
HotDB Server部署与基本使用.集群部署
HotDB Server概述:建议结合章节2的架构图理1.1 HotDB Server组成:*
HotDB Server是一款中间件模式的分布式事务型数据库,由4大组件构成:基于java的管理平台hotdb-management、计算节点hotdb-server,基于C的备份程序hotdb_backup,基于C的官方版原生MySQL(作为数据节点和配置库)。
其中,hotdb-server主要负责SQL解析、路由、结果处理等分布式数据处理功能以兼容原生mysql语法,mysql进行数据存储以及集中式数据处理。此外hotdb-server需要一个mysql物理库hotdb_config(计算节点配置库)来保存与数据服务相关的配置(如表分片规则、数据节点高可用切换规则等)。上面三个部分构成了HotDB Server的数据服务部分。hotdb-server时刻保持对集群中数据服务部分mysqld的连接,数据节点或计算节点配置库有双主等高可用架构时,若某个mysqld故障,hotdb-server可以自动切换到可用mysqld进行读写,实现数据节点和计算节点配置库的高可用。
至于运维管理部分,主要由可视化Web服务进程hotdb-management承担,辅以hotdb_backup用于对mysql进行备份还原。而hotdb-management同样用到一个mysql物理库hotdb_cloud_config(管理平台配置库)来保存与运维管理相关的数据(如监控信息,备份计划等)。一旦无需配置与运维管理HotDB Server,运维管理部分完全可以关闭(亦即,运维管理部分不影响数据服务)。该部分中hotdb_backup时刻保持到hotdb-management端口3322的连接,接收到management的备份指令时,backup则连接到mysqld进行逻辑备份,同时备份binlog文件。当然,除实际的备份操作,运维管理部分其他功能都由management进程访问server进程的3323、3325端口,并监听其他服务器资源状态等完成。
1.2 HotDB Server分布式设计基本原则:
HotDB Server将存储节点(*实际存在的mysql*物理库IP:PORT

B)根据高可用、分片需求划分成逻辑上的数据节点(可由单主、双主、MGR架构的存储节点构成)。进而将一个表hotdb.tb1根据设定的表信息**,将表存储到指定的数据节点。如应用端访问HotDB服务器IP:3323,存取hotdb.tb1,实际上是由计算节点hotdb-server根据规则从物理表db01.tb1、dbtest.tb1等存取数据并处理后返回给应用。
2.本文部署的HotDB Server架构简介
本文指引使用者在5台Linux服务器上完成一个HotDB Server环境的部署,并能明白HotDB基本用法。整个环境的组件架构将如下图所示:
management及其配置库部署于服务器160上,主、备server及主、备计算节点配置库、keepalived分别部署于60/61上,存储节点mysql必伴有backup部署于62/63中。此次部署设定两个数据节点,其主库分别为62/63的mysqld3311:db01,并分别以63/32的mysqld3312:db01作为双主备库。因而,借助keepalived的VIP访问server端口的3323,实现了计算节点的高可用,而数据节点高可用由计算节点本身保证,从而实现了整个数据服务部署的高可用。

3. 本文架构部署要求
3.1服务器要求:
| 数量 | 用途 | 架构 | 系统 | 账号 | yum | 内存 | 磁盘 | 备注 |
|---|---|---|---|---|---|---|---|---|
| 1 | 管理 | x86_64 | redhat 6/7 centos 6/7 | root | 含glibc.i686 | >5G | /usr/local >10G /data > 20G | 推荐新装centos7,本文IP为160 |
| 2 | 计算 | x86_64 | redhat 6/7 centos 6/7 | root | 含glibc.i686 | >6G | /usr/local >10G /data > 20G | 推荐新装centos7,本文IP为60/61 |
| 3 | 存储 | x86_64 | redhat 6/7 centos 6/7 | root | 含glibc.i686 | >6G | /usr/local >10G /data > 20G | 推荐新装centos7,本文IP为62/63 |
