云原生应用你应该这么管- 谐云发布基于KubeVela增强的应用版本管理和在线升级
在 OAM 最早推出时,谐云就参与其中,并基于社区中 oam-kubernetes-runtime 项目二次开发,以满足容器云产品中 OAM 应用模型的功能需求。该功能是将应用划分为多个 Kubernetes 资源 —— 组件(Component)、配置清单(ApplicationConfiguration = Component + Trait),其目的是希望将用户侧的开发、运维视角进行分离,并能够借助社区的资源快速上线一些开源组件和运维特征。
后续,KubeVela 项目在组件和配置清单两个资源上抽象出应用资源(Application),并借助 cuelang 实现 KubeVela 的渲染引擎。 谐云快速集成了 KubeVela ,并将原有的多种应用模型(基于 Helm、基于原生 Workload、基于 OAM 的应用模型) 统一成基于 KubeVela 的应用模型 。这样做既增强了谐云 Kubernetes 底座的扩展性和兼容性,同时又基于 Application 这一抽象资源分离的基础架构和平台研发,将许多业务功能下沉到底座基础设施,以便适应社区不断发展的节奏,快速接入多种解决方案。
除此之外,确定的、统一的应用模型能够帮助谐云多产品间的融合,尤其是容器云产品和中间件产品的融合,将中间件产品中提供的多款中间件作为不同的组件类型快速接入到容器云平台,用户在处理中间件特性时使用中间件平台的能力,在处理底层资源运维时,使用容器云平台的能力。
基于以上背景, 谐云对社区版本管理、纳管功能进行了增强 ,并希望能够分享至社区进行讨论,引发更多的思考后,对社区功能做出贡献。
01
应用版本管理
版本控制与回滚
在应用运维时,应用的版本控制是用户非常关心的问题,KubeVela 社区中提供了 ApplicationRevision 资源进行版本管理,该资源在用户每次修改 Application 时将产生新的版本,记录用户的修改,实现用户对每次修改的审计和回滚。
而谐云的应用模型当中,由于组件可能会包含一些“不需要计入版本”的纯运维 Trait,例如版本升级的 Trait,手动指定实例数的 Trait 等,我们在升级、回滚时,需要将这些 Trait 忽略。 在社区早期版本中,TraitDefinition 含有 skipRevisionAffect 字段,该字段在早期社区版本中实现如下:
- ApplicationRevision 中仍会记录 skipRevisionAffect 的 Trait
- 若用户触发的修改范围仅包含 skipRevisionAffect 的 Trait,将此次更新直接修改至当前记录的最新版本中
- 若用户触发的修改范围不仅包含 skipRevisionAffect 的 Trait,将此次更新作为新版本记录
这样实现的 skipRevisionAffect 无法真正使 Trait 不计入版本,例如,我们将 manualscaler 作为不计入版本运维特征,与 Deployment 的伸缩类似,当我们仅修改 manualscaler ,新的实例数量会被计入到最新版本,但当我们的版本真正发生改变产生新的版本后,再次手动修改了实例数量,最后因为某些原因回滚到上一个版本时,此时实例数量将发生回滚(如下图)。而通常情况下,决定应用实例数量的原因不在其处于什么版本,而在当前的资源使用率、流量等环境因素。且在 Deployment 的使用中,实例数量也不受版本的影响。
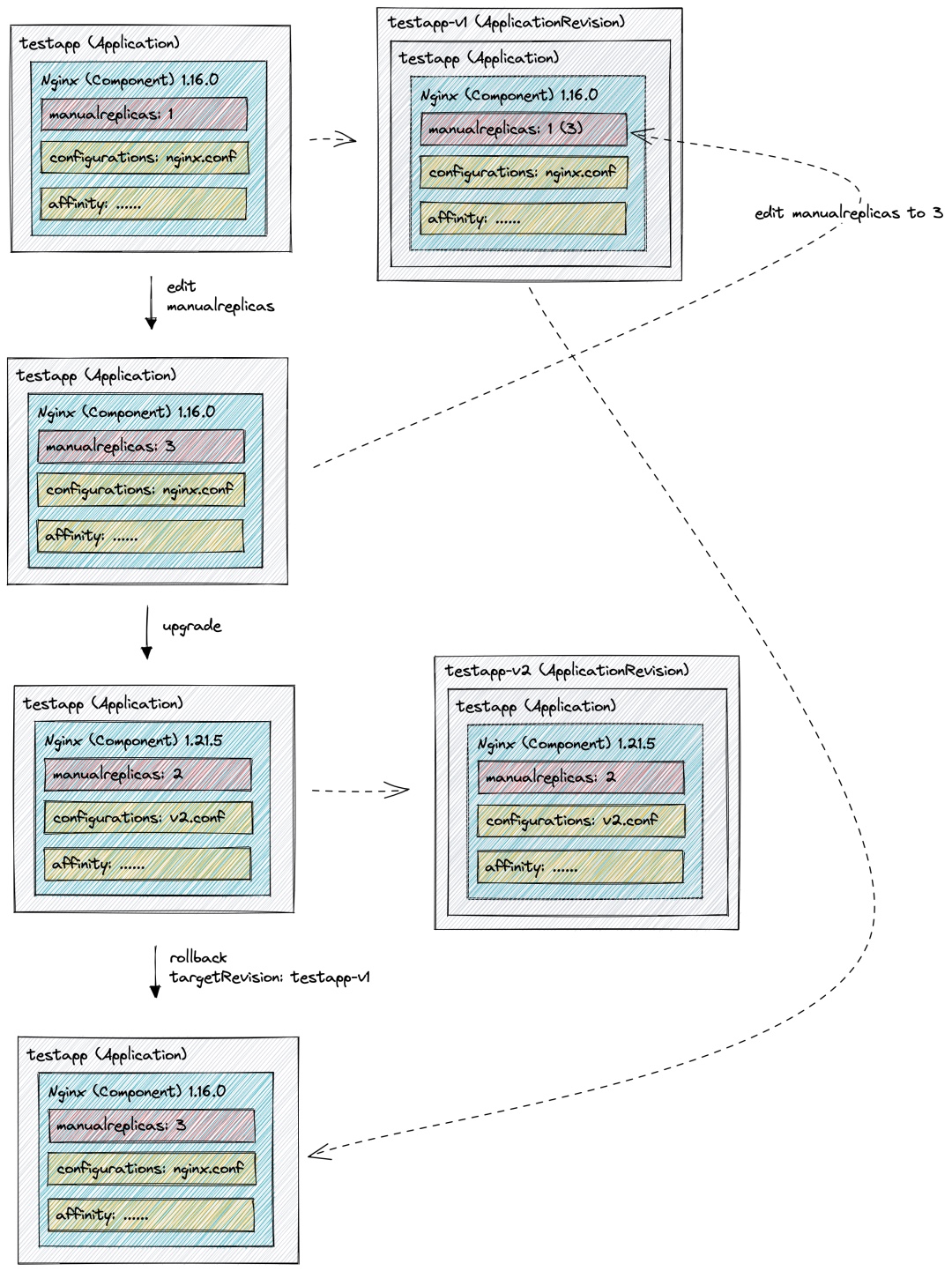
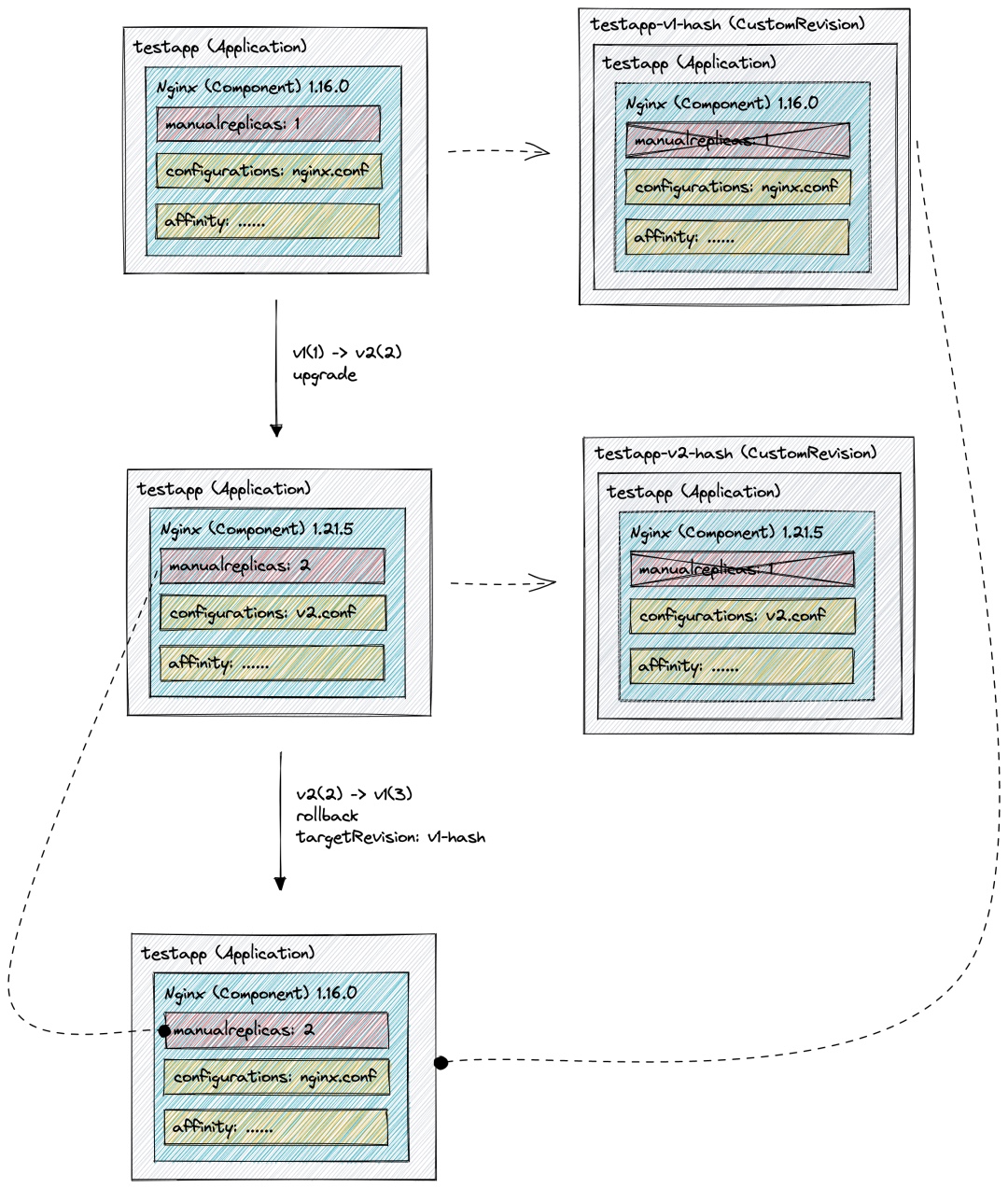
基于以上需求,谐云提出了一套另一种思路的 版本管 理设计1 , 在记录版本时,将彻底 忽略 skipRevisionAffect 的 Trait,在进行版本回滚时, 将当前 Application 中包含的 skipRevisionAffect 的 Trait 合并到目标版本中,这样便是的这些纯运维的 Trait 不会随着应用版本的改变而改变。 下图是该 设计的版本管理过程 :
