
利用 AIX 6.1 相关工具调优应用系统
本文中将介绍关于 AIX 6.1 中 ps、sar、tprof、netstat 等性能监视工具,以及如何用这些工具进行应用系统的性能监视和通过得到的分析数据,来发现系统存在的性能瓶颈和准备更多的优化的动作。您将了解更多有关性能优化方法的信息,而这些内容是任何优化策略所必需的部分。
优化方法
我们做系统调优,要遵循一些思想方法论。没有思想指导而茫然的动手操作,就如同黑夜里没有路灯而前进一样。针对一个应用系统的优化,有一些比较标准的流程,具体如下:
获取基准数据
压力测试和性能监视
发现瓶颈所在
优化,解决问题所在。
重复(从第二个步骤开始)
思想方法论这些东西,已经成熟了很多年,不能去怀疑了。我们需要做的,不是重新创造新的思想,而是牢记心中,贯穿行动。
工具的作用
在这些思想路灯的指引下,我们还需要一些工具的支持。“工欲善其事,必先利其器”这个道理流传了千年。这些工具有些是编译器提供给我们的,有些是我们自己打磨定制的。当然,大部分是操作系统提供给我们的。这些工具的目的是测量代码执行的时间和资源消耗数据。这些数据再和我们对代码执行的预期进行判断,协助我们定位和分析问题。
工具一般分为两大类,一种是嵌入到程序代码中使用,一种是非接触式使用。前者如 dbx、gprof、日志记录,后者如 ps/vmstat/truss 等等。具体使用哪种工具更合适,或者哪个工具更好,这个问题的答案不是绝对的。中国人喜欢用筷子吃饭,西洋人喜欢用刀叉进食。这些都是习惯,当然,中国人吃牛排时,也可以用刀叉,西洋人吃面条时,用筷子也会更好。这是不同的场景需要不同的工具。筷子、刀叉这些工具都很好,都能帮我们解决吃饭问题。没有这些工具,我们只能用手抓,想想这是多么悲催的景象。所以,根据具体的场景具体使用者的爱好来决定使用哪些工具。另外,多尝试工具的组合,可能会有更美妙的享受和收获。
瓶颈所在 CPU ? Memory ? Network ?
当完成在 AIX 平台的编译以后,需要启动应用测试,并观察运行结果是否与我们期望的一样。我们也许会很顺利,恭喜你,这可是很幸运的事情。通常情况是:大部分应用移植完成后,会有各种各样的问题表现,我们需要根据不同症状进行分门别类,并对症分析治疗。
观察应用运行情况,更多时候需要观察应用所运行的操作系统资源使用情况,从 CPU,到内存,到磁盘 I/O,再到网络通讯。这些资源的使用数据会及时反映出应用运行的健康状况。
CPU
CPU,系统运行之中枢大脑。AIX 运行的硬件平台为 Power 处理器。Power 是 IBM 设计的一款基于 RISC 架构的处理器,主要用于服务器市场的小型机平台。
CPU 资源常见的问题为使用率过高和使用率过低。我们需要知道操作系统的 CPU 具体使用值,来判定 CPU 的使用是否正常。具体谈到 CPU 使用率为高的判定条件,根据不同的应用特征而定。一般来说,如果一个生产环境系统的 CPU 使用率持续高于 80%~85% 之上,我们可以认为该环境的 CPU 资源使用过高。如果运行环境的 CPU 资源突然出现使用率过低的情况(相比较正常情况而言),说明运行的应用可能也有性能问题,导致不能充分利用 CPU 资源。
通过 AIX 提供的相关工具,我们可以很简便的了解到当前的 CPU 使用数据。这些数据包括,操作系统整体的 CPU 使用状态;个体进程的 CPU 使用状态;进程内部的线程 CPU 使用数据等等。我本人平时用起来得心应手的一些工具包括如下几个,topas、sar、ps、tprof。这几个工具的用起来比较简单,可以参看 manual 手册,网上随便 Google,也是一大堆一大堆,为了不使这篇文章看起来像 man 手册的汉化,我决定不在这里解释太多的工具参数说明,更多的介绍一下几个常用技巧。
用 topas 或者 sar,可以看到系统的 CPU 使用情况。注意 wio 一列,wio 通常表示 CPU 在 I/O 方面的使用率。
清单 1. sar 结果输出示例
sar -u 10 3
AIX lpar05 2 5 00040B1EFC00
17:54:58 %usr %sys %wio %idle
17:55:08 30 57 1 12