注意,要保证组播keepalived可正常工作与该环境,并准备一个未被使用的IP作为keepalived挂载的VIP,本文为250
3.2软件要求:
已下载形如auto_hotdbinstall_HotDB2.5.*.tar.gz的HotDB Server安装包,如auto_hotdbinstall_HotDB2.5.3_v1.0_20191231.tar.gz。
4.部署步骤:
本章命令,复制每个框的命令到shell执行即可
4.1 环境检查:所有服务器执行4.1.1关闭selinux、firewalld等安全服务
关闭selinux
setenforce 0;sed -i's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config;getenforce
关闭防火墙
if [ -n "which systemctl2>/dev/null" ] ;then
systemctl list-unit-files --all | egrep 'iptables|ip6tables|firewalld'| awk '{print $1}' | xargs -I{} systemctl stop {}
systemctl list-unit-files --all | egrep 'iptables|ip6tables|firewalld'| awk '{print $1}' | xargs -I{} systemctl disable {}
else
serviceiptables stop 2>/dev/null
chkconfig iptables off 2>/dev/null
serviceip6tables stop 2>/dev/null
chkconfig ip6tables off 2>/dev/null
servicefirewalld stop 2>/dev/null
chkconfig firewalld off 2>/dev/null
4.1.2 检查ssh等网络环境,保证ssh服务拥有较快的速度:推荐如下配置
配置主机名和IP的映射关系
{
owf="/etc/hosts"
localip=ip a|grep 'inet '|grep -v '127.0.0'|grep-v 'secondary'|head -1|awk '{print $2}' | cut -d'/' -f 1 #&& echo $localip
myflag="$localip hostname"
ls "${owf}" &>/dev/null&& ! grep "${myflag}" "${owf}" &>/dev/null&& mv -f "${owf}" "${owf}".bak_date+%Y_%m_%d_%H_%M_%S
cat > "${owf}" << EOF
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
${myflag}
EOF
}
配置sshd,禁用DNS反向解析等功能
sed -i 's/^[[:space:]]#[[:space:]]UseDNS yes./UseDNSno/g' /etc/ssh/sshd_config
sed -i's/^[[:space:]]#[[:space:]]*GSSAPIAuthentication yes/GSSAPIAuthenticationno/g' /etc/ssh/sshd_config
sed -i's/^[[:space:]]#[[:space:]]PermitRootLogin./PermitRootLogin yes/g'/etc/ssh/sshd_config
service sshd restart
4.1.3 关闭所有设定的时间同步服务
关闭chronyd服务和ntpd服务,因为HotDB部署时会重建时间同步服务,避免冲突
timedatectl set-ntp no 2>/dev/null
service chronyd stop 2>/dev/null &&systemctl disable chronyd 2>/dev/null
service ntpd stop 2>/dev/null
4.1.4 注释配置的java环境变量
以下命令有输出,请自行注释配置的java变量,因为HotDB会自行设定,避免冲突
echo $JAVA_HOME
grep -Hi java ~/.bash_profile ~/.bashrc /etc/bashrc /etc/profile.d/* /etc/profile
