企业大部分容器化后如何快速定位问题,分析故障?
容器化的应用,也就是以前直接运行在操作系统之上大的单体应用程序,需要根据单体应用架构,拆分为许多微服务,基本上每个微服务都运行在独立的一个容器里面,紧密耦合的微服务1 目前公司上线了部分pass平台(基于k8s) 大部分问题出现的原因基于一些简单的故障,但是很多分析定位都...显示全部
查看其它 4 个回答liubin0521的回答

如果对于常见故障,通常是有FAQ,可以根据现象快速地查找可能原因。不在此回答讨论范围内。
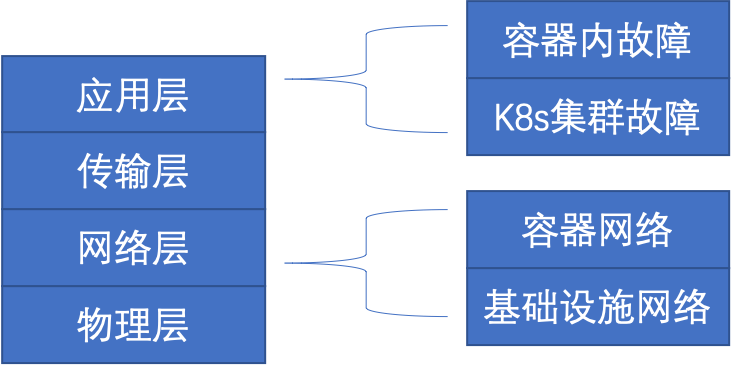
对于新问题故障,建议采用“分层分段”的逻辑来考虑问题。
1)物理层:所在服务器是否有告警,是否硬件层面有故障。
2)网络层:不同应用或不同模块之间是否网络可以通信?
3)传输层: tcp/udp层面,中间是否有防火墙阻断了访问,可能与网络仍然相关,但按协议栈是TCP层;
4)应用层:看部署的应用模块是否可以正常运行,检查日志是常见办法。
对于容器化应用,与普通应用不同。但首先应该保证的是基础设施要能够正常工作,无故障。在基础设施一切正常的前提下,需要保障
1)容器的网络是否正常,pod与pod间互访,pod与集群外互访,这里面会涉及到flannel\calico这样的
cni组件的工作原理。但目前常见cni开源组件未提供troubleshooting的工具,只能手工排查。(打个小广告,博云自研的fabric是带了troubleshooting 工具的)。
2)k8s平台是否正常运行,可以通过查看pod状态做基本判断。如果是集成了prometheus/grafana, 可以较好地监控资源层面
3)容器内应用的运行状态,如其他回答类似,可以通过查看容器内日志,或者集成skywalking工具进行应用层监控。
4)其他的还涉及到负载均衡器到各实例的分发,根据用的负载均衡器类型(可能是ingress)进行问题定位。
分段定位的意思与非容器化应用问题定位没有差异,如 a,b,c,d四个模块组成共同完成一个功能的处理。在定位过程中可以分段进行,例如先看a->b是否正常, 再看b->c是否正常。
浏览3320