17:55:18 29 57 1 12
17:55:28 26 43 1 29
Average 29 53 1 18
用 tprof 命令,可以跟踪统计程序运行期间,代码中具体调用方法对 CPU 资源的消耗情况。统计的数据中,又根据不同的调用方式分为了系统 CPU 消耗,用户 CPU 消耗等等。这个工具简而言之,可以用来分析程序中哪一部分代码对 CPU 的使用率最高。下面这个例子是 Java 进程共享库部分对 CPU 的使用率。共享库使用了 29% 的 CPU 资源。这其中,libj9gc24.so 使用了 12%。这个动态库的作用是负责 Java 运行过程中的 GC(Garbage Collection)。
清单 2. tprof 结果输出示例
Total % For All Processes (SH-LIBs) = 29.42
Shared Object %
============= ======
/usr/java6/jre/lib/ppc/libj9gc24.so 11.71
/usr/java6/jre/lib/ppc/libj9jit24.so 11.44
/usr/lib/libpthreads.a[shr_xpg5.o] 2.04
/usr/java6/jre/lib/ppc/libj9vm24.so 1.63
/usr/java6/jre/lib/ppc/libzip.so 0.69
/usr/lib/libc.a[shr.o] 0.67
通过 ps 命令配合相关选项,可以看到进程内线程对 CPU 的使用情况。这是一个非常好的方法,尤其在一些 Java 进程的 CPU 性能分析的场合。Java 进程的应用大多数是多线程实现,一个 Java 进程的 CPU 的资源使用,其实就是进程内部线程的使用。能即时知道每个线程对 CPU 的使用情况,对解决 Java 的性能问题至关重要。具体的使用命令如下 (CP 一列表示 CPU 使用率,TID 表示线程 ID):
清单 3. ps 查看线程结果输出示例
ps -mo THREAD -T <pid>
USER PID PPID TID ST CP PRI SC WCHAN F TT BND COMMAND
jil2200 7274588 2294004 - A 0 60 43 * 242001 - - \java -Xms4096m
- 8978441 S 22 60 1 f1000a01001f01d8 410400 - - \---
- 9240763 S 0 78 1 f1000f0a10008d40 8410404 - - \---
- 9568481 S 0 82 1 f1000f0a10009240 8410404 - - \---
- 16187639 S 0 82 1 f1000f0a1000f740 8410404 - - \--
通过这些命令,可以观察到进程和 CPU 资源的使用情况。同时,也可以看到进程内部具体方法、线程对 CPU 的使用数据等等。有了这些,就可以很容易的处理进程 CPU 使用率过高的问题。
除了进程 CPU 使用率过高,还有一种相反的现象是 CPU 使用率过低。尤其在进行一些性能压力测试的场景里。这也是一种性能问题,需要进行分析。分析的过程也是利用这些 CPU 资源观察工具,检查问题所在。
针对 CPU 的使用率高低所产生的性能问题,有一些共性的分析点。当观察到 CPU 几乎无使用或者使用率很低时,可以检查的方向包括:一、进程内部的死锁,或者有频繁的锁同步。二,进程所依赖的外部资源堵塞;当观察到 CPU 的使用率很高时,检查的方向包括:程序代码中是否有循环代码。详见下图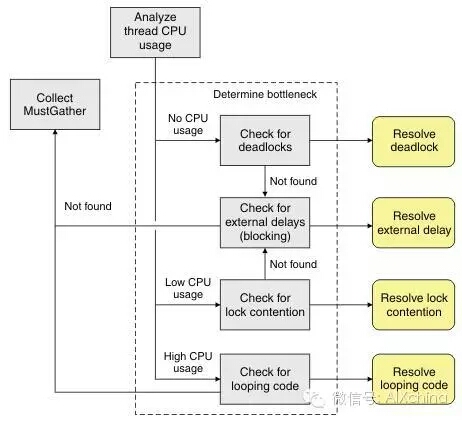
注意:很多场景下,CPU 使用率过高或者过低,往往还与其他资源使用有关系,包括网络、存储、数据库等等。切勿简单的以头痛医头,脚痛医脚的方式来处理此类问题。
Memory
内存引起的性能问题,一般来说,现象比较明显,处理起来也比较简单。
内存资源常见的问题为资源不足。资源不足有两种,一是整体操作系统内存资源不足;二是分配给进程的内存资源不足。
