为什么网络是分布式技术的基石
有感而发:被忽视的基石
何为基石?基石首先是基础,决定有无;基石又代表“硬件”,是可触碰的实体;最后,基石虽然关键,但往往被忽略。最近看了 对标Spanner?国产分布式数据库其实并不好做…… 的文章,提到“确保网络延时低于7ms是谷歌Spanner的成功密码”,而“能够具备这种强大的广域网优化能力的企业是屈指可数的,能够花得起这个钱的企业更是凤毛麟角”。所以Spanner这种分布式数据库只能膜拜,却难以学习。回顾多年实践分布式的经验教训,以替代大/小型机而成名的分布式架构能够流行正是利益于2000年后TCP/IP网络的大发展,而同时网络又是分布式能力的最大瓶颈,甚至极大影响了分布式系统的架构设计。本文尝试将网络的重要作用进行分析,以开阔分布式系统规划的思路,提供可能事半功倍的解题之道。
败也萧何
CPU:我要能干,才懒得等你们
某种程度上可以认为分布式计算是用网络代替多核/多CPU间的总线实现并行/串行计算,用分布式调度软硬件替代了操作系统的多核/多CPU分时调度能力。但网络的速度远比CPU总线慢,这就使网络成为决定分布式系统性能的那块“短板”。多年前有一篇文章《 我是一个CPU:这个世界慢!死!了! 》把2.6G CPU处理一个指令的时间(0.38ns)换算成人类能感知的时间单位1秒,那么:
- 一级缓存读取时间为 0.5ns,换算成人类时间大约是 1.3s;
- 二级缓存,读取时间大约在 7ns,换算成人类时间大约是 18.2s;
- 内存每次寻址需要 100ns,换算成人类时间是 260s,够CPU“读”一篇千字短文;
- 1Gbps 的网络上传输 2K 的数据需要 20us,换算成人类时间是 14.4小时;
- 世界上不同城市网络上走一个来回,平均需要 150ms,换算成人类时间是 12.5年……
假设一个CPU用一个指令时间“打了个哈欠”并用千兆网直播给旁边的CPU看,对方要等多半天才能看到,而如果是在另一个城市的CPU,可能要等很多年才能看到!因此除非达到能力上限,还是多CPU和多核心比搞分布式更快成本更低,计算机技术的发展方向也证明了这一点。
线性度:1+1<2
分布式系统的很多著名难题就是网络造成的。在 分布式系统中总的计算能力永远小于单机算力的总和,即线性度小于1就与网络密切相关 ,因为分布式系统需要进行状态和数据的同步,尤其是为保证一致性进行的数据同步对性能的损耗巨大。比如HADOOP,如果有N个副本,那么就有N-1个副本要用网络传输到其它服务器保存;数据库使用日志做事务一致性同步减少了网络上同步的数据量,但为保证数据库事务一致性,反而对网络的时延和稳定性要求更高。
另外当分布式系统要想将工作分散到所有服务器时需要不同的服务器操作的数据保持一致。或者像分布式数据库或分库分表中间件在处理事务时所有节点通过网络互相协商来实现分布式事务;或者像HADOOP把计算和存储逻辑上分开,但又由于无法保证所有数据在服务器内能找到,仍需要大量通过网络进行数据读写,总之是对网络的性能和稳定性都有很高的要求。
就像一个团队因为需要进行分工和协调,人越多、需要协调的事情越多效率就越低。当然除了网络,在数据处理中存储性能也是关键因素,限于篇幅有机会再单独讨论。由于网络对分布式的性能影响大到性能和一致性不可兼得,导致很多分布式系统会放弃一致性来保证性能,这就是CAP定理的表现。
CAP跷跷板
CAP定理是分布式架构的重要原理,指在一个分布式系统中, Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),不能同时实现。由于分区容错保证分布式系统能在分区间(比如节点间,生产和容灾站点间)通信中断的情况下工作,因此一般分区容错性是必须实现的,所以CAP就变成了在AP和CP间二选一。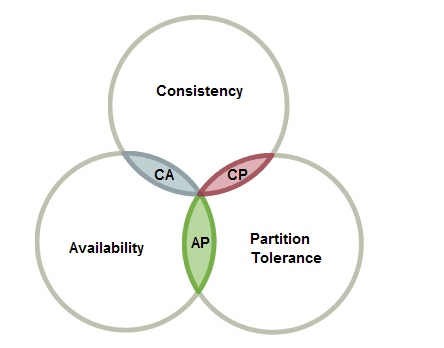
