
于无声处听惊雷 浅析计算型存储技术的发展
作者:方勇,原华为资深存储专家,深耕存储领域20余年。以文字解读优秀公司商业战略,洞察行业发展趋势

1.什么是Computational Storage(计算型存储)?
2022 年 8 月 Gartner 新鲜出炉了年度存储和数据保护炒作周期( Hyper Cycle For Storage and Data Protection Technologies,2022 )报告, Computational Storage (计算型存储)位列炒作热点之一。按照 SNIA 的定义,计算型存储是一种具备计算型存储功能( Computational Storage Function )的架构,用于卸载主机处理或减少数据移动。
这种架构将计算资源(在传统的计算和内存架构之外)直接与存储或在主机和存储之间进行整合,使应用性能和 / 或基础设施效率得到改善。计算型存储出现的目标在于启用并行计算,从而减轻对现有计算、内存、存储和 I/O 的约束。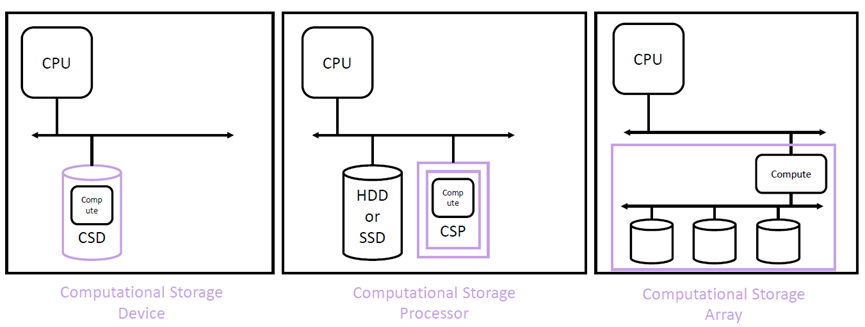
按照具体的技术形态, Computational Storage (计算型存储)又被分为三个大的类别: CSD ( Computational Storage Device )、 CSP ( Computational Storage Processor )和 CSA ( Computational Storage Array )。
2.offload(卸载)是计算型存储设计思想的精髓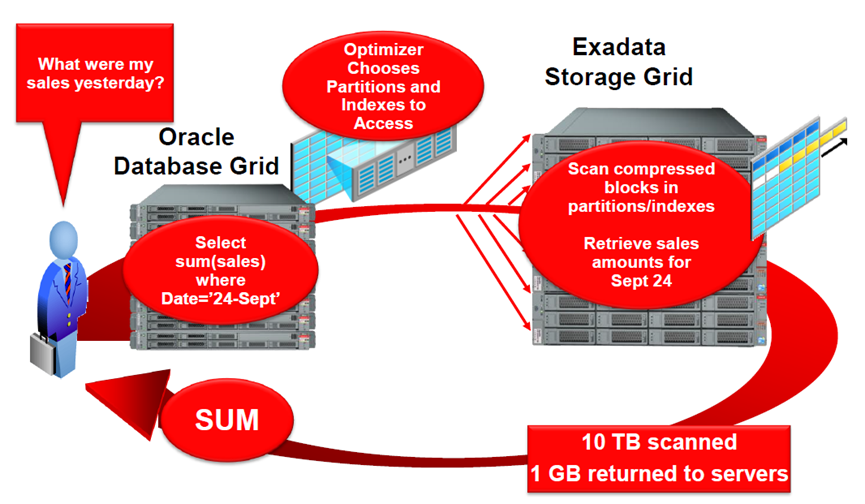
谈到计算型存储就不能不谈 Oracle Exadata 数据库一体机。 2008 年研发的 Exadata 是针对 Oracle 数据库进行优化的计算平台,用于解决传统数据库受 I/O 瓶颈引发的性能问题。在解决思路上, Exadata 采用了颠覆性的设计思想 - “ offload (卸载)”,即将数据库系统中的数据处理行为从计算节点(数据库服务器)卸载到存储节点(存储服务器)进行并行处理,并且仅有计算后的最终结果会被返还给计算节点。这种设计方式大大规避了计算、存储和网络等硬件设备的 I/O 瓶颈对数据库性能造成的局限。
透过官方标称值,我们可以看到 Exadata 宣称具备极高的性能数值,那么实际的表现如何呢?数年前笔者曾有幸做过一次 Exadata X5 和国产数据库一体机之间的性能对比测试。 OLTP 场景下二者之间的差异主要体现为硬件配置差异带来的差距,换句话 Exadata 在 OLTP 场景下的加速效应可以忽略;而在 OLAP 场景下, Exadata “卸载”的设计带来 2-3 倍以上的巨大性能增益,诸如全库扫描体现出的性能已不再受到 IB 交换机网络带宽的限制!
