干货贴|基于日志易数据工厂实现数据治理融合
背景介绍
大数据分析、人工智能等新兴科技已经成为金融、能源、政府、交通、医疗等关键行业在数字化转型过程中,不可或缺的战略实现工具,能否迅速地理解、适应、运用这些工具,在一定程度上决定了企业是否拥有赢得未来市场的实力。
高度数字化的系统运营,催生了海量多维异构的数据,这些数据同时也是系统运营与安全防御能力建设的基础。大部分企业在运维管理、客户营销、风险防控、安全防护、资源利用等领域都取得了局部进展,但是在提升核心竞争力、有效整合线上线下资源构建高效运维平台、完善客户图谱、实现精准营销、数据治理与融合利用等方面的问题逐渐凸显。
数据孤岛
企业机构繁多,数据散落在各个角落,例如边界安全的数据可能会存储于安全设备中,负载均衡、中间件、操作系统等数据往往因为存储在运维相关平台上而被安全部门忽略,另外涉及到资产的CMDB数据、系统架构等,普遍是包含在CMDB的登记数据中,实则与机构的安全态势感知息息相关。这些类型的数据,相对于机构安全设备中的安全数据来说,既与安全相关,又相对孤立,治理难度相对较大。
数据交互时效性高
在安全攻防过程中,对数据交互的实时性要求较高。例如,在出现安全攻击时,如果在发生攻击之后,再进行查询被攻击IP是否跟威胁情报有关联、对应哪一项资产的话,整个安全防御系统的时效性极差,无法及时为业务端提供所需数据,难以保障系统安全运营。关键行业对安全防御能力要求极高,都希望在攻击发生时,能够实现自动的数据碰撞,也称数据补全。
数据交互复杂多变
各行业数字化转型加速,大数据技术应用场景越来越广泛,相关平台工具的增多,导致数据存储的地址也在增多;安全以及运维设备增多,相关的数据逐渐散落存储在庞杂的系统各处。
- -
数据种类繁多包括日志,资产信息,漏洞信息,情报信息,配置信息等,通常存储在不同的存储介质中。
- 不同的数据来源提供不同的读取方式,需要采用不同的客户端或编写特定的程序脚本;
- 不同的数据目的提供不同的写入方式,也需要采用不同的客户端或编写特定的程序脚本;
- 不同数据来源和目的仓库之间,数据结构设计不同,还需要采用不同的转换软件或程序。
由此,随着数据网络中数据源、数据使用目的等因素的不断复杂化,使得整个数据治理变得更加错综复杂。
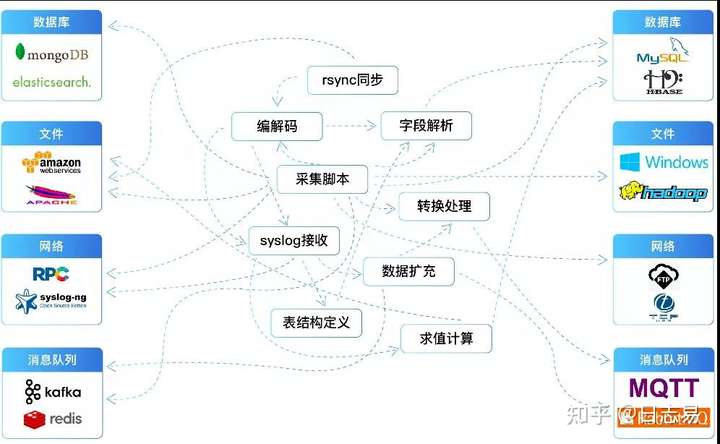
