学习笔记:DB2 9 基础
1、DB2 的各个版本从低到高依次为:
DB2 Everyplace
每个版本都包含前一个版本的所有特性和功能,并添加了新特性和新功能。
DB2 在 AIX、Windows 和 UNIX 、Linux 平台上的代码大约有90%是相同的,另有10%的专用代码,用于使数据库和底层操作系统紧密集成。
2、DB2 Everyplace
主要用于移动计算。
移动计算的真正力量并不在于移动设备本身,而是在于能够利用来自其他来源的数据。
DB2 Everyplace 不仅仅是一种移动计算基础设施。它是一个完整的环境,包含了构建、部署和支持强大的电子商务应用程序所需的工具。DB2 Everyplace 提供一个 “指纹” 引擎(大约 200 KB),其中包含所有的安全特性,比如表加密和提供高性能的高级索引技术。
DB2 Personal 包含 DB2 Express 的所有特性,但是有一个例外:远程客户机无法连接运行这个DB2 版本的数据库。
4、DB2 Express - C
DB2 Express - C 其实 不算是 DB2 系列的一个版本,但是它提供了 DB2 Express 的大多数功能。2006 年 1 月,IBM 发布了这个特殊的 DB2 免费版本,可以用于基于 Linux 和 Windows 的操作系统。
5、DB2 Express Edition
6、DB2 Workgroup Edition
7、DB2 Enterprise Edition
8、Data Enterprise Developer Edition
9、DB2 客户机
10、DB2 Connect
11、DB2 Data WareHouse Enterprise
其实,DB2 Data WareHouse Enterprise Edition 就是DB2 Enterprise Edition 的群集(Clusters)版本,并且提供了丰富的数据仓库工具(包含了数据的采集、加工、存储、展现、挖掘等各个方面)
待续……
--学习笔记:DB2 9 基础
--彭建军
--最新更新时间:2006-11-13 16:29
----------------------------------------------------------------------
DB2 9 基础 第 1 部分:DB2 规划
二、DB2 工具
1、DB2 中包含的工具其实就是大多数 DB2 特性提供的图形界面,可以帮助您节省时间并减少错误。
2、DB2 工具是 DB2 Client 的组成部分。在安装 DB2 服务器时,实际上也安装了 DB2 Client 的所有组件。
3、DB2 工具实际上分成两大类:
Control Center(CC):主要用来管理 DB2 服务器。有其他几个集成的中心,可以从 Control Center 启动。
Configuration Assistant(CA):用来设置客户机/服务器通信和维护注册表变量等等。稍后我们会进一步了解 CA。
4、在任何 DB2 工具中都应该能够找到 6 种基本特性:
Wizards、Generate DDL、Show SQL/Show Command、Show Related、Filter 和 Help。(详细说明见后)
5、向导(Wizards)
向导对于初学者和专家级 DB2 用户都非常有用。向导带领用户每次一步地执行每个任务,并在适当的时候对设置提出建议,从而帮助用户完成特定的任务。向导可以通过 Control Center 和 Configuration Assistant 启动。
6、顾问(advisor)
一些特殊的向导不只是对完成任务提供帮助,还能够提供建议型的功能,DB2 称它们为顾问。
顾问是 IBM 推进自动化计算的措施之一,其目标是使软件和硬件更加 “聪明”(自己进行管理和资源调优)!与某些厂商不同,DB2 中的顾问在每个 版本中都是免费提供的,包括 DB2 Express - C。
7、生成数据字典(Generate DDL)
Generate DDL 功能允许您重新生成数据定义语言(Data Definition Language,DDL)、在对象上重建特权所需的授权语句、存储对象的表空间、节点组、缓冲池、数据库统计信息和其他许多构成数据库基础的东西(除了数据之外),还可选择将它们保存到一个脚本文件中。
在点击 Generate DDL 选项时,实际上是运行 db2look DB2 系统命令。你可以使用该命令迅速建立目标测试环境,但是需要注意,该命令并不能迁移数据。需要迁移数据可以使用 LOAD、IMPORT或者DB2MOVE实用程序。
8、显示命令(Show SQL/Show Command)
如果一个工具生成 SQL 语句或 DB2 命令,那么在这个工具的界面中点击 Show SQL 或 Show Command 按钮就可以进行查看了。
可以将这个特性返回的信息保存为脚本,以便在以后重用(这样就不必重新输入它)或者调度它在以后执行,还可以利用它更好地理解界面背后发生的情况。
9、显示相关(Show Related)
Show Related 特性显示表、索引、视图、别名、触发器、表空间、用户定义的函数(UDF)和用户定义的类型(UDT)之间的直接关系。
通过查看相关的对象,可以更好地理解数据库的结构,了解数据库中现有的对象以及它们之间的关系。例如,如果想删除一个有相关视图的表,Show Related 特性会识别出在删除这个表之后哪些视图会失效。
10、过滤(Filter)
可以对任何 DB2 工具的内容面板中显示的信息进行过滤。还可以对查询返回的信息进行过滤(比如限制结果集中的行数)。
可以使用这个过滤器快速轻松地找到您希望操作的数据库对象(当您的业务表有上千个的时候,过滤就显得非常重要了)。
11、帮助(Help)
DB2 工具使用 Eclipse 帮助引擎提供了丰富的帮助信息。
DB2 帮助是面向任务的,因此应该很容易找到执行特定任务(例如,创建数据库)所需的信息。
12、DB2 处理程序简介:
DB2 Command Line Processor(DB2 CLP)是所有 DB2 产品中都有的,可以使用这个应用程序运行 DB2 命令、操作系统命令或SQL 语句。用这个工具调用 DB2 命令有点儿麻烦。但是,DB2 CLP 可以成为强大的工具,因为它能够将经常使用的命令或语句序列存储在批处理文件中,可以在必要的时候运行这些批处理文件。
有一种模式允许用户不必在命令前面加上关键字 db2,在这个教程中将这种模式称为交互 模式的 DB2 CLP。DB2 CLP 允许交互地输入 DB2 命令,而不必使用 db2 前缀来告诉操作系统您打算输入 DB2 命令。但是,如果希望输入操作系统命令,那么就必须在前面加上惊叹号(!),也称为 bang 键。例如,在 DB2 CLP 中,如果想运行 dir 命令,就输入 !dir。
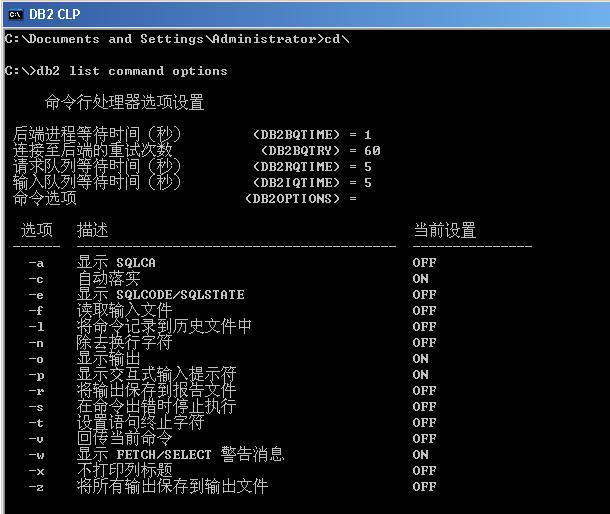
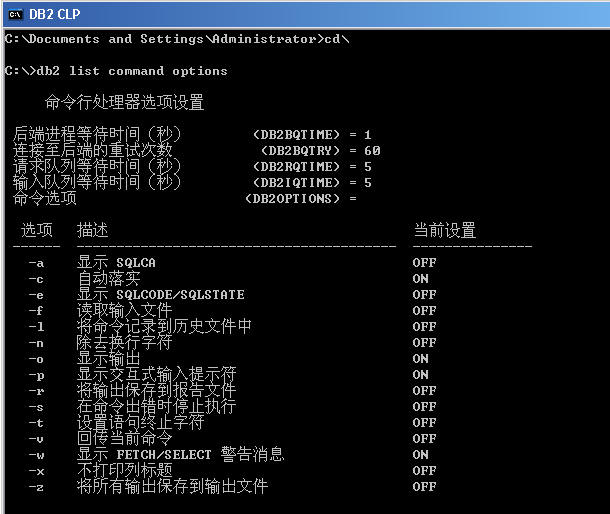
在 Windows 系统下,可以在 运行 界面中键入 db2cmd 或者 db2cw 调出 DB2 CLP界面。可以键入LIST COMMAND OPTIONS 调出其选项设置。如下图:

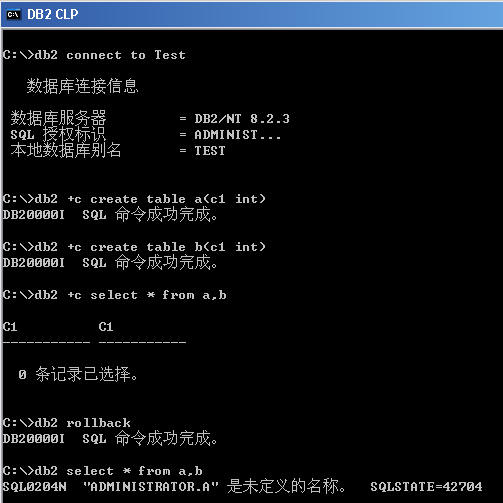
一个有趣的小例子!在默认情况下,自动提交特性是打开的(-c)。这个选项指定每个语句是否自动提交或回滚。如果一个语句成功了,它就和它前面执行的关闭了自动提交(+c 或 -c-)的所有成功语句一起提交。但是,如果它失败了,它就和它前面执行的关闭了自动提交的所有成功语句一起回滚。如果这个语句关闭了自动提交,就必须显式地执行提交或回滚命令。在下图中,在命令行上修改了自动提交特性的值来演示这个过程。如下图:

不知道细心的你发现什么地方有趣了吗?呵呵。
您的操作系统可能对在一个语句中可以读取的最大字符数量有限制(即使命令行在显示器上转入下一行)。为了在输入长语句时解决这个限制,可以使用续行字符()。下图是一个示例:

如果使用 DB2 CW 输入命令,那么下面这些特殊字符会导致问题:
$ & *( ) ; < > ? ' "
操作系统 shell 可能会错误地解释这些字符。解决方法是,将整个语句或命令放在引号中,从而表示希望由 DB2 解释系统操作符而不是由操作系统进行解释。
待续……
--学习笔记:DB2 9 基础 - 2
--彭建军
--最新更新时间:2006-11-15 14:33
----------------------------------------------------------------------
1、控制中心(Control Center) 概述
打开控制中心的快捷方式:db2cc
2、复制中心(Replication Center)概述
使用 DB2 Replication Center(DB2 RC)管理 DB2 数据服务器和其他关系数据库(DB2 或非 DB2)之间的复制。在 DB2 RC 中,可以定义复制环境,将来自一个位置的指定的修改应用于另一个位置,以及对两个或多个位置中的数据进行同步。
打开复制中心的快捷方式:db2rc
注意:Q 复制是在 WebSphere MQ 系列产品上构建的应用。
3、卫星管理中心(Satellite Administration Center)概述
使用 DB2 Command Editor 构造和执行 DB2 命令和 SQL 语句,以及查看 SQL 语句的访问计划的图形表示。
打开命令编辑器的快捷方式:db2ce
注意,命令编辑器不支持撤销(Ctrl + Z)哦
关于命令编辑器的一些详细说明:
命令(Commands)
访问计划(Access Plan)
允许查看在这个编辑器中运行过的任何可解释语句的访问计划。在 DB2 编译 SQL 语句时,它会自动地生成访问计划。可以使用这些信息调优查询来获得最好的性能。如果在一个操作中指定多个语句,那么只为第一个语句创建访问计划。
5、任务中心(Task Center)概述
使用 DB2 Task Center(DB2 TC)运行任务(立即运行或者根据调度计划运行)以及通知相关人员任务完成了。
任务 是一种附带相关的失败或成功条件、调度计划和通知的脚本。脚本可以包含 DB2、SQL 或操作系统命令。
打开任务中心的快捷方式:db2tc
6、健康中心(Health Center)概述
使用 DB2 Health Center(DB2 HC)监视 DB2 环境的状态并对它做必要的修改。
在使用 DB2 时,监视器会连续跟踪一组健康状态指示。如果健康状态指示的当前值超过了警告(warning)或警报(alarm)所定义的可接受操作范围,健康状态监视器会产生健康状态警报。DB2 附带一组预定义的阈值,可以对这些阈值进行定制。例如,可以定制分配给特定堆的内存量的警报或警告阈值,或者在排序溢出到硬盘时进行通知,等等。
打开健康中心的快捷方式:db2hc
7、日志查看(DB2 Journal)概述
DB2 Journal 显示关于任务、数据库活动和操作、Control Center 操作、消息、出现的健康状态警报等等的历史信息。
这个工具中有四个选项卡,它们都向 DBA 提供有价值的信息:Task History、Database History、Messages、Notification Log。
8、许可证中心(License Center)概述
DB2 License Center 显示系统上安装的 DB2 产品的 DB2 许可证和使用信息。还允许配置系统来进行适当的许可证监视。可以使用DB2 License Center 添加新的许可证、设置授权用户策略、将试用许可证升级到生产许可证等等。还可以在命令行上使用 db2licm 命令控制 DB2 许可证。
9、信息中心(Information Center)概述
打开命令编辑器的快捷方式:db2ic
注意,信息中心需要从IBM提供的光碟进行安装,否则,信息中心将指向IBM 的在线信息中心。
Configuration Assistant(CA)允许维护应用程序可以连接和管理的数据库的列表。它主要用来进行客户机配置。
在 CA 中,可以操作现有的数据库、添加新数据库、绑定应用程序、设置客户机配置和注册表参数以及导入和导出配置文件。
打开配置助手的快捷方式:db2ca
待续……
四、其他 DB2 工具
1、虚拟执行计划(Visual Explain)
Visual Explain 可以将解释的 SQL 语句的访问计划显示为图形。可以使用从图中获得的信息调优 SQL 查询来获得更好的性能。Visual Explain 还允许动态地解释 SQL 语句并查看产生的访问计划图。
DB2 优化器选择访问计划,Visual Explain 显示这个计划。在计划图中,表和索引(以及对它们的操作)表示为节点,数据流表示为节点之间的链接。
Visual Explain 最出色的地方是,甚至不必运行查询就能够获得需要的信息。例如,假设您怀疑某个查询编写得很差;可以使用 Visual Explain 以图形化方式查看这个查询的开销,而不需要实际运行它。
2、快照(Snapshot) 和 事件监视器(Event Monitor)
DB2 中提供的两个实用程序可以帮助您更好地了解自己的系统以及操作对它的影响。
Snapshot Monitor 捕捉特定时间点上的数据库信息。您可以决定这些时间点之间的间隔和将捕捉的数据。Snapshot Monitor 可以帮助分析性能问题、调整 SQL 问题并根据限制或阈值识别异常情况。在 DB2 中,可以使用 SQL UDF 或动态地使用 C API 将快照信息放进 DB2 表。
Event Monitor 允许记录特定事件发生时的数据库状态,从而分析资源使用情况。例如,可以使用 Event Monitor 了解完成一个事务花费了多长时间,或者一个 SQL 语句使用的可用 CPU 资源的百分数。
3、工具设置(Tool Settings)
Tools Settings 笔记本可以用来定制 DB2 图形工具以及它们的一些选项。
4、DB2 Governor
DB2 Governor 可以监视针对数据库运行的应用程序的行为,并可以根据在 Governor 的配置文件中指定的规则修改某些行为。Governor 实例由一个配置文件和一个或多个守护进程组成。启动的每个 Governor 实例专门针对数据库管理程序的一个实例。
5、DB2开发环境(DB2 Developer Workbench)
DB2 9 有一个全新的集成开发环境(IDE),它称为 DB2 Developer Workbench(DB2 DWB),是专门为帮助 DBA 和开发人员为数据库开发业务逻辑而设计的。DB2 9 DWB 替代了 DB2 8 Development Center(DB2 DC),而 DB2 DC 是 DB2 7 Stored Procedure Builder(DB2 SPB)的后续版本。
DB2 DWB 是在 Eclipse 平台上完全重新编写的,而 DB2 DC 是基于 Java-Swing 类的。这种新的架构提高了这个工具的可伸缩性和生产效率。与 DB2 DC 不同,DB2 DWB 是一个可单独安装的产品(它是免费的)。必须用 DB2 客户机单独下载和安装它。DB2 DWB 在 DB2 9 中是单独安装的,所以它可以更新得比数据服务器本身更频繁。
6、内存可视化器(Memory Visualizer)
Memory Visualizer 帮助 DBA 逐个实例地了解系统的内存分配情况。
这个工具监视的高层内存成分包括:数据库管理程序共享的内存、数据库全局内存、应用程序全局内存、代理/应用程序共享的内存和代理私有内存。每个高层成分划分为低层成分,这些成分决定内存如何分配和释放。例如,在数据库管理程序启动时、数据库被激活时以及应用程序连接数据库时分配和释放内存。
7、管理存储器(Storage Management)
DB2 有一个 Storage Management 工具,它帮助 DBA 了解他们的存储需求和可能需要考虑的事项。DB2 9 提供了自动化的存储管理,可以自动地使需要更多空间的容器增长,甚至管理表空间(这个特性只能用于基于 DMS FILE 的表空间)。
8、不确定事务管理器(In-doubt Transaction Monitor)
In-doubt Transaction Monitor 帮助 DBA 处理处于 in-doubt 状态的全局事务。例如,通信线路中断会导致事务已经准备好,但是还没有提交或回滚。在大多数情况下,不必使用这个工具,只需等待 Transaction Manager 重新进行同步;但是如果您不能等待,那么可以使用 In-doubt Transaction Manager。只有经验丰富的 DBA 才应该这么做 —— 这个工具是为那些确实 知道自己在做什么的人准备的。
打开快捷方式:db2indbt
9、SQL助手(SQL Assist)
SQL Assist 是一个可以用来构建 SELECT、INSERT、UPDATE 和 DELETE 语句的图形化工具。这个工具使用笔记本帮助您对创建 SQL 语句所需的信息进行组织。能够从多个工具和向导中调用 SQL Assist。
10、第一步(First Steps)
First Steps 是一个帮助用户开始使用 DB2 的图形化工具。First Steps 有几个选项;都可以通过点击所需操作旁边的图标来访问。
可以利用 First Steps 创建示例数据库、启动用于管理和连接的 DB2 工具、创建新数据库、检查产品更新、查看产品库、访问应用程序开发资源、在 Web 上寻找更多的 DB2 资源等等。
11、活动监视器(Activity Monitor)
Activity Monitor 可以帮助监视应用程序性能、应用程序并发性、资源消耗和 SQL 语句的使用情况。它可以帮助诊断数据库性能问题(比如等待锁状态),以及调优查询来优化对数据库资源的使用。Activity Monitor 还提供 DB2 自动生成的许多报告。
待续……
五、数据仓库 OLTP 系统可能是一个 Web 订购系统,可以通过 Web 执行交易(比如购买产品)。这些应用程序的特征是进行细粒度的单行查询,可能更新少量的记录。与之相反,BI 类型的查询执行大型的表扫描,因为它们尝试在大量数据中寻找数据模式。如果要求您汇总西部地区的所有销售,这就是仓库查询。 简单地说,OLTP 是简短的查询,而 BI 是对大量数据进行搜索和汇总以便进行报告。 这个特性允许在单一服务器上或者跨服务器集群对数据库进行分区。DB2 Data Partitioning 为企业提供了支持超大型数据库(这是数据仓库环境中的常见情况)所需的可伸缩性,并可以处理涉及复杂工作负载和高并行性的管理任务。 DWE Design Studio 是通过包含和扩展一些基于 Eclipse 的 Rational Data Architect(RDA)建模功能形成的,这是一个针对 BI 解决方案的开发环境。Design Studio 将以下任务集成在一个统一的图形化环境中:物理数据建模(RDA)、DB2 基于 SQL 的仓库构造、OLAP 多维数据集建模和数据挖掘建模。这个设计工具使设计人员能够连接源数据库和目标数据库、对物理数据模型进行反向工程、构建 DB2 基于 SQL 的数据流和挖掘流、设置 OLAP 多维数据集以及准备将应用程序部署到运行时系统上。因为它是基于 Eclipse 框架的,这个工具看起来与DB2 Developer Workbench 相似。 为了支持端到端业务智能化解决方案,DB2 DWE 提供了用于仓库构建和维护的基础设施,包括用于应用程序设计、部署、执行和管理的工具。 DB2 DWE Administration Console 是一个用于管理和监视 BI 应用程序的基于 Web 的应用程序。安装在 WebSphere Application Server 上之后,DWE Administration Console 使用 Web 客户机访问和部署在 DWE 中建模和设计的数据仓库应用程序。这个控制台使用 WebSphere 安全模型,使用户能够以管理员、经理和操作员的角色从统一的控制台页面执行各种管理任务。 以前称为 DB2 Cube Views。通过使用 DWE Design Studio 和 Administration Console 中的 OLAP 功能,用户可以创建、操作、优化、部署、导入或导出多维数据集模型、多维数据集和在 OLAP 分析中使用的其他元数据对象。 通过使用 DB2 DWE 数据挖掘特性,可以发现数据中隐藏的关系,而不需要将数据导出到特殊的数据挖掘计算机上或者借助于少量数据样本。DB2 DWE 为一些建模操作提供了 DB2 扩展:市场篮分析、市场分割、分析等等。 DB2 Query Patroller 是 DWE 的查询工作负载管理特性。 DB2 9 基础 第 1 部分:DB2 规划 至此结束,下一篇文章将介绍 DB2 安全性 的相关知识。 三、DB2 授权 ● 用户被授予的权限级别 ● 允许用户运行的命令 ● 允许用户读取和/或修改的数据 ● 允许用户创建、修改和/或删除的数据库对象 授权由特权组和高级数据库管理程序(实例级)维护和实用操作组成。在 DB2 可用的 5 种权限中,SYSADM、SYSCTRL 和 SYSMAINT 是实例级权限。这意味着它们的范围包含实例级命令以及针对这个实例中的所有数据库的命令。这些权限只能分配给组;可以通过 DBM CFG 文件分配这些权限。 拥有 SYSCTRL 权限的用户可以在实例中执行所有管理和维护命令。但是,与 SYSADM 用户不同,他们不能访问数据库中的任何数据,除非他们被授予了访问数据所需的特权。SYSCTRL 用户可以对实例中的任何数据库执行的命令示例如下: ● db2start/db2stop ● db2 create/drop database ● db2 create/drop tablespace ● db2 backup/restore/rollforward database ● db2 runstats(针对任何表) ● db2 update db cfg for database dbname [示例]-[拥有 SYSADM 权限的用户可以使用以下命令将 SYSCTRL 分配给一个组]: 拥有 SYSMAINT 权限的用户可以发出的命令是拥有 SYSCTRL 权限的用户可以发出的命令的子集。SYSMAINT 用户只能执行与维护相关的任务。 ● drop database ● drop/create tablespace ● backup/restore database ● update db cfg for database db name 但是,他们可以执行以下任务: ● db2 create/drop table ● db2 grant/revoke(任何特权) ● db2 runstats(任何表) DBADM 用户还被自动地授予对数据库对象及其内容的所有特权。 1、数据库和对象特权 ● CREATETAB: 用户可以在数据库中创建表。 ● BINDADD: 用户可以使用 BIND 命令在数据库中创建包。 ● CONNECT: 用户可以连接数据库。 ● CREATE_NOT_FENCED: 用户可以创建 unfenced 用户定义函数(UDF)。 ● IMPLICIT_SCHEMA: 用户可以在数据库中隐式地创建模式,而不需要使用 CREATE SCHEMA 命令。 ● LOAD: 用户可以将数据装载进表中。 ● QUIESCE_CONNECT: 用户可以访问处于静默(quiesced)状态的数据库。 ● CREATE_EXTERNAL_ROUTINE: 用户可以创建供应用程序和数据库的其他用户使用的过程。 一、DB2 数据库的组成 1、创建测试数据库 DB2 9 基础 第 3 部分:访问 DB2 数据 三、对 DB2 数据库进行编目 五、小结 一、结构化查询语言(Structured Query Language,SQL)
1、数据库应用程序有两种主要类型:在线事务处理(online transactional processing,OLTP)和数据仓库,数据仓库包括在线分析处理(online analytical processing,OLAP)和数据挖掘应用程序。DB2 9 同时适用于这两种应用程序。
2、OLTP 系统与商业智能(Business Intelligence,BI)数据仓库系统的区别是什么?