4.2 yum预安装:所有服务器执行
脚本会自行安装,但推荐自行预安装,保证脚本运行过程中不会因为yum不全等问题而安装失败
安装yum,命令无输出即可
yum -y install gawk >>/dev/null
yum -y install yum-plugin-security>>/dev/null
yum -y update-minimal >>/dev/null
yum -y install initscripts >>/dev/null
yum -y install glibc.i686 >>/dev/null
yum -y install ntpdate >>/dev/null
yum -y install ntpdate initscripts grep procps coreutils xfsprogsutil-linux-ng e2fsprogs libselinux-utils chkconfig wget yum-utils gawk manlibaio perl perl-DBD-MySQL cronie xz numactl sysstat screen iotop unzip cpuspeedcpupowerutils irqbalance ethtool net-tools hdparm iproute lrzsz dos2unix glibcglibc.i686 usbutils telnet psmisc policycoreutils-python selinux-policy>>/dev/null
4.3 脚本部署管理平台:于管控服务器160上执行4.3.1部署命令
cd切换到当前auto_hotdbinstall_HotDB2.5.*.tar.gz包所在位置,解压并复制包于标准安装目录/usr/local/hotdb下
mkdir -p /usr/local/hotdb
tar -zxvf auto_hotdbinstall_HotDB2.*.tar.gz-C /usr/local/hotdb
\cp auto_hotdbinstall_HotDB2.*.tar.gz /usr/local/hotdb
.# 一键安装,复制下述命令执行,看到success即可,过程中有些warning可忽略
.# --ntpdate-server-host=192.168.0.60参数建议使用接下来即将要部署的主计算节点所在IP,我这里是192.168.0.60
sh /usr/local/hotdb/Install_Package/hotdbinstall_v*.sh\
--ntpdate-server-host=192.168.0.60 \
--hotdb-version=2.5 \
--hotdb-config-port=3316 \
--hotdb-config-init=yes \
--install-hotdb-server-management=yes \
--mysql-version=5.7 \
--character-set-server=utf8mb4 \
--creat-hotdbroot-in-mysql=yes \
&& echo "installed successfully"
若想查看安装进度,打开另一个窗口,执行下面命令即可
tail -fn 1000 /usr/local/hotdb/Install_Package/hotdbinstall.log
4.3.2 安装成功后,启动管理平台
bash/usr/local/hotdb/hotdb-management/bin/hotdb_management restart
4.3.3 安装失败如何清理?成功请忽略
若安装失败,执行下述命令清空原安装后,重新执行上面的安装命令即可
service keepalived stop
bash /usr/local/hotdb/hotdb-backup/bin/hotdb_backupstop
bash /usr/local/hotdb/hotdb-management/bin/hotdb_managementstop
bash /usr/local/hotdb/hotdb-server/bin/hotdb_serverstop
service mysql stop
service ntpd stop
sleep 5s
rm -rf /usr/local/hotdb
rm -rf /data/mysql
rm -rf /etc/my.cnf
rm -rf /etc/keepalived*
4.4 使用管理平台的集群部署功能部署其他所有组件4.4.1 登陆HotDB管理平台
