一次关于系统应急处理过程中惊心动魄的问题排查
经历了一次系统应急处理,可谓惊险。简单回顾一下,梳理排查思路,算是总结,也是学习。由于涉及些隐私问题,所以屏蔽了一些信息,只阐述技术问题。
应用逻辑并不很复杂,需要访问远端数据库,进行一些数据交互的操作,从应用端日志看,出现问题的时候,现象就是卡在某一步,不动了,hang的状态,具体来讲,就是卡在数据库操作,比如SELECT语句,正常来讲,毫秒级就能返回,但当前几秒、几十秒、甚至几十分钟,都没有响应。选择重启应用,偶尔能起作用,但随着时间推进,效果不很明显。
由于很久没有更新过应用,软硬件环境,同样许久未变更,突然出现这现象,第一感觉,就是怀疑数据库层面(Oracle),例如SQL语句执行计划的突变,或者数据量累积起来,没有清除策略,导致到达一个临界点,影响CBO的判断。
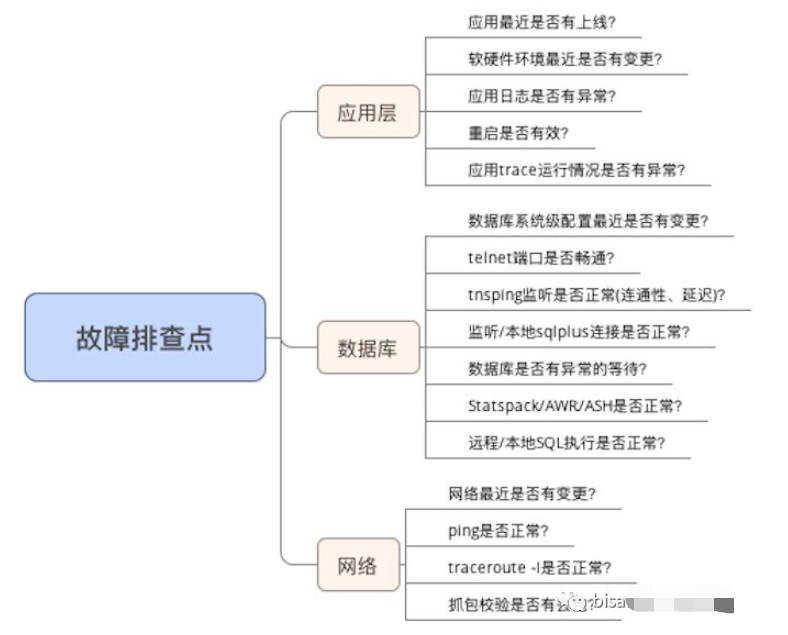
排查一:应用层面是否有问题
应用已经许久未更新了,包括软硬件环境,而且从应用层面,几乎将所有异常,都记录于日志当中了,换句话说,只要是应用问题,日志都会记录。但出现问题时,应用未有任何的报错。
trace了出现问题的应用进程,也并未出现任何异常。
因此初步判断,不是应用层面的问题。
排查二:数据库层面是否有问题
我们团队的DBA-albert久经沙场了(P.S. 推荐一下,albert的博客http://travelskydba.com/),第一步就是让对端DBA用如下SQL,检索当前数据库的等待事件,如果是数据库层面的问题,操作慢,就一定在等待着什么
但从实际来看,没有任何异常的等待,数据库层面都比较正常。
此时,另一个现象,就是我从应用服务器,sqlplus几十秒才能登陆,执行应用使用的语句,几十秒未返回,其中sqlplus执行cancel出现过,
oerr ora 12152
12152, 00000, "TNS:unable to send break message"
// *Cause: Unable to send break message. Connection probably disconnected.
