【有容云干货-容器系列】Kubernetes调度核心解密:从Google Borg说起
在之前“容器生态圈脑图大放送”文章中我们根据容器生态圈脑图,从下至上从左至右,依次介绍了容器生态圈中8个组件,其中也提到Kubernetes ,是一个以 Google Borg 为原型的开源项目。可实现大规模、分布式、高可用的容器集群。本篇我们重点介绍Kubernetes前世今生。
目前三大主流的容器平台Swarm, Mesos和Kubernetes具有不同的容器调度系统:
Swarm的特点是直接调度Docker容器,并且提供和标准Docker API一致的API。
Mesos针对不同的运行框架采用相对独立的调度系统,其中Marathon框架提供了Docker容器的原生支持。
Kubernetes则采用了Pod和Label这样的概念把容器组合成一个个的互相存在依赖关系的逻辑单元。
相关容器被组合成Pod后被共同部署和调度,形成服务(Service)。这个是Kubernetes和Swarm,Mesos的主要区别。相对来说,Kubernetes采用这样的方式简化了集群范围内相关容器被共同调度管理的复杂性。换一种角度来看,Kubernetes采用这种方式能够相对容易的支持更强大,更复杂的容器调度算法。
谈到Kubernetes, 我们就不能不提到Google的Borg系统。Google的Borg系统群集管理器负责管理几十万个以上的jobs,来自几千个不同的应用,跨多个集群,每个集群有上万个机器。它通过管理控制、高效的任务包装、超售、和进程级别性能隔离实现了高利用率。它支持高可用性应用程序与运行时功能,最大限度地减少故障恢复时间,减少相关故障概率的调度策略。Kubernetes的架构设计基本上是参照了Google Borg。
本文结合Google发布的相关论文和视频,初步介绍了Google Borg的资源调度,以及它对Kubernetes容器调度系统产生的影响和未来走向。关于本文内容的具体技术细节描述请参见Google论文以及Kubernetes文档。
Borg调度介绍
本文的第一部分我们先介绍一下看看Borg。 Google的Borg系统运行几十万个以上的任务,来自几千个不同的应用,跨多个集群,每个集群(cell))有上万个机器。它通过管理控制、高效的任务包装、超售、和进程级别性能隔离实现了高利用率。它支持高可用性应用程序与运行时功能,最大限度地减少故障恢复时间,减少相关故障概率的调度策略。以下就是Borg的系统架构图。其中Scheduler负责任务的调度。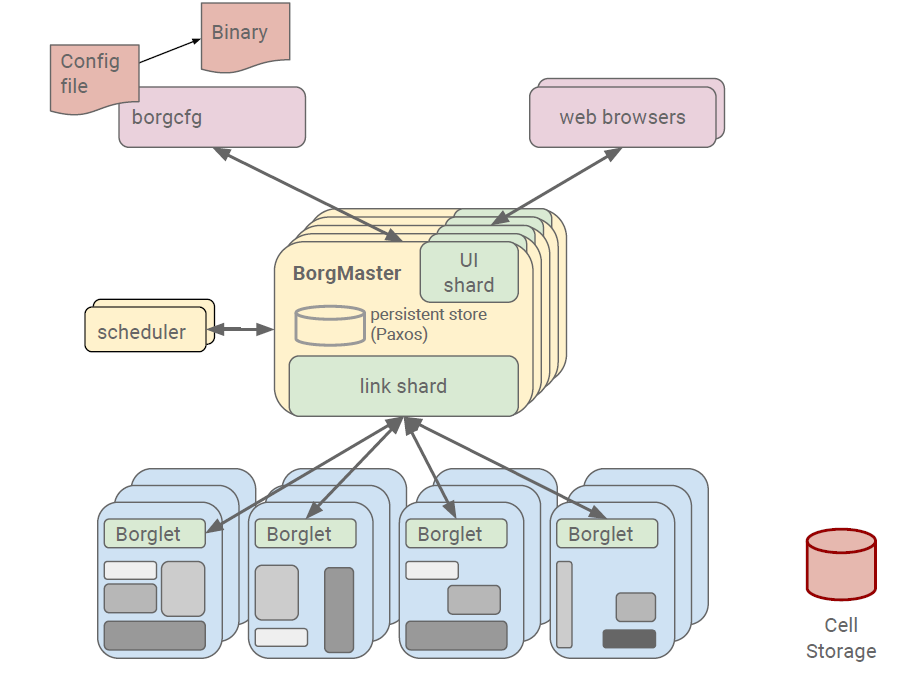
Borg调度测试
Borg对开发者隐藏了系统资源管理和故障处理细节,我们来从开发者的角度来看如何在Borg中运行一万个Hello World的任务。开发者只需要完成以下config file并且提交给Borg。