- testapp 应用中包含 nginx 组件,且镜像版本为 1.16.0,其中包含三个运维特征,manualreplicas 控制其实例数量,是 skipRevisionAffect 的 Trait,该应用发布后,版本管理控制器将记录该版本至自定义的 Revision 中,且将 manualreplicas 从组件的运维特征中删除;
- 当修改 testapp 的镜像版本、实例数量及其他运维特征,发生升级时,将生成新版本的 Revision,且 manualreplicas 仍被删除;
- 此时若发生回滚,新的 Application 将使用 v1 版本 Revision 记录的信息与回滚前版本(v2)进行合并,得到实例数量为 2 的 1.6.0 的 nginx 组件。
版本升级
版本管理除了版本控制和回滚之外,还需要关注应用的升级过程,社区目前较为流行的方式是使用 kruise-rollout 的 Rollout 资源对工作负载进行金丝雀升级。我们在使用 kruise-rollout 时发现,在金丝雀升级过程中,应用新旧版本最多可能同时存在两倍实例数量的实例,在某些资源不足的环境中,可能出现由于资源不足导致实例无法启动,从而阻塞升级过程。
基于以上场景, 我们在 kruise-rollout 上进行了二次开发,添加了滚动升级的金丝雀策略 ,能够使得应用在升级过程中通过新版本滚动替换旧版本实例,控制实例数量总数最大不超过实例数量+滚动步长。 但这么做仍然存在一些问题,例如 kruise-rollout 能够完全兼容升级过程中的实例扩缩场景(无论是 hpa 触发还是手动扩缩),但带有滚动策略的升级过程一开始就需要确定总的升级实例数量,且在升级过程中,hpa 和手动扩缩容都将失效。 我们认为带有滚动策略的金丝雀发布仍在某些资源不足的场景下是有用的,所有并没有更改社区 kruise-rollout 的策略,仅是在社区的版本上做了一些补充。 以下是 社区版本的金丝雀升级过程与带有滚动策略的金丝雀升级的过程 :
- 社区金丝雀升级过程:

- 带有滚动策略的金丝雀升级过程:

小结
我们 在基于 KubeVela 的应用模型上对应用版本管理采用了另外一种思路 ,主要为了满足上文中描述的场景,应用版本管理的整体架构如下:
- 通过 vela-core 管理应用模型
- 通过自研的 rollback-controller 进行应用版本控制和应用回滚
- 通过二次开发的 kruise-rollout 进行应用升级
02
应用纳管
在接入 KubeVela 的同时,面对存量集群的应用模型纳管也是一个值得思考的话题。对于谐云而言,将 KubeVela 定义为新版本容器云的唯一应用模型,在平台升级过程中,纳管问题也是无法避免的。 由于我们定义的 ComponentDefinition 和存量集群中的工作负载在大部分情况下都存在差异,直接将原有的工作负载转换为 Component 将导致存量业务的重启。而平台升级后,KubeVela 作为我们的唯一模型,我们需要在业务上能够看到原有的应用,但不希望它直接重启,而是在期望的时间窗口有计划地按需重启。 为了解决上述矛盾,我们提出了以下纳管思路 : 首先要做的是在平台升级过程中,尽可能地不去影响原有的应用,即 在首次纳管时我们通过社区中提供的 ref-objects 组件对现有的工作负载进行纳管 。由于容器云产品中面向的是 Application 资源,此时被纳管的组件在应用模型中无法进行日常的运维操作(没有可用的运维特征),但仍可以通过工作负载资源直接运维(如直接操作 Deployment)。