当操作系统内存资源不足时,会发生 Paging Space 使用率过高的现象。AIX 使用虚拟内存技术,来分配管理操作系统内存。这种管理方式将虚拟内存分为 Page。虚拟内存包括两部分,一部分是物理内存 Page,另一部分是存储硬盘的映射 Page。这两种类型 Page 的访问和运行速度是完全不一样的,相当于内存和硬盘的响应差别。简而言之,当进程使用的大量内存 Page 是存储硬盘映射时,运行速度会显著地变慢。
关于 AIX 的内存管理知识,可以参考“AIX Memory performance”获取更多的细节。
常用的观察内存资源的命令有 vmstat、topas、ps,、svmon、ulimit 等等。使用这些命令的目的是,观察系统内存资源是否有足够剩余,观察进程使用的内存资源数据。几个有用的技巧如下:
vmstat 命令可以获取很多信息。我们主要关注几个列的数值即可,分别是 fre - 表示当前虚存页面可用数量,pi/po - 页面换入换出的数量。内存资源足够的一个现象是:fre 一列的有足够多的数值,pi/po 的值很少,或者为 0。 该命令的输出结果如下:
vmstat 1 10
System Configuration: lcpu=4 mem=8192MB
kthr memory page faults cpu
r b avm fre re pi po fr sr cy in sy cs us sy id wa
2 0 852221 703268 0 0 0 0 0 0 71 161 296 0 0 99 0
2 0 852221 703268 0 0 0 0 0 0 72 177 277 0 0 99 0
4 0 852221 703268 0 0 0 0 0 0 59 62 271 0 1 99 0
ps 真是一个万用工具。ps 可以看到单个进程对 CPU 资源,以及内存资源的使用情况。注意 RSS 一列,该列表示进程驻留于物理内存的字节大小(单位为 K)。通过这个数据,可以判断进程的内存使用是否正常(譬如内存泄露等问题)。PS 查看进程内存的命令如下:
ps v 7667852 <pid>
PID TTY STAT TIME PGIN SIZE RSS LIM TSIZ TRS %CPU %MEM COMMAND
7667852 - A 0:00 0 700 9840 32768 241 284 0.0 0.0 /bin/java
svmon 的输出内容比较多,我们只需要了解简单的一点即可,Inuse - 当前进程使用的物理内存(real memory)页面消耗:Pgsp - 当前进程使用的 Paging Space 页面消耗。当 Pgsp 数值比较大的时候,要引起注意。
svmon -P 7274588
Pid Command Inuse Pin Pgsp Virtual 64-bit Mthrd 16MB
7274588 java 82413 8202 1 47882 Y Y N
ulimit 命令用来显示或设置用户一个进程的资源限制情况。这些资源主要包括:进程的数据区大小 - data;进程的堆栈区大小 - stack;进程 dump 镜像的大小 - core;进程可以打开的文件描述符数量 - nofiles。通常使用 ulimit 命令用来改变这些参数,以满足进程运行的需要。譬如:1) 进程运行时需要分配 (malloc) 使用大量内存,这时需要修改 data 数据段,建议设置为 unlimited。2) Java 进程 (WebLogic) 运行时需要使用大量文件描述符,需要修改 nofiles 数值。修改方法(假设修改为 4096)为 ulimit -n 4096
ulimit -a
time(seconds) unlimited
file(blocks) unlimited
data(kbytes) unlimited
stack(kbytes) 4194304
coredump(blocks) 2097151
nofiles(descriptors) 2000
threads(per process) unlimited
processes(per user) unlimited
I/O