数据工厂(DataFlow Manager)是日志易针对数据整合共享的核心需求,推出的新一代数据治理融合平台,通过图形可视化操作,简单拖拽即可实现数据的采集、流转、清洗、发布,大幅简化异构数据来源和目的的对接,同时提供了任务流调度、可视化监控、自助数据清洗等丰富的平台管理功能,帮助企业高效地实现异构数据源和目的的连接共享需求。
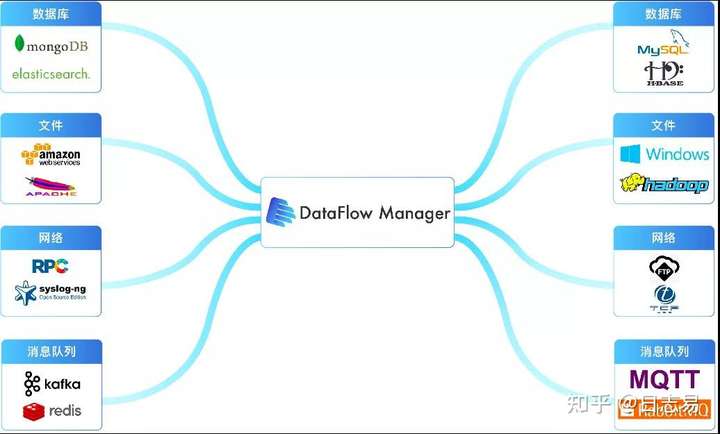
日志易数据工厂——数据治理
源数据对接
日志易数据工厂可以对接业内所有主流数据源,包括Hadoop、Kafka、MongoDB、人行上报相关的HTTPS接口等数据存储介质,实现数据的无缝对接。此外,数据工厂的对接是无需定制开发的。
建立指标标准化体系
帮助用户建立指标标准化体系,不同类型的数据对接到日志易数据工厂之后,将被转换为标准化的字段名称如SICIP,目的IP将会全部转换为标准化的描述,帮助用户实现异构数据指标的统一标准化管理。

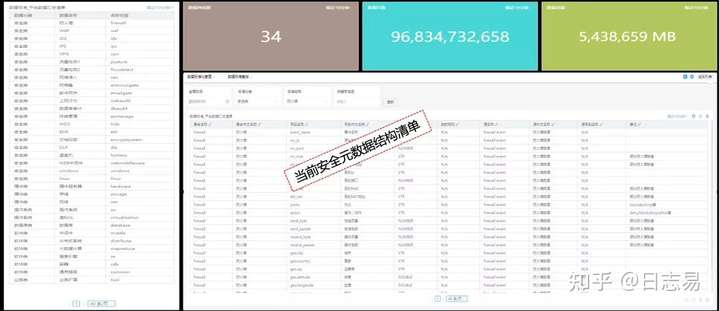
元数据管理
用户可以随时查阅虚拟资产,随时掌握已有的元数据。例如,用户能够查询到防火墙在整个数据治理体系中的字段以及字段名。
可视化数据调度流程编辑
日志易数据工厂为用户提供了智能可视化的自动编排引擎,实现各类异构数据的采集、处理以及调度。数据工厂配置了轻量级设计和执行引擎,能够通过最简单的拖拽完成数据的采集、流转、清洗、发布;具有从一到多的数据分发任务能力,支持批流一体处理,能够大幅简化异构数据来源和目的的对接过程。
如下图,数据工厂可以从界面右侧的组件库中拖出一个组件,再通过一个数据处理的组件进行分流,之后对需要满足条件的数据进行字符转化,并将其放进Hive组件中。通过数据工厂这一简单的流程化配置操作,用户可以轻松完成繁杂异构数据的自动转化,实现数据调度的自定义编辑。
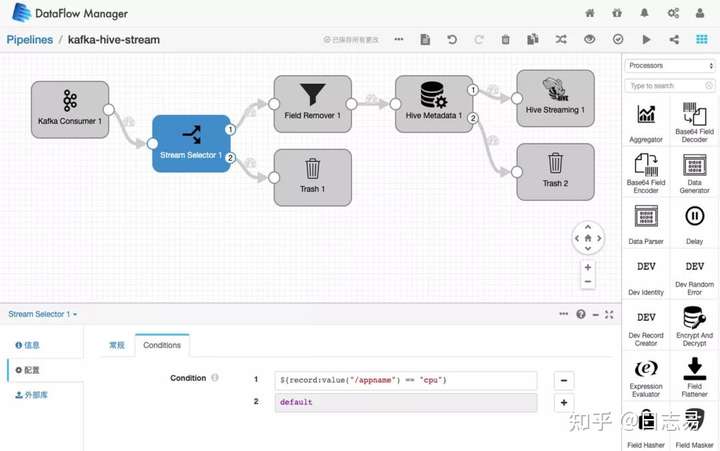
在数据调度过程中,日志易数据工厂还能够帮助用户跟踪元数据的质量体系态势。实时监测数据传输过程中的元数据质量体系,分析是否有些数据源缺失字段,若有即产生告警。此外,数据工厂还能够对不同数据源之间指标转换过程中每一步输入、输出的结果进行血缘跟踪,深度实现数据治理有迹可循。
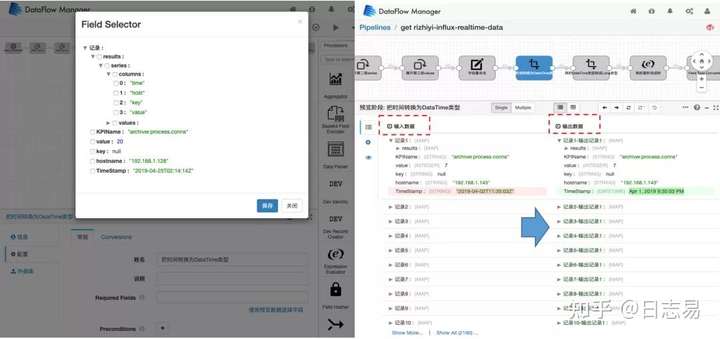