在浏览器的url输入框中填写安装管控平台的服务器IP:3324,输入默认的用户admin、密码admin,点击用户登陆,进入管理员界面
4.4.2 进入集群部署界面
依次点击“集群管理”》》“计算节点集群”》》“集群部署”
[url=]4.43 进入参数配置页面
选则“主备节点”,点击“参数配置”,进入参数配置界面,弹出环境建议提示框,关闭即可。
[url=]
4.44 开始配置参数
[url=][url=]
填写即将部署的计算节点信息,如主机名、服务器root账号密码、堆内存和直接内存(按照章节3部署要求的最低内存,这里填写1和1,内存大的,可以适当增加,建议堆内存在4-64G,大于8G开启G1垃圾回收器)。填写完毕时“测试连接”**[/url]
[/url]**
**填写计算节点配置库的信息,如主机名、服务器root账号密码。注意选择双主、版本5.7。填写完毕时“测试连接”
填写keepalived的信息
注意保证keepalived的组播、vrrp协议能正常运行于部署环境中。选择一个未被使用的IP作为keepalived挂载的VIP。建议vitual_router_id以及网卡设备别名序号都用VIP最后一个分段(本文演示环境为250)。后面ens192注意改成主、备计算节点服务器上的网卡设备名称。备注:查看服务器物理IP对应的网卡设备
**置数据节点:存储节点实例选择5.7,个数填入2,节点类型选择双主,然后点击“生成”。
随后,配置好实例端口、主机名和root密码、管理平台IP,点击“测试连接”成功即可。
本文根据架构图,两个数据节点分别以62和63的3311作为主库,以另一台的3312作为双主备库。[/url][url=]l 配置时间同步:时间同步地址建议填写可用的NTPD服务器地址,服务器可联网时建议使用阿里的ntpd服务器182.92.12.11,不能联网,建议填写内网ntpd服务器。没有可用的内网时间同步服务器,则填写本地时间同步地址127.127.1.0。[/url]
上述参数都配置完毕后,点击“检查并保存”(该过程管理平台将安装包推送到每台服务器,并进行一些环境检查,请耐心等待),web界面出现动态等待提示信号,等待一段时间,成功后会自动回到“集群部署界面”
上述步骤都成功后,在“集群部署”界面,可以看到即将部署的架构图
4.4.5 在集群部署界面中开始部署所有组件在集群部署界面,点击“开始部署
[url=]
[/url]
将web界面拉到下方,可以看到集群部署的进展:
您可以选择总控看整体进展、可以选择分控的IP标签看相应服务器的安装进展。
一般等待约20-40分钟,安装进展框右上角的“进行中”变成“已完成”,则我们已成功部署所有HotDB Server。
安装完成后,点击“集群管理”》》“计算节点集群”,可以查看刚才安装的集群的基本信息
5.将hotdb-server分配给平台的某些用户管理
这里不演示添加新管理平台用户,直接将计算节点集群分配给admin用户进行访问和管理。
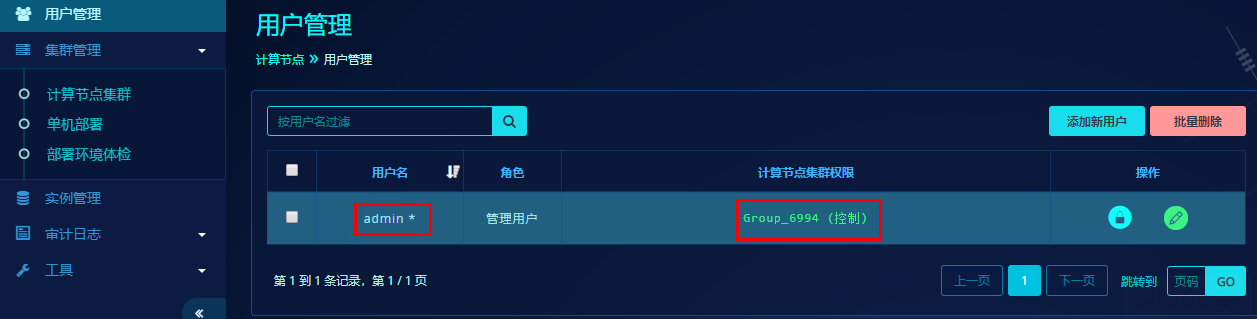
- 切换“用户管理”,点击绿色的编辑图标,进入编辑用户信息界面
- 点击“用户基本信息”,将我们添加的计算集群分配给admin用户访问和控制;点击“用户菜单权限”,给admin用户所有的用户菜单权限;点击“保存”,界面自动转到“用户管理”,可以看到admin用户拥有了对刚添加的计算集群的控制权限。(注意,大家的计算节点集群名称可能不同)

6.完成计算集群的基本配置:添加数据节点,数据库,数据库用户[url=]6.1切换到计算集群所属的普通角色界面
l 本指引中admin拥有对计算集群“随意填写”的控制权限,故此可以点击右上角的用户名“admin”,弹出菜单中点击“切换到普通角色”,界面自动转到“计算节点集群选择”,可以看到admin用户拥有的所有计算集群。点击某个集群,进入集群的“首页”。注意初次进入首页会弹出是否进入新手导航的弹框,我们选择“取消”,不用体验教程。
[url=]
[/url]
在普通角色界面,可以在“监控”》》“智能逻辑拓扑”界面看到当前的逻辑拓扑图。绿色代表当前状态主,蓝色代表备。M代表主,同一数据节点下两个存储节点都是M,代表该数据节点是一个双主架构,其中绿色为双主主库提供数据读写,蓝色为双主备库保证高可用的故障自动转移。[url=]6.2 添加逻辑库:
注意集群部署过程已经自动帮大家完成了该步骤,可以不看该步骤。此步骤放在此处,只是为了指导大家添加其他逻辑库。
l “配置”》》“逻辑库”》》“添加逻辑库”,弹出逻辑库填写框。本文演示创建一个名为hotdb的逻辑库,输入逻辑库名称hotdb,选择其默认分片节点为全部的2个节点,点击绿色的勾选图标的“保存”。
