3同行回答

分布式一致性缓存技术:EMC Vplex是一个集群系统,提供分布式缓存一致性保证,能够将两个或多个Vplex的缓存进行统一管理,从而使主机访问到一个整体的缓存系统。当主机向Vplex的一个缓存区域写I/O时,Vplex缓存将锁定这个缓存区域,同一时刻其他主机是无法向这个缓存区域写入I/O的。但是,当主机读取I/O时,Vplex缓存允许多个主机访问一个缓存区域,尤其是主机访问其他Vplex集群中其他Vplex节点所管理的数据时,统一缓存管理会将这个I/O的具体缓存位置告知主机,主机直接跨Vplex集群访问。分布式一致性缓存技术在实现上面,并没有强求所有的Cache都保持统一,而是基于卷缓存目录的形式来跟踪细小的内存块,并通过锁的粒度来保证数据一致性。每个引擎的cache分为本地Cache(Cache Local)和全局Cache(Cache Global),每引擎的本地Cache只有26GB,其余为全局Cache,见下图。
(4)分布式缓存模式:Vplex Local和Vplex Metro采用了写直通缓存模式,当Vplex集群的虚拟卷接收到了主机的写请求时,写I/O直接透写到该卷映射的后端存储LUN(Vplex Metro包含两套后端存储LUN)中,后端阵列确认写I/O完成后,Vplex将返回确认信号至主机,完成本次写I/O周期。写直通缓存模式需要等待后端存储阵列落盘完成,对写I/O时延要求较高。这种写直通缓存模式并适合Vplex Geo方案,该方案最大支持50ms的跨站点往返延迟,采用该缓存模式将对主机产生非常大的性能影响,对于大多数应用而言显然是无法接受的。因此,Vplex Geo采用了回写缓存模式,在该模式下,Vplex收到了主机的写请求后,直接写入引擎控制器的缓存,并将写I/O镜像至引擎另一个控制器和另一套Vplex集群的引擎控制器的内存中,然后向主机确认本次写I/O周期。最后再将数据异步转储到引擎后端的存储阵列中。当出现电源故障时,Vplex引擎自带的备用电源能够保证缓存中的所有未持久化的数据暂存到本地SSD存储上。回写缓存模式无需等待后端存储阵列落盘,即可回响应主机,大幅提升了Vplex双活方案的距离和时延要求。
收起
1 、读 I/O : EMC Vplex 具有读缓存,可以通过写 I/O 的独特机制,实现读 I/O 的加速。 Vplex Local/Metro/Geo 架构的读 I/O 流程如下:
( 1 )读 I/O 的时候先读 Local Cache ,如命中则直接读取,相较于直接读后端存储阵列,内存较机械硬盘的读取性能有着显著提升,因此,从 Cache 内存中直接命中读 I/O ,将大幅提升读 I/O 性能;
( 2 )如果没有命中 Local Cache ,将继续在 Global Cache 中查找,如果命中,则从对应的 Vplex 引擎 Cache 中将其读取到 Local Cache ,因此,两引擎的 VplexMetro/Geo 架构存在 1 倍的跨站点往返时延;
( 3 )如果在 Global Cache 中没有命中,则从本地后端的存储阵列中读取到 Local Cache 中,并同时修改 Local 和 Global Cache 中的信息与索引信息(表明其他引擎可以从该引擎 Cache 读取数据),本次读 I/O 加速无效果。
