分布式数据库疑难运营点
摘要:在核心早已进入运维的时间节点,分享学习到的知识,是没有意义的。帮助大家认识已存在或可能会存在的棘手问题的解决办法,并且指明下一代智能运营方向,是没有问题的。
监控往深里做,做到真正能在关键时候帮助定位解决问题,并不是一个简单的课题。简单的来说,部个普罗米修斯,吐出常见指标,貌似就很好看了。而我们真正想要的监控系统,是要能智能高效地帮助DBA分析解决棘手问题的。我们为什么需要这么深入的一个运营系统?只是尝试可能的交易成功率由99.8%到99.99%的提升。
一.关键监控指标
1.1 锁等待
常见现象
- SQL单独执行很快
- 负载很低,但是时快时慢
- 偶尔出现Lock wait timeout错误
常见原因:
- 事务未提交
- 事务时耗长
锁:事务未提交(应用异常等)
请求响应时间= 执行时间+锁等待时间

Mysql 的information_schema库下有3张表(innodb_trx, innodb_lock_waits, innodb_locks)记录了会话之间锁等待的依赖关系.
我们监控可以通过分析这三张表锁等待关系,找出当前持有锁的领头的会话。
在我们实际联调中已出现不少次的Lock wait timeout报错,重跑无法解决,只能手动登陆对应分片(前提为报错了具体哪个分片)检查是否有执行了很长时间的会话,然后找出kill 掉该会话(当然应用故障断开连接这种情况下,为什么proxy没有透传kill query的操作下到DB后面还得分析)。
锁:事务时耗长
- 事务持锁时间长
- 其他会话等锁时间长,执行时间并不长
- 等锁时间超过innodb_lock_wait_timeout(默认50s,我们改成了15s)会返回锁超时错误

这个时候,我们goldenDB的日志云(DBProxy + DB两种index)所记录的慢日志是不会记录下来其中的SQL(后面的慢SQL也会说明)。 如何找出这些SQL,又如何高效的找出sessionA和sessionB的历史交错会话信息,是个困难点。
TDSQL扁鹊的做法或许值得参考。扁鹊实现了一个事务模拟器,可以通过按客户端执行记录的IP:PORT分组并结合语法解析回放用户执行过的SQL来提取所有事务信息,如事务的开始,结束时间,事务中访问了哪些表,事务的影响行数,事务的总时耗等等,这样我们就可以通过设定过滤条件以事务为单位来找出某个事务具体的执行信息。都涉及多表的情况下,事务模拟开发是困难的。
当然审计日志也是一种做法,记录SQL,耗时,源IP和端口等,分析审计日志来提取会话的事务信息。不过,使用插件(商业版mysql也有)预计会带来超过15%的性能损耗,不一定值得。
1.2 可用性诊断处理
我们goldenDB探测主DB是否健康也不只是ping或者select 1这种操作。
我们会事先在mysql上自建一个心跳表,DBAgent模块连接DB,定期向DB心跳表中写入数据,这样无论是磁盘坏块,磁盘满了还是DB重启导致DB不可用,DBAgent都能准确的判断出来,当agent连续一段时间写入心跳失败或超时就会触发切换的逻辑,在这期间DB会处于短暂的秒级不可用状态,从用户侧可能会收到DB只读(group disabled),连接断开等异常。 这种情况,业务是需要清楚地知道切换的原因是什么,如何避免切换再次发生。 我们现在是通过告警去发生切换的DB分片上查看错误日志来进行定位,但是所追溯出来的根因其实不精确。
之前的文章有介绍,触发DB切换的原因很多,有DB意外重启;内核bug引起系统hang住;文件系统或磁盘故障;资源竞争(IO耗尽,CPU好紧,binlog写入紧张)。 要分析出切换的原因,我们是需要保留必要的现场信息的,为后面提供线索。
实现iotop,top,iostat主机资源的秒级采集我们用普罗米修斯就可以实现,但是切换前DB内部的processlist(平时也要分钟级的采集),innodb_trx等这些快照信息也是需要记录。 通常慢查询并发和大事务引起两大类引起的切换最多。而针对慢查询并发的情况,我们的mysql已经加入了线程池的功能,可以大大提高了并发处理能力。而大事务,我们在binlog一次性写入进行了可配的限制来禁止大事务的产生,确保不会因为binlog顺序写入中,心跳写入受到大事务影响而超时。 实际来看,我们核心出现的切换,也基本都是造成硬件资源耗尽才影响了(如慢SQL导致CPU持续打满的问题)。
二.慢查询原理和解释
2.1 慢日志触发条件
- The server uses the controlling parameters in the following order to determine whether to write a query to the slow query log:The query must either not be an administrative statement, or log_slow_admin_statements must be enabled.
- The query must have taken at least long_query_time seconds, or log_queries_not_using_indexes must be enabled and the query used no indexes for row lookups.
- The query must have examined at least min_examined_row_limit rows.
- The query must not be suppressed according to the log_throttle_queries_not_using_indexes setting.
2.2 Query_time小于long_query_time,但是依旧出现在慢日志中
相信有些人遇到这个问题的时候觉得很奇怪,其实这个不是bug,而是你设置了系统变量log_queries_not_using_indexes ,这个系统变量开启后,会将那些未使用索引的SQL也被记录到慢查询日志中,另外,full index scan的SQL也会被记录到慢查询日志。所以,当满足这些条件的SQL,即使Query_time时间小于long_query_time的值,也会被记录到慢查询日志。
官方:The query must have taken at least long_query_time seconds, or log_queries_not_using_indexes must be enabled and the query used no indexes for row lookups.
当然,我们一般不存在应该建索引而不建索引的问题,所以这种情况并不常见。
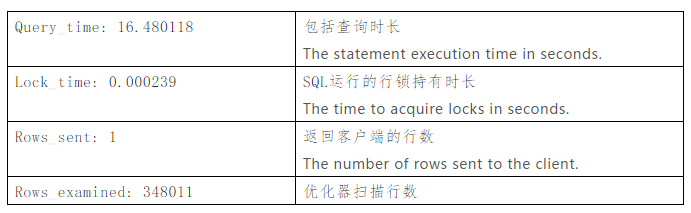
通常需要优化的就是最后一个内容,尽量减少SQL语句扫描的数据行数。
2.3 运行时间过长,但是慢SQL里面并无体现
如果真正的运行时间达到了long_query_time才会被记录到slow log中,有lock_time的话,才会被显示出来,比如一个update执行只需要0.1s,等待了10s(总的query_time是10.1s),long_query_time为1s,这时这个update的read exec time是 0.1s(并非是query time 10.1s),小于long_query_time,不会被记录,这个update不是慢sql.
2.4 关于慢查询日志中query_time和lock_time的关系
只有当一个SQL的执行时间(不包括锁等待的时间lock_time)>long_query_time的时候,才会判定为慢查询SQL;但是判定为慢查询SQL之后,输出的Query_time包括了(执行时间+锁等待时间),并且也会输出Lock_time时间。当一个SQL的执行时间(排除lock_time)小于long_query_time的时候(即使他锁等待超过了很久),也不会记录到慢查询日志当中的。
query_time可以大概认为是lock_time+real exec time的时间。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞1作者其他文章
评论 2 · 赞 14
评论 10 · 赞 24
评论 0 · 赞 4
评论 0 · 赞 4
评论 0 · 赞 6
添加新评论0 条评论