查看其它 1 个回答ccww552010的回答

一、云服务告警
1.1 监控告警架构
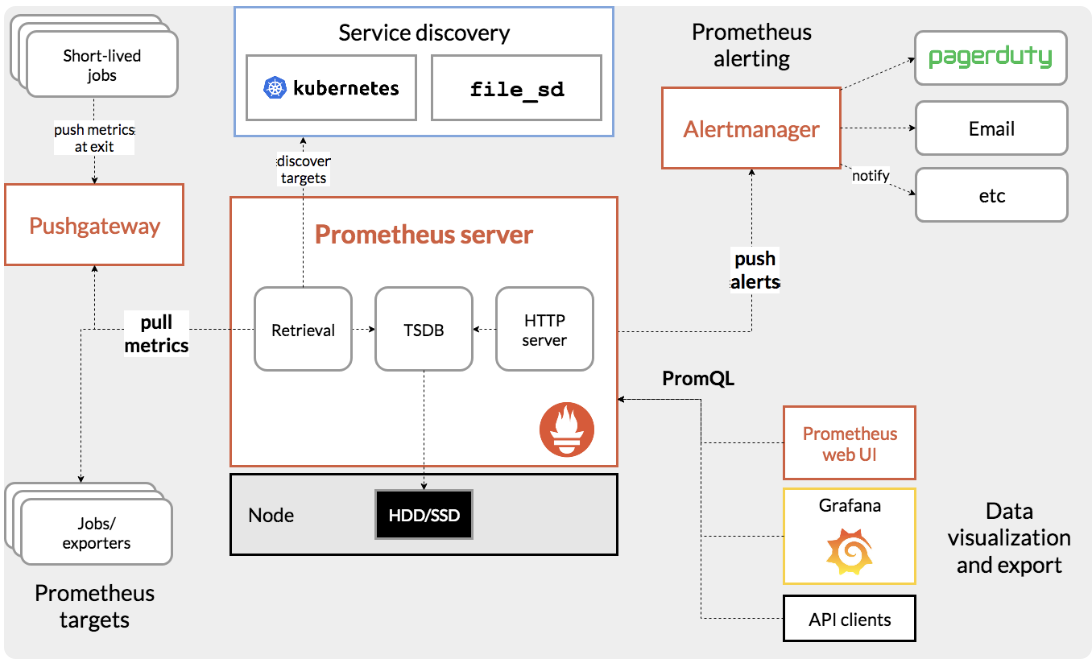
1.2 主要功能模块:
1.2.1 采集层
1. Pushgateway:推送网关,为支持short-lived(生命周期较短)作业提供一个推送网关。应用于无法pull方式获取指标的应用。
2. exporter:应用指标暴露接口。
1.2.2 存储计算层
1. Prometheus Server:主服务器,负责收集和存储时间序列数据,并对查询的数据进行计算。
2. Retrieval:指标数据采集组件,它会主动从Pushgateway或者Exporter拉取指标数据。
3. Service discovery:可以动态发现要监控的目标。
4. TSDB:监控数据存储与查询。
5. HTTP server:prometheus对外提供HTTP服务。
1.2.3 应用层
1. Alertmanager:专门用于处理alert报警的组件。
2. 数据可视化:包括Prometheus build-in WebUI、Grafana、其他基于API开发的客户端。
1.3 工作流程:
- Prometheus server定期从静态配置的 targets 或者服务发现的 targets 拉取数据(zookeeper,consul,DNS SRV Lookup等方式)。
2. 当新拉取的数据大于配置内存缓存区的时候,Prometheus会将数据持久化到磁盘,也可以远程持久化到云端。
3. Prometheus通过PromQL、API、Console和其他可视化组件展示数据。Prometheus支持很多方式图表可视化,比如Grafana,自带的Promdash。它还提供HTTP API的查询方式,自定义输出。
4. Prometheus 可以配置rules,然后定时查询数据,当条件触发的时候,会将alert推送到配置的Alertmanager。
5. Alertmanager收到告警的时候,会根据配置,聚合,去重,降噪,最后发出警告。
1.4 配置监控告警
1.4.1 配置prometheus抓取目标
global:
scrape_interval: 15s
- job_name: "node"
# 静态抓取
static_configs:
- targets:
- "192.168.100.10:20001"
- "192.168.100.11:20001
- "192.168.100.12:20001"
# 动态发现:kubernets
- job_name: kubernetes-apiservers
metrics_path: /metrics
scheme: https
kubernetes_sd_configs:
- api_server: https://192.168.2.224:6443/
role: endpoints
bearer_token_file: /prometheus/k8s_token
insecure_skip_verify: true
bearer_token_file: /prometheus/k8s_token
tls_config:
insecure_skip_verify: true
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
separator: ;
regex: default;kubernetes;https
replacement: $1
action: keep
- separator: ;
regex: (.*)
target_label: __address__
replacement: 192.168.2.224:6443
action: replace
# 动态发现:文件
- job_name: "file_job"
file_sd_configs:
- files:
- targets/prometheus*.yaml
refresh_internal: 2m1.4.2 prometheus配置告警规则
global:
scrape_interval: 15s
evaluation_interval: 15s
alerting:
alertmanagers:
- static_configs:
# alertmanager地址
- targets: ["localhost:9093"]
# 告警规则文件
rule_files:
- "*_rules.yml"
groups:
- name: example
rules:
# 告警规则
- alert: InstanceDown
expr: up == 0
for: 5m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes."二、kubernetes弹性动态扩容
