一个SQL引发的血案
作者:陈思
文章来自微信公众号平台人生
大家有没有遇到过这样的恐怖场景:一条运行平稳的sql语句突然变慢,耗费大量系统资源,最终拖垮整个数据库。本期数据库运维团队与大家分享一则生产案例,看看一条逻辑读只有16的“简单”sql是如何消耗掉主机全部CPU资源的。
1.案发现场
某应用系统Weblogic中间件等待连接数异常增多,Weblogic连接池访问数据库的连接都处于等待数据库返回结果的状态。数据库RAC两节点CPU使用率均达到100%,内存、I/O等其他资源无异常,主机登陆缓慢,几乎无法通过sqlplus登入数据库进行操作。通过RAC切换或重启数据库均无法得到解决。
那么问题来了,到底是什么原因导致CPU使用率异常增长?为什么运行平稳的系统突然出现问题?为什么以前没有问题?
环境:HP-UX 11.31,Oracle 11.2.0.4 RAC
2.追踪嫌疑人
由于案发时段数据库几乎处于hang死状态,没能保留下详细的快照信息,无法生成性能分析中常用的ASH、AWR等报告。那么在这种情况下,应该如何切入继续问题分析呢?这里,向大家分享一种分析诊断的思路:
1) 通过OracleOSWatcher工具,或操作系统提供的nmon、mwa等日志,从系统层面分析主机CPU、内存等资源的性能记录,观察问题的主要表现,定位问题发生的准确时间点。
2) 挖掘问题发生时段的数据库活动会话历史,分析等待事件、会话状态等相关记录,找到导致问题发生的sql语句。
3) 观察语句的历史执行情况,分析语句的执行计划,比对所涉及对象的统计信息、数据量、数据分布等变化,找到问题发生的根本原因。
按照上面的思路,我们先通过OSW vmstat日志定位CPU使用率异常增长的准确时间点。可以看到:RAC二节点CPU使用率的user部分在30秒内从14%突增到88%,随后,由于CPU使用率持续处于100%,数据库进入hang死状态。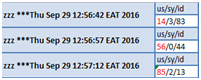
从数据库的活动会话历史可以进一步查证,12:56:40-12:57:40短短1分钟之内,session_state处于ON CPU状态的会话数量急剧增长,在12:57:32增长到36,占满全部CPU(主机CPU配置为32C)。大概10秒后陆续出现gc等其他等待事件。

那么是哪些语句处于ON CPU状态呢?我们从dba_hist_active_sess_history中定位到与某张汇率表相关的一类sql语句。由于观察到语句的sql_exec_start、sql_exec_id没有发生变化(sql_id、sql_exec_start、sql_exec_id三列可以唯一标识sql的一次执行),可以确定语句是同一个进程在持续执行,而不是执行次数多。
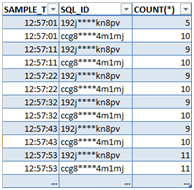


至此,我们找到了消耗CPU资源的真凶:(以其中一条语句为例,进行了敏感信息处理)
3.真相只有一个
缉拿真凶之后,我们先来看看这条语句的历史执行情况,可以发现:语句在案发时段起,性能急剧恶化,执行时间从5毫秒涨到数分钟,而且时间几乎都消耗在CPU上。
接下来再看看语句的执行计划:该SQL对TEST_RATE表进行自关联,表连接方式走的是HASH JOIN,然后GROUP BY。单表访问路径一个走索引全扫描,另一个走全表扫描。TEST_RATE是一张4M左右的小表,记录数85706。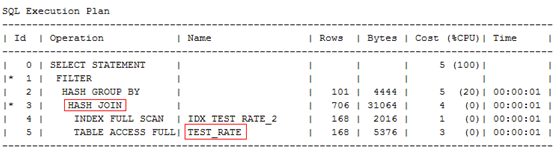