区别在于访问数据的典型查询。
3、在数据仓库中可以存储信息性数据 —— 这些数据是从操作性数据中提取出来的,然后为帮助最终用户决策进行了转换和清理。例如,数据仓库工具可能会复制操作性数据库中的所有销售数据,执行计算来汇总数据,并将汇总的数据写入一个与操作性数据库分开的数据库中。最终用户可以查询这个独立的数据库(仓库),而不会影响 OLTP 数据库。
4、用于数据仓库的 DB2 产品:
DB2 有两个 Data Warehouse Editions(DB2 DWE),用以提供一整套数据仓库工具和解决方案。
DB2 DWE 分为 Base 和 Enterprise 两个版本。
5、DB2 DWE 是在强大的 DB2 Enterprise 9 产品上构建的并扩展了它的功能,提高了数据仓库和分析特性的性能和易用性,帮助进行实时探察和决策的用户获得需要的信息。DB2 DWE 特性包括用于仓库管理、分析应用程序开发、OLAP、数据挖掘以及超大型数据库(VLDB)查询和资源管理的工具。
6、DB2 DW Enterprise Edition 中包含的产品:
(1)、DB2 Enterprise
(2)、DB2 Data Partitioning 特性
(3)、DB2 Data Warehouse Edition Design Studio
(4)、SQL Warehousing Tool
SQL Warehousing Tool 解决了 DB2 数据仓库环境中的数据集成问题。
(5)、DB2 Data Warehouse Edition Administration Console
(6)、DB2 Data Warehouse Edition OLAP Acceleration
(7)、DB2 Data Warehouse Edition Data Mining
(8)、DB2 Data Warehouse Edition Data Visualization Feature
用来显示创建的挖掘模型。
(9)、DB2 Alphablox analytics
DB2 Alphablox 提供了快速创建基于 Web 的定制应用程序的能力,使应用程序能够适应公司的基础设施并能够为公司防火墙内外的用户服务。用 DB2 Alphablox 构建的应用程序在标准 Web 浏览器中运行,允许从客户计算机执行实时的高度可定制的多维分析。DB2 Alphablox 与 DWE Cube Views 紧密集成,DWE Cube Views 提供常用的元数据并为 Alphablox 多维分析进行数据库优化。
(10)、DB2 Data Warehouse Edition Query Workload Management Feature
DB2 Query Patroller 是一个强大的查询管理系统,可以使用它前瞻性地动态控制 DB2 数据库的查询流。
1、数据库安全涉及的问题
数据库安全是当今最重要的问题。您的数据库可能允许顾客通过互联网购买产品,它也可能包含用
来预测业务趋势的历史数据;无论是哪种情况,公司都需要可靠的数据库安全计划。
数据库安全计划应该定义:
● 允许谁访问实例和/或数据库
● 在哪里以及如何检验用户的密码
● 用户被授予的权限级别
● 允许用户运行的命令
● 允许用户读取和/或修改的数据
● 允许用户创建、修改和/或删除的数据库对象
2、DB2 中有三种主要的安全机制,可以帮助 DBA 实现数据库安全计划:身份验证(authentication)、授权(authorization) 和特权(privilege)。
身份验证(authentication)是用户在尝试访问 DB2 实例或数据库时遇到的第一种安全特性。DB2 身份验证与底层操作系统的安全特性紧密协作来检验用户 ID 和密码。DB2 还可以利用 Kerberos 这样的安全协议对用户进行身份验证。
授权(authorization)决定用户和/或用户组可以执行的操作以及他们可以访问的数据对象。用户执行高级数据库和实例管理操作的能力由指派给他们的权限决定。在 DB2 中有 5 种不同的权限级别:SYSADM、SYSCTRL、SYSMAINT、DBADM 和 LOAD。
特权(privilege)的粒度比授权要细,可以分配给用户和/或用户组。特权定义用户可以创建或删除的对象。它们还定义用户可以用来访问对象(比如表、视图、索引和包)的命令。DB2 9 中新增的一个概念是基于标签的访问控制(LBAC),它允许以更细的粒度控制谁有权访问单独的行和/或列。
3、客户机、服务器、网关和主机
数据库服务器 是数据库实际所在的机器(在分区的数据库系统上可能是多台机器)。DB2 数据库客户机 是对服务器上的数据库执行查询的机器。这些客户机可以是本地的(驻留在与数据库服务器相同的物理机器上),也可以是远程的(驻留在单独的机器上)。
如果数据库驻留在运行 AS/400(iSeries)或 OS/390(zSeries)的大型机上,它就称为主机 或主机服务器。网关 是一台运行 DB2 Connect 产品的机器。DB2 客户机可以通过网关连接驻留在主机上的 DB2 数据库。网关也称为 DB2 Connect 服务器。安装了 Enterprise Server Edition 产品的系统也内置了 DB2 Connect 功能。
1、什么时候进行 DB2 身份验证
● 在哪里以及如何检验用户的密码
在发出 attach 或 connect 命令时,它在底层操作系统安全特性的帮助下完成这个任务。attach 命令用来连接 DB2 实例,connect 命令用来连接 DB2 实例中的数据库。
[示例]-[更改用户口令]:
db2 connect to DB_Name user UserName using OldPassword new NewPassword confirm NewPassword
2、DB2 身份验证类型
DB2 使用身份验证类型 决定在什么地方进行身份验证。例如,在客户机 - 服务器环境中,是客户机还是服务器检验用户的 ID 和密码?在客户机 - 网关 - 主机环境中,是客户机还是主机检验用户的 ID 和密码?
DB2 9 能够根据用户是试图连接数据库,还是执行实例连接和实例级操作,指定不同的身份验证机制。在默认情况下,实例对于所有实例级和连接级请求使用一种身份验证类型。这由数据库管理程序配置参数 AUTHENTICATION 来指定。V9.1
3、在服务器上设置身份验证
[示例]:
db2 update dbm cfg using authentication server_encrypt
db2stop
db2start
4、在网关上设置身份验证
[示例]:
db2 catalog database myhostdb at node nd1 authentication SERVER
db2 terminate
5、在客户机上设置身份验证
使用 catalog database 命令在客户机上设置身份验证。
注意,如果网关上的身份验证类型设置为 SERVER,那么从客户机发出的命令会导致客户机向网关发送未加密的用户 ID 和密码。
如果网关上的身份验证类型设置为 SERVER_ENCRYP,那么用户 ID 和密码在客户机上进行加密,然后再发送到网关,并在网关上进行加密,然后再发送到主机。这是默认的做法。
[示例]:
db2 catalog database myhostdb at node nd1 authentication SERVER
6、处理不可信的客户机
如果服务器或网关将身份验证类型设置为 CLIENT,那么这意味着期望客户机对用户的 ID 和密码进行身份验证。
DB2 V9.1 不支持 Windows 98 或 Windows ME,但是它支持低版本的客户机,所以仍然可能必须处理不可信的 V8 客户机。在 DBM CFG 文件中有两个额外参数,用于在服务器或网关身份验证方法设置为 CLIENT,而不可信的客户机试图连接数据库或 DB2 实例时,决定应该在哪里进行身份验证。这些参数是 TRUST_ALLCLNTS 和 TRUST_CLNTAUTH 参数。
[示例]:
[服务器端执行]:
db2 update dbm cfg using authentication client
db2 update dbm cfg using trust_allclnts yes
db2 update dbm cfg using trust_clntauth server
db2stop
db2start
[客户端执行]:
db2 catalog database sample at node nd1 authentication client
注意,在上面的示例中,如果从任何客户机发出命令 db2 connect to sample ,那么身份验证在客户机上进行。
如果从任何客户机发出命令 db2 connect to sample user test1 using password 那么身份验证在服务器上进行。
7、DB2 的安全插件架构
DB2 V8.2 引入了安全插件的概念。这个概念在 DB2 V9.1 中得到了进一步增强。通过使用标准的 GSS-API 调用,用户可以编写一个安全插件并将对用户 ID 进行身份验证的工作交给一个外部安全程序。这种方式的一个示例是 DB2 本身的 KERBEROS 身份验证。
8、Kerberos 身份验证
Kerberos 身份验证为 DB2 提供了一种无需通过网络发送用户 ID 和密码的用户身份验证方法。Kerberos 安全协议作为第三方身份验证服务执行身份验证,它使用传统的密码术创建一个共享的密钥。这个密钥成为用户的凭证,在请求本地或网络服务时在所有情况下都使用它检验用户的身份。通过使用 Kerberos 安全协议,可以实现对远程 DB2 数据库服务器的单点登录。
在 DB2 中使用 Kerberos 之前,必须在客户机和服务器上启用和支持 Kerberos。为此,必须满足以下条件:
(4). 所有机器必须有同步的时钟。
9、其他身份验证设置
1、DB2 授权控制数据库安全计划的以下方面:
针对特定数据库的 DBADM 和 LOAD 权限可以分配给用户或用户组。可以使用 GRANT 命令显式地分配这些权限。注意,任何提到组成员关系的地方都假设在操作系统级上已经定义了这些用户和组名。
[示例]-[取得权限列表]:
db2 get authorizations
2、获得 SYSADM 权限
DB2 中的 SYSADM 权限就像是 UNIX 上的根权限或 Windows 上的 Administrator 权限。对一个 DB2 实例拥有 SYSADM 权限的用户能够对这个实例、这个实例中的任何数据库以及这些数据库中的任何对象发出任何 DB2 命令。他们还能够访问数据库中的数据以及对其他用户授予或撤消特权或权限。只允许 SYSADM 用户更新 DBM CFG 文件。
SYSADM 权限由 DBM CFG 文件中的 SYSADM_GROUP 参数控制。
[示例]-[向 db2grp1 组授予 SYSADM 权限]:
db2 update dbm cfg using SYSADM_GROUP db2grp1
3、获得 SYSCTRL 权限
db2 update dbm cfg using SYSCTRL_GROUP group name
4、获得 SYSMAINT 权限
拥有 SYSMAINT 权限的用户不能创建或删除数据库或表空间。他们也不能访问数据库中的任何数据,除非他们被显式地授予访问数据所需的特权。
[示例]-[拥有 SYSADM 权限的用户可以使用以下命令将 SYSMAINT 权限分配给一个组]:
db2 update dbm cfg using SYSMAINT_GROUP group name
5、获得 DBADM 权限
DBADM 权限是一个数据库级权限,而不是实例级权限。DBADM 用户对一个数据库有几乎完全的控制能力。DBADM 用户不能执行某些维护或管理任务,比如:
6、获得 LOAD 权限
LOAD 权限是一个数据库级权限,所以它可以被分配给用户和用户组。顾名思义,LOAD 权限允许用户对表发出 LOAD 命令。当用大量数据填充表时,LOAD 命令通常用来替代插入或导入命令,它的速度更快。根据您希望执行的 LOAD 操作类型,仅仅拥有 LOAD 权限可能还不够。可能还需要表上的特定特权。
四、DB2 特权
数据库级特权(针对数据库中的所有对象)和对象级特权(与特定的对象相关联)。
用户可以拥有的数据库级特权有:
对象级特权的信息存储在系统编目视图中。视图名称是 syscat.tabauth、syscat.colauth、syscat.indexauth、syscat.schemaauth、syscat.routineauth 和 syscat.packageauth。
2、显式特权
可以使用 GRANT 和 REVOKE 命令显式地 对用户或组授予或撤消特权。
[示例]-[拥有 SYSADMIN 的用户可以使用下面的命令显示地对用户 test1 授权]:
db2 grant select on table gmilne.org to user test1
db2 grant insert on table gmilne.org to group db2grp1
db2 grant dropin on schema gmilne to all
说明,上例中的 dropin 意为 允许用户删除模式中的对象,同 CreateIn,AlterIn 。
[示例]-[拥有 SYSADMIN 的用户可以使用下面的命令显示地对用户 test1 撤销授权]:
db2 revoke select on table gmilne.org from user test1
db2 revoke insert on table gmilne.org from group db2grp1
db2 revoke dropin on schema gmilne from all
这里需要大家注意,对某一个用户显示授权后,再对该用户所在组撤销权限,那么该用户仍然具有被显示授予的权限。
3、隐式特权
当发出某些命令时,DB2 可能会自动地授予特权,而不需要像前面看到的那样发出显式的 GRANT 语句。
注意,当删除创建的对象时,这些特性会隐式地撤消。但是,当显式地撤消更高级的特权时,不会撤消它们。
当用户创建数据库时,隐式地授予这个用户这个数据库上的 DBADM 权限。获得 DBADM 权限就会隐式地授予 CONNECT、CREATETAB、BINDADD、IMPLICIT_SCHEMA 和 CREATE_NOT_FENCED 特权。即使撤消了 DBADM 权限,这个用户仍然会保留这些特权。
PUBLIC 是一个特殊的 DB2 组,其中包括特定数据库的所有用户。与前面讨论过的其他组不同,PUBLIC 不必在操作系统级进行定义。在默认情况下,会向 PUBLIC 授予一些特权。例如,这个组自动接受数据库上的 CONNECT 特权和编目表上的 SELECT 特权。可以对 PUBLIC 组发出 GRANT 和 REVOKE 命令。
3、间接特权
当数据库管理器执行包 时,可以间接获得特权。包中包含一个或多个 SQL 语句,这些语句已经转换为 DB2 用来在内部执行它们的格式。换句话说,包中包含可执行格式的多个 SQL 语句。如果包中的所有语句都是静态的,那么用户只需要有包上的 EXECUTE 特权,就能够成功地执行包中的语句。
4、基于标签的访问控制
DB2 9 中新增的一个概念是基于标签的访问控制(LBAC)。LBAC 为 DBA 提供了在表的行或列级限制读/写特权的能力。
LBAC 由安全管理员 通过创建安全策略来设置。每个表只能由一个安全策略来控制,但是系统中可以有任意数量的安全策略。设置LBAC 需要几个步骤。必须做的第一件事情是,决定对于您的数据需要什么类型的访问控制。
1、数据库的逻辑、物理和性能特性
DB2 数据库实际上由一个对象集合组成。从用户的角度来看,数据库是一组通常以某种方式相关联的表。
从数据库管理员(DBA,也就是您)的角度来看,数据库比这要复杂一点儿。实际的数据库包含许多物理对象和逻辑对象:
● 表、视图、索引、模式
● 锁、触发器、存储过程、包
● 缓冲池、日志文件、表空间
这些对象中的一部分(比如表或视图)帮助决定如何对数据进行组织。其他对象(比如表空间)涉及数据库的物理实现。最后,一些对象(比如缓冲池和其他内存对象)只处理如何管理数据库性能。
DBA 应该首先关注数据库的物理实现,而不是直接研究所有可能的参数和对象组合。
2、DB2 存储模型
DB2 利用一个逻辑存储模型和一个物理存储模型来处理数据。用户操作的实际数据放在表中。表由行和列组成,用户并不知道数据的物理表示。这一事实有时候称为数据的物理独立性。
表本身放在表空间中。表空间作为数据库与包含实际表数据的容器对象之间的一层。表空间可以包含多个表。
容器 是一个物理存储设备。它可以由目录名、设备名或文件名标识。容器被分配给表空间。表空间可以跨许多容器,这意味着可以突破操作系统对于一个容器可以包含的数据量的限制。
3、表、索引、长字段和表空间
表、索引和长字段(有时候称为二进制大对象,BLOB)是在 DB2 数据库中创建的对象。这些对象映射到表空间,表空间本身映射到物理磁盘存储。
表是数据记录的无序集合。它由列和行组成,行常常也称为记录。表可以是持久的表(基表)、临时的(声明)表或临时的(派生)表。从 DBA 的角度来看,空间都会分配给这些表对象,但是是在不同的表空间中。
索引 是与一个表相关联的物理对象。索引用来在表中实施惟一性(也就是说,确保没有重复的值)以及改进检索信息时的性能。运行SQL(结构化查询语言)语句并不需要索引;但是,如果创建索引来提高查询处理的速度,您的用户会因此受益!