我们 将工作负载及其关联资源转换为 Component 的关键在于理解 Definition 。在 KubeVela 中,工作负载及其关联资源是通过 cuelang 进行渲染生成的,这是一个开放的模型,我们无法假定 Definition 的内容,但我们期望编写 Definition 的人员可以同时编写 Decompile 资源指导程序如何将工作负载及其关联资源转换为 Component 或 Trait。 这就类似于我们将 Definition 作为一次事务,而回滚时要执行的动作由 Decompile 决定,两者都是开放的,具体行为取决于开发者。 在首次纳管之后到下一次纳管目标组件进行版本升级之前,我们将持续保持上述状态,等到该组件进行升级时,我们将通过“反编译”将纳管目标工作负载及其关联资源转换为 Component + Trait,并将需要升级的部分合并到反编译的结果中, 通过容器云平台更新到 Application 中,彻底完成应用模型的转换 。 该过程如下图所示:

示例
例如,我们包含一个节点亲和类型的运维特征:
# Code generated by KubeVela templates. DO NOT EDIT. Please edit the original cue file.apiVersion: core.oam.dev/v1beta1kind: TraitDefinitionmetadata: annotations: definition.oam.dev/description: Add nodeAffinity for your Workload name: hc.node-affinity namespace: vela-systemspec: appliesToWorkloads: - hc.deployment podDisruptive: true schematic: cue: template: | parameter: { isRequired: bool labels: [string]: string }
patch: spec: template: spec: affinity: nodeAffinity: { if parameter.isRequired == true { // +patchKey=matchExpressions requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: [ for k, v in parameter.labels { { matchExpressions: [ { key: k operator: "In" values: [v] }, ] } }, ] } if parameter.isRequired == false { // +patchKey=preference preferredDuringSchedulingIgnoredDuringExecution: [ for k, v in parameter.labels { { weight: 50 preference: matchExpressions: [{ key: k operator: "In" values: [v] }] } }, ] } }
同时我们还包含一个从 Deployment 节点亲和到 Trait 转换的 Decompile 资源(它的 cuelang 模型与 Trait 类似,都是通过参数和输出部分组成,只是在正向过程中,output 输出的是 CR,而在本过程中,output 输出的是 component 或是 trait):
apiVersion: application.decompile.harmonycloud.cn/v1alpha1kind: DecompileConfigmetadata: annotations: "application.decompile.harmonycloud.cn/description": "decompiling deployment node affinity to application" labels: "decompiling/apply": "true" "decompiling/type": "node-affinity" name: node-affinity-decompile namespace: vela-systemspec: targetResource: - deployment schematic: cue: template: | package decompile
