2同行回答
需求方面两个重点:
1. 几千万笔这个范围还是十分巨大的,1000万笔与9000万笔之前的架构区别可能就会十分明显了。
2. 这个量级的交易是否包含查询,还是不包含查询纯交易。这个区别也是非常大的,因为对于普遍意义上的应用程序来说,查询的占比一般都会在80%以上。因此如果纯交易是1000万笔的话,按照80%查询计算,查询还要增加额外的4000万笔。每天总量5000万。如果纯交易5000万的话,那么总量还要同比放大。所以这两点非常关键。
对于这种大交易量系统来说,我们在设计上要从三个层面进行考虑。
1. 应用架构层面
一般来说,目前的主流分布式架构都可以满足。如下图所示: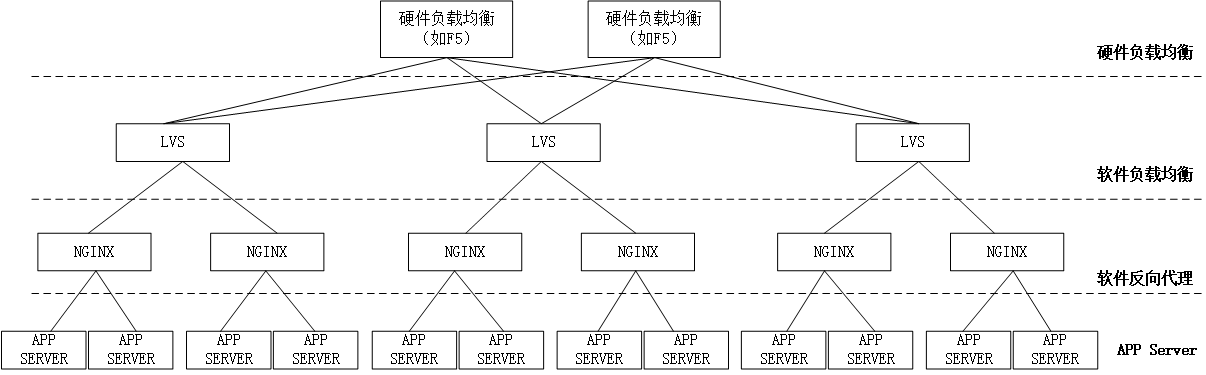
当然,这是通常情况下的架构,也有很多应用不是这个架构的,在这里就不做详细讨论了。
2. 应用架构与数据库架构耦合层面
在这里主要需要考虑,业务系统是否有强一致性需求。如果系统没有强一致性需求,业务上可以忍受最终一致性的话,可以考虑通过MQ解决方案,将应用层对数据库层的调用从同步调用改成异步调用。这一点是可以让吞吐量实现翻天覆地的变化的。
3. 数据库架构层面
首先,千万级的交易量并不是一个非常可怕的量级。以每日5000万笔为例,按照每天峰值交易时间16小时。换算成每秒笔数的话换算公式是这样的50000000/(16x3600) = 868笔/秒。这个量级的负载集中式的Oracle数据库完全可以满足。妥妥地。
数据库层面上最主要需要考虑的一点就是这几千万的交易量是作用在一个多大的数据集上。即并发冲突问题。
如果核心应用如淘宝一般,系统支持海量店家,但是每个店家的数据完全没有重叠,为了降低成本,什么分布式数据库,数据库分库分表等方案都可以往上招呼。但是如果向银行那样的应用,大并发作用在小数据集上,考虑到数据库锁对性能的影响,集中式数据库就有较大优势了。
另外针对海量查询的需求,还可以采用读写分离以及内存数据库等方案进行分流,减少核心数据库穿透。但是在做编程模型的时候需要详细设计和考虑读脏数据的问题。
希望以上回答对您有所帮助。这个问题其他小伙伴们怎么看呢?欢迎留言!!!
收起核心系统设计按照原先的思路确实是要为未来5年甚至更久进行自上而下分析,精心测算,仔细规划。但是我们往往发现规划不如变化,再详细的规划和设计都很难满足业务的快速规划和变化。因此才会有现在的云原生、Devops等概念出来。因此个人觉得体系架构的弹性、敏捷性比日均几千万笔的交易量更重要。只有以不变应万变才是正道。
收起