大家可以看到这样的一个config file包含了集群名称,任务二进制, 资源要求以及Replica数量。Kubernetes的YAML文件很大程度上继承了这些配置项。
当我们提交这样一个Hello World 任务给Borg后,调度器Scheduler会根据系统资源自动部署一万个Hello World任务到主机上。下图是一个部署时间表。
可以看到经过了3分钟后大约一万个任务就开始运行了。原因在于其中会有一些任务因为各种各样的原因停止运行。
下图可以看到3分钟后大概只有9993个任务在运行。Borg会自动进行错误处理并且部署新的任务。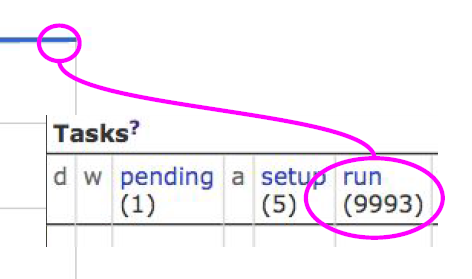
Borg调度核心
那么如何提升整个Borg系统的资源利用率呢?核心的解决方案就是根据主机资源合理的调度任务,提高系统效率。Borg主要从以下几个方面着手:
1、在同一台主机上跑多个任务
2、采用最优的打包算法
合理的把成比例的CPU、Memory资源分配给任务,避免资源阻塞造成浪费。下图橙色标识的主机就是因为CPU或者内存资源占用超过合理比例而造成另外一种资源的浪费。 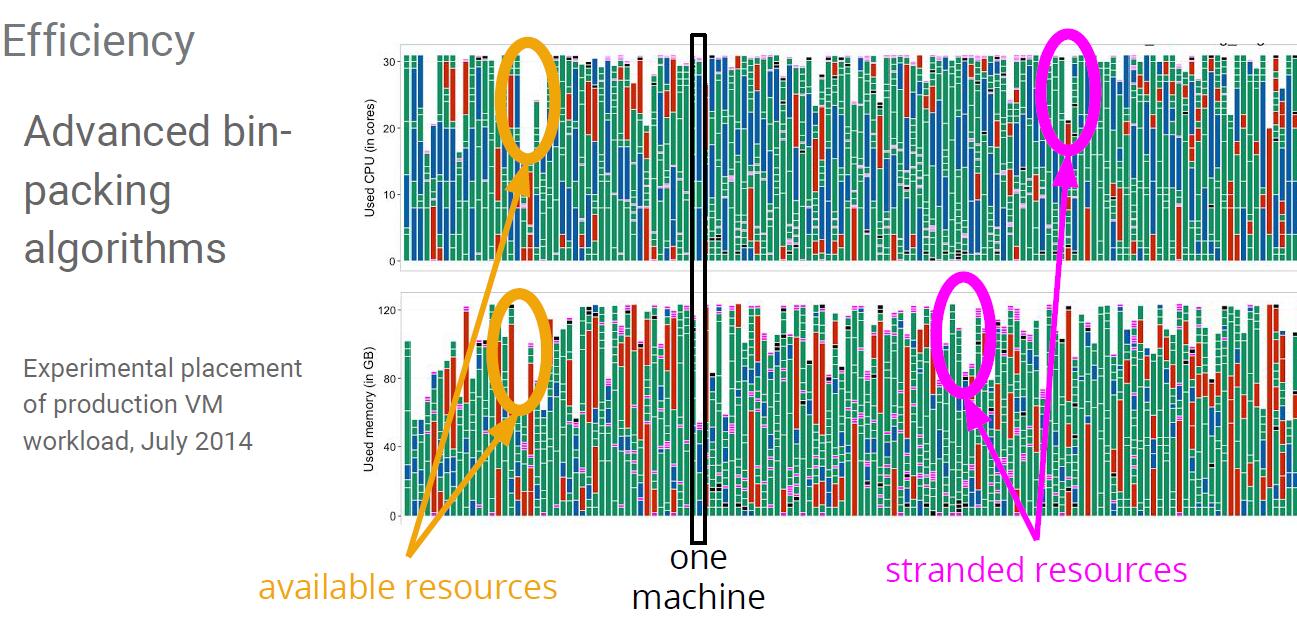
3、在系统中同时跑生成和非生产任务
Borg系统的任务分为生产型(Prod)任务,即高优先级任务和非生产的(non-prod)任务。大多数长期服务是Prod的,大部分批处理任务是non-prod的。通常情况下,生产型任务会保留一部分资源以应付极端情况,这些资源可以被用来跑非生产型应用,当生产型任务需要更多资源的时候,非生产型任务会被调度出系统。
4、资源回收
从下图可以看到,Borg会根据现有资源消耗情况评估任务对未来资源的需求作为Reservation,把绿色部分的资源回收再利用给那些可以忍受低质量资源的工作。Borg调度器使用限制资源(limit)来计算Prod任务的可用性,这些Prod任务从来不依赖于回收的资源,也不提供超售的资源;对于non-prod的任务则使用了目前运行任务的Reservation,新的任务也可以被调度到回收资源上去。当一台主机因为对资源预估不足时,Borg会限制或者杀掉non-prod任务。资源预估可以采用激进或者保守的策略,Borg目前采用的介于两者之间的中庸策略。
Kubernetes借鉴了Borg的整体架构思想。如下图,其中Pod调度也是由Scheduler组件完成的。
有一种情况下,Scheduler不参与Pod调度,那就是用NodeName指定部署主机。
Kubernetes资源调度
