布隆过滤器(Bloom Filter)原理和应用浅说(二)
接上篇
布隆过滤器的应用
从上面讨论可知,布隆过滤器一般用于在允许一定误判率条件下,在一个大数据量的集合中判定某元素是否存在。典型如网页 URL 去重、垃圾邮件识别、缓存穿透等问题。布隆过滤器可以与一些 key-value 的数据库一起使用,来加快查询。 key-value 存储系统的 value 存储在硬盘,查询非常耗时。此时,就可以将 key 值映射到布隆过滤器上,对于一个 key-value 查询请求,如果在布隆过滤器中查询不存在时,那就不需要去 Storage 查询了。如果查询存在,只是会导致一次多余的 Storage 查询。
由于布隆过滤器所用的空间非常小,所以它可以常驻内存。从而,对于相当一部分查询请求,我们只要访问内存中布隆过滤器就可以判断作出判断;只有一小部分请求,我们需要访问在硬盘上的 key-value 数据库。从而整体上大大地提高了查询效率。示意图如下:

1 ,在分布式存储 Ceph 中的应用
Ceph 是一个开源分布式存储系统,可以提供文件系统、块存储和对象存储等存储服务,在云计算环境中多有应用。为了提升读写效率, Ceph 提供了 CacheTier 服务。使用者可以将 CacheTier 部署在 SSD 等高速介质中,实现读写加速。示意图如下:
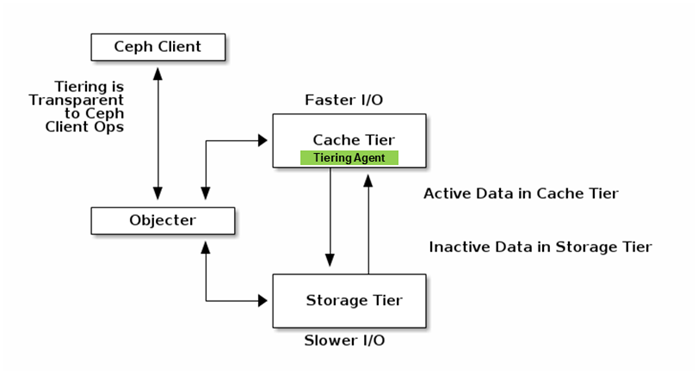
上图中, Objecter 来负责 I/O 数据路由, Cache Tier 层和后端存储层对 Ceph Client 透明。 Cache Tier 利用 Bloom Filter 快速判断一个 object 是否在 Cache 中。
2 ,在 LSM-Tree 中的应用:
LSM-Tree 全称是 Log Structured Merge Tree ,是一种分层,有序,面向磁盘的数据结构,它充分利用磁盘顺序写性能远高于随机写性能的特点,通过把随机写 IO 变成大块数据顺序写入(追加写)获得超高的写入性能。一些著名的应用,如 LevelDB 、 RocksDB 、 Bigtable 、 Hbase 、 Cassandra 等,都使用了 LSM-Tree 存储引擎。 LSM-Tree 的基本数据布局和原理如下图所示:
LSM-Tree 把随机写变成了顺序写,非常适合数据写入密集型的应用;但在数据读取时,则需要遍历查询多个文件( SSTable ),读放大问题非常严重。为了提升读性能,同样可以采用布隆过滤器。在每个 SSTable 文件结构中的元数据区保存该文件 key 值的布隆过滤器数据,并将这些数据保存在内存中。这样,在处理读 IO 时,可以首先通过查询内存中的布隆过滤器快速定位需要实际读取的 SSTable 数据字段,大幅提升读取效率。
3 ,在备份归档中的应用
数据备份是为应对潜在的数据丢失风险,而将业务系统中的数据加以复制并转储到备份存储的工作。数据备份一般以自动化方式进行,由于数据的反复复制和保存,备份设备中充斥着大量的冗余数据。为了解决这个问题,节省更多空间,“重复删除”技术便顺理成章地成了人们关注的焦点。它的基本原理是在数据写入到备份设备中时,这些数据会被分割成固定长度的数据块(如 8KB ),为了快速比较系统中是否存在相同的数据块,我们会通过一个哈希函数为每个数据块计算出一个定长指纹(如 20Byte ),通过比较指纹来确定是否存在相同的数据块。一台备份设备往往要存储数十甚至上百 TB 的数据,此时,形成的指纹所占据的空间也是非常可观的。比如,假定有 80TB 数据,则生成 100 亿个指纹,则至少需要 200GB 内存。此时,同样可以利用布隆过滤器来减少内存的占用。此例中,简单计算可得,在 1% 的误判率条件下,只需要 12GB 内存。
示意图如下: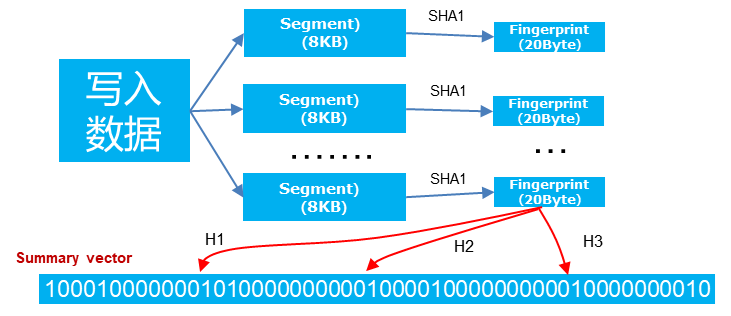
除了上面所列举的例子,布隆过滤器在浏览器、比特币、大数据、 CDN 等多个领域均有广泛的应用。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞1作者其他文章
评论 1 · 赞 2
评论 2 · 赞 4
评论 1 · 赞 3
评论 1 · 赞 1
评论 1 · 赞 1
添加新评论0 条评论