l 要想使应用能立即看到该逻辑库,请点击web界面右上角的“动态加载”按钮,弹出确认框“确认”,成功时界面会闪现一会“同步成功”。该操作是将设定同步到计算节点内存中,即使设定立即生效。
注意,在管控界面上配置的任何和数据服务有关的信息,都只是暂时保存在计算节点的配置库或配置文件中,要使设定立即生效,请点击“动态加载”。若你不知道哪些信息与计算节点有关,建议每次在管控界面设定保存后,都点击一下“动态加载”。
[url=]6. 3 添加数据库用户
l “配置”》》“数据库用户管理”》》绿色的编辑按钮,进入编辑用户权限界面。此处我们不演示创建新的用户,直接赋予自带的root账号所有的数据库权限。
l 赋予root所有权限,即勾选“ALL”,“提交修改”。

使root能立即连接到数据库hotdb,请如添加逻辑库小节一样,点击“动态加载”。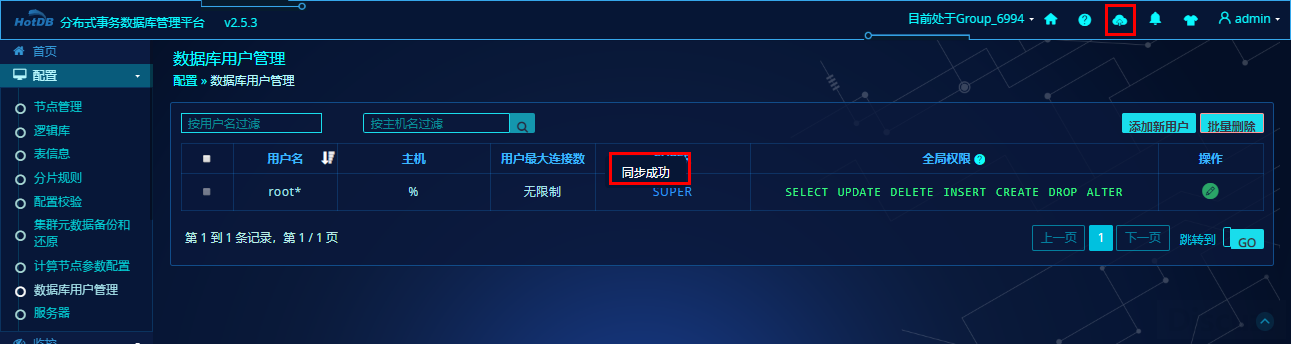
7.使用VIP连接到HotDB数据库,如同使用mysql一般使用HotDB7.1 常规SQL语句
此处演示使用的命令。-h192.168.0.250是部署集群是配置的VIP。
mysql -h192.168.0.250 -P3323 -uroot -proot #提示mysql命令不存在时,请先执行source /etc/profile.d/mysql.sh
use hotdb
drop table if exists tb1;
create table tb1(id int auto_increment,name varchar(24),country int,primary key(id));
insert into tb1(name,country) values (1,1),(2,1),(3,1),(4,1),(5,1),(6,1),(7,1),(8,1),(9,2),(10,2),(11,2),(12,2),(13,2) ,(14,2) ,(15,2) ,(16,2) ,(17,3) ,(18,3) ,(19,3) ,(20,3) ,(21,3) ,(22,3) ,(23,3) ,(24,3);
select * from tb1 order by id;
select country,count(*) from tb1 group by country;
quit
HotDB独有命令,主要是用于查看各数据节点数据分布情况,感兴趣的朋友可以执行下
当然,为了查看每个节点的状况,你还可以使用hotdb_root或hotdb_datasource账号连接到部署的mysqld存储节点中查看每个节点里面的数据。
l set show_dnid=1;命令可以将简单的select语句取出的记录加上其所在数据节点编号列DNID
我们可以看到记录分别存储在1,2,这2个数据节点中
mysql -h192.168.0.250 -P3323 -uroot -proot
use hotdb
drop table if exists tb1;
create table tb1(id int auto_increment,namevarchar(24),country int,primary key(id));
insert into tb1(name,country) values (1,1),(2,1),(3,1),(4,1),(5,1),(6,1),(7,1),(8,1),(9,2),(10,2),(11,2),(12,2),(13,2),(14,2) ,(15,2) ,(16,2) ,(17,3) ,(18,3) ,(19,3) ,(20,3) ,(21,3) ,(22,3) ,(23,3),(24,3);
set show_dnid=1;
select * from tb1 order by id;
quit
set show_dnid=1;加上setmerge_result=0;命令,还可以查看每个节点执行SQL的结果
我们看到每个数据节点的不同国家的记录数
mysql -h192.168.0.250 -P3323 -uroot -proot
use hotdb
drop table if exists tb1;
create table tb1(id int auto_increment,namevarchar(24),country int,primary key(id));