长字段(即 BLOB)是表中的一种数据类型。这种数据类型通常由非结构化数据(图像、文档、音频文件)组成,常常包含大量的信息。如果在表中存储这种类型的数据,就会在删除、插入和操作这些对象时导致过大的开销。所以并不是将它们直接放在表的行中,而是存储一个指针,这个指针链接到一个 Large 表空间(以前称为 Long Field 表空间)。DBA 需要了解这种数据类型,从而创建适当的表空间来包含这些对象。
另一种特殊的数据类型是 XML(eXtensible Markup Language,可扩展标记语言)。XML 这种数据类型可以存储在行中,也可以存储在与 BLOB 对象相似的单独的表空间中。XML 数据类型的独特之处在于,它可以跨一个表中的多个页面,而其他数据类型必须放在与行相同的页面中。DBA 需要利用应用程序设计器来决定表中存储的 XML 对象应该放在常规(数据)页面中,还是放在自己的单独的表空间中。如果检索性能是重要的因素,DBA 应该使用比较大的页面大小并将 XML 列放在与常规数据相同的表空间中。
4、DMS 和 SMS 表空间
表空间是数据库与这个数据库中存储的表之间的逻辑层。表空间在数据库中创建,表在表空间中创建。DB2 支持三种表空间:
● 系统管理的空间(System-Managed Space,SMS):在这里,由操作系统的文件系统管理器分配和管理空间。在 DB2 9 之前,如果不带任何参数创建数据库或表空间,就会导致所有表空间作为 SMS 对象创建。
● 数据库管理的空间(Database-Managed Space,DMS):在这里,由数据库管理程序控制存储空间。这种表空间本质上是一种特殊用途的文件系统实现,可以最好地满足数据库管理程序的需要。
● DMS 的自动存储(Automatic Storage With DMS):自动存储实际上不是一种单独的表空间类型,而是一种处理 DMS 存储的不同方式。DMS 容器需要比较多的维护,在 DB2 V8.2.2 中引入了自动存储,作为简化空间管理的方式。
SMS 表空间需要的维护非常少。但是,与 DMS 表空间相比,SMS 表空间提供的优化选项少而且性能不好。
除了使用 SMS 表空间可以简化管理之外,这两种存储模型之间最显著的差异是表空间的最大大小。如果页面大小为 4k ,那么 SMS 表空间最大存储限制为 64GB,而 DMS 表空间则为 2TB。
5、DMS 与自动存储
DB2 8.2.2 引入了自动存储的概念。自动存储允许 DBA 为数据库设置在创建所有表空间容器时可以使用的存储路径。DBA 不必显式地定义表空间的位置和大小,系统将自动地分配表空间。在 DB2 9 中,数据库在创建时将启用自动存储,除非 DBA 显式地覆盖这个设置。
启用自动存储的数据库有一个或多个相关联的存储路径。表空间可以定义为 “由自动存储进行管理”,它的容器由 DB2 根据这些存储路径进行分配。数据库只能在创建时启用自动存储。对于在最初没有启用自动存储的数据库,不能在以后启用这个特性。同样,对于在最初启用了自动存储的数据库,也不能在以后禁用这个特性。
引入自动存储模型的主要目的是简化 DMS 表空间的管理,同时保持其性能特征。
二、创建数据库
[示例]-[创建数据库]:
CREATE DB Test
数据库的命名规则是:
● 数据库名称可以由以下字符组成:a-z、A-Z、0-9、@、# 和 $。
● 名称中的第一个字符必需是字母表字符、@、# 或 $;不能是数字或字母序列 SYS、DBM 或 IBM。
● 数据库名称或数据库别名是一个惟一的字符串,包含前面描述的一个到八个字母、数字或键盘字符。
2、DB2 创建了什么?
在发出 CREATE DATABASE 命令时,DB2 会创建许多文件。这些文件包括日志文件、配置信息、历史文件和三个表空间。这些表空间是:
● SYSCATSPACE:这是保存 DB2 系统编目的地方,系统编目跟踪与 DB2 对象相关联的所有元数据。
● TEMPSPACE1:DB2 用来放置中间结果的临时工作区域。
● USERSPACE1:默认情况下存放所有用户对象(表、索引)的地方。
所有这些文件都放在默认驱动器上的 DB2 目录中。默认驱动器通常是安装 DB2 产品的卷。
注意!对于从 DB2 8 进行迁移的用户,有一个特殊的注意事项:在 DB2 9 之前,CREATE DATABASE 命令会为上面列出的所有对象创建 SMS 表空间。在 DB2 9 中,所有表空间都将定义为自动存储(DMS)表空间。
3、CREATE DATABASE 命令
DB2 CREATE DATABASE 命令的完整语法可以在 DB2 Command Reference 中找到,这里简要介绍一下几个重要的参数
(1)、数据库位置
CREATE DATABASE 命令的参数之一是 ON path/drive 选项。这个选项告诉 DB2 您希望在哪里创建数据库。如果没有指定路径,就会在数据库管理程序设置(DFTDBPATH 参数)中指定的默认数据库路径上创建数据库。
[示例]-[指定位置创建数据库]:
CREATE DB Test ON D:DB
(2)、表空间和容器
● AUTORESIZE YES
当表空间用光空间时,系统将自动地扩展容器的大小。
● INITIALSIZE 300 M
没有定义初始大小的任何表空间的大小默认为 300 MB。每个容器是 100 MB(有三个存储路径)。
● INCREASESIZE 75 M (或百分数)
当表空间用光空间时,表空间的总空间增加 75 MB。还可以指定一个百分数,在这种情况下,表空间会增长它的当前大小的百分数。
● MAXSIZE NONE
表空间的最大大小没有限制。如果 DBA 希望限制一个表空间可以占用的存储空间,那么可以指定一个最大值。
使用自动存储(AUTOMATIC STORAGE)可以大大简化日常的表空间维护,但是,与重要的大型生产表相关联的表空间就可能需要 DBA 更多地干预。
在没有启用自动存储的数据库中创建表空间时,必须指定 MANAGED BY SYSTEM 或 MANAGED BY DATABASE 子句。使用这些子句会分别创建 SMS 表空间和 DMS 表空间。在这两种情况下,都必须提供容器的显式列表。如果数据库启用了自动存储,那么有另一个选择。可以指定 MANAGED BY AUTOMATIC STORAGE 子句,或者完全去掉 MANAGED BY 子句(这意味着自动存储)。在这种情况下,不提供容器定义,因为 DB2 会自动地分配容器。
创建数据库时,若为指定(SYSCATSPACE、TEMPSPACE1、USERSPACE1)三个表空间的位置,则系统调用参数配置中的默认目录自动创建表空间。
如果创建的数据库使用 SMS 表空间,SYSTEM USING ('container string'),那么容器字符串(container string) 标识一个或多个将属于这个表空间的容器,表空间数据将存储在这些容器中。每个容器字符串可以是绝对的或相对的目录名。如果目录名不是绝对的,它就相对于数据库目录。如果目录的任何部分不存在,数据库管理程序就会创建这个目录。容器字符串的格式取决于操作系统。
如果创建的数据库使用 DMS 表空间,DATABASE USING ( FILE/DEVICE 'container string' number of pages )那么容器字符串标识一个或多个将属于这个表空间的容器,表空间数据将存储在这些容器中。指定容器的类型(FILE 或DEVICE)和大小(按照 PAGESIZE 大小的页面)。大小还可以指定为一个整数,后面跟着 K(表示千字节)、M(表示兆字节)或 G(表示千兆字节)。可以混合指定 FILE 和 DEVICE 容器。对于 FILE 容器,容器字符串必须是绝对或相对的文件名。如果文件名不是绝对的,它就相对于数据库目录。如果目录名的任何部分不存在,数据库管理程序就会创建这个目录。如果文件不存在,数据库管理程序就会创建这个文件并初始化为指定的大小。对于 DEVICE 容器,容器字符串必须是设备名而且这个设备必须已经存在。
重要提示:所有容器必须是在所有数据库上惟一的;一个容器只能属于一个表空间。
● EXTENSIZE
指定数据库可以写到一个容器中的 PAGESIZE 页面数量,达到这个数量之后将跳到下一个容器。
● PREFETCHSIZE number of pages
它指定在执行数据预获取时将从表空间中读取的 PAGESIZE 页面数量。预获取大小还可以指定为一个整数,后面跟着 K、M 或 G。预获取会在查询引用数据之前读取查询所需的数据,这样查询就不需要等待底层操作系统执行 I/O 操作。
(3)、代码页和整理次序
所有 DB2 字符数据类型(CHAR、VARCHAR、CLOB、DBCLOB)都有一个相关联的字符代码页。可以认为代码页是一个对照表,用来将字母数字数据转换为数据库中存储的二进制数据。一个 DB2 数据库只能使用一个代码页。代码页是在 CREATE DATABASE 命令中使用 CODESET 和 TERRITORY 选项设置的。
如果指定选项 COLLATE USING SYSTEM,就根据为数据库指定的 TERRITORY 对数据值进行比较。如果使用选项 COLLATE USING IDENTITY,那么以逐字节的方式使用二进制表示来比较所有值。
(4)、CREATE DB 命令示例
( 1) CREATE DATABASE MY1STDB
( 2) DFT_EXTENT_SZ 4
( 3) CATALOG TABLESPACE MANAGED BY DATABASE USING
( 4) (FILE 'C:CATCATALOG.DAT' 2000, FILE 'D:CATCATALOG.DAT' 2000)
( 5) EXTENTSIZE 8
( 6) PREFETCHSIZE 16
( 7) TEMPORARY TABLESPACE MANAGED BY SYSTEM USING
( 8) ('C:TEMPTS','D:TEMPTS')
( 9) USER TABLESPACE MANAGED BY DATABASE USING
(10) (FILE 'C:TSUSERTS.DAT' 121)
(11) EXTENTSIZE 24
(12) PREFETCHSIZE 48
结合上面的说明,大家应该能搞懂上面命令的意思了吧(有问题欢迎讨论哈)
1、为什么要对数据库进行编目?
如果没有编目信息,应用程序就无法连接数据库!DB2 有多个用来访问数据库的目录。这些目录让 DB2 能够找到已知的数据库,无论它们是在本地系统上,还是在远程系统上。系统数据库目录包含一个列表和指针,它们指出可以找到每个已知数据库的地方。节点目录包含的信息指出如何以及在哪里能够找到远程系统或实例。要在这些目录中放进一个条目,需要使用 CATALOG 命令。要删除条目,应该使用 UNCATALOG 命令。
简单说来,数据库编目就是让你系统上的DB2实例和数据库简单明了。(咳咳,被我说得太简单了)
在创建 DB2 数据库的服务器上通常不需要对它进行编目。但是,要想从客户机访问数据库,客户机就必须先在本地对数据库进行编目,这样应用程序才能访问它。
想查看更多相关信息,可以在 CLP 中输入: DB2 ? Catalog
2、在客户机上进行编目
需要连接 DB2 数据库的用户应该在本地工作站上对数据库进行编目。为此,用户要使用 CATALOG 命令或 DB2 Configuration Assistant(CA)。CA 允许维护应用程序可以连接的一个数据库列表。它对节点和数据库进行编目,而对用户隐藏了这些任务固有的复杂性。
在客户机上对数据库进行编目有三种方法:
● 使用发现的自动配置(一般情况下推荐使用)
● 使用访问配置文件的自动配置(适用于需要大量配置客户机的情况,配置文件都是从服务器 DB2 系统导出,然后导入到每一个客户机的 DB2 系统中)
● 手工配置(命令行 CATALOG NODE/DB 方法是这两者中比较麻烦的,但是它有一个优点:可以将配置步骤保存成脚本,这样就可以在必要时重新进行配置。)
对于不太了解目标数据库明细的情况下,推荐使用 DB2 Configuration Assistant(CA,DB2 配置助手),打开 CA 的快捷方式为: db2ca
四、用 Control Center 操纵 DB2 对象
1、Control Center 是 DB2 管理的中心点。Control Center 向用户提供执行日常数据库管理任务所需的工具。它允许轻松地访问其他服务器管理工具、给出整个系统的清晰的视图、执行远程数据库管理并对复杂的任务提供一步步的帮助。
2、既然是这样,我们为什么还要费那么多力气学习如何从命令行创建数据库?咳咳,答案很简单,某些操作系统,例如 IBM 小型机 AIX 操作系统就不支持 Control Center,所以,命令还是要学习地。
3、在 Control Center 中还有鼠标停留帮助。
另外,可以使用 Control Center 生成 DB2 命令,从而以后在脚本或程序中使用。这个特性允许开发要使用的命令,而不必实际执行它。
可以将 Show Command 按钮作为一种出色的学习工具使用。即使是经验丰富的 DBA 也可以使用 Control Center 生成很少使用的命令!
个人觉得这两点还是非常实用的。
关于 DB2 Control Center 的更多信息可以在工具提供的在线帮助中找到。另外,DB2 Administration Guide 和 DB2 Command Reference 提供了关于数据库特性和功能以及如何设计数据库来获得最佳性能的大量信息。这些书是出色的参考资料,在设计自己的数据库时应该把它们放在手边!
DB2 9 基础 第 4 部分:处理 DB2 数据
1、SQL 的组成部分
SQL 是一种用来定义和操纵数据库对象的语言。使用 SQL 定义数据库表、将数据插入表中、修改表中的数据和从表中检索数据。
大多数 SQL 语句包含一个或多个以下语言元素:
● 单字节的字符 可以是字母(A-Z、a-z、$、# 和 @,或某个扩展字符集的成员)、数字(0-9)或特殊字符(包括逗号、星号、加号、百分号、与符号等等)。
● 标记(token) 是包含一个或多个字符的序列。它不能包含空白字符,除非它是被限界的标识符(由双引号包围的一个或多个字符)或字符串常量。
● SQL 标识符 是用来形成名称的标记。
● 值的数据类型 决定 DB2 如何解释这个值。DB2 支持许多内置的数据类型,还支持用户定义的类型(UDT)。
● 常量 指定一个值。它们分为字符、图形或十六进制字符串常量,以及整数、小数或浮点数字常量。
● 特殊寄存器 是数据库管理程序为一个应用程序进程定义的一个存储区域,用来存储可以在 SQL 语句中引用的信息。特殊寄存器的示例是 CURRENT DATE、CURRENT DBPARTITIONNUM 和 CURRENT SCHEMA。
● 例程 可以是函数、方法或过程。
● 函数 表示一个或多个输入数据值与一个或多个结果值之间的关系。数据库函数可以是内置的或用户定义的。
列(即聚合)函数 对一个列中的一组值进行操作,返回单一值。例如:
■ SUM(sales) 返回 Sales 列中值的总和。
■ AVG(sales) 返回 Sales 列中值的平均值(即总和除以值的数量)
■ MIN(sales) 返回 Sales 列中的最小值。
■ MAX(sales) 返回 Sales 列中的最大值。
■ COUNT(sales) 返回 Sales 列中非空值的数量。
标量函数 对单一值进行操作,返回另一个单一值。例如:
■ ABS(-5) 返回 -5 的绝对值,即 5。
■ HEX(69) 返回数字 69 的十六进制表示,即 45000000。
■ LENGTH('Pierre') 返回字符串 “Pierre” 中的字节数量,即 6。对于 GRAPHIC 字符串,LENGTH 函数返回双字节字符的数量。
■ YEAR('03/14/2002') 提取 03/14/2002 的年份部分,即 2002。
■ MONTH('03/14/2002') 提取 03/14/2002 的月份部分,即 3。
■ DAY('03/14/2002') 提取 03/14/2002 的日部分,即 14。
■ LCASE('SHAMAN') 或 LOWER('SHAMAN') 返回已经转换为全小写字符的字符串,即 ‘shaman’。
■ UCASE('shaman') 或 UPPER('shaman') 返回已经转换为全大写字符的字符串,即 ‘SHAMAN’。
用户定义的函数使用 CREATE FUNCTION 语句注册到数据库的系统编目中(可以通过 SYSCAT.ROUTINES 编目视图
● 过程 是一个可以通过执行 CALL 语句来启动的应用程序。过程的参数是不同类型的标量值,可以用来将值传递进过程中、接受过程的返回值或者同时有这两种作用。用户定义的过程使用 CREATE PROCEDURE 语句注册到数据库的系统编目中(可以通过 SYSCAT.ROUTINES 编目视图访问)。
● 表达式 指定一个值。有字符串表达式、算术表达式和情况表达式,情况表达式可以用来根据对一个或多个条件的计算来指定某一结果。
● 方法 也是一组输入数据值和一组结果值之间的关系。但是,数据库方法是作为用户定义的结构化类型的一部分隐式或显式地定义的。例如,一个称为 CITY 的方法(类型为 ADDRESS)接受 VARCHAR 类型的输入值,结果是ADDRESS 的一个子类型。用户定义的方法使用 CREATE METHOD 语句注册到数据库的系统编目中(可以通过SYSCAT.ROUTINES 编目视图访问)。
● 谓词(predicate) 指定关于给定的行或组的一个条件,结果可以是真、假或未知。谓词有几个子类型:
■ 基本谓词 对两个值进行比较(例如,x > y)。
■ BETWEEN 谓词将一个值与一个值范围进行比较。
■ EXISTS 谓词测试某些行是否存在。
■ IN 谓词判断一个或多个值是否在一个值集合中。
■ LIKE 谓词搜索具有某一模式的字符串。
■ NULL 谓词测试空值。
1、使用 SELECT 语句从数据库表检索数据
SELECT 语句用来检索表或查看数据。最简单形式的 SELECT 语句可以用来检索一个表中的所有数据,如下:
SELECT * FROM staff
要限制结果集中行的数量,可以使用 FETCH FIRST 子句,例如:
SELECT * FROM staff FETCH FIRST 10 ROWS ONLY
可以通过指定选择列表 从表中检索特定的列,选择列表由逗号分隔的列名组成。例如:
SELECT name, salary FROM staff
使用 DISTINCT 子句消除结果集中的重复行。例如:
SELECT DISTINCT dept, job FROM staff
使用 AS 子句给选择列表中的表达式或项目分配一个有意义的名称。例如:
SELECT name, salary + comm AS pay FROM staff
如果没有 AS 子句,派生的列会命名为 2,这表示它是结果集中的第二列。
2、使用 WHERE 子句和谓词限制查询返回的数据量
使用 WHERE 子句指定一个或多个搜索标准(即搜索条件),从而从表或视图选择特定的行。搜索条件 由一个或多个谓词组成。谓词指定关于行的某一情况。
在构建搜索条件时,要确保:
● 算术操作只应用于数字数据类型
● 只在可比较的数据类型之间进行比较
● 将字符值包围在单引号中
● 字符值应该指定为与数据库中的值完全一样
一下是一些示例(说明,示例中使用的 staff 表存在与 db2 的 Sample 数据库中):
●寻找工资超过 $20,000 的职员的姓名:
"SELECT name, salary FROM staff WHERE salary > 20000"
将语句包围在双引号中,可以防止操作系统错误地解释特殊字符,比如 * 或 >;如果不这么做,大于号会被解释为输出重定向请求。
● 列出工资超过 $20,000 的不是经理的职员的姓名、头衔和工资:
"SELECT name, job, salary FROM staff WHERE job <> 'Mgr' AND salary > 20000"
● 寻找以字母 S 开头的所有姓名:
SELECT name FROM staff WHERE name LIKE 'S%'
在这个示例中,百分号(%)是一个通配符,代表零个或多个字符的字符串。
子查询(subquery) 是主查询的 WHERE 子句中出现的 SELECT 语句,它将结果集提供给 WHERE 子句。例如:
"SELECT lastname FROM employee WHERE lastname IN
(SELECT sales_person FROM sales WHERE sales_date < '01/01/1996')"
相关名称(correlation name)是在查询的 FROM 子句中定义的,可以作为表的简短名称。相关名称还可以消除对来自不同表的相同列名的二义性引用。例如:
"SELECT e.salary FROM employee e
WHERE e.salary < (SELECT AVG(s.salary) FROM staff s)"
3、使用 ORDER BY 子句对结果进行排序
使用 ORDER BY 子句按照一个或多个列中的值对结果集进行排序。ORDER BY 子句中指定的列名不一定在选择列表中指定。例如:
"SELECT name, salary FROM staff
WHERE salary > 20000
ORDER BY salary"
在 ORDER BY 子句中指定 DESC 可以对结果集进行降序排序:
ORDER BY salary DESC
注意,如果 Order BY 后面的字段没有显示指定 ASC 或者 DESC ,那么默认为升序排列(ASC)。
关于排序还要强调一点,如果没有 Order BY 字句,那么查询结果将按照表中数据的物理顺序进行显示。
联结(join) 是一种将来自两个或更多表中的数据组合起来的查询。常常需要从两个或更多的表中选择信息,因为所需的数据常常是分散的。联结将列添加到结果集中。
最简单的联结中没有指定条件。例如:
SELECT deptnumb, deptname, manager, id, name, dept, job
FROM org, staff
这个语句从 ORG 表和 STAFF 表返回列的所有组合。前三列来自 ORG 表,后四列来自 STAFF 表。这样的结果集(两个表的叉积(cross product))没什么用处。需要用一个联结条件(join condition) 来调整结果集。例如,下面这个查询标识出那些是经理的职员:
SELECT deptnumb, deptname, id AS manager_id, name AS manager
FROM org, staff
WHERE manager = id
ORDER BY deptnumb
前面的语句是一个内部联结的示例。内部联结(inner join) 只返回叉积中满足联结条件的行。如果一行在一个表中存在,但是在另一个表中不存在,它就不包含在结果集中。
如果要显示地使用内链接,则上例可改写为:(结果无影响)
SELECT deptnumb, deptname, id AS manager_id, name AS manager
FROM org INNER JOIN staff
ON manager = id
ORDER BY deptnumb
外部联结(Outer join) 返回内部联结操作产生的行,加上内部联结操作不会返回的行。有三种类型的外部联结:
● 左外部联结 包括内部联结,加上左 表中内部联结操作不会返回的行。这种联结在 FROM 子句中使用 LEFT OUTER JOIN(或 LEFT JOIN)操作符。
● 右外部联结 包括内部联结,加上右 表中内部联结操作不会返回的行。这种联结在 FROM 子句中使用 RIGHT OUTER JOIN(或 RIGHT JOIN)操作符。
● 完全外部联结 包括内部联结,加上左表和右表 中内部联结操作不会返回的行。这种联结在 FROM 子句中使用 FULL OUTER JOIN (或 FULL JOIN)操作符。
5、使用 UNION 集合操作符将两个或更多的查询组合成一个查询
使用 UNION 操作符、EXCEPT 或 INTERSECT 将两个或更多的查询组合成一个查询。集操作符 对查询的结果进行处理、消除重复并返回最终的结果集。
● UNION 操作符将两个或更多的结果表组合在一起,生成一个结果表。
● EXCEPT 集合操作符生成的结果表中包含第一个查询返回的所有行,但是去掉了第二个或任何后续查询返回的行。
● INTERSECT 集合操作符生成的结果表只包含所有查询都返回的行。
示例:
"SELECT sales_person FROM sales
WHERE region = 'Ontario-South'
UNION
SELECT sales_person FROM sales
WHERE sales > 3"
6、使用 GROUP BY 子句对结果进行汇总
使用 GROUP BY 子句对结果集中的行进行组织。每个组在结果集中由一行表示。例如:
SELECT sales_date, MAX(sales) AS max_sales
FROM sales
GROUP BY sales_date
另一个风格的 GROUP BY 子句要指定 GROUPING SETS 子句。分组集 可以用来在一遍中分析不同聚合层次上的数据。例如:
SELECT YEAR(sales_date) AS year, region, SUM(sales) AS tot_sales
FROM sales
GROUP BY GROUPING SETS (YEAR(sales_date), region, () )
分组集列表 指定如何对数据进行分组,即聚合。在分组集列表中添加一对空的圆括号,可以获得结果集中的总量。这个语句返回以下结果:
YEAR REGION TOT_SALES
- - 155
- Manitoba 41
- Ontario-North 9
- Ontario-South 52
- Quebec 53
1995 - 8
1996 - 147
HAVING 子句常常与 GROUP BY 子句一起使用,从而检索出满足特定条件的组的结果。HAVING 子句可以包含一个或多个谓词,将组的某一属性与组的另一个属性或常量进行比较。例如:
"SELECT sales_person, SUM(sales) AS total_sales
FROM sales
GROUP BY sales_person
HAVING SUM(sales) > 25"
这个语句返回销售总量超过 25 的销售人员的列表。
7、使用 INSERT 语句在表或视图中添加新的行
INSERT 语句用来在表或视图中添加新的行。在视图中插入一个新行也会在视图基于的表中插入这一行。
● 使用 VALUES 子句为一行或多行指定列数据。例如:
INSERT INTO staff VALUES (1212,'Cerny',20,'Sales',3,90000.00,30000.00)
注意,连续使用 VALUES 插入多行数据时,推荐使用下面的写法,可以获得更高的效率:
INSERT INTO staff (id, name, dept, job, years, salary, comm)
VALUES (1212,'Cerny',20,'Sales',3,90000.00,30000.00),
(1213,'Wolfrum',20,'Sales',2,90000.00,10000.00)
可以指定完全选择来标识出要从其他表或视图复制的数据。完全选择(fullselect) 是产生结果表的语句。例如:
SELECT id, name, dept, job, years, salary, comm
FROM staff
WHERE dept = 38
8、使用 UPDATE 语句修改表或视图中的数据
UPDATE 语句用来修改表或视图中的数据。通过指定 WHERE 子句,可以修改满足条件的每一行的一个或多个列的值。例如:
UPDATE staff
SET dept = 51, salary = 70000
WHERE id = 750
多个列同时更新:
UPDATE staff
SET (dept, salary) = (51, 70000)
WHERE id = 750
警告!如果没有指定 WHERE 子句,DB2 就会更新表或视图中的每一行!