根据上述情况可以看出:
1) 执行计划没有发生改变。按照经验,整个HASH JOIN的执行时间应该在毫秒级别,与之前的执行时间相吻合。
2) 逻辑读有少量增长。由于执行时间几乎都耗在CPU上,可以推断所需要的数据应该都在内存中。那么,即使语句的逻辑读从16涨到800多,执行时间也应该在几十毫秒量级(一般情况下,如果数据块在内存中,CPU每秒可以处理十万甚至几十万的逻辑读)。
3) 没有其他异常等待事件。同样由于sql都跑在CPU上,没有出现其他异常等待事件。
鉴于问题sql都涉及TEST_RATE表,那么再来观察一下这张表是不是发生了什么变化。通过表的历史统计信息可以发现,前一晚应用跑批之后,TEST_RATE表的记录数从168涨到85706,数据量发生较大变化,但没有及时收集统计信息,因此当前的num_rows仍为168。
由此可以猜测,很有可能是表的数据量和数据分布发生变化,导致语句执行变慢。但问题又来了:按照经验,整个HASH JOIN的执行时间基本等同于两张表的单表访问时间,即使TEST_RATE表的数据量涨到8万多条,扫描的数据加起来也只有4M*2=8M,通常也可以在毫秒级完成,为什么会跑到3分多钟呢?
为了解开这个谜团,这里我们简单回顾一下HASH JOIN的原理,以两张表A和B的整表关联为例:SELECT * FROM A,BWHERE A.ID=B.ID
ORACLE内部的执行过程,可以简化为:
- 扫描A表
- HASH(A.ID)基于hash key构建hash table,将A表的数据打散到hash table的各个BUCKET桶中,存放在PGA的hash area中等待匹配
- 扫描B表
- HASH(B.ID)对于B表的每一条数据使用相同的hash函数进行探测,找到相应的BUCKET,比较表关联字段的值是否相同,返回或丢弃
HASH的目的是为了将数据打散到各个桶中。如果hash table所依赖的hash key的distinct value太少,重复值太多,就会导致某个桶(BUCKET)里有很多数据,那么B表的一条数据到该桶里比较起来就需要遍历很多数据,处理时间自然也就变长了。可以说这是HASH JOIN不适合驱动表表关联字段分布不均匀的一个缺点。
现在我们回头验证一下TEST_RATE表关联字段AAA_CD的数据分布情况(根据上面的执行计划可以看出,第3步关联的hash table是基于AAA_CD字段建立的),可以发现:以前AAA_CD的数据分布相对均匀,重复值较少;而前一天批量过后,数据分布开始不均匀,重复值变得非常多。
在案发时段,TEST_RATE表中AAA_CD字段各个值的记录数都达到3000多条,意味着几乎每个BUCKET中的数据都达到3000多行,每一次数据比对都要遍历3000多行数据!所以HASH JOIN的操作效率非常差,几乎变为了NEST LOOP操作。
(注:可以设置10104event来trace一下HASH JOIN的过程,里面有BUCKET的详细数据。)
这样一来,单条sql的执行在短时间内就几乎占满一颗CPU,多条sql并发执行导致主机CPU使用率急剧升高。随后,在前面的sql还没有执行完的情况下,后续又有新的sql发起,导致主机CPU使用率持续100%,大量sql处于等待CPU状态,数据库整体运行缓慢。
4.案结
针对上述案例中遇到的问题,提供几种解决方案供参考:
- TEST_RATE表导入大量数据后,应及时收集统计信息,以便ORACLE生成更优的执行计划。
- 对TEST_RATE表的数据进行调查和确认。如果可以删除,重建TEST_RATE表,恢复数据分布情况,降低重复值。
- 如果无法修改数据,也可以考虑通过sql profile指定更优的执行计划。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞4本文隶属于专栏

作者其他文章
评论 2 · 赞 9
评论 0 · 赞 1
评论 2 · 赞 9
评论 7 · 赞 25
评论 1 · 赞 0
添加新评论0 条评论