和Borg类似,Kubernetes的资源分为两种属性。可压缩资源(例如CPU循环,Disk I/O带宽)都是可以被限制和被回收的,对于一个Pod来说可以降低这些资源的使用量而不去杀掉Pod。不可压缩资源(例如内存、硬盘空间)一般来说不杀掉Pod就没法回收。未来Kubernetes会加入更多资源,如网络带宽,存储IOPS的支持。
Kubernetes调度器使用Predicates和Priorites来决定一个Pod应该运行在哪一个节点上。Predicates是强制性规则,用来形容主机匹配Pod所需要的资源,如果没有任何主机满足该Predicates, 则该Pod会被挂起,直到有主机能够满足。可用的Predicates如下:
PodFitPorts:没有任何端口冲突
PodFitsResurce:有足够的资源运行Pod
NoDiskConflict:有足够的空间来满足Pod和链接的数据卷
MatchNodeSelector:能够匹配Pod中的选择器查找参数。
HostName:能够匹配Pod中的Host参数
如果调度器发现有多个主机满足条件,那么Priorities就用来判断哪一个主机最适合运行Pod。Priorities是一个键值对,key表示名称,value表示权重。可用的Priorities如下:
LeastRequestdPriority:计算Pods需要的CPU和内存在当前节点可用资源的百分比,具有最小百分比的节点就是最优的。
BalanceResourceAllocation:拥有类似内存和CPU使用的节点。
ServicesSpreadingPriority:优先选择拥有不同Pods的节点。
EqualPriority:给所有集群的节点同样的优先级,仅仅是为了做测试。
Kubernetes调度总结
为了对pod所运行时要求的资源做出限制,Kubernetes通过配额YAML文件来设置Resource quotas和limit,从而管理独立Pod以及项目中所有Pod(即Namespace)的资源要求。未来Kubernetes会针对Pod资源QoS做出更多功能增强,以应对日益复杂的容器应用需求。
我们可以看到基于资源分配的任务调度是Borg和Kubernetes的核心组件。两者的调度模块都处于整个系统的核心位置。Kubernetes的调度策略源自Borg, 但是为了更好的适应新一代的容器应用,以及各种规模的部署,Kubernetes的调度策略相应做的更加灵活,也更加容易理解和使用。
本文来源:http://www.youruncloud.com/blog/116.html
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞0作者其他文章
评论 0 · 赞 0
评论 0 · 赞 4
评论 0 · 赞 0
评论 0 · 赞 0
评论 0 · 赞 0
添加新评论0 条评论