9、使用 DELETE 语句删除数据
DELETE 语句用来从表中删除整行的数据。通过指定 WHERE 子句,删除满足条件的每一行。例如:
DELETE FROM staff
WHERE id IN (1212, 1213)
警告!如果没有指定 WHERE 子句,DB2 就会删除表中的所有行!
10、使用 MERGE 语句将有条件更新、插入或删除操作组合起来
MERGE 语句使用来自源表的数据更新目标表或可更新视图。仅仅用一个操作,目标表中与源表匹配的行就可以被更新或删除,目标表中不存在的行被插入。例如:
MERGE INTO employee AS e
USING (SELECT empno, firstnme, midinit, lastname, workdept, phoneno,
hiredate, job, edlevel, sex, birthdate, salary FROM my_emp) AS m
ON e.empno = m.empno
WHEN MATCHED THEN
UPDATE SET (salary) = (m.salary)
WHEN NOT MATCHED THEN
INSERT (empno, firstnme, midinit, lastname, workdept, phoneno,
hiredate, job, edlevel, sex, birthdate, salary)
VALUES (m.empno, m.firstnme, m.midinit, m.lastname,
m.workdept, m.phoneno, m.hiredate, m.job, m.edlevel,
m.sex, m.birthdate, m.salary)
对上面 SQL 的解释如下(Merge 操作对一些 SQL 老手来说都可能从来没用过呢):使用表 my_emp 联合表 employee,根据两个表的比照(ON e.empno = m.empno),如果存在这样的记录,则使用 表 my_emp 的 salary 值来更新表 employee 的 salary 的值;如果不存在符合条件的记录,则将表 my_emp 中的数据插入到表 employee 中去。可以理解为 先更新数据,更新不了就插入数据。
11、使用数据修改-表引用子句在同一个工作单元中获得中间结果集
假设您想在同一个工作单元(UOW)中给职员 000220 加薪 7% 并检索她原来的工资。可以使用 数据修改-表引用 子句来实现,这个子句是 SQL 语句中 FROM 子句的一部分。
SELECT salary FROM OLD TABLE (
UPDATE employee SET salary = salary * 1.07
WHERE empno = '000220');
数据修改操作(插入、更新或删除)的目标中的列变成中间结果表中的列,可以在查询的选择列表中按名称引用这些列(在这个示例中是 Salary )。
关键字 OLD TABLE 指定中间结果表应该包含数据修改操作之前 的值。
关键字 NEW TABLE 指定中间结果表应该包含数据修改操作之后 (在发生引用完整性计算和触发操作后触发器之前)的值。
关键字 FINAL TABLE 指定中间结果表应该包含数据修改操作、引用完整性计算和触发操作后触发器之后的值。
1、工作单元和保存点
工作单元(unit of work,UOW) 也称为事务,它是应用程序进程中一个可恢复的(recoverable) 操作序列。UOW 的经典示例是简单的银行转帐事务,即把资金从一个帐号转到另一个帐号中。在应用程序从一个帐号减去一定数量的资金之后,数据库会出现不一致的状态;在第二个帐号中增加同样数量的资金之后,这种不一致才会消除。当这些修改已经提交之后,其他应用程序才能使用它们。
保存点(savepoint) 允许选择性地回滚组成 UOW 的操作子集,这样就不会丢失整个事务。可以嵌套保存点并可以同时拥有几个活跃的 保存点级别(savepoint level);这允许应用程序根据需要回滚到特定的保存点。
[示例]-[保存点]:
假设在某个 UOW 中定义了三个保存点(A、B 和C):
savepoint A;
do some more work;
savepoint B;
do even more work;
savepoint C;
wrap it up;
roll back to savepoint B;
1、创建和调用 SQL 过程
SQL 过程 是过程体用 SQL 编写的过程。过程体包含 SQL 过程的逻辑。它可以包含变量声明、条件处理、流控制语句和 DML。可以在复合语句(compound statement) 中指定多个 SQL 语句,复合语句将几个语句组合成一个可执行块。
当成功地调用 CREATE PROCEDURE (SQL) 语句时,就会创建一个 SQL 过程,这会在应用服务器上定义 SQL 过程。SQL 过程是一种定义比较复杂的查询或任务的简便方式,可以在需要时调用它们。
创建 SQL 过程的一种简便方法是在命令行处理程序(CLP)脚本中编写 CREATE PROCEDURE (SQL) 语句。
[示例]-[存储过程相关]:
●1、连接数据库
DB2 CONNECT TO SAMPLE USER DB2ADMIN USING *****
●2、编写存储过程
下例是一个非常简单的存储过程示例,使用了输入、输出参数和游标,保存为 C:sales_status.db2
CREATE PROCEDURE sales_status
(IN quota INTEGER, OUT sql_state CHAR(5))
DYNAMIC RESULT SETS 1
LANGUAGE SQL
BEGIN
DECLARE SQLSTATE CHAR(5);
DECLARE rs CURSOR WITH RETURN FOR
SELECT sales_person, SUM(sales) AS total_sales
FROM sales
GROUP BY sales_person
HAVING SUM(sales) > quota;
OPEN rs;
SET sql_state = SQLSTATE;
END @
这个过程称为 SALES_STATUS,它接受一个输入参数 quota 并返回输出参数 sql_state。过程体中只有一个 SELECT 语句,它返回销售总量超过指定额度的销售人员的姓名和销售总量。
大多数 SQL 过程接受至少一个输入参数。在我们的示例中,输入参数包含一个值(quota),这个值用在过程体包含的 SELECT 语句中。
●3、编译存储过程(DB2 CLP)
注意,存储过程中涉及到的表必须存在于 Sample 数据库,并且有相应的结构,否则编译存储过程将出错。
DB2 -td@ -vf C:sales_status.db2
说明:db2 命令指定 -td 选项标志,这让命令行处理程序使用 @ 作为语句终止字符(因为在过程体内已经使用分号作为语句终止字符);-v 选项标志让命令行处理程序将命令文本回显到标准输出;-f 选项标志让命令行处理程序从指定的文件(而不是标准输入)读取命令输入。
●4、执行存储过程
DB2 CALL sales_status (25, ?);
2、SQL 过程的参数
SQL 过程的参数列表可以指定零个或更多的参数,每个参数可以是三种类型之一:
● IN 参数将一个输入值传递给 SQL 过程;在过程体内不能修改这个值。
● OUT 参数从 SQL 过程返回一个输出值。
● INOUT 参数将一个输入值传递给 SQL 过程并从 SQL 过程返回一个输出值。
3、SQL 过程的返回值
SQL 过程可以返回零个或更多的结果集。返回结果集的方法是:
1. 在 DYNAMIC RESULT SETS 子句中声明 SQL 过程返回的结果集数量。
2. 在过程体中为返回的每个结果集声明一个游标(使用 WITH RETURN FOR 子句)。游标(cursor) 是一个命名的控制结构,应用程序使用它指向有序行集中的特定行。游标用来从行集中检索行。
3. 打开返回的每个结果集的游标。
4. 当 SQL 过程返回时,让游标打开着。
4、SQL 过程的变量
变量必须在 SQL 过程体的开头进行声明。要声明 一个变量,应该分配一个惟一的标识符并指定变量的 SQL 数据类型,还可以可选地分配一个初始值。
5、SQL 过程的流控制语句
上例中的 SET 子句 就是一个流控制语句。在 SQL 过程体中可以使用以下的流控制语句、结构和子句来进行有条件处理:
● CASE 结构根据对一个或多个条件的计算选择一个执行路径。
● FOR 结构对于表中的每一行执行一个代码块。
● GET DIAGNOSTICS 语句将关于前一个 SQL 语句的信息返回到一个 SQL 变量中。
● GOTO 语句将控制转移到一个有标签的块(一个或多个语句的块,由一个惟一的 SQL 名称和冒号来标识)。
● IF 结构根据对条件的计算选择一个执行路径。ELSEIF 和 ELSE 子句允许执行分支,或指定在其他条件不满足时执行的默认操作。
● ITERATE 子句将流控制传递到一个有标签的循环的开头。
● LEAVE 子句使程序控制离开一个循环或代码块。
● LOOP 子句多次执行一个代码块,直到 LEAVE、ITERATE 或 GOTO 语句使控制离开循环。
● REPEAT 子句重复执行一个代码块,直到指定的搜索条件返回真为止。
● RETURN 子句将控制从 SQL 过程返回给调用者。
● SET 子句将一个值赋值给一个输出变量或 SQL 变量。
● WHILE 在指定的条件为真时重复执行一个代码块。
6、以前需要用 C 编译器来创建 SQL 过程,这种依赖性在 DB2 Universal Database Version 8 中已经消除了。
7、执行存储过程相关
WINDOWS 操作系统:
db2 CALL sales_status (25, ?)
注意!因为圆括号对于基于 UNIX 的系统上的命令 shell 有特殊意义,所以在这些系统上必须在它们前面加上反斜线()字符,或者用双引号包围它们:
db2 "CALL sales_status (25, ?)"