insert into tb1(name,country) values (1,1),(2,1),(3,1),(4,1),(5,1),(6,1),(7,1),(8,1),(9,2),(10,2),(11,2),(12,2),(13,2),(14,2) ,(15,2) ,(16,2) ,(17,3) ,(18,3) ,(19,3) ,(20,3) ,(21,3) ,(22,3) ,(23,3),(24,3);
set show_dnid=1;
set merge_result=0;
select country,count(*) from tb1 group bycountry;
quit
hint语法,会直接绕过计算节点的结果处理,直接下发给每个mysqld存储节点执行,并且不合并数据
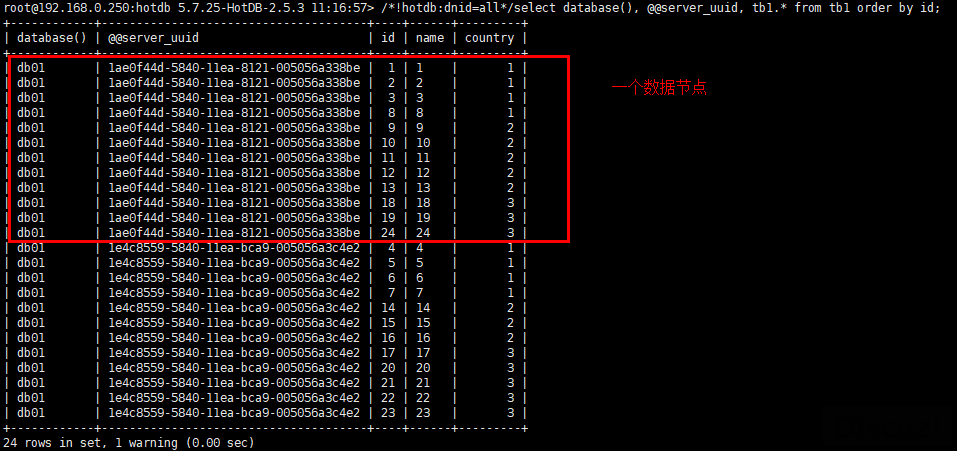
我们可以看到hotdb.tb1这张表实际上按照我们的设定,保存为db01.tb1、db01.tb1这2张表
mysql -h192.168.0.250 -P3323 -uroot -proot
use hotdb
drop table if exists tb1;
create table tb1(id int auto_increment,namevarchar(24),country int,primary key(id));
insert into tb1(name,country) values(1,1),(2,1),(3,1),(4,1),(5,1),(6,1),(7,1),(8,1),(9,2),(10,2),(11,2),(12,2),(13,2),(14,2) ,(15,2) ,(16,2) ,(17,3) ,(18,3) ,(19,3) ,(20,3) ,(21,3) ,(22,3) ,(23,3),(24,3);
/!hotdb:dnid=all/select database(),@@server_uuid, tb1.* from tb1 order by id;
quit
8.HotDB表信息入门指引8.1 基本了解
分布式数据库要能正常存储数据,就要知道表如何存储,HotDB当前采用的设计策略是人为指定哪张表以怎么样的规则存储在哪些数据节点中。这里说的人为指定存储方式,指的就是配置表信息,即告诉HotDB该如何存储接下来要创建的对应表。
当前,决定表如何存储的方式,有三种:
1) 不在管理平台配置表信息,直接在3323端口执行常规create table 语句,那么表按照autocrc32分片规则分布到表所在逻辑库的默认数据节点;
2) 不在管理平台配置表信息,直接在3323端口执行带有HotDB分片语法的create table语句,那么表按照HotDB分片语法存储;
3) 在管理平台配置表信息,同步加载后,在3323端口执行常规create table 语句,那么表按照配置的表信息存储。
执行create语句创建表之前,通常建议使用方式3先配置表信息。而对于刚接触HotDB的朋友,可以直接使用方式1完成建表,后续对分片不满意时可以通过管理平台在线分片方案变更功能在线修改分片规则。至于2的语法,大家可以参考HotDB官方文档《【标准】功能使用手册》中“SQL语法支持”章节的“计算节点语法特殊功能”小节。
更多关于分片规则的信息,可以参考HotDB官方文档《【标准】功能使用手册》中“快速配置HotDB Server”章节的“添加分片规则”、“添加表信息”小节,同时可以参考《【管理平台】功能使用手册》,“配置”章节的“分片规则”、“表信息”小节。
本文对方式1和3做简单演示。
8.2 演示
- 先在管理平台“配置”》》“表信息”》》“添加表信息”界面,配置即将create的3个表automodtb1、automodtb2、automodtb3分别为以country、id、name作为分片字段的auto_mod自动分片表。按如下方式填写后,点击“生成预览”,“保存”。注意填写说明“表名称与分片字段使用英文冒号间隔,未使用冒号,取默认分片字段”。
- 随后在管理平台“配置”》》“表信息”》》“添加表信息”界面,配置即将create的1个表globaltb1为全局表。按如下方式填写后,点击“生成预览”,“保存”。
- 此时,我们应该能在“表信息”界面看到我们设定的4个表信息,点击“动态加载”,使表信息配置立即生效。
- create表,并验证表的存储方式
automodtb1以country为分片字段,列散到2个数据节点中
mysql -h192.168.0.250 -P3323 -uroot -proot
use hotdb
drop table if exists automodtb1;
create table automodtb1(id intauto_increment,name varchar(24),country int,primary key(id));