import ( "k8s.io/api/apps/v1" core "k8s.io/api/core/v1" )
parameter: { deployment: v1.#Deployment }
#getLabels: { x="in": core.#NodeSelectorTerm out: [string]: string
if x.matchExpressions != _|_ { for requirement in x.matchExpressions { key: requirement.key if requirement.operator == "In" { if requirement.values == _|_ { out: "\\(key)": "" } if requirement.values != _|_ { for i, v in requirement.values { if i == 0 { out: "\\(key)": v } } } } } } if x.matchFields != _|_ { for requirement in x.matchFields { if requirement.operator == "In" { if requirement.values == _|_ { out: "\\(requirement.key)": "" } if requirement.values != _|_ { for i, v in requirement.values { if i == 0 { out: "\\(requirement.key)": v } } } } } } }
#outputParameter: { isRequired: bool labels: [string]: string }
#decompiling: { x="in": v1.#Deployment out?: #outputParameter
if x.spec != _|_ && x.spec.template.spec != _|_ && x.spec.template.spec.affinity != _|_ && x.spec.template.spec.affinity.nodeAffinity != _|_ { nodeAffinity: x.spec.template.spec.affinity.nodeAffinity if nodeAffinity.requiredDuringSchedulingIgnoredDuringExecution != _|_ { out: isRequired: true for term in nodeAffinity.requiredDuringSchedulingIgnoredDuringExecution.nodeSelectorTerms { result: #getLabels & {in: term} if result.out != _|_ { for k, v in result.out { out: labels: { "\\(k)": "\\(v)" } } } } } if nodeAffinity.preferredDuringSchedulingIgnoredDuringExecution != _|_ { out: isRequired: false for schedulingTerm in nodeAffinity.preferredDuringSchedulingIgnoredDuringExecution { if schedulingTerm.preference != _|_ { result: #getLabels & {in: schedulingTerm.preference} if result.out != _|_ { for k, v in result.out { out: labels: { "\\(k)": "\\(v)" } } } } } } } }