如果以交互输入模式使用命令行处理程序(CLP)(由 db2 => 输入提示表示),那么不必包含双引号。
在这个示例中,值 25 作为输入参数 quota 传递给 SQL 过程,并使用问号(?)作为输出参数 sql_state 的占位符。这个过程返回销售总量超过指定额度(25)的每个销售人员的姓名和销售总量。下面是这个语句返回的输出示例:
SQL_STATE: 00000
SALES_PERSON TOTAL_SALES
GOUNOT 50
LEE 91
"SALES_STATUS" RETURN_STATUS: "0"
五、创建和使用 SQL 用户定义函数
1、可以创建用户定义函数来扩展内置的 DB2 函数。例如,创建计算复杂的算术表达式或操作字符串的函数,然后在 SQL 语句中像对待任何现有的内置函数一样引用这些函数。
[示例]-[用户自定义函数]:
输入半径,返回圆的面积:
CREATE function ca (r DOUBLE)
RETURNS DOUBLE
LANGUAGE SQL
CONTAINS SQL
NO EXTERNAL ACTION
DETERMINISTIC
RETURN 3.14159 * (r * r);
说明:NO EXTERNAL ACTION 子句指出这个函数不会对数据库管理程序不管理的对象的状态有任何影响。DETERMINISTIC 关键字指出这个函数对于给定的参数值总是返回相同的结果。
调用自定义函数示例:
方法1:
db2 SELECT ca(2.5) AS area FROM sysibm.sysdummy1
方法2:
db2 values ca(2.5)
2、还可以创建用户定义的表函数,它接受零个或更多的输入参数并以表的形式返回数据。表函数只能用在 SQL 语句的 FROM 子句中。
[示例]-[返回结果集的用户自定义函数]:
CREATE FUNCTION jobemployees (job VARCHAR(8))
RETURNS TABLE (
empno CHAR(6),
firstname VARCHAR(12),
lastname VARCHAR(15)
)
LANGUAGE SQL
READS SQL DATA
NO EXTERNAL ACTION
DETERMINISTIC
RETURN
SELECT empno, firstnme, lastname
FROM employee
WHERE employee.job = jobemployees.job;
调用自定义函数示例:
db2 SELECT * FROM TABLE(jobemployees('CLERK')) AS clerk
1、概述
DB2 提供了一套丰富且灵活的数据类型。DB2 附带 INTEGER、CHAR 和 DATE 等基本数据类型。它还提供了创建用户定义的数据类型(UDT)的工具,使用户能够创建复杂的非传统的数据类型,从而适应当今复杂的编程环境。
内置的数据类型分为四类:数字、字符串、日期时间和 XML。
用户定义的数据类型分为:单值类型、结构化类型和引用类型。
2、数字数据类型
● 整数:SMALLINT、INTEGER 和 BIGINT 用来存储整数。例如,库存数量可以定义为 INTEGER。SMALLINT 可以在 2 个字节中存储从 -32,768 到 32,767 的整数。INTEGER 可以在 4 个字节中存储从 -2,147,483,648 到 2,147,483,647 的整数。BIGINT 可以在 8 个字节中存储从 -9,223,372,036,854,775,808 到 9,223,372,036,854,775,807 的整数。
● 小数:DECIMAL 用来存储有小数部分的数字。要定义这个数据类型,需要指定精度 (p,表示总的位数)和小数位 (s,表示小数点右边的位数)。定义为 DECIMAL(10,2) 的列可以保存的金额最高可为 99999999.99。数据库中需要的存储空间依赖于精度,按照公式 p/2 +1 计算。所以 DECIMAL(10,2) 需要 10/2 + 1 (即 6)字节。
● 浮点数:REAL 和 DOUBLE 用来存储数字的近似值。例如,非常小或非常大的科学计量值可以定义为 REAL。REAL 可以定义为具有 1 到 24 位之间的长度,需要 4 字节的存储空间。DOUBLE 可以定义为具有 25 到 53 位之间的长度,需要 8 字节的存储空间。FLOAT 可以视为 REAL 或 DOUBLE 的同义词。
3、字符串数据类型
下面的数据类型用来存储单字节字符串:
● CHAR 或 CHARACTER 用来存储最多 254 字节的固定长度的字符串。例如,制造商可以给零件分配一个 8 字符长度的标识符,因此这些标识符在数据库中存储为 CHAR(8) 类型的列。
● VARCHAR 用来存储可变长度的字符串。例如,制造商用不同长度的标识符表示大量零件,因此这些标识符存储为 VARCHAR(100) 类型的列。VARCHAR 列的最大长度为 32,672 字节。在数据库中,VARCHAR 数据只占用恰好所需的空间。
下面的数据类型用来存储双字节字符串:
● GRAPHIC 用来存储固定长度的双字节字符串。GRAPHIC 列的最大长度是 127 个字符。
● VARGRAPHIC 用来存储可变长度的双字节字符串。VARGRAPHIC 列的最大长度是 16,336 个字符。
DB2 还提供了存储非常长的字符串数据的数据类型。所有长字符串数据类型都具有相似的特征。首先,在数据库中此数据在物理上并没有与行数据存储在一起,这意味着需要进行额外处理才能访问此数据。长数据类型的长度最大可以定义为 2GB。但是,需要的空间只是实际使用的空间。
长数据类型有:
● LONG VARCHAR
● CLOB(字符大对象)
● LONG VARGRAPHIC
● DBCLOB(双字节字符大对象)
● BLOB(二进制大对象)
4、日期时间数据类型
DB2 提供了三种存储日期和时间的数据类型:
● DATE
● TIME
● TIMESTAMP
注意!这些数据类型的值在数据库中存储为一种内部格式;但是应用程序可以将其作为字符串操纵。在检索这些数据类型之一时,它被表示为字符串。在更新这些数据类型时,将值包围在引号中。
DB2 提供了操纵日期时间值的内置函数。例如,可以使用 DAYOFWEEK 或 DAYNAME 函数判断一个日期值是星期几。使用 DAYS 函数计算两个日期之间相差多少天。DB2 还提供了特殊寄存器以根据时间-日期时钟生成当前日期、时间或时间戳。例如,CURRENT DATE 返回一个表示系统上的当前日期的字符串。
日期和时间值的格式取决于在创建数据库时指定的数据库国家编码。有几种可用的格式:ISO、USA、EUR 和 JIS。例如,如果数据库使用 USA 格式,那么日期值的格式是 mm/dd/yyyy。在创建应用程序时,可以使用 BIND 命令的 DATETIME 选项改变格式。
TIMESTAMP 数据类型只有一种格式。字符串表示是 yyyy-mm-dd-hh.mm.ss.nnnnnn。
5、XML 数据类型
DB2 提供了 XML 数据类型来存储格式良好的 XML 文档。
XML 列中的值存储为与字符串数据类型不同的内部表示。要在 XML 数据类型的列中存储 XML 数据,需要使用 XMLPARSE 函数对数据进行转换。可以使用 XMLSERIALIZE 函数将 XML 数据类型的值转换为 XML 文档的串行化字符串值。DB2 还提供了许多其他的内置函数来操纵 XML 数据类型。
6、用户定义的数据类型
DB2 允许用户定义适合自己应用程序的数据类型。有三种用户定义的数据类型:
● 用户定义的单值类型:基于内置类型定义新的数据类型。这个新类型具有该内置类型相同的功能,但可以使用它确保只比较相同类型的值。
[示例]-[用户自定义类型]:
--创建 RMB (人民币)自定义类型
CREATE DISTINCT TYPE RMB AS DECIMAL(10,2) WITH COMPARISONS
--使用该类型
CREATE TABLE Sales (ID INT NOT NULL,Name VARCHAR(20),SaleMoney RMB)
--插入数据
INSERT INTO Sales(ID,Name,SaleMoney)
VALUES(007,'彭建军',RMB(1234.56))
● 用户定义的结构化类型:创建由几个内置类型列组成的类型。然后,可以在创建表时使用这个结构化类型。例如,可以创建一种名为ADDRESS 的结构化类型,它包含表示街道号码、街道名、城市之类的数据。然后在定义其他表(如职工表或者供应商表)时使用这种类型,因为这些表也需要同样的数据。
● 用户定义的引用类型:在使用结构化类型时,可以使用引用类型定义对另一个表中行的引用。这些引用看起来与参照约束相似,然而,它们不强制表间有关系。表中的引用允许用不同的方法指定查询。
7、DB2 扩展器
DB2 扩展器支持复杂的、非传统的数据类型。它们与 DB2 服务器代码分开打包,必须安装在服务器上,并必须安装在使用那些数据类型的每个数据库中。
IBM 和独立软件供应商提供许多 DB2 扩展器。IBM 最早提供的四个扩展器用于存储音频、视频、图像和文本数据。例如,DB2 Image Extender 可用于存储一本书的封面图像,而 DB2 Text Extender 可用于存储书的正文。现在,还有其他几个扩展器可用。DB2 Spatial Extender 可以用来存储和分析空间数据,XML Extender 用来管理 XML 数据。
DB2 扩展器是用用户定义类型和用户定义函数(UDF)的特性实现的。每个扩展器提供一个或多个 UDT、用于操作 UDT 的 UDF 和特定的应用程序编程接口(API),或许还提供其他工具。
二、表
1、概述
所有数据都存储在数据库的表中。表 由不同数据类型的一列或多列组成。数据存储在行(或称为记录)中。
表是使用 CREATE TABLE SQL 语句定义的。DB2 还提供了一个用来创建表的 GUI 工具 DB2 Control Center,这个工具可以根据指定的信息创建一个表。它还生成 CREATE TABLE SQL 语句,以后可以在脚本或应用程序中使用这个语句。
每个数据库都有一组表,称为系统编目表(system catalog tables),它们保存关于数据库中所有对象的信息。DB2 为基系统编目表提供了视图。数据库中定义的每个表在编目视图 SYSCAT.TABLES 中都有相应的一行。数据库中每个表的每一列在 SYSCAT.COLUMNS 中都有相应的一行。可以用 SELECT 语句像查看数据库中的任何其他表一样查看编目视图;但是,不能使用 INSERT、UPDATE 或 DELETE 语句。在执行数据定义语言(DDL)语句(比如 CREATE)和其他操作(比如 RUNSTATS)时,这些表会自动更新。
2、创建表
使用 CREATE TABLE SQL 语句在数据库中定义一个表。
[示例]-[创建表]:
CREATE TABLE BOOKS
(
BOOKID INTEGER,
BOOKNAME VARCHAR(100),
ISBN CHAR(10)
)
可以使用 CREATE TABLE SQL 语句创建与数据库中另一个表或视图相似的表:
CREATE TABLE MYBOOKS LIKE BOOKS
这个语句创建一个与原始表或视图具有相同列的表。新表的列具有与原始表或视图中的列相同的名称、数据类型和可空属性。还可以指定复制其他属性(比如列默认值和标识属性)的子句。
CREATE TABLE SQL 语句的详细信息可以在 SQL Reference 中找到。
3、填充数据
INSERT 语句允许向表中插入一行或几行数据。DB2 还提供了一些实用程序插入来自文件的大量数据。IMPORT 实用程序使用 INSERT 语句插入行。它是为向数据库中加载少量数据而设计的。LOAD 实用程序用于加载大量数据,它将行直接插入到数据库中的数据页,因此比 IMPORT 实用程序要快得多。
4、在数据库中存储表
表存储在数据库的表空间 中。表空间拥有分配给它们的物理空间。在创建表之前必须先创建表空间。
在创建表时,可以让 DB2 把表放在默认的表空间内(如上例),也可以指定表应该驻留在哪个表空间内,如下:
[示例]-[创建指定表空间、索引空间的表]:
CREATE TABLE BOOKS
(
BOOKID INTEGER,
BOOKNAME VARCHAR(100),
ISBN CHAR(10)
) IN TableSpace1
INDEX IN TableSpace2
说明,本例中创建的表 BOOKS 存储在表空间 TableSpace1 中,表 BOOKS 的索引将会存储在 表空间 TableSpace2 中。如果不显示指定表空间,DB2 将使用默认表空间存储用户创建的表和索引。
5、修改表
可以使用 ALTER TABLE SQL 语句更改表的某些特征。例如,可以添加或删除:
● 列
● 主键
● 一个或多个惟一性或参照约束
● 一个或多个检查约束
还可以修改表中特定列的特征:
● 列的标识属性
● 字符串列的长度
● 列的数据类型
● 列的可空性
● 列的约束
对于修改列有一些限制:
● 在修改字符串列的长度时,只能增加长度。
● 在修改列的数据类型时,新的数据类型必须与现有的数据类型兼容。例如,可以将 CHAR 列转换为 VARCHAR 列,但是不能将它们转换为 GRAPHIC 或数字列。数字列可以转换为任何其他数字数据类型,只要新数据类型的长度足以容纳其中的值。例如,可以将 INTEGER 列转换为 BIGINT,但是 DECIMAL(10,2) 列不能转换为 SMALLINT。
● 固定长度的字符串可以转换为可变长度的字符串,可变长度的字符串也可以转换为固定长度的字符串。例如,CHAR(100) 可以转换为 VARCHAR(150)。对于可变长度的图形字符串也有类似的限制。
表的某些特征不可以更改。例如,不可以修改某些列的数据类型、表驻留的表空间或列的次序。要更改这样的特征,必须保存表数据,删除表,然后重新创建表。
[示例]-[修改表]:
ALTER TABLE BOOKS ADD BOOKTYPE CHAR(1)
ALTER TABLE BOOKS ALTER BOOKNAME SET DATA TYPE VARCHAR(200) ALTER ISBN SET NOT NULL
6、删除表
DROP TABLE 语句将表从数据库中删除,数据和表定义都被删除。如果为表定义了索引或者约束,它们也同时被删除。
警告!删除表操作请谨慎执行!
[示例]-[删除表]:
DROP TABLE BOOKS
7、NOT NULL、DEFAULT 和 GENERATED 列选项
表的列在 CREATE TABLE 语句中由列名和数据类型指定。还可以指定一些额外的子句来限制列中的数据。
在默认情况下,列允许空值。如果不想允许空值,可以为列指定 NOT NULL 子句。还可以使用 WITH DEFAULT 子句和一个默认值来指定默认值。
[示例]-[自增列]:
CREATE TABLE BOOKS
(
BOOKID INTEGER NOT NULL GENERATED ALWAYS AS IDENTITY
(START WITH 1, INCREMENT BY 1),
BOOKNAME VARCHAR(100) WITH DEFAULT 'TBD',
ISBN CHAR(10)
)
说明,上例中的 BOOKID 列由 DB2 进行管理,从1开始,每次有新增数据,则该列自动加 1 。注意,不能显示的对自增列进行插入操作。
[示例]-[自动计算列]:
CREATE TABLE AUTHORS
(
AUTHORID INTEGER NOT NULL PRIMARY KEY,
LNAME VARCHAR(100),
FNAME VARCHAR(100),
FICTIONBOOKS INTEGER,
NONFICTIONBOOKS INTEGER,
TOTALBOOKS INTEGER GENERATED ALWAYS AS (FICTIONBOOKS + NONFICTIONBOOKS)
)
说明,上例中的 TOTALBOOKS 列由 DB2 进行管理,该列的值由 DB2 根据 FICTIONBOOKS 和 NONFICTIONBOOKS 的值自动计算。
注意,不能显示的对自动计算列进行插入操作。
重要地,自动计算列和自增列都有实际的物理存储。
1、概述
DB2 提供了几种方法来控制什么数据可以存储在列中。这些特性被称为约束(constraint) 或规则(rule),数据库管理程序强制一个数据列或一组列遵守这些约束。
DB2 提供了三种类型的约束:惟一性、参照完整性和表检查。
2、惟一性约束
惟一性约束 用于确保列中的值是惟一的。可以对一个或多个列定义惟一性约束。惟一性约束中包括的每个列都必须定义为 NOT NULL。
惟一性约束可以定义为 PRIMARY KEY 或 UNIQUE 约束。这些可以在创建表时作为 CREATE TABLE SQL 语句的一部分定义,或者在创建表后使用 ALTER TABLE 语句添加。
DB2 在一个表中只允许定义一个主键;但可以定义多个惟一性约束。
DB2 不允许在同样的列上创建多个惟一的索引。因此,不能在同样的列上同时定义 PRIMARY KEY 和 UNIQUE 约束。
PRIMARY KEY 和 UNIQUE 的区别?
它们的区别在于数据的性质。当列/列的组合被其他表引用或使用时,推荐使用 PRIMARY KEY,否则使用 UNIQUE 键。
3、参照完整性约束
参照完整性约束 用于定义表之间的关系并确保这些关系保持有效。
假设有一个表包含关于作者的信息,而另一个表列出这些作者已经写的书。在 BOOKS 表和 AUTHORS 表之间有这样一种关系 —— 每本书都有一个作者,该作者必须存在于 AUTHORS 表中。每个作者都有一个存储在 AUTHORID 列中的惟一的标识符。AUTHORID 在 BOOKS 表中用于识别每本书的作者。要定义这种关系,应该把 AUTHORS 表的 AUTHORID 列定义为主键,然后在 BOOKS 表上定义一个外键,从而与 AUTHORS 表中的 AUTHORID 列建立关系:
[示例]-[外键约束]:
CREATE TABLE AUTHORS
(
AUTHORID INTEGER NOT NULL PRIMARY KEY,
LNAME VARCHAR(100),
FNAME VARCHAR(100)
)
CREATE TABLE BOOKS
(
BOOKID INTEGER NOT NULL PRIMARY KEY,
BOOKNAME VARCHAR(100),
ISBN CHAR(10),
AUTHORID INTEGER REFERENCES AUTHORS
)
拥有与另一个表相关的主键的表(这里的 AUTHORS 表)被称为父表(parent table)。与父表相关的表(这里的 BOOKS 表)被称为从属表(dependent table)。可以为一个父表定义多个从属表。
还可以定义同一个表中各行之间的关系。在这种情况下,父表和从属表是同一个表。
如果为一组表定义了参照约束,当对这些表执行更新操作时,DB2 就会强制这些表遵守参照完整性规则:
● DB2 确保只向定义了参照完整性约束的列中插入有效数据。
● 当从父表中删除一行,而该行在从属表中有从属行时,DB2 也强制实施一些规则。DB2 采取的操作取决于为表定义的删除规则。
可以指定四个规则:RESTRICT、NO ACTION、CASCADE 和 SET NULL。
● 如果指定了 RESTRICT 或 NO ACTION,那么 DB2 不允许删除父行。必须首先删除从属表中的行才能删除父表中的行。这条规则是默认设置,所以当定义 AUTHORS 和 BOOKS 表时这个规则也适用于它们。
● 如果指定了 CASCADE,那么从父表中删除行时还会自动地删除所有从属表中的从属行。
● 如果指定了 SET NULL,那么从父表中删除父行时从属行中的外键值被设置为空(如果可以为空的话)。
● 在更新父表中的键值时,可以指定两条规则:RESTRICT 和 NO ACTION。如果从属表中有从属行,则 RESTRICT 不允许更新键值。如果在更新完成时在从属表中有从属行,而从属行在父表中没有父键,则 NO ACTION 将导致对父键值的更新操作被拒绝。
4、表检查约束
表检查约束 用于确保列数据不违反为列定义的规则,并限制表的某一列中的值。DB2 确保在插入和更新时不违反这些约束。
[示例]-[表检查约束]:
ALTER TABLE PERSONS ADD SEX VARCHAR(5) CHECK (SEX IN ('MAN','WOMAN') )
说明,以上约束确保 PERSONS 表中的 SEX 性别字段只能插入形如 'MAN' 或 'WOMAN' 的值。违反约束,DB2 将报错。
1、概述
视图就是允许不同的用户或应用程序以不同的方式查看相同的数据。这不仅使得数据更容易访问,还可以用它来限制用户可以查看或更新哪些行和列。
对于用户来说,视图看起来就像表一样。除视图定义之外,视图在数据库内并不占用空间;视图中显示的数据来自另一个表。可以根据现有的一个表(或多个表)、另一个视图或者表和视图的任意组合创建一个视图。在另一个视图的基础上定义的视图被称为嵌套视图。
可以用不同于基表中相应列的列名定义视图。还可以定义一些检查插入或更新的数据是否一直满足视图条件的视图。
数据库中定义的视图的列表存储在系统编目表 SYSIBM.SYSVIEWS 中,SYSIBM.SYSVIEWS 还有一个根据它定义的名为 SYSCAT.VIEWS 的视图。系统编目还有一个 SYSCAT.VIEWDEP,对于数据库中定义的每一个视图所依赖的每个视图或表,SYSCAT.VIEWDEP 中都有一行。另外,每个视图都在 SYSIBM.SYSTABLES 中有一个条目,在 SYSIBM.SYSCOLUMNS 中有多个条目,因为可以像表一样使用视图。
2、创建、删除和修改视图
CREATE VIEW SQL 语句用于定义视图。SELECT 语句用于指定将在视图中显示哪些行与列。
[示例]-[创建视图1]:
CREATE VIEW NONFICTIONBOOKS AS
SELECT * FROM BOOKS WHERE BOOKTYPE = 'N'
[示例]-[创建视图2]:
CREATE VIEW MYBOOKVIEW (TITLE,TYPE) AS
SELECT BOOKNAME,BOOKTYPE FROM BOOKS
DROP VIEW SQL 语句用于从数据库中删除视图。如果删除一个视图所基于的表或另一个视图,那么这个视图依然在数据库中被定义,但变得不起作用。SYSCAT.VIEWS 的 VALID 列表明视图是有效的(‘Y’)还是无效的(‘X’)。即使重新创建基表,无效的视图仍然是无效的;必须也重新创建它。
[示例]-[删除视图]:
DROP VIEW MYBOOKVIEW
不能修改视图;要更改视图定义,必须删除视图,然后重新创建它。DB2 提供的 ALTER VIEW 语句只用于修改引用类型。
3、只读视图和可更新视图
在创建一个视图时,可以将它定义为只读视图 或者可更新视图。视图的 SELECT 语句决定视图是只读的还是可更新的。
一般情况下,如果视图中的行可以映射到基表中的行,那么该视图就是可更新的。例如,就像前面示例中定义的那样,视图 NONFICTIONBOOKS 是可更新的,因为视图中的每一行都是基表中的行。
创建可更新视图的规则很复杂,它们取决于查询的定义。例如,使用 VALUES、DISTINCT 或 JOIN 特性的视图是不可更新的。通过查看SYSCAT.VIEWS 的 READONLY 列很容易就能确定视图是不是可更新的:Y 表示只读,N 表示非只读。
先前定义的 NONFICTIONBOOKS 视图只包含 BOOKTYPE 为 N 的行。如果向这个视图中插入一个 BOOKTYPE 为 F 的行,DB2 将把该行插入到基表 BOOKS 中。但是,如果以后从视图中进行选择,通过该视图却看不到新插入的行。如果不想允许用户插入视图范围以外的行,那么在定义视图时可以使用检查选项。使用 WITH CHECK OPTION 定义视图会让 DB2 检查使用视图的语句是否满足视图的条件。
[示例]-[视图检查定义]:
CREATE VIEW NONFICTIONBOOKS AS
SELECT * FROM BOOKS WHERE BOOKTYPE = 'N'
WITH CHECK OPTION
说明,这个视图仍然限制用户只能看到非小说类的书;另外,它还防止用户插入 BOOKTYPE 列的值不为 N 的行,并防止把现有行中 BOOKTYPE 列的值更新为 N 以外的值。例如,下列语句将不再允许使用:
INSERT INTO NONFICTIONBOOKS VALUES (...,'F');
UPDATE NONFICTIONBOOKS SET BOOKTYPE = 'F' WHERE BOOKID = 111
4、带检查选项的嵌套视图
在定义嵌套视图时,检查选项可以用于限制操作。但是,还可以指定其他子句来定义如何继承限制。检查选项可以定义为 CASCADED 或 LOCAL。如果没有指定关键字,CASCADED 是默认值。
当用 WITH CASCADED CHECK OPTION 创建视图时,所有针对该视图执行的语句都必须满足视图和所有底层视图的条件 —— 即使那些视图不是带检查选项定义的,也是如此。
用 WITH LOCAL CHECK OPTION 在视图 NONFICTIONBOOKS 的基础上创建嵌套视图 NONFICTIONBOOKS2。现在,针对这个视图执行的语句只需要满足指定了检查选项的视图的条件就可以了。
通俗一点来讲,创建 视图1,存在 条件1 ;使用 WITH CASCADED CHECK OPTION 创建基于 视图1 的视图2,存在 条件2 ,那么对 视图2 的操作必须同时满足 条件1 和 条件2 才能成功;但是如果创建 视图2 的时候使用的是 WITH LOCAL CHECK OPTION 选项,那么对 视图2 的操作只要满足 条件2 就可以了。
索引 是表的一个或多个列的键值的有序列表。创建索引的原因有两个:
● 确保一个或多个列中值的惟一性。
● 提高表查询的性能。DB2 优化器使用索引提高执行查询时的性能,或者以索引的顺序显示查询结果。
索引可以定义为惟一的或非惟一的。非惟一的 索引允许重复的键值;惟一的 索引只允许一个键值在列表中出现一次。惟一的索引允许出现单个空值。然而,第二个空值会导致重复现象,因此不允许。
索引是使用 CREATE INDEX SQL 语句创建的。为支持 PRIMARY KEY 或 UNIQUE 约束,还会隐式地创建索引。当创建惟一索引时,会检查键数据的惟一性,如果发现重复的键数据则该操作失败。
索引可以创建为升序、降序或双向。选择哪个选项取决于应用程序如何访问数据。
2、创建索引
在默认情况下,索引按升序创建,但也可以创建降序索引。甚至可以为索引中的各个列指定不同的顺序。
在数据库中创建索引时,按照指定的顺序存储键。索引要求数据处于指定的顺序,从而帮助提高查询的性能。升序索引还用于确定 MIN 列函数的结果;降序索引用于确定 MAX 列函数的结果。
如果应用程序还需要数据按与索引相反的顺序排序,那么 DB2 允许创建双向索引。双向 索引使您不必创建逆向索引,而且它使优化器不需要按逆向对数据进行排序。它还允许高效地获得 MIN 和 MAX 函数值。
DB2 不允许创建具有相同定义的多个索引。即使对于为支持主键或惟一性约束而隐式创建的索引,这一点也适用。
创建一个索引花费的时间比较长。DB2 必须读取每一行来提取键,对这些键进行排序,然后将键值列表写到数据库中。如果表比较大,那么将使用临时表空间对键进行排序。
索引存储在表空间中。如果表驻留在数据库管理的表空间中,就可以选择将索引放在不同的表空间中。在创建表时,使用 INDEXES IN 子句定义这一点。表索引的位置在创建表时设置,除非删除并重新创建表,否则无法改变索引的位置。
DB2 还提供了 DROP INDEX SQL 语句从数据库中删除索引。索引是无法修改的。如果需要更改索引,例如向键中添加另一个列,必须删除并重新创建该索引。
[示例]-[创建索引]:
CREATE INDEX Idx_1 ON TableName(C1)
[示例]-[创建包含多列且不同排序规则的索引]:
CREATE INDEX Idx_2 ON TableName(C1 ASC, C2 DESC)
[示例]-[创建双向索引]:
CREATE INDEX Idx_3 ON TableName(C1) ALLOW REVERSE SCANS
[示例]-[删除索引]:
DROP INDEX Idx_1
3、聚集索引
在每个表上,可以将一个索引创建为聚集索引。如果常常以某一次序引用表数据,那么聚集索引比较有用。聚集索引(clustering index) 定义数据在数据库中存储的次序。在插入期间,DB2 会试图将新的行放置得靠近有相似键的行。这样的话,在查询以聚集索引序列请求数据期间,可以更快地检索数据。
要将索引创建为聚集索引,应该在 CREATE INDEX 语句上指定 CLUSTER 子句:
CREATE INDEX IAUTHBKNAME ON BOOKS (AUTHORID,BOOKNAME) CLUSTER
这个语句在 AUTHORID 和 BOOKNAME 列上创建一个索引,并将其作为聚集索引。如果编写的查询要求列出作者及其所写的所有书籍,这个索引会提高查询的性能。
4、在索引中使用包含的列
在创建索引时,可以选择包含额外的列数据,这些额外的列数据将与键存储在一起,但实际上它们不是键本身的一部分,所以不被排序。
在索引中包含额外列的主要原因是为了提高某些查询的性能:因为索引页面中已经提供了数据值,DB2 就不需要访问数据页面。只能为惟一索引定义包含的列。但是,在强制实施索引的惟一性时不考虑包含的列。
假设我们经常需要获得按 BOOKID 排序的书名列表。查询将如下所示:
SELECT BOOKID,BOOKNAME FROM BOOK ORDER BY BOOKID
下面的语句会创建一个可能提高性能的索引:
CREATE UNIQUE INDEX IBOOKID ON BOOKS (BOOKID) INCLUDE(BOOKNAME)
这样的话,查询结果所需的所有数据都出现在索引中,不需要检索数据页面。
那么,为什么不干脆在索引中包括所有的数据?首先,这需要占用数据库中更多的物理空间,因为本质上表数据与索引中的数据是重复的。其次,每当更新数据值时,数据的所有拷贝都需要更新,在发生许多更新的数据库中,这是一项很大的开销。
5、应该创建什么索引?