( 4 )无论有没有命中 Cache ,最后都将反馈主机读 I/O 结果,本次读 I/O 周期结束。从整个读 I/O 流程可以看出,相较于常见的后端存储直接读取,由于读 Cache 的存在,对读 I/O 性能的提升是有积极意义的,命中 Local Cache 将提升数倍读响应时间,没有命中 Local Cache 几乎和直接后端存储读取性能一致,在实际联机型应用读写比例大致为 7 : 3 的情况下,提升读 I/O 的效果是显而易见的。
2、 写 I/O : EMC Vplex 同样也具备“写缓存”, Vplex Metro 没有真实的“写缓存”,实际上是读缓存,用于加速读 I/O ,模式采用的是写直通缓存; Vplex Geo 具有真实的写缓存,模式采用的是回写缓存。其中 Vplex Metro 写 I/O 流程如下图所示: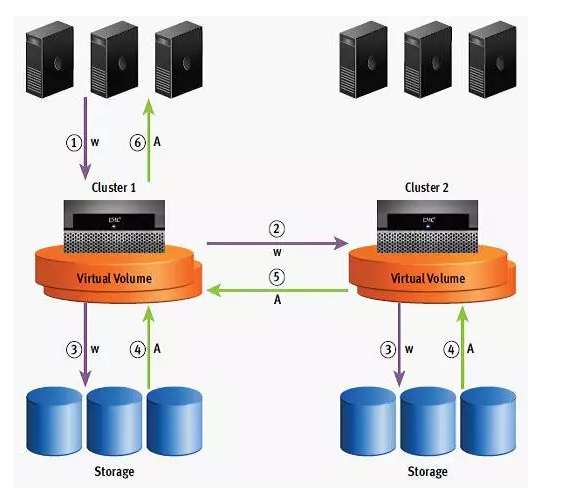
Vplex Metro/Geo 的写 I/O 步骤如下:
(1) 写 I/O 时先判断是否在 Local 、 Global Cache 中有对应的旧数据,如果没有,则直接写入本地 Local Cache ;
(2) 如果有旧数据,需先废除旧数据再写入 Local Cache 。若通过 Global Cache 查询到 旧数据存在于其他站点 Vplex 引擎中,则需要跨数据中心查询和废除旧数据,通讯具有 1 倍的跨站点往返时延;
(3) 写入 Local Cache 后, Vplex Metro 和 Geo 的处理方式有所区别, Vplex Metro 通过写直通缓存模式将写 I/O 刷入两套后端存储阵列,刷入跨站点的后端存储将引入 1 倍的跨站点往返时延;而 Vplex Geo 通过回写缓存模式将写 I/O 写入引擎控制器的缓存,并异步镜像至另一套 Vplex 集群的引擎控制器的写 Cache 中;
(4) Vplex Metro 待两套存储全部写反馈完成,最后将反馈主机写 I/O 周期完成,同时 Global Cache 中的索引做相应修改,并在所有引擎上共享该信息,实现分布式缓存一致性;而 Vplex Geo 在镜像异步写发起后,直接反馈主机写I/O 周期完成,并待两个引擎的 Cache 达到高水位后刷入后端存储。
从整个写 I/O 流程可以看出, Vplex Metro 为了加速读 I/O ,引入了读 Cache ,为了保证读 I/O 的数据一致性( AccessAnyWhere ),又引入了 Global Cache ,造成写 I/O 必须要查询本地和其他引擎的 Local Cache 是否有旧数据,以及时废弃旧数据,更新和同步所有引擎的 Global Cache 。这样的机制原理势必牺牲了一定的写 I/O 性能,相较于后端存储直接写,引入了两倍的 RTT 和更新同步 Local 、 Global Cache 过程的时延。其应用场景更适合于查询比例远高于更新比例的联机型应用。
楼上解释的非常详细,赞!
补充两点:
1、现在vplex GEO模式已经没有了,也就是缓存只有透写模式,没有回写模式了。
2、虽然vplex的透写机制会造成写I/O的延时,但是这个延时和双活复制链路延时比起来,基本可以忽略,加上一般数据交易业务都是读多写少,所以实际对整体性能影响不大
3、如果一个业务是写I/O密集型的,理论上都不建议部署双活方案,甚至不建议部署同步复制方案,对性能的影响比较大,不管是谁家的方案,一般可以考虑异步方案。