2.1 HPA动态扩容原理

- 用户需要在HPA里设置的metrics类型和期望的目标metrics数值;
- HPA Controller会定期(horizontal-pod-autoscaler-sync-period配置,默认15s)reconcile每个HPA对像,reconcile里面又通过metrics的API获取该HPA的metrics实时最新数值(在当前副本数服务情况下),并将它与目标期望值比较,首先根据比较的大小结果确定是要扩缩容方向:扩容、缩容还是不变,若不需要要进行扩缩容调整就直接返回当前副本数,否则才使用HPA metrics 目标类型对应的算法来计算出deployment的目标副本数,最后调用deployment的scale接口调整当前副本数,最终实现尽可能将deployment下的每个pod的最终metrics指标(平均值)基本维持到用户期望的水平。
2.2 HPA metric指标分类
- Resource metrics——CPU核 和 内存利用率指标。
- Pod metrics——例如网络利用率和流量。
- Object metrics——特定对象的指标,比如Ingress, 可以按每秒使用请求数来扩展容器。
- Custom metrics——自定义监控,比如通过定义服务响应时间,当响应时间达到一定指标时自动扩容。
2.3 HPA扩缩容配置
2.3.1 动态扩容前提
1. 安装prometheus operator。
2. 安装promethues adatper。
3. 安装metric server。
4. apiserver开启API Aggregator 。
2.3.2 HPA配置
1. Resource metrics配置
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50注意:只支持cpu和memory
2. Pod metrics指标配置
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Pods
pods:
metric:
name: packets-per-second
target:
type: AverageValue
averageValue: 1k注意:Pod 度量指标 。这些指标从某一方面描述了 Pod, 在不同 Pod 之间进行平均,并通过与一个目标值比对来确定副本的数量。 它们的工作方式与资源度量指标非常相像,只是它们 仅 支持 target 类型为 AverageValue 。
3. Object metrics指标配置
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Object
object:
metric:
name: requests-per-second
describedObject:
apiVersion: networking.k8s.io/v1
kind: Ingress
name: main-route
target:
type: Value
value: 10k注意: (Object)度量指标 。 这些度量指标用于描述在相同名字空间中的别的对象,而非 Pod。 请注意这些度量指标不一定来自某对象,它们仅用于描述这些对象。 对象度量指标支持的 target 类型包括 Value 和 AverageValue 。 如果是 Value 类型, target 值将直接与 API 返回的度量指标比较, 而对于 AverageValue 类型,API 返回的度量值将按照 Pod 数量拆分, 然后再与 target 值比较。
4. exrternal指标配置
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: External
external:
metric:
name: queue_messages_ready
selector:
matchLabels:
queue: "worker_tasks"
target:
type: AverageValue
averageValue: 30注意: 使用外部度量指标时,需要了解你所使用的监控系统,相关的设置与使用自定义指标时类似。 外部度量指标使得你可以使用你的监控系统的任何指标来自动扩缩你的集群。 你需要在 metric 块中提供 name 和 selector ,同时将类型由 Object 改为 External 。 如果 metricSelector 匹配到多个度量指标,HorizontalPodAutoscaler 将会把它们加和。 外部度量指标同时支持 Value 和 AverageValue 类型,这与 Object 类型的度量指标相同。