下面是创建索引时应该考虑的一些事项:
● 由于索引是键值的持久性列表,它们要占用数据库空间。所以,创建许多索引就需要数据库中有更多的存储空间。所需的空间量由键列的长度决定。DB2 提供了一个工具帮您估计索引的大小。
● 索引是值的额外副本,所以当表中的数据被更新时,它们也必须被更新。如果表数据经常被更新,就要考虑额外的索引会对更新性能产生什么样的影响。
● 如果在适当的列上定义索引,索引会大大提高查询的性能。
DB2 提供了一个称为 Index Advisor 的工具帮助您确定要定义哪些索引。Index Advisor 允许指定将对表执行的工作负载,然后它将建议要为表创建的索引。
1、理解数据一致性
如果用户忘记了进行所有必要的更改,或者如果在用户进行更改的过程中系统崩溃了,又或者如果数据库应用程序由于某种原因过早地停止了,数据库中的数据都会变得不一致。当几个用户同时访问相同的数据库表时,也可能发生不一致。为了防止数据的不一致(尤其是在多用户环境中),DB2 的设计中集成了下列数据一致性支持机制:
● 事务
● 隔离级别
● 锁
2、事务和事务边界
事务(也称为工作单元)是一种将一个或多个 SQL 操作组合成一个单元的可恢复操作序列,通常位于应用程序进程中。事务的启动和终止定义了数据库一致性点;要么将一个事务中执行的所有 SQL 操作的结果都应用于数据库(提交),要么完全取消并丢弃已执行的所有SQL 操作的结果(回滚)。
使用从 Command Center、Script. Center 或 Command Line Processor 运行的嵌入式 SQL 应用程序和脚本,在可执行 SQL 语句第一次执行时(在建立与数据库的连接之后或在现有事务终止之后),事务就会自动启动。在启动事务之后,必须由启动事务的用户或应用程序显式地终止它,除非使用了称为自动提交(automatic commit) 的过程(在这种情况下,发出的每个单独的 SQL 语句被看作单个事务,它一执行就隐式地提交了)。
在大多数情况下,通过执行 COMMIT 或 ROLLBACK 语句来终止事务。当执行 COMMIT 语句时,自从事务启动以来对数据库所做的一切更改就成为永久性的了 —— 即,它们被写到磁盘。当执行 ROLLBACK 语句时,自从事务启动以来对数据库所做的一切更改都被撤消,而数据库返回到事务开始之前所处的状态。不管是哪种情况,数据库在事务完成时都保证能回到一致状态。
一定要注意一点:虽然事务通过确保对数据的更改仅在事务被成功提交之后才成为永久性的,从而提供了一般的数据库一致性,但还是需要用户或应用程序来确保每个事务中执行的 SQL 操作序列始终会导致一致的数据库。
3、COMMIT 和 ROLLBACK 操作的效果
正如在前面提到的,通常通过执行 COMMIT 或 ROLLBACK SQL 语句来终止事务。
默认情况下,在 CLP 中设置了自动提交(Autocommit ON),如下图:
如果不更改 DB2 COMMAND OPTION ,那么 DB2 每执行一个语句,都会自动提交/隐式提交事务,这是需要注意的。
4、不成功事务的效果
如果在事务完成前出现系统故障,那会发生什么情况呢?在这种情况下,DB2 数据库管理程序会取消所有未提交的更改,从而恢复数据库一致性(假定在事务启动时存在这样的一致性)。
四、并发性和隔离级别
1、当多个用户访问同一数据库时会发生的现象
在单用户环境中,每个事务都是顺序执行的,而不会遇到与其他事务的冲突。但是,在多用户环境下,多个事务可以(而且常常)同时执行。因此每个事务都有可能与其他正在运行的事务发生冲突。有可能与其他事务发生冲突的事务称为交错的 或并行的 事务,而相互隔离的事务称为串行化 事务,这意味着同时运行它们的结果与一个接一个连续地运行它们的结果没有区别。
在多用户环境下,在使用并行事务时,会发生四种现象:
● 丢失更新:这种情况发生在两个事务读取并尝试更新同一数据时,其中一个更新会丢失。例如:事务 1 和事务 2 读取同一行数据,并都根据所读取的数据计算出该行的新值。如果事务 1 用它的新值更新该行以后,事务 2 又更新了同一行,则事务 1 所执行的更新操作就丢失了。由于设计 DB2 的方法,DB2 不允许发生此类现象。
● 脏读:当事务读取尚未提交的数据时,就会发生这种情况。例如:事务 1 更改了一行数据,而事务 2 在事务 1 提交更改之前读取了已更改的行。如果事务 1 回滚该更改,则事务 2 就会读取被认为是不曾存在的数据。
● 不可重复的读:当一个事务两次读取同一行数据,但每次获得不同的数据值时,就会发生这种情况。例如:事务 1 读取了一行数据,而事务 2 在更改或删除该行后提交了更改。当事务 1 尝试再次读取该行时,它会检索到不同的数据值(如果该行已经被更新的话),或发现该行不复存在了(如果该行被删除的话)。
● 幻像:当最初没有看到某个与搜索条件匹配的数据行,而在稍后的读操作中又看到该行时,就会发生这种情况。例如:事务 1 读取满足某个搜索条件的一组数据行,而事务 2 插入了与事务 1 的搜索条件匹配的新行。如果事务 1 再次执行产生原先行集的查询,就会检索到不同的行集。
维护数据库的一致性和数据完整性,同时又允许多个应用程序同时访问同一数据,这样的特性称为并发性。DB2 数据库用来尝试强制实施并发性的方法之一是通过使用隔离级别,它决定在第一个事务访问数据时,如何对其他事务锁定或隔离该事务所使用的数据。
DB2 使用下列隔离级别来强制实施并发性:
● 可重复的读(Repeatable Read)
● 读稳定性(Read Stability)
● 游标稳定性(Cursor Stability)
● 未提交的读(Uncommitted Read)
可重复的读隔离级别可以防止所有现象,但是会大大降低并发性的程度(可以同时访问同一资源的事务数量)。未提交的读隔离级别提供了最大的并发性,但是后三种现象都可能出现。
2、可重复读隔离级别(最高级别)
可重复读隔离级别是最严格的隔离级别。在使用它时,一个事务的影响完全与其他并发事务隔离:脏读、不可重复的读、幻像都不会发生。当使用可重复的读隔离级别时,在事务执行期间锁定该事务以任何方式 引用的所有行。因此,如果在同一个事务中发出同一个SELECT 语句两次或更多次,那么产生的结果数据集总是相同的。
因此,使用可重复的读隔离级别的事务可以多次检索同一行集,并可以对它们执行任意操作,直到由提交或回滚操作终止事务。但是,在事务存在期间,不允许其他事务执行会影响这个事务正在访问的任何行的插入、更新或删除操作。为了确保这种行为,锁定该事务所引用的每一行 —— 而不是仅锁定被实际检索或修改的那些行。因此,如果一个事务扫描了 1000 行,但只检索 10 行,则所扫描的 1000 行(而不仅是被检索的 10 行)都会被锁定。
3、读稳定性隔离级别
读稳定性隔离级别没有可重复读隔离级别那么严格;因此,它没有将事务与其他并发事务的效果完全隔离。读稳定性隔离级别可以防止脏读和不可重复的读,但是可能出现幻像。在使用这个隔离级别时,只锁定事务实际检索和修改的行。因此,如果一个事务扫描了 1000 行,但只检索 10 行,则只有被检索的 10 行(而不是所扫描的 1000 行)被锁定。因此,如果在同一个事务中发出同一个 SELECT 语句两次或更多次,那么每次产生的结果数据集可能不同。
与可重复读隔离级别一样,在读稳定性隔离级别下运行的事务可以检索一个行集,并可以对它们执行任意操作,直到事务终止。在这个事务存在期间,其他事务不能执行那些会影响这个事务检索到的行集的更新或删除操作;但是其他事务可以执行插入操作。如果插入的行与第一个事务的查询的选择条件匹配,那么这些行可能作为幻像出现在后续产生的结果数据集中。其他事务对其他行所做的更改,在提交之前是不可见的。
4、游标稳定性隔离级别(默认级别)
游标稳定性隔离级别在隔离事务效果方面非常宽松。它可以防止脏读;但有可能出现不可重复的读和幻像。这是因为在大多数情况下,游标稳定性隔离级别只锁定事务声明并打开的游标当前引用的行。
当使用游标稳定性隔离级别的事务通过游标从表中检索行时,其他事务不能更新或删除游标所引用的行。但是,如果被锁定的行本身不是用索引访问的,那么其他事务可以将新的行添加到表中,以及对被锁定行前后的行进行更新和/或删除操作。所获取的锁一直有效,直到游标重定位或事务终止为止。(如果游标重定位,原来行上的锁就被释放,并获得游标现在引用的行上的锁。)此外,如果事务修改了它检索到的任何行,那么在事务终止之前,其他事务不能更新或删除该行,即使在游标不再位于被修改的行。与可重复读和读稳定性隔离级别一样,其他事务在其他行上进行的更改,在这些更改提交之前对于使用游标稳定性隔离级别的事务(这是默认的隔离级别)是不可见的。
5、未提交的读隔离级别(最低级别)
未提交的读隔离级别是最不严格的隔离级别。实际上,在使用这个隔离级别时,仅当另一个事务试图删除或更改被检索的行所在的表时,才会锁定一个事务检索的行。因为在使用这种隔离级别时,行通常保持未锁定状态,所以脏读、不可重复的读和幻像都可能会发生。因此,未提交的读隔离级别通常用于那些访问只读表和视图的事务,以及某些执行 SELECT 语句的事务(只要其他事务的未提交数据对这些语句没有负面效果)。
顾名思义,其他事务对行所做的更改在已经提交之前对于使用未提交的读隔离级别的事务是可见的。但是,此类事务不能看见或访问其他事务所创建的表、视图或索引,直到那些事务被提交为止。类似地,如果其他事务删除了现有的表、视图或索引,那么仅当进行删除操作的事务终止时,使用未提交的读隔离级别的事务才能知道这些对象不再存在了。(一定要注意一点:当运行在未提交的读隔离级别下的事务使用可更新游标时,该事务的行为和在游标稳定性隔离级别下运行一样,并应用游标稳定性隔离级别的约束。)
6、选择正确的隔离级别
使用的隔离级别不仅影响数据库对并发性的支持如何,而且影响并发应用程序的性能。通常,使用的隔离级别越严格,并发性就越小,某些应用程序的性能可能会越低,因为它们要等待资源上的锁被释放。那么,如何决定要使用哪种隔离级别呢?