Exadata “卸载”的设计思想可能是计算型存储早期的雏形,但是由于只能在 Oracle 数据库场景下使用,注定这项颠覆性技术在市场上的推广受到极大的局限。
3.DPU的出现让普适型计算型存储成为可能
近几年 DPU ( Data processing unit )概念异常火爆,但是参与的企业多半隶属半导体行业,如: Intel 、 Marvel 、 Nvdia 、 Samsung 等,所出产品也多属于 CSD 或 CSP 的范畴。初创公司 Fungible 在自研 DPU 芯片同时,开发了一套分离式存储平台( Disaggregated storage platform ),其设计核心理念和 Exadata 如出一撤,就是将数据应用的数据处理环节“卸载”到存储端进行执行,并通过专用的 DPU 芯片实现加速。因此, Fungible 存储操作系统的软件模块除了包括常见的存储(存储协议、 EC 、消重、压缩、复制等)、网络、安全等功能以外,还增加了数据分析的类别:数据库、大数据、 Serverless 等富数据应用的协同模块被包括其中。应用运行在计算型存储平台的效果如何呢?“在 DPU 上使用单线程,将 X86 服务器上的 MySQL 查询与基于 DPU 的存储集群进行比较,查询时间提高了 75 倍;使用正则表达式匹配,拿软件实现与 DPU 加速操作对比,吞吐量提高了 27 倍。”
4. HPC应用正成为计算型存储技术被最早的实践场景
除了作为供应侧的厂商在进行计算型存储的创新努力以外,作为需求侧的最终用户也在进行这样的尝试。美国阿拉莫斯国家实验室 (LANL) 是世界上最大的科学和技术研究机构之一,它在国家安全、 太空探索、 可再生能源、医药 、纳米技术和超级计算机等多个学科领域开展科学研究。阿拉莫斯的工程人员预计他们的 Trinity 超算系统在 2023 年将达到 10PB DRAM 、 100PB Flash 存储和 0.5EB 磁盘存储的规模。在不断发展中的 HPC 环境下,数据存储环境面临巨大的挑战,譬如:
(1). 面对 CPU 频率增益已不复存在、计算内核从 1000 增加到 100 万、基准 FLOPS 在增加,效率却在降低等现实挑战,在 PB 乃至 EB 数据量级的数据存储环境下,如何利用横向扩展架构实现更高性能?
(2). 在系统规模不变大的情况下,如何让存储系统跑的更快?
(3). 如何更快的解决文件固定尺寸的问题?
为了克服这些挑战,阿拉莫斯的工程师与各类科技厂商合作探索计算型存储的创新实践。对存储在文件系统上的数据处理进行“卸载”是设计的核心,为此将每个处理环节涉及数据处理部分卸载到 DPU ,以近盘 / 近存储计算来大幅加速数据处理效率。阿拉莫斯在实践中通过 Eideticom FPGA 加速器和 Nvidia BlueField-2 SmartNIC 构建具备数据处理加速的闪存磁盘框( ABOF ),将数据访问速度提高了 10-30 倍。
此外,阿拉莫斯还尝试和SK 海力士构建了计算型存储 SSD ,通过索引关键值存储数据,将仿真输出分析速度提高了 1000倍 。
5.除了提升数据处理性能,计算型存储对现代数据中心的绿色节能有现实意义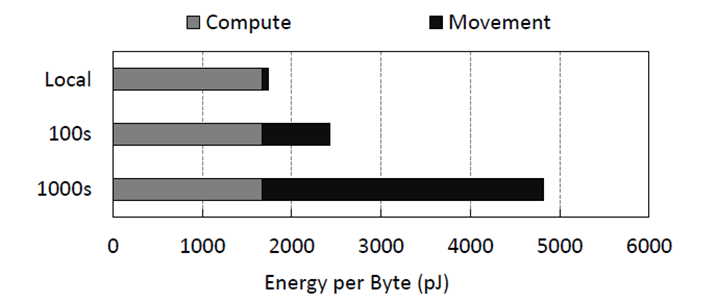
2015 年三星半导体实验室的一项研究 1 表明,分布式计算环境下的数据移动将会导致更高的能量消耗。即在一个上千节点的计算集群中,数据移动能耗几乎是计算能耗的两倍以上,而在单个计算节点上,这样的比例则不到 5% 。数据中心的高能效设计已是趋势,如:“东数西算”工程对数据中心 PUE (电能利用效率)要求为 <1.2 。然而“东数西算”当前更多是资源配置层面的构想,让我们大胆想象一下,如果未来计算型存储技术可以实现跨域的配置,那么真正意义上的“东数西算”就会变成现实,而数据中心资源的高能效将会走向一个新的高度。
今天计算型存储尚处在发展早期,当前行业实践也主要发生在 HPC 和公有云的应用场景,但是在数据库、私有云、大数据、 AI 等富数据应用场景下,计算型存储同样会存在很好的应用前景。然而任何一项创新技术都需要时间在市场去验证其实用价值, Gartner 将计算型存储位列在 Hyper Cycle 的炒作曲线上升位置,但是市场渗透所需时间还是定义为 5-10 年之久。不过正如历史上的电子支付、电子商务、智能手机等颠覆性技术的出现,如果一项创新技术显露出十倍乃至百倍的效率替代时,那么阳光最终会出现在并不遥远的未来。
来源:__
1 Energy Efficient Scale-In Clusters with In-Storage Processing for Big-Data Analytics
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞2本文隶属于专栏

作者其他文章
评论 0 · 赞 0
评论 3 · 赞 12
评论 3 · 赞 9
评论 2 · 赞 1
评论 7 · 赞 3
添加新评论1 条评论
2023-06-10 11:26