result: #decompiling & {in: parameter.deployment}
output: traits: [ if result.out != _|_ { { type: "hc.node-affinity" properties: #outputParameter & result.out } } ]
(由于长度原因,省略了 hc.deployment 的正反渲染) 我们在集群中创建这样一个 Deployment:
apiVersion: apps/v1kind: Deploymentmetadata: name: demo-app namespace: demospec: replicas: 1 selector: matchLabels: app: demo-app template: metadata: labels: app: demo-app spec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: area operator: In values: - east containers: - image: 10.120.1.233:8443/library/nginx:1.21 name: nginx ports: - containerPort: 80 protocol: TCP
通过调用 kubevela-decompile-controller 提供的 API,将 demo-app 进行转换,将得到如下结果,平台可以将 data 中的 component 替换掉 Application 中的 ref-objects 组件。
{ "code": 0, "message": "success", "data": { "components": [ { "name": "demo-app", "type": "hc.deployment", "properties": { "initContainers": [], "containers": [ { "name": "nginx", "image": "10.120.1.233:8443/library/nginx:1.21", "imagePullPolicy": "IfNotPresent", "ports": [ { "port": 80, "protocol": "TCP" } ] } ] }, "traits": [ { "type": "hc.dns", "properties": { "dnsPolicy": "ClusterFirst" } }, { "type": "hc.node-affinity", "properties": { "isRequired": true, "labels": { "area": "east" } } }, { "type": "hc.manualscaler", "properties": { "replicas": 1 } } ] } ] }}
小结
谐云通过类比事务的方式,将渲染过程分为正向和逆向,同时将首次纳管和真正的纳管动作进行了分离,完成了平台升级的同时,给应用的纳管行为留下了一定的可操作空间。 这是一种应用纳管的思路,近期社区当中对于应用纳管的讨论也十分火热,并且在 1.7 的版本更新中也推出了 应用纳管的能力 2 ,同时同样支持“反向渲染”的功能,能够支持我们将现有的纳管模式迁移到社区的功能中。
【1】https://github.com/kubevela/kubevela/issues/2168
【2】https://kubevela.net/docs/next/end-user/policies/resource-adoption#use-in-application
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞0作者其他文章
评论 0 · 赞 1
评论 0 · 赞 0
评论 0 · 赞 0
评论 0 · 赞 0
评论 0 · 赞 0
添加新评论0 条评论