最好的方法是确定哪些现象是不可接受的,然后选择能够防止这些现象发生的隔离级别:
● 如果正在执行大型查询,而且不希望并发事务所做的修改导致查询的多次运行返回不同的结果,则使用可重复的读隔离级别。
● 如果希望在应用程序之间获得一定的并发性,还希望限定的行在事务执行期间保持稳定,则使用读稳定性隔离级别。
● 如果希望获得最大的并发性,同时不希望查询看到未提交的数据,则使用游标稳定性隔离级别。
● 如果正在只读的表/视图/数据库上执行查询,或者并不介意查询是否返回未提交的数据,则使用未提交的读隔离级别。
7、指定要使用的隔离级别
尽管隔离级别控制事务级上的行为,但实际上是在应用程序级指定它们的:
● 对于嵌入式 SQL 应用程序,在预编译时或在将应用程序绑定到数据库(如果使用延迟绑定)时指定隔离级别。在这种情况下,使用 PRECOMPILE 或 BIND 命令 的 ISOLATION 选项来设置隔离级别。
● 对于开放数据库连接(Open Database Connectivity,ODBC)和调用级接口(Call Level Interface,CLI)应用程序,隔离级别是在应用程序运行时通过调用指定了 SQL_ATTR_TXN_ISOLATION 连接属性的 SQLSetConnectAttr() 函数进行设置的。(另外,也可以通过指定 db2cli.ini 配置文件中的 TXNISOLATION 关键字的值来设置 ODBC/CLI 应用程序的隔离级别;但是,这种方法不够灵活,不能像第一种方法那样为一个应用程序中的不同事务修改隔离级别。)
● 对于 Java 数据库连接(Java Database Connectivity,JDBC)和 SQLJ 应用程序,隔离级别是在应用程序运行时通过调用 DB2 的 java.sql 连接接口中的 setTransactionIsolation() 方法设置的。
当没有使用这些方法显式指定应用程序的隔离级别时,默认使用游标稳定性隔离级别。这个默认设置应用于从命令行处理程序(CLP)执行的 DB2 命令、SQL 语句和脚本以及嵌入式 SQL、ODBC/CLI、JDBC 和 SQLJ 应用程序。因此,也可以为从 CLP 执行的操作(以及传递给 DB2 CLP 进行处理的脚本)指定隔离级别。在这种情况下,隔离级别是通过在建立数据库连接之前在 CLP 中执行 CHANGE ISOLATION 命令设置的。
在 DB2 UDB 8.1 及更高版本中,能够指定特定查询所用的隔离级别,方法是在 SELECT SQL 语句中加上 WITH [RR | RS | CS | UR] 子句。使用这个子句的简单 SELECT 语句示例如下所示:
SELECT * FROM EMPLOYEE WHERE EMPID = '001' WITH RR
--允许读脏数据
SELECT * FROM EMPLOYEE WHERE EMPID = '001' WITH UR
如果应用程序在大多数时候需要比较宽松的隔离级别(以支持最大的并发性),但是对于其中的某些查询必须防止某些现象出现,那么这个子句就是帮助您实现目标的好方法。
关于数据库的隔离级别,简单的可以这样来理解:
● 可重复的读(Repeatable Read):锁定目标表
● 读稳定性(Read Stability):锁定目标结果集
● 游标稳定性(Cursor Stability):锁定游标打开的表的结果集的目标行
● 未提交的读(Uncommitted Read):无锁定
待续……
--学习笔记:DB2 9 基础 - 14
--彭建军
--最新更新时间:2006-12-6 9:42
----------------------------------------------------------------------
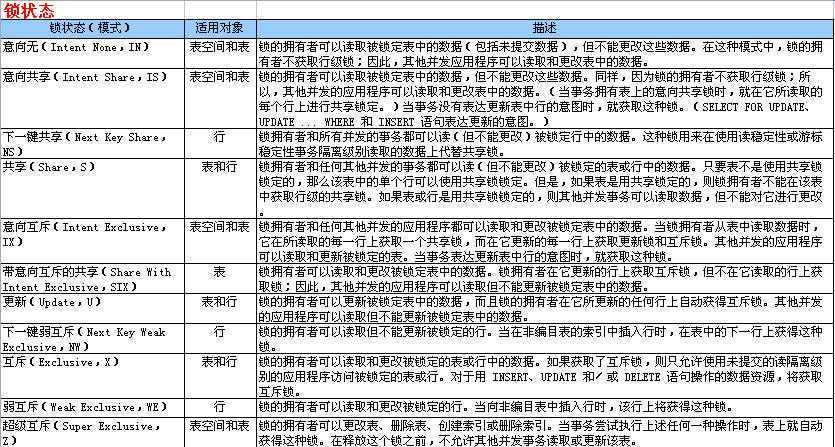
1、锁的工作原理
在上一篇学习笔记中,我们看到 DB2 通过使用锁 把事务彼此隔离开来。锁是一种用来将数据资源与单个事务关联起来的机制,其用途是当某个资源与拥有它的事务关联在一起时,控制其他事务如何与该资源进行交互。(我们称与被锁定的资源关联的事务持有 或拥有 该锁。)DB2 数据库管理程序用锁来禁止事务访问其他事务写入的未提交数据(除非使用了未提交的读隔离级别),并禁止其他事务在拥有锁的事务使用限制性隔离级别时对这些行进行更新。一旦获取了锁,在事务终止之前,就一直持有该锁;该事务终止时释放锁,其他事务就可以使用被解锁的数据资源了。
如果一个事务尝试访问数据资源的方式与另一个事务所持有的锁不兼容(稍后我们将研究锁兼容性),则该事务必须等待,直到拥有锁的事务终止为止。这被称为锁等待 事件。当锁等待事件发生时,尝试访问数据资源的事务所做的只是停止执行,直到拥有锁的事务终止和不兼容的锁被释放为止。
2、锁的属性
所有的锁都有下列基本属性:
● object:object 属性标识要锁定的数据资源。DB2 数据库管理程序在需要时锁定数据资源(如表空间、表和行)。
● size:size 属性指定要锁定的数据资源部分的物理大小。锁并不总是必须控制整个数据资源。例如,DB2 数据库管理程序可以让应用程序独占地控制表中的特定行,而不是让该应用程序独占地控制整个表。
● duration:duration 属性指定持有锁的时间长度。事务的隔离级别通常控制着锁的持续时间。
● mode:mode 属性指定允许锁的拥有者执行的访问类型,以及允许并发用户对被锁定数据资源执行的访问类型。这个属性通常称为锁状态。
3、锁状态
锁状态确定允许锁的拥有者执行的访问类型,以及允许并发用户对被锁定数据资源执行的访问类型。下图说明了可用的锁状态,按照控制递增的次序排列。

4、如何获取锁
在大多数情况下,DB2 数据库管理程序在需要锁时隐式地获取它们,因此这些锁在 DB2 数据库管理程序的控制之下。除了使用未提交读隔离级别的情况外,事务从不需要显式地请求锁。实际上,惟一有可能被事务显式地锁定的数据库对象是表。
DB2 数据库管理程序总是尝试获取行级锁。但是,可以通过执行特殊形式的 ALTER TABLE 语句来修改这种行为,如下所示:
ALTER TABLE [TableName] LOCKSIZE TABLE
其中的 TableName 标识一个现有表的名称,所有事务在访问它时都要获取表级锁。
也可以通过执行 LOCK TABLE 语句,强制 DB2 数据库管理程序为特定事务在表上获取表级锁,如下所示:
LOCK TABLE [TableName] IN [SHARE | EXCLUSIVE] MODE
其中的 TableName 标识一个现有表的名称,对于这个表应该获取表级锁(假定其他事务在该表上没有不兼容的锁)。如果在执行这个语句时指定了共享(SHARE)模式,就会获得一个允许其他事务读取(但不能更改)存储在表中的数据的表级锁;如果执行时指定了互斥(EXCLUSIVE)模式,就会获得一个不允许其他事务读取或修改存储在表中的数据的表级锁。
如果数据资源上的一种锁状态允许在同一资源上放置另一个锁,就认为这两种锁(或两种状态)是兼容的。每当一个事务持有数据资源上的锁,而第二个事务请求同一资源上的锁时,DB2 数据库管理程序会检查两种锁状态以判断它们是否兼容。如果锁是兼容的,则将锁授予第二个事务(假定没有其他事务在等待该数据资源)。但是,如果锁不兼容,则第二个事务必须等待,直到第一个事务释放它的锁为止,然后它才可以获取对资源的访问权并继续处理。(如果资源上有多个与新请求的锁不兼容的锁,则第二个事务必须等到它们全部被释放为止。)请参阅 IBM DB2 9 Administration Guide: Performance 文档(或在 DB2 信息中心搜索 Lock type compatibility 主题)以获取关于各个锁之间是否兼容的特定信息。
2、锁转换
当事务尝试访问它已经持有锁的数据资源,但是所需的访问模式需要比已持有的锁更严格的锁时,则所持有的锁的状态更改成更严格的状态。将已经持有的锁的状态更改成更严格状态的操作称为锁转换。
发生锁转换是因为一个事务同一时间内只能在一个数据资源上持有一个锁。
3、锁升级
所有的锁都需要存储空间;因为可用空间并不是无限的,所以 DB2 数据库管理程序必须限制锁可以使用的空间(这是通过 maxlocks 数据库配置参数完成的)。为了防止特定数据库代理超过已建立的锁空间限制,当获取的(任意类型的)锁过多时,会自动执行称为锁升级的过程。锁升级是一种转换,它将同一表内几个单独的行级锁转换成一个单一的表级锁。因为锁升级是在内部处理的,所以惟一可从外部检测到的结果可能只是对一个和多个表的并发访问减少了。
以下是锁升级的工作原理:当事务请求锁而锁存储空间已满时,就选择与该事务相关联的一个表,让它获取一个表级锁,释放该表的所有行级锁(从而在锁列表数据结构中让出空间),并将表级锁添加到锁列表。如果这个过程所释放的空间不够,则选择另一个表,重复这个过程,直到释放了足够的可用空间为止。这时,事务将获取所请求的锁并继续执行。但是,如果在该事务的所有行级锁都已经升级之后,仍然没有获得必要的可用锁空间,则(通过 SQL 错误编码)要求事务提交或回滚它启动以来所做的所有更改,然后事务终止。
4、锁超时
每当一个事务在特定数据资源(例如,表或行)上持有锁时,直到持有锁的事务终止并释放它所获取的所有锁之前,其他事务对该资源的访问都可能被拒绝。如果没有某种锁超时检测机制,则事务可能无限期地等待锁的释放。例如,有可能出现这种情况:一个事务在等待另一个用户的应用程序所持有的锁被释放,而该用户离开了他或她的工作站,但忘了执行一些允许应用程序终止拥有锁的事务的交互。显然,此类情况会导致极差的应用程序性能。要避免发生此类情况时阻碍其他应用程序的执行,可以在数据库的配置文件中指定锁超时值(通过 locktimeout 数据库配置参数)。该参数控制任何事务等待获取所请求的锁的时间。如果在指定的时间间隔过去之后还未获得想要的锁,则等待的应用程序接收一个错误,并回滚请求该锁的事务。分布式事务应用程序环境尤其容易产生此类情况;可以通过使用锁超时避免它们。
5、死锁
尽管可以通过建立锁超时来避免一个事务无限期地等待另一个事务释放锁的情况,但是锁超时无法解决两个或更多事务对锁的争用。这种情况称为死锁 或死锁循环。
说明死锁的发生原因的最佳方式是举例说明:假定事务 1 在表 A 上获取了互斥(X)锁,而事务 2 在表 B 上获取了互斥(X)锁。现在,假定事务 1 尝试在表 B 上获取互斥(X)锁,而事务 2 尝试在表 A 上获取互斥(X)锁。这两个事务的处理都将被挂起,直到同意第二个锁请求为止。但是,因为在任何一个事务释放它目前持有的锁(通过执行或回滚操作)之前,这两个事务的锁请求都不会被同意,而且因为这两个事务都不能释放它目前持有的锁(因为它们都已挂起并等待锁),所以它们都陷入了死锁循环。
当死锁循环发生时,除非某些外部代理进行干涉,否则所涉及的所有事务将无限期地等待释放锁。在 DB2 UDB 中,用于处理死锁的代理是称为死锁检测器 的异步系统后台进程。死锁检测器的惟一职责是定位和解决在锁定子系统中找到的任何死锁。每个数据库有自己的死锁检测器,它在数据库初始化过程中激活。激活之后,死锁检测器在大多数时间处于 “休眠” 状态,但会以预置的时间间隔被 “唤醒”,以确定锁定子系统中是否存在死锁循环。如果死锁检测器在锁定子系统中发现死锁,则随机选择死锁涉及的一个事务,终止并回滚它。选择的事务收到一个 SQL 错误编码,它所获得的所有锁都被释放;这样,剩下的事务就可以继续执行了,因为死锁循环已经被打破了。
6、锁粒度
正如先前提到的,每当一个事务在特定数据资源上持有锁时,在持有锁的事务终止之前,其他事务对该资源的访问都可能被拒绝。因此,为了进行优化以获取最大的并发性,行级锁通常比表级锁更好,因为它们所限制访问的资源要小得多。但是,因为所获取的每个锁都需要一定数量的处理时间和存储空间,才能获取锁并进行管理,所以单个表级锁需要的开销比几个单独的行级锁少。
除非另外指定,否则默认情况下获取行级锁。
可以通过使用 ALTER TABLE ... LOCKSIZE TABLE、ALTER TABLE ... LOCKSIZE ROW 和 LOCK TABLE 语句控制锁的粒度(即,获取行级锁还是表级锁)。ALTER TABLE ... LOCKSIZE TABLE 语句提供了确定粒度的全局方法,它使得所有访问特定表中行的事务都获取表级锁。
7、事务和锁定
从锁定的角度来看,所有事务通常归为以下几类之一:
● 只读:这是指只读性的事务,它们包含 SELECT 语句(它们本质上就是只读的)、指定了 FOR READ ONLY 子句的 SELECT 语句或意义虽不明确但因为在预编译和/或绑定过程中指定了 BLOCKING 选项而看作是只读的 SQL 语句。
● 倾向于更改:这是指有可能进行更改的事务,它们包含指定了 FOR UPDATE 子句的 SELECT 语句或者那些意义虽不明确但因为 SQL 预编译器解释它的方式而看作是倾向于进行更改的 SQL 语句。
● 更改:这是指一定会进行更改的事务,它们包含 INSERT、UPDATE 和/或 DELETE 语句,但不包括 UPDATE ... WHERE CURRENT OF ... 或 DELETE ... WHERE CURRENT OF ... 语句。
● 游标控制:这是指包含 UPDATE ... WHERE CURRENT OF ... 和 DELETE ... WHERE CURRENT OF ... 语句的事务。
只读事务通常使用意向共享(IS)和/或共享(S)锁。另一方面,倾向于更改的事务将更新(U)、意向互斥(IX)和互斥(X)锁用于表,将共享(S)、更新(U)和互斥(X)锁用于行。更改事务往往使用意向互斥(IX)和/或互斥(X)锁,而游标控制的事务通常使用意向互斥(IX)和/或互斥(X)锁。
当 SQL 语句准备执行时,DB2 优化器研究各种满足该语句请求的方法,并估计每种方法所涉及的执行成本。然后,DB2 优化器根据这一评估选择它认为最优的访问计划(访问计划指定满足 SQL 请求所需的操作,以及执行这些操作的顺序)。访问计划可以使用两种方法之一来访问表中的数据:通过直接地读取表(称为执行表 或关系扫描);或通过读取该表上的索引,然后检索特定索引项所引用的表行(称为执行索引扫描)。
DB2 优化器选择的访问路径(通常是根据数据库的设计确定的)会对所获取锁的数目和所使用的锁状态产生显著的影响。例如,当使用索引扫描来查找特定行时,DB2 数据库管理程序极有可能获取一个或多个意向共享(IS)行级锁。但是,如果使用表扫描,因为必须依次扫描整个表来找到特定行,所以 DB2 数据库管理程序可能会选择获取单个共享(S)表级锁。
为了维护数据完整性,DB2 数据库管理程序隐式地获取锁,获取的所有锁都在 DB2 数据库管理程序的控制之下。锁可以放置在表空间、表和行上。
为了进行优化以获取最大的并发性,行级锁通常比表级锁更好,因为它们所限制访问的资源要小得多。但是,因为所获取的每个锁都需要一定数量的存储空间和处理时间来进行管理,所以单个表级锁需要的开销比几个单独的行级锁低。
待续……
--学习笔记:DB2 9 基础 - 15
--彭建军
--最新更新时间:2006-12-6 10:05
----------------------------------------------------------------------
1、概述
DB2 9 提供了对 XQuery 的支持。XQuery 是一种专门为操作 XML 数据而设计的新的查询语言,它是 W3C 行业标准的一部分。XQuery 使用户能够在 XML 文档固有的层次结构中导航。因此,可以使用 XQuery 检索 XML 文档或文档片段。还可以编写包含基于 XML 的谓词的 XQuery,从而将不需要的数据从 DB2 将返回的结果中 “过滤出去”。XQuery 提供了许多其他功能,比如对 XML 输出进行转换以及将条件逻辑合并到查询中。
在学习如何使用 XQuery 之前,需要了解这种语言的一些基本概念。
2、XQuery 基础
XQuery 总是将 XQuery Data Model 的一个值转换为 XQuery Data Model 的另一个值。XQuery Data Model 中的一个值是由零个或更多条目组成的序列。
条目可以是:
● 任何原子值
● XML 节点(有时候称为 XML 文档片段),比如元素、属性或文本节点
● 完整的 XML 文档
XQuery 的输入常常是一个 XML 文档集合。
清单 1 显示一个 XML 文档,其中包含 8 个元素节点、1 个属性节点和 6 个文本节点。元素节点由元素标记表示。在这个文档中,Client、Address、street、city、state、zip 和两个 email 元素都是元素节点。如果仔细看看 Client 元素,就会发现它包含一个属性节点,客户的 id。文档的一些元素节点有相关联的文本节点。例如,city 元素的文本节点是 San Jose。
清单 1. 示例 XML 文档
<Address>
<street>9999 Elm St.</street>
<city>San Jose</city>
<state>CA</state>
<zip>95141</zip>
</Address>
<email>anyemail@yahoo.com</email>
<email>anotheremail@yahoo.com</email>
</Client>
XQuery 提供了几种不同的表达式,可以按照自己喜欢的任何方式组合使用它们。每个表达式都返回一系列值,这些值可以用作其他表达式的输入。最外层表达式的结果就是查询的结果。
这里讨论两种重要的 XQuery 表达式:
路径表达式:允许用户在 XML 文档的层次结构中导航(或者说 “漫游”)并返回在路径末端找到的节点。
FLWOR 表达式:它很像 SQL 中的 SELECT-FROM-WHERE 表达式。它用来遍历一系列条目并可选地返回每个条目的某些计算结果。
3、XQuery 与 SQL 的差异
许多 SQL 用户误认为 XQuery 与 SQL 非常相似。但是,XQuery 在许多方面与 SQL 差异很大,因为设计这种语言的目的是操纵具有不同性质的不同数据模型。XML 文档包含层次结构并有固有的次序。与之相反,关系 DBMS(或者更准确地说,基于 SQL 的 DBMS)支持的表是平面的和基于集合的,所以行是无序的。
数据模型中的这些差异使得用来支持它们的查询语言有很大差异。例如,XQuery 使程序员能够在 XML 的层次结构中导航。一般的 SQL(不带 XML 扩展)没有(也不需要)在表数据结构中 “导航” 的表达式。XQuery 支持有类型数据和无类型数据,而 SQL 数据总是要用特定的类型进行定义。
在 XQuery 和 SQL 之间有不少差异。这里列出一部分作参考:
XQuery 没有空值(null),因为 XML 文档忽略缺失的或未知的数据。SQL 使用空值表示缺失的或未知的数据。XQuery 返回 XML 数据的序列;SQL 返回各种 SQL 数据类型的结果集。最后,XQuery 只操作 XML 数据。SQL 操作按照传统 SQL 类型定义的列,SQL/XML(带 XML 扩展的 SQL)操作 XML 数据和传统类型的 SQL 数据。
4、XQuery 中的路径表达式
XQuery 支持 XPath 表达式,使用户能够在 XML 文档层次结构中导航,找到他们所需要的部分。我们在这里要看几个简单的示例。
XPath 表达式看起来非常像在操作传统计算机文件系统时使用的表达式。考虑一下在 Unix 或 Windows 目录中是如何导航的,就能够理解使用 XPath 在 XML 文档中进行导航的方式。
XQuery 中的路径表达式由一系列 “步” 组成,步之间由斜线字符分隔。在最简单的形式中,每一步在 XML 层次结构中下降一层,寻找前一步返回的元素的子元素。路径表达式中的每一步还可以包含一个谓词,它对这一步返回的元素进行过滤,只保留满足条件的元素。稍后将看到这样的一个示例。
一种常见的任务是从 XML 文档根(XML 层次结构的最顶层)开始导航,寻找感兴趣的某个节点。例如,要想获得清单 1 的文档中的 email 元素,可以编写下面的表达式:
清单 2. 导航到 email 元素
/Client/email
如果文档包含多个 email 元素,而您只想获得第一个,那么可以编写:
清单 3. 导航到第一个 email 元素
/Client/email[1]
除了在路径表达式中指定元素节点之外,还可以使用 @ 符号指定属性节点,从而在元素中识别出属性。下面这个路径表达式导航到 id 属性等于 123 的 Client 元素中的第一个 email 元素:
清单 4. 指定属性节点和值
/Client[@id='123']/email[1]
前面这个示例使用了一个基于属性值的过滤谓词。还可以根据其他节点值进行过滤。XPath 用户常常根据元素值进行过滤,比如下面的表达式返回住在加利福尼亚的客户的 zip 元素:
清单 5. 根据元素值进行过滤
/Client/Address[state="CA"]/zip
可以使用通配符(“*”)匹配路径表达式中各个步上的任何节点。下面的示例获取在 Client 元素的任何直接子元素下找到的任何 city 元素。
清单 6. 使用通配符
/Client/*/city
对于我们的示例文档,这将返回值为 San Jose 的 city 元素。导航到这个 city 元素的更精确的方法是:
清单 7. 导航到 city 元素的更精确的方法
/Client/Address/city
清单 8. 更多路径表达式及其含义
//* (获取文档中的所有节点)
//email (寻找文档中任何地方的 email 元素)
/Client/email[1]/text() (获得 Client 元素下第一个 email 元素的文本节点)
/Client/Address/* (选择根 Client 元素的 Address 子元素的所有子节点)
/Client/data(@id) (返回 Client 元素的 id 属性的值)
/Client/Address[state="CA"]/../email (寻找地址在加利福尼亚的客户的 email 元素。“..” 这一步导航回 Address 节点的父元素。)
注意,XPath 是大小写敏感的。在编写 XQuery 时记住一点很重要,因为这是 XQuery 与 SQL 不同的一个方面。例如,如果将路径表达式 “/client/address” 放进 XQuery,对于 清单 1 中的示例文档,不会返回任何结果。
5、XQuery 中的 FLWOR 表达式
人们常常提到 XQuery 中的 FLWOR 表达式。与 SQL 中的 SELECT-FROM-WHERE 块一样,XQuery FLWOR 表达式可以包含多个由关键字指示的子句。FLWOR 表达式的子句以下面的关键字开头:
● for:遍历一个输入序列,依次将一个变量绑定到每个输入条目
● let:声明一个变量并给它赋值,值可以是包含多个条目的列表
● where:指定对查询结果进行过滤的标准
● order by:指定结果的排序次序
● return:定义返回的结果
我们来简要介绍一下每个关键字。我们将在一节中讨论 for 和 return,所以可以看到一个完整的示例。(如果没有 return 子句,表达式就不完整。)
● for 和 return
for 和 return 关键字用来遍历一系列值并为每个值返回某些结果。下面是一个非常简单的示例:
for $i in (1, 2, 3)
return $i
在 XQuery 中,变量名前面有一个美元符号(“$”)。所以,前面的示例将数字 1、2 和 3 绑定到变量 $i(每次绑定一个数字),并对于每次绑定返回 $i 的值。前面表达式的输出是 3 个值的序列:
1
2
3
● let
有时候人们难以判断什么时候应该使用 let 关键字而不是 for。let 关键字并不像 for 关键字那样遍历一系列输入,并将每个条目依次绑定到一个变量,而是将一个单一输入值赋值给变量,但是这个输入值可以是零个、一个或更多条目的序列。因此,在 XQuery 中 for 和 let 的行为差异很大。看一个示例应该有助于澄清这一差异。请考虑下面这个使用 for 关键字的表达式,并注意返回的输出:
for $i in (1, 2, 3)
return <output> {$i} </output>
<output>1</output>
<output>2</output>
<output>3</output>
表达式的最后一行要求为每次迭代返回一个名为 output 的新元素。这个元素的值是 $i 的值。因为 $i 依次设置为数字值 1、2和 3,所以这个 XQuery 表达式返回 3 个 output 元素,它们具有不同的值。
现在考虑使用 let 关键字的类似表达式:
let $i := (1, 2, 3)
return <output>{$i}</output>
<output>1 2 3</output>
输出很不一样。输出只有一个 output 元素,它的值是 “1 2 3”。这两个示例说明了一个重点:for 关键字遍历输入序列中的条目(每次一个),并将每个条目依次绑定到一个指定的变量。与之相反,let 关键字将输入序列中的所有条目同时绑定到一个指定的变量。