摩尔定律说,每过十八个月集成电路的晶体管数量会增加一倍;存储的密度每过十二个月就会增加一倍;每过十二个月至十八个月,客户就开始担心自己的存储的容量空间是否还足够了。不过,磁盘头旋转读取的速度可没变化这么快,传输速率还在 MB 的级别速度上。这种现状造成 I/O 频频成为系统中一个拖后腿的性能短板。
在 Power 平台,一个内存地址的操作,大概会消耗 500~600 个 CPU 单元;而一个磁盘地址操作,大概需要 20,000,000 个 CPU 单元消耗,没错,两千万。相当于 40,000 次内存操作。
所以很多时候,应用系统的瓶颈,出现在 I/O 层面。如何识别 I/O 的问题,变得很重要。
操作系统磁盘 I/O 的一些性能指标包括:
吞吐量:硬盘传输数据流的速度,传输数据为读出数据和写入数据的和。其单位一般为 Kbps, MB/s 等。当传输大块不连续数据的数据,该指标有重要参考作用。
每秒 I/O 数 (I/OPS):一次磁盘的连续读或者连续写,成为一次 I/O。那么磁盘的 I/OPS 就是每秒中磁盘连续读和连续写的和。
等待时间:指磁盘读或写操作等待执行的时间,即在队列中排队的时间。如果 I/O 请求持续超出磁盘的处理能力,那么来不及处理的请求将在队列中排队等候。
通过观察通过监控以上指标,结合以往监控的历史数据,以及经验数据进行对比,就比较容易发现 I/O 的潜在问题,或者已经出现的问题。
经常用到的 sar、nmon、topas 等命令,可以提供给我们相关的 I/O 数据信息。我们主要看一下 sar 如何使用。
sar 命令可以获取很多信息。我们主要关注几个列的数值即可,分别是:%busy - 表示读取或写入设备的时间的百分比,一般来说如果磁盘使用率长时间达到 75% 或 80%, 通常会视为该磁盘较忙;avwait - 这是磁盘读或写操作等待执行的平均时间(单位为毫秒);avserv - 这是磁盘读或写操作所执行的平均时间(单位为毫秒)。当 avque 数值过高时,可能来证实表示多个人正在竞争使用该磁盘。高 avserv 值表示磁盘的速度较慢。sar 的结果如下:
速度较慢。sar 的结果如下:
sar -d 1 5
device %busy avque r+w/s Kbs/s avwait avserv
hdisk1 0 0.0 0 0 0.0 0.0
hdisk0 0 0.0 0 0 0.0 0.0
hdisk2 0 0.0 0 0 0.0 0.0
hdisk3 0 0.0 0 0 0.0 0.0
hdisk4 80 0.0 514 6137 1.2 5.3
hdisk5 100 2.6 1536 14223 26.4 5.9
cd0 0 0.0 0 0 0.0 0.0
很多时候,解决 I/O 性能问题需要磁盘、存储等性能优化方面的知识和技术。主要考虑以下以下方向:
I/O 分布均衡:尽量将 I/O 的请求合理地分布在所用到的物理磁盘上。
RAID:使用 RAID 时,尽量使应用程序 I/O 等于条带尺寸或者为条带尺寸的倍数。并选取合适的 RAID 方式,如 RAID10,RAID5 等等。
I/O 缓存:应用 I/O 缓存技术,减少直接对磁盘的 I/O 数量。可以在应用程序层面进行缓存处理,也可以在文件系统层面进行缓存设置(参考 vmtune 说明)。
数据 CACHE :利用内存读写访问比磁盘访问优越的特点,将应用程序读写频繁的文件或者数据,放置在内存中进行 cache,减少磁盘 I/O 操作,提高整体性能。
Network
在一些基于网络通信的应用系统场景下,需要注意网络引起的性能问题。常见的网络引起的性能问题主要表现在传输不稳定、丢包或者传输速率达到网卡设备极限,造成网络消息排队等方面。
在 AIX 系统上,提供了几个有用的工具来进行网络监控观察。一些工具可以用来实时诊断问题性能,另外一些工具可以显示网络数据的历史趋势和分析数据。
关于网络的设置和优化知识,有太多和太深的内容可以来进行阐述,不过在这里,我们仅了解一下如何快速利用 AIX 的几个工具,来帮我们解决常见的性能问题。
常用的判断网络性能问题的命令有 ping、netstat。几个有用的技巧如下:
ping 命令主要用来检查网络的连通性。从 ping 的结果,可以检查网络的质量、丢包率等。time 值,可以用来判断两台主机直接的网络传送延时情况,在局域网服务器之间(大多数为万兆卡光纤连接),time 值应该为 0。
ping 10.33.102.107
PING 10.33.102.107: (10.33.102.107): 56 data bytes
64 bytes from 10.33.102.107: icmp_seq=0 ttl=255 time=42 ms
64 bytes from 10.33.102.107: icmp_seq=1 ttl=255 time=20 ms
64 bytes from 10.33.102.107: icmp_seq=2 ttl=255 time=20 ms
64 bytes from 10.33.102.107: icmp_seq=3 ttl=255 time=18 ms
64 bytes from 10.33.102.107: icmp_seq=4 ttl=255 time=21 ms
netstat 是用来对网络运行进行统计观察的最常用的一个工具。netstat 有很多参数,主要用的的有 -in/ -an/ 等等。注意:使用 -in 选项时的 Ierrs 和 Oerrs 两栏。Ierrs 表示接收失败的总包数,Oerrs 表示发送失败的总包数。检查 Ierrs/Ipkts 超过 1% 时,或者 Oerrs/Opkts 超过 1% 时,此时可能要检查一下网络是否存在不稳定的情况。当使用 -an 选项时,注意 Recv-Q、Send-Q 和 state 这三栏。Recv-Q 表示接收网卡队列的排队情况,Send-Q 表示网卡发送队列的排队情况。state 表示网络连接的状态,一般为 LISTEN 或者 ESTABLISH。当出现类似 LAST_ACK、FIN_WAIT 之类的状态时,说明相关的 TCP 连接状态比较差,如果该 TCP 连接是应用程序所使用,那么需要引起注意。
netstat -in
Name Mtu Network Address Ipkts Ierrs Opkts Oerrs Coll
en1 1500 link#2 66.da.93.d1.6b.18 70136750 0 336237 0 0
en1 1500 172.153 172.153.20.65 70136750 0 336237 0 0
en0 1500 172.29.128 172.29.148.225 202571785 0 79277 0 0
netstat -an
Active Internet connections (including servers)
Proto Recv-Q Send-Q Local Address Foreign Address (state)
tcp4 0 0 .13 .* LISTEN
tcp 0 0 .21 .* LISTEN
tcp4 0 0 172.16.15.56.2049 172.16.29.200.63593 ESTABLISHED
tcp 0 0 .9510 .* LISTEN
tcp4 0 0 172.16.15.56.23 9.125.1.127.49626 LAST_ACK
tcp 0 235 172.16.15.56.45575 172.16.29.200.23 ESTABLISHED
篇幅限制,在这里不再过多阐述 AIX 的网络调优知识。
优化总结
在本文中,介绍了如何利用 AIX 6.1 相关工具来发现应用系统是否存在性能瓶颈的知识。内容包括了 AIX 平台如何监控 CPU、Memory,I/O 和 Network 等系统资源的常用命令,以及作者常用的使用技巧,并给出了一些性能问题判断经验。
性能优化是一个经验不断积累的过程。善于总结自己用顺手的工具和技巧,不断尝试思考,就会有新的收获。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞0作者其他文章
评论 1 · 赞 1
评论 0 · 赞 4
评论 1 · 赞 2
评论 0 · 赞 2
评论 0 · 赞 2
添加新评论0 条评论