈。(进程所在CPU可用的内存减少,直接导致脏数据写回的频率提高了,写回产生的影响也就增加了,cache写回对cache的读写性能一定有短暂的影响)
这会降低某个内存节点相关的进程的性能,因为进程不再能够使用其他节点上的内存。但是会增加节点之间的隔离性,其他节点的相关进程运行将不会因为另一个节点上的内存回收导致性能下降。
推荐值:vm.zone_reclaim_mode = 1
(在内存分配不足,且内存需求较多,建议关闭,加速cache回收!)
3.4.vm.dirty_ratio
是可以用脏数据填充的绝对最大系统内存量,用占系统 空闲内存 的百分比来表示,当系统到达此点时,必须将所有脏数据提交到磁盘,同时所有新的I/O块都会被阻塞,直到脏数据被写入磁盘。
这通常是长I/O卡顿的原因,但这也是保证内存中不会存在过量脏数据的保护机制。
表示当写缓冲使用到系统内存多少的时候,开始向磁盘写出数据。增大只会使用更多系统内存用于磁盘写缓冲,可以极大提高系统的写性能。但是,当你需要持续、恒定的写入场合时,应该降低其数值。
推荐值:vm.dirty_ratio = 30 (保持默认)
3.5.vm.dirty_background_ratio
内存脏数据开始写回的上限。用占系统 空闲内存 的百分比来表示,这些脏数据稍后会写入磁盘,pdflush/flush/kdmflush这些后台进程会稍后清理脏数据。
控制文件系统的pdflush进程,在何时刷新磁盘,以脏数据是否达到占系统 空闲 内存的百分比,pdflush开始将内存中的内容和文件系统进行同步。比如说,当一个文件在内存中进行修改,pdflush负责将它写回硬盘.每当内存中的垃圾页(dirty page)超过10%的时候,pdflush就会将这些页面备份回硬盘.增大之会使用更多系统内存用于磁盘写缓冲,也可以极大提高系统的写性能。但是,当你需要持续、恒定的写入场合时,应该降低其数值:
推荐值:vm.dirty_background_ratio = 10
情景1:减少Cache
你可以针对要做的事情,来制定一个合适的值。
在一些情况下,我们有快速的磁盘子系统,它们有自带的带备用电池的NVRAM caches,这时候把数据放在操作系统层面就显得相对高风险了。所以我们希望系统更及时地往磁盘写数据。
可以在/etc/sysctl.conf中加入下面两行,并执行"sysctl -p"
vm.dirty_background_ratio = 5
vm.dirty_ratio = 10
这是虚拟机的典型应用。不建议将它设置成0,毕竟有点后台IO可以提升一些程序的性能。情景2:增加Cache
在一些场景中增加Cache是有好处的。例如,数据不重要丢了也没关系,而且有程序重复地读写一个文件。允许更多的cache,你可以更多地在内存上进行读写,提高速度。
vm.dirty_background_ratio = 50
vm.dirty_ratio = 80
有时候还会提高vm.dirty_expire_centisecs 这个参数的值,来允许脏数据更长时间地停留。情景3:增减兼有
有时候系统需要应对突如其来的高峰数据,它可能会拖慢磁盘。(比如说,每个小时开始时进行的批量操作等)
这个时候需要容许更多的脏数据存到内存,让后台进程慢慢地通过异步方式将数据写到磁盘当中。
vm.dirty_background_ratio = 5
vm.dirty_ratio = 80
这个时候,后台进行在脏数据达到5%时就开始异步清理,但在80%之前系统不会强制同步写磁盘。这样可以使IO变得更加平滑。
从/proc/vmstat, /proc/meminfo, /proc/sys/vm中可以获得更多资讯来作出调整。
四、参考文献:
红帽官网:
CONFIGURING SYSTEM MEMORY CAPACITY
https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/7/html/performance_tuning_guide/sect-red_hat_enterprise_linux-performance_tuning_guide-configuration_tools-configuring_system_memory_capacity#sect-Red_Hat_Enterprise_Linux-Performance_Tuning_Guide-Configuring_system_memory_capacity-Virtual_Memory_parameters
Aerospike_Knowledge:
How to tune the Linux kernel for memory performance
https://discuss.aerospike.com/t/how-to-tune-the-linux-kernel-for-memory-performance/4195
红帽官网:
Several "page allocation failure. order:1, mode:0x20" messages are seen on the console after upgrade to Red Hat Enterprise Linux 6.2
https://access.redhat.com/solutions/90883?spm=a2c4e.10696291.0.0.65ee19a4TLMVIV
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞7
添加新评论0 条评论