日志易数据工厂——数据融合
数据存储
在做数据融合之前,如果用户自身并没有合适的数据存储介质,日志易自研的国内首个高可用性分布式数据搜索引擎Beaver,能够帮助用户存储海量繁杂的非结构化以及半结构化数据,每天可处理数百TB日志数据,相比通用开源搜索引擎来说,Beaver性能提升了10倍且硬件成本降低了50%。
对于指标类的数据,例如防火墙的连接数、会话数等,将会保存在时序数据库中。同时,数据工厂能够从流量设备中提取出源IP跟目的IP之间的访问关系,也能够从扫描机器或防火墙会话日志中提取出源IP跟目的IP之间的会话连接关系,会话连接关系数据一般保存在图数据库中。
通过数据采集、转换、调度、留存的准备,为接下来要做的数据治理与融合碰撞提供了基础。

机器学习——数据融合所需要的功能
日志易数据工厂对接了业内主流的机器学习算法。时序预测算法更多地应用在指标类的数据,例如上文提到的防火墙会话数与连接数、CPU使用率等。通过这些类型的机器学习,帮助用户实现自动化地监测安全设备是否正常运行,例如发现会话数突然增加,或是CPU使用率突然增加等异常情况。DBSCAN的算法普遍应用在用户行为分析的过程中,例如通过聚类去分析出个人行为是否跟相应群组的行为基线存在明显偏差,进而发现员工可能存在的异常行为。
SPL(Search Processing Language)安全建模分析
那如何使用这些机器学习的功能呢?
日志易数据工厂将相关函数全部封装成分析建模语言,即SPL(Search Processing Language),它是日志易自主研发的低代码可建模搜索处理语言,通过界面化的脚本式建模编程,帮助用户将复杂的数据搜索分析,直观地转变为便捷可视化的条件处理流程,具有更强的可用性、灵活性、功能性,已达到国内顶尖技术水平。

目前,日志易SPL(Search Processing Language)已实现了200多函数及指令,全面覆盖日常运维分析和安全分析工作需求,涵盖了几乎所有机器学习函数。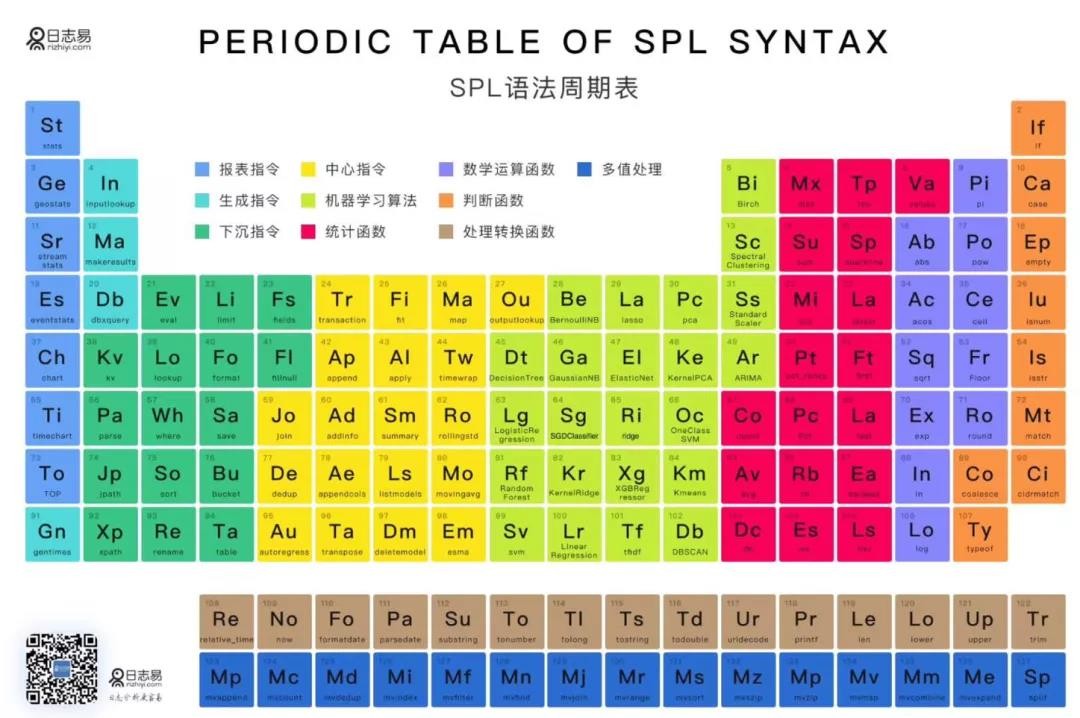
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞0作者其他文章
评论 0 · 赞 0
评论 0 · 赞 0
评论 0 · 赞 0
评论 0 · 赞 0
评论 0 · 赞 0
添加新评论0 条评论