insert into automodtb1(name,country) values(1,1),(2,1),(3,1),(4,1),(5,1),(6,1),(7,1),(8,1),(9,2),(10,2),(11,2),(12,2),(13,2),(14,2) ,(15,2) ,(16,2) ,(17,3) ,(18,3) ,(19,3) ,(20,3) ,(21,3) ,(22,3) ,(23,3),(24,3);
set show_dnid=1;
select * from automodtb1 order by id;
quit
automodtb2以id为分片字段,列散到3个数据节点中
mysql -h192.168.0.250 -P3323 -uroot -proot
use hotdb
drop table if exists automodtb2;
create table automodtb2(id intauto_increment,name varchar(24),country int,primary key(id));
insert into automodtb2(name,country) values (1,1),(2,1),(3,1),(4,1),(5,1),(6,1),(7,1),(8,1),(9,2),(10,2),(11,2),(12,2),(13,2),(14,2) ,(15,2) ,(16,2) ,(17,3) ,(18,3) ,(19,3) ,(20,3) ,(21,3) ,(22,3) ,(23,3),(24,3);
set show_dnid=1;
select * from automodtb2 order by id;
quit
globaltb1在2个数据节点中,都有全部的表数据
mysql -h192.168.0.250 -P3323 -uroot -proot
use hotdb
drop table if exists globaltb1;
create table globaltb1(id int auto_increment,namevarchar(24),country int,primary key(id));
insert into globaltb1(name,country) values(1,1),(2,1),(3,1),(4,1),(5,1),(6,1),(7,1),(8,1),(9,2),(10,2),(11,2),(12,2),(13,2),(14,2) ,(15,2) ,(16,2) ,(17,3) ,(18,3) ,(19,3) ,(20,3) ,(21,3) ,(22,3) ,(23,3),(24,3);
set show_dnid=1;
select * from globaltb1 order by id;
set merge_result=0;
/!hotdb:dnid=all/select database(), country,count(*)from globaltb1 group by country;
quit

unconfigtb1以auto_crc32规则,列散到逻辑库hotdb默认的分片节点中
mysql -h192.168.0.250 -P3323 -uroot -proot
use hotdb
drop table if exists unconfigtb1;
create table unconfigtb1(id intauto_increment,name varchar(24),country int,primary key(id));
insert into unconfigtb1(name,country) values(1,1),(2,1),(3,1),(4,1),(5,1),(6,1),(7,1),(8,1),(9,2),(10,2),(11,2),(12,2),(13,2),(14,2) ,(15,2) ,(16,2) ,(17,3) ,(18,3) ,(19,3) ,(20,3) ,(21,3) ,(22,3) ,(23,3),(24,3);
set show_dnid=1;
select * from unconfigtb1 order by id;
quit

如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞0作者其他文章
评论 0 · 赞 5
评论 0 · 赞 0
评论 0 · 赞 2
评论 2 · 赞 3
评论 0 · 赞 1
添加新评论0 条评论