● where
在 XQuery 中,where 的功能很像 SQL 中的 WHERE 子句:它使用户能够将过滤标准应用于查询。考虑以下示例:
for $i in (1, 2, 3)
where $i < 3
return <output>{$i}</output>
<output>1</output>
<output>2</output>
● order by
使用户能够让返回的结果按照指定的次序排序。考虑以下 XQuery 表达式和它的输出(输出没有按照任何用户指定的次序进行排序):
for $i in (5, 1, 2, 3)
return $i
5
1
2
3
可以使用 order by 关键字对结果进行排序。下面的示例使返回的结果按照降序排序:
for $i in (5, 1, 2, 3)
order by $i descending
return $i
5
3
2
1
6、DB2 对 XQuery 的支持
DB2 把 XQuery 当作一类语言,这允许用户直接编写 XQuery 表达式,而不需要将 XQuery 嵌入或包装到 SQL 语句中。DB2 的查询引擎将原生地处理 XQuery,这意味着它直接分析、评估和优化 XQuery,而不需要在幕后将它们转换为 SQL。如果愿意,可以编写同时包含 XQuery 和 SQL 的 “多语种” 查询。DB2 也会处理和优化这些查询。
要在 DB2 中直接执行 XQuery,必须在查询前面加上关键字 xquery。这指示 DB2 调用它的 XQuery 分析器来处理请求。如果将XQuery 作为最外层的(顶级)语言使用,那么只需这么做就够了。如果将 XQuery 表达式嵌入 SQL 中,那么不需要在前面加上xquery 关键字。
待续……
1、概述
为了帮助您学习 XQuery,本教程建立一个包含 XML 文档的 “clients” 示例表。下面几节详细地解释这个表及其内容,并描述 DB2 提供的可以用来执行 XQuery 的功能。
示例表
示例中的 clients 表包含几个传统 SQL 数据类型(比如整数和可变长度的字符串)的列,还有一个新的 SQL “XML” 数据类型的列。
前三列记录客户的 ID、姓名和状态信息。status 列的典型值包括 Gold、Silver 和 Standard。第四列包含每个客户的联系信息,比如家庭的邮政地址、电话号码、电子邮件地址等等。这些信息存储在良构的 XML 文档中。
下面是 clients 表的定义:
清单 9. clients 表的定义
create table clients
(
id int primary key not null,
name varchar(50),
status varchar(10),
contactinfo xml
);
2、示例 XML 文档
在研究如何编写针对这个表的 XQuery 之前,需要用一些示例数据填充它。下面的 SQL 语句将 6 行数据插入 clients 表。每行都包含一个 XML 文档,每个 XML 文档的结构都有所不同。例如,有的客户有电子邮件地址,而其他客户没有。
清单 10. clients 表的示例数据
-- insert sample data
insert into clients values (3227, 'Ella Kimpton', 'Gold',
'<Client>
<Address>
<street>5401 Julio Ave.</street>
<city>San Jose</city>
<state>CA</state>
<zip>95116</zip>
</Address>
<phone>
<work>4084630000</work>
<home>4081111111</home>
<cell>4082222222</cell>
</phone>
<fax>4087776666</fax>
<email>love2shop@yahoo.com</email>
</Client>'
);
insert into clients values (8877, 'Chris Bontempo', 'Gold',
'<Client>
<Address>
<street>1204 Meridian Ave.</street>
<apt>4A</apt>
<city>San Jose</city>
<state>CA</state>
<zip>95124</zip>
</Address>
<phone>
<work>4084440000</work>
</phone>
<fax>4085555555</fax>
</Client>'
);
insert into clients values (9077, 'Lisa Hansen', 'Silver',
'<Client>
<Address>
<street>9407 Los Gatos Blvd.</street>
<city>Los Gatos</city>
<state>CA</state>
<zip>95032</zip>
</Address>
<phone>
<home>4083332222</home>
</phone>
</Client>'
);
insert into clients values (9177, 'Rita Gomez', 'Standard',
'<Client>
<Address>
<street>501 N. First St.</street>
<city>Campbell</city>
<state>CA</state>
<zip>95041</zip>
</Address>
<phone>
<home>4081221331</home>
<cell>4087799881</cell>
</phone>
<email>golfer12@yahoo.com</email>
</Client>'
);
insert into clients values (5681, 'Paula Lipenski', 'Standard',
'<Client>
<Address>
<street>1912 Koch Lane</street>
<city>San Jose</city>
<state>CA</state>
<zip>95125</zip>
</Address>
<phone>
<cell>4085430091</cell>
</phone>
<email>beatlesfan36@hotmail.com</email>
<email>lennonfan36@hotmail.com</email>
</Client>'
);
insert into clients values (4309, 'Tina Wang', 'Standard',
'<Client>
<Address>
<street>4209 El Camino Real</street>
<city>Mountain View</city>
<state>CA</state>
<zip>95033</zip>
</Address>
<phone>
<home>6503310091</home>
</phone>
</Client>'
);
3、查询环境
本教程中的所有查询都设计为交互式地执行。可以通过 DB2 命令行处理程序或 DB2 Control Center 的 DB2 Command Editor 执行这些查询。本教程中的示例使用 DB2 命令行处理程序。
可以修改 DB2 命令行处理程序的默认设置,以便更容易处理 XML 数据。例如,下面的命令(从一个 DB2 命令窗口中发出)将以某种方式启动 DB2 命令行处理程序,这种方式让 XQuery 结果以容易阅读的格式显示:
清单 11. 设置 DB2 命令行处理选项
db2 -i -d
这个命令使 DB2 在显示的 XQuery 结果中增加额外的空白。DB2 实际上并不将这些空白添加到数据中。应用程序看到的返回条目中也没有额外的空白 —— 这些空白只出现在 DB2 命令行处理程序窗口中。
三、简单的 XML 数据检索操作
在本节中,将学习如何编写检索整个 XML 文档和 XML 文档的特定部分(即片段)的 XQuery。为此,将使用 XPath 表达式和 FLWOR 表达式。
2、检索 DB2 中存储的完整 XML 文档
在作为顶级语言运行时,XQuery 需要一个输入数据的来源。在 DB2 中,指定输入数据来源的一种方法是调用函数 db2-fn:xmlcolumn。
这个函数有一个输入参数,这个参数标识用户感兴趣的 DB2 表和 XML 列。db2-fn:xmlcolumn 函数返回给定的列中存储的 XML 文档序列。例如,以下查询返回包含客户联系信息的 XML 文档序列:
清单 12. 返回客户联系数据的简单 XQuery
xquery
db2-fn:xmlcolumn('CLIENTS.CONTACTINFO')
除非另外指定,DB2 会在内部编目表中将表和列名转换为大写。因为 XQuery 是大小写敏感的,所以小写的表和列名与 DB2 编目中的大写名称不匹配。
3、检索特定的 XML 元素
用户常常希望检索 XML 文档中的特定元素。用 XQuery 完成这个任务很容易。假设希望检索所有提供了传真号的客户的传真号。下面是编写这种查询的一种方法:
清单 14. 检索客户传真号的 FLWOR 表达式
xquery
for $y in db2-fn:xmlcolumn('CLIENTS.CONTACTINFO')/Client/fax
return $y
第一行指示 DB2 调用它的 XQuery 分析器。下一行指示 DB2 遍历 CLIENTS.CONTACTINFO 列中包含的 Client 元素的 fax 子元素。每个 fax 元素依次绑定到变量 $y。第三行指示对于每次迭代返回 $y 的值。
清单 16. 检索客户传真号的路径表达式
xquery
db2-fn:xmlcolumn('CLIENTS.CONTACTINFO')/Client/fax
假设不希望从查询获得 XML 片段,而是获得 XML 元素值的文本表示。为此,可以在 return 子句中调用 text() 函数:
清单 17. 检索客户传真号的文本表示的两个查询
xquery
for $y in db2-fn:xmlcolumn('CLIENTS.CONTACTINFO')/Client/fax
return $y/text()
(或)
xquery
db2-fn:xmlcolumn('CLIENTS.CONTACTINFO')/Client/fax/text()
清单 19. 检索复杂 XML 类型的 XQuery
xquery
for $y in db2-fn:xmlcolumn('CLIENTS.CONTACTINFO')/Client/Address
return $y
(或)
xquery
db2-fn:xmlcolumn('CLIENTS.CONTACTINFO')/Client/Address
1、指定单一过滤谓词
我们先研究一下如何返回邮政编码为 95116 的所有客户的邮政地址。可以将 where 子句结合进 XQuery,从而根据 DB2 中存储的示例XML 文档中的 zip 元素值对结果进行过滤。将一个 where 子句添加到 清单 19 中的 FLWOR 表达式中,从而只获得感兴趣的地址,如下所示:
清单 21. 带 “where” 子句的 FLWOR 表达式
xquery
for $y in db2-fn:xmlcolumn('CLIENTS.CONTACTINFO')/Client/Address
where $y/zip="95116"
return $y
添加的 where 子句相当简单。for 子句依次将变量 $y 绑定到每个地址。这个 where 子句包含一个简短的路径表达式,它从每个地址导航到其中嵌套的 zip 元素。仅当这个 zip 元素的值等于 95116 时,这个 where 子句才为真(因此获得这个地址)。
(或)
xquery
db2-fn:xmlcolumn('CLIENTS.CONTACTINFO')/Client/Address[zip="95116"]
2、指定多个过滤谓词
当然,通过根据邮政编码值进行过滤,也可以返回与街道地址无关的元素。还可以在一个查询中根据多个 XML 元素值进行过滤。下面的查询返回那些住在 San Jose 市或者邮政编码为 95032(这是加利福尼亚 Los Gatos 的邮政编码)的客户的电子邮件信息。
清单 24. 用 FLWOR 表达式根据多个 XML 元素值进行过滤
xquery
for $y in db2-fn:xmlcolumn('CLIENTS.CONTACTINFO')/Client
where $y/Address/zip="95032" or $y/Address/city="San Jose"
return $y/email
(或)
xquery
db2-fn:xmlcolumn('CLIENTS.CONTACTINFO')/Client[Address/zip="95032"
or Address/city="San Jose"]/email;
这个示例修改了 for 子句,从而将变量 $y 绑定到 Client 元素而不是 Address 元素。这样就可以根据子树的一部分(Address)对 Client 元素进行过滤,但是返回子树的另一部分(email)。where 子句和 return 子句中的路径表达式必须相对于绑定到变量(在这个示例中是 $y)的元素。
3、XQuery 和 SQL 之间差异的实际示例
● 对于没有提供电子邮件地址的客户,没有返回 XML 数据。
在我们的 示例数据 中,有四个客户满足查询的选择条件(住在 San Jose 或者邮政编码为 95032),但是这一事实没有反映在查询结果中。为什么呢?因为其中两个客户的记录中没有 email 元素。因为 XQuery 不使用空值,这些 “缺失的” 信息不会反映在结果中。
● 输出没有表明哪些电子邮件地址来自同一个 XML 文档。
仔细看 示例数据,就会发现 清单 26 所示的最后两个电子邮件地址包含在同一个 XML 文档中(也就是说,它们属于同一个客户)。这一点在输出中看不出来。
在某些情况下,这两种表现可能正是我们需要的,但在其他情况下可能不理想。例如,如果希望向记录的每个帐号发送一封电子邮件,那么会遍历 XML 格式的客户电子邮件地址列表,这在应用程序中很容易办到。但是,如果希望向每个客户只发送一次通知,包括那些只提供了街道地址的客户,那么前面的 XQuery 就不够了。
可以以多种方式改写前面的查询,让返回的结果以某种方式表达出缺失的信息,并表明多个电子邮件地址来自同一个客户记录(即,同一个 XML 文档)。在本教程后面,您将学到如何编写这样的查询。但是,如果只是希望返回的列表中对于每个客户只包含一个电子邮件地址,那么只需稍稍修改前面的查询:
清单 27. 返回客户的第一个 email 元素
xquery
for $y in db2-fn:xmlcolumn('CLIENTS.CONTACTINFO')/Client
where $y/Address/zip="95032" or $y/Address/city="San Jose"
return $y/email[1]
(或)
xquery
db2-fn:xmlcolumn('CLIENTS.CONTACTINFO')/Client[Address/zip="95032"
or Address/city="San Jose"]/email[1];
这两个查询都指示 DB2 返回在符合条件的 XML 文档(客户联系记录)中找到的第一个 email 元素。如果对于某个符合条件的客户没有找到电子邮件地址,那么它不返回这个客户的任何信息。
1、将 XML 转换为 HTML
在基于 Web 的应用程序中,常常需要将全部或部分 XML 文档转换为 HTML 以便进行显示。利用 XQuery 很容易完成这个过程。请考虑以下查询,它检索客户的地址、按邮政编码对结果进行排序并将输出转换为 XML 元素,这些元素是一个无序 HTML 列表的组成部分:
清单 29. 查询 DB2 XML 数据并返回 HTML 形式的结果
xquery
<ul> {
for $y in db2-fn:xmlcolumn('CLIENTS.CONTACTINFO')/Client/Address
order by $y/zip
return <li>{$y}</li>
} </ul>
这个查询以 xquery 关键字开头,从而向 DB2 分析器表示 XQuery 用作主要语言。第二行使无序列表的 HTML 标记(<ul>)出现在结果中。它还引入一个花括号,这是这个查询中使用的两对花括号中的第一对。花括号让 DB2 计算并处理其中包含的表达式,而不是将它作为字符串对待。
第三行遍历客户的地址,依次将变量 $y 绑定到每个 Address 元素。第四行包含一个 order by 子句,它指定结果必须根据客户的邮政编码(即绑定到 $y 的每个 Address 的 zip 子元素)进行升序排序(这是默认次序)。return 子句表示将 Address 元素包围在 HTML 列表项标记中,然后再返回。最后一行结束查询并完成 HTML 无序列表标记。
2、使用转换表示 XML 文档中缺失的或重复的元素
我们来考虑前面提出的一个主题:如何编写 XQuery 在返回的结果中表示缺失的值,以及表示一个 XML 文档(比如一个客户记录)包含重复的元素(比如多个电子邮件地址)。一种方法涉及到将返回的输出包装在一个新的 XML 元素中,如以下查询所示:
清单 31. 在 XQuery 结果中表示缺失的值或重复的元素
xquery
for $y in db2-fn:xmlcolumn('CLIENTS.CONTACTINFO')/Client
where $y/Address[zip="95032"] or $y/Address[city="San Jose"]
return <emailList> {$y/email} </emailList>
运行这个查询会返回一系列 emailList 元素,每个符合条件的客户记录都有一个 emailList 元素。每个 emailList 元素将包含电子邮件数据。如果 DB2 在一个客户的记录中只找到一个电子邮件地址,那么它会返回这个元素及其值。如果找到多个电子邮件地址,就会返回所有 email 元素及其值。最后,如果没有找到电子邮件地址,就会返回一个空的 emailList 元素。
可以使用几个简单的关键字将条件逻辑结合进 XQuery 中。
假设您要联络每位客户。您最希望通过电子邮件与他们取得联络,但如果没有他们的电子邮件地址,那么就向他们家里打电话。如果也没有家庭电话号码,就通过邮局邮寄一封信。因此,需要查询 DB2 clients 表,获得一个包含每个客户的单一电子邮件地址、家庭电话号码或邮政地址的联系列表。
如果将条件逻辑结合进 XQuery 中,这个任务就很容易完成。获得所需信息的一种方法如下:
清单 33. 具有分三部分的条件表达式的 XQuery
xquery
for $y in db2-fn:xmlcolumn('CLIENTS.CONTACTINFO')/Client
return (
if ($y/email) then $y/email[1]
else if ($y/phone/home) then <homePhone>{$y/phone/home/text()}</homePhone>
else $y/Address)
我们来看看这个查询的第四行到第六行。可以看到,它们是 return 子句的组成部分,因此决定查询的输出是什么。
第四行检查文档中是否至少有一个 email 元素;如果有,那么它指定应该返回第一个 email 元素。如果没有 email 元素,那么执行第五行。它指示 DB2 在 phone 元素下寻找 home 元素。如果文档中包含家庭电话号码,那么提取它的文本节点并作为新的“homePhone” 元素的一部分返回。最后,如果客户的联系文件(XML 文档)中没有电子邮件地址和家庭电话号码,那么 DB2 返回完整的 Address 元素。因为 clients 表 中的所有记录都包含邮政地址,所以这个查询的逻辑确保 DB2 会为每个客户返回一种联系方式。
1、将 SQL 嵌入 XQuery 中
要将 SQL 嵌入 XQuery 中,需要使用 db2-fn:sqlquery 函数替代 db2-fn:xmlcolumn 函数。db2-fn:sqlquery 函数执行一个 SQL 查询并只返回选择的数据。传递给 db2-fn:sqlquery 的 SQL 查询必须只返回 XML 数据;这使 XQuery 能够进一步处理 SQL 查询的结果。
我们用一个示例将已经讨论的许多概念结合起来。假设希望获得住在 San Jose 的 Gold 客户的所有电子邮件地址。如果一个客户有多个电子邮件地址,那么希望这些地址在输出中是同一个记录的组成部分。最后,如果符合条件的 Gold 客户没有提供电子邮件地址,那么希望检索他的邮政地址。编写这样的查询的一种方法如下:
清单 35. 将 SQL 嵌入包含条件逻辑的 XQuery 中
xquery
for $y in
db2-fn:sqlquery('select contactinfo from clients where status=''Gold'' ')/Client
where $y/Address/city="San Jose"
return (
if ($y/email) then <emailList>{$y/email}</emailList>
else $y/Address
)
我们仔细看看第三行,这里嵌入了一个 SQL 语句。这个 SELECT 语句包含一个基于 status 列的查询谓词,将这个 VARCHAR 列的值与字符串 Gold 进行比较。在 SQL 中,这样的字符串要包围在单引号中。尽管这个示例看起来似乎使用了双引号,但实际上是在比较值前后使用了两个单引号(''Gold'')。“额外的” 单引号是转义字符。如果在基于字符串的查询谓词外使用双引号代替单引号,就会出现语法错误。
2、将 XQuery 嵌入 SQL 中
一定要注意,也可以将 XQuery 嵌入 SQL 中。实际上,DB2 9 提供了对标准 SQL/XML 函数的支持,这些函数常常用来构造以 SQL 为最外层(即顶级)语言的混合型查询。
有两个函数值得注意:
XMLExists:允许导航到 XML 文档中的一个元素(或其他类型的节点)并对特定的条件进行测试。在 SQL WHERE 子句中指定时,XMLExists 将返回的结果限制为那些包含满足指定条件(即指定的条件为 “true”)的 XML 文档的行。您可能猜到了,应该将XQuery 表达式作为输入传递给 XMLExists 函数,从而导航到文档中感兴趣的节点。
XMLQuery:允许将 XML 放到 SQL/XML 查询返回的 SQL 结果集中。它通常用来从 XML 文档中检索一个或多个元素。同样,XMLQuery 函数也以 XQuery 表达式作为输入。
考虑以下查询。这个查询将 SQL 用作顶级语言并包含对 XMLQuery 和 XMLExists 函数的调用:
清单 37. 将 XQuery 路径表达式嵌入 SQL 来获取和限制 XML 数据
select name, status,
xmlquery('$c/Client/phone/home' passing contactinfo as "c")
from clients
where xmlexists('$y/Client/Address[zip="95032"]' passing contactinfo as "y")
这个查询返回的结果集包括客户姓名、状态和家庭电话号码列。前两列包含 SQL VARCHAR 数据,第三列包含从符合条件的 XML 文档中提取的一个 XML 元素。我们来仔细看看这个查询的第二行和第四行。
第二行在 SELECT 子句中调用 XMLQuery,这表示这个函数返回的结果应该作为 SQL 结果集中的一列。我们指定一个 XQuery 路径表达式作为这个函数的输入,这个表达式让 DB2 导航到 Client 元素下面的 phone 元素的 home 子元素。这个路径表达式引用一个变量($c),这个变量引用 contactinfo 列。
第四行在 SQL WHERE 子句中调用 XMLExists,这表示 DB2 应该根据一个 XML 谓词对结果进行限制。这个谓词是在路径表达式中指定的,它表示我们只对具有特定邮政编码的客户感兴趣。同样,作为这个 SQL/XML 函数的输入提供的路径表达式定义一个变量(在这个示例中是 $y),这个变量标识 DB2 将在哪里寻找 XML 文档(在 contactinfo 列中)。
--DB2 9 基础 全文完毕--
后记:科学在发展、技术在进步。人也应该与时俱进,落伍了可不好哦~古人云:学无止境。然也。
--学习笔记:DB2 9 基础 - 17(终结篇)

如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞0作者其他文章
评论 0 · 赞 1
评论 0 · 赞 2
评论 0 · 赞 0
评论 0 · 赞 0
评论 0 · 赞 0
添加新评论0 条评论