// *Action: Reestablish connection. If the error is persistent, turn
// on tracing and reexecute the operation.又让对端DBA做了如下操作:
- 本地sqlplus登陆。
速度很快。
- 本地通过监听登陆数据库。
速度很快。
- 本地执行SQL语句
速度很快。
因此初步判断,不是数据库层面的问题。
排查三:网络层面是否有问题
排查网络问题,常用的方法,可能就是如下这些了,
- ping
- telnet
- tnsping
- traceroute(Linux)
前三个很好理解,第四个指令,其实在排查网络问题时,非常实用。
traceroute最早是由Van Jacobson在1988写出的小程序。可以让我们看到IP数据报从一台主机传到另一台主机所经过的路由及RTT(往返时间)。通过traceroute我们可以知道信息从你的计算机到互联网另一端的主机是走的什么路径。当然每次数据包由某一同样的出发点(source)到达某一同样的目的地(destination)走的路径可能会不一样,但基本上来说大部分时候所走的路由是相同的。linux系统中,我们称之为traceroute,在MS Windows中为tracert。 traceroute通过发送小的数据包到目的设备直到其返回,来测量其需要多长时间。一条路径上的每个设备traceroute要测3次。输出结果中包括每次测试的时间(ms)和设备的名称(如有的话)及其IP地址。
从工作原理上,traceroute程序的设计是利用ICMP及IP header的TTL(Time To Live)栏位(field)。首先,traceroute送出一个TTL是1的IP datagram(其实,每次送出的为3个40字节的包,包括源地址,目的地址和包发出的时间标签)到目的地,当路径上的第一个路由器(router)收到这个datagram时,它将TTL减1。此时,TTL变为0了,所以该路由器会将此datagram丢掉,并送回一个[ICMP time exceeded]消息(包括发IP包的源地址,IP包的所有内容及路由器的IP地址),traceroute收到这个消息后,便知道这个路由器存在于这个路径上,接着traceroute再送出另一个TTL是2的datagram,发现第2个路由器...... traceroute每次将送出的datagram的TTL加1来发现另一个路由器,这个重复的动作一直持续到某个datagram抵达目的地。 当datagram到达目的地后,该主机并不会送回ICMP time exceeded消息,因为它已是目的地了,那么traceroute如何得知目的地到达了呢?
traceroute在送出UDP datagrams到目的地时,它所选择送达的port number是一个一般应用程序都不会用的号码(30000以上),所以当此UDP datagram到达目的地后该主机会送回一个[ICMP port unreachable]的消息,而当traceroute收到这个消息时,便知道目的地已经到达了。所以traceroute在Server端也是没有所谓的Daemon程式。traceroute提取发ICMP TTL到期消息设备的IP地址并作域名解析。每次,traceroute都打印出一系列数据,包括所经过的路由设备的域名及IP地址,三个包每次来回所花时间。
traceroute常用的参数如下:
-n: 可以不必进行主机的名称解析,单纯使用IP,速度较快;
-U: 使用UDP的port 33434来进行检测,这是默认的检测协议;
-I: 使用ICMP的方式来进行检测;
-T: 使用TCP来进行检测,一般使用port 80测试;
-w timeout: 若对方主机在几秒内没有回应就声明不通,默认是5秒
-p port: 若不想使用UDP与TCP的默认端口号来检测,可在此改变端口号;
-i device: 当自己的主机有多个网络接口时,可在此指明使用的接口;
-g gateway: 宽松的源站选路。指定路线中的路由;
出现问题的时候,ping和telnet正常,traceroute有时会有延迟,tnsping偶尔连接较长。
此时,对端检查,到我们的网络有丢包现象,还学到一点,就是单向有问题,意味着双向会有问题,所以基本定位,和网络相关。
最终确认,就是网络光纤的问题,更换之后,一切恢复正常。当然不是简单的两点A-B网络,其中比较复杂,因此某些监控,是无法真正覆盖,或者联动。
从上面描述看,轻描淡写,但真正经历整个过程,才能深刻体会到,其中的惊心动魄,这种经历,只能意会,不能言传。
从整个处理过程,有不少值得总结。
除此之外,还有一些非技术因素,可能左右问题的排查。例如:1. 是否能做到团队间亲密协作,有甲方,有乙方,有DBA,有中间件,有网络,有业务,尤其是临时组成的虚拟团队,信息资源的共享,操作上的互补,都很重要。2. 是否能清楚地阐述问题,无论是技术人员,还是业务人员,在紧急的情况下,能否言简意赅地表达,提供其他人判断问题的素材,非常重要。
现在都说智能化运维、AI运维,归根结底,还是有人的因素在其中,机器学习等技术,能根据历史数据,以及精细化推演算法,辅助甚至代替人做出监控、做出判断、做出应急操作,“解放了”运维,但是真要达到这种程度,对于一般的企业来说,还是有很长的路要经历,不能急于求成,还应该脚踏实地,做好该做的工作。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞1本文隶属于专栏

作者其他文章
评论 1 · 赞 5
评论 0 · 赞 2
评论 0 · 赞 2
评论 0 · 赞 1
评论 0 · 赞 1
添加新评论0 条评论