一致性和可用性成了跷跷板的两头,迫使一些业务选择放弃一致性,采用最终一致性之类的方式保性能(可用性)。另一些业务由于对一致性要求高(比如涉及钱的业务,不一致就麻烦了),就只能牺牲性能并通过堆积高性能硬件来弥补损耗。 与线性度问题一样,二选一的局面主要是网络和存储能力造成的 ,经常会看到网络打个喷嚏(不稳定),系统就感冒发烧(数据不一致,集群重启暂停服务)。
网络对分布式技术发展的影响
286时代,电脑内存只有640K,打个吃内存的游戏,为了腾出几K的内存空间能写篇攻略,等386之后大内存和保护模式的普及这些优化“神技”就消失了。 IT系统中,硬件决定系统能力的决定下限,软件能力决定系统能力的上限,分布式系统也是如此。 当网络能力不足时,必须通过架构和各种优化弥补,而有时这些优化不如换万兆网效果明显,以至网络常常会成为分布式技术发展的技术变革拐点。
规避网络影响及其局限性
绕着走
这是最常用的方式,比如前端应用的负载均衡架构,后来容器化中的“应用无状态化”是这一架构的最好总结。这一架构的数据处理都剥离到数据库、缓存、消息队列或共享文件中,因而只需要对应用做分发调度就可实现分布式。

但问题也很明显:甩锅最终得有人接, 一个普遍的现象是,前端应用早就实现分布式改造了,后端数据层却要么还要依赖“集中式”架构,导致至今大部分分布式系统都是应用系统 。
分头计算,汇总结果
很多数据处理需要大量源数据,但结果数据量却小得多,如果能在本地做数据处理,只在网络上传统结果数据再进行汇总,网络的影响就小多了。
上图是MapReduce原理,可以简单理解为负载均衡时“工人”和数据在一个服务器上,同时调度器增加了汇总计算结果的功能。不过如果“工人”之间要互相访问数据就很难使用这种架构了,比如一份数据要多个节点共享就要跨节点访问,要是做数据变更就又回到一致性的老问题,所以目前只是数据仓库,大数据,AI等应用能使用这种架构。
还有一个容易忽略的问题就是为了在计算节点出现故障时不中断业务,这一架构仍然要在节点间大量同步数据,对网络的要求并不低。另外如果计算节点只能访问本地数据,那么磁盘故障将同时导致算力损失或任务重做,这是MPP数据库等系统的通病。
两段处理,但并不完美
为了解决本地访问的可靠性问题和充分利用计算资源,Google的大数据体系采用了“计算可移动”架构,之后的HADOOP将其继承和修改。这一架构中应用将数据写入HDFS文件系统,由HDFS完成多副本数据持久化,把应用和数据处理分成了两段。

虽然HADOOP试图保证优先本地读写,但随着业务变得复杂和HADOOP生态的扩大,本地读写难以保证,叠加三副本对网络的压力巨大,最终还得靠升级网络能力来解决。
用日志还原,但对网络要求更高
数据的变更操作记录通常比数据变更本身小很多。比如一个替换操作,只需要一条“把XX改成YY”的记录,但数据可能有万千上万的变化。如果在数据同步时只传输数据的变更日志,再由日志在其它节点上还原出数据就可以减少传输的数据量。
不过这种方式实际上却对网络和存储IO的要求一点不低,因为分布式系统是多节点同时工作的。一个节点把XX改成YY的操作时如果另一个节点在统计YY的数量,要得到准确结果就要等前面的修改完成,如果前面的修改失败还要等它回滚。如果要通过日志同步数据副本,还要等“把XX改成YY”的副本同步完才能认为“把XX改成YY”的操作完成了,这又需要等。而如果统计YY的数量的操作是访问本地存储的数据,那么还需要等日志把“把XX改成YY”这一操作在本地执行完才能进行!MySQL的MGR架构就是典型,通过Paxos协议实现日志同步,仍然存在“大事务”问题,即执行“大事务”或网络不稳定时,集群出现故障停服重启。理论上MGR能实现多写,要么接受数据不一致,要么性能极差,所以MGR“很贴心”地给出了五种多写参数,让用户在一致性和性能之间权衡,可以说是把CAP的的CP/AP二选一体现到了极致。
用网络驱动技术革新
和网络有关的问题,如果网络足够“快”就能解决了,甚至像CAP都能“得兼”。
网络速率和协议栈升级实现CAP“全都要”
CAP不可能同时实现,但 如果网络和存储快到在确保一致性的同时性能影响小于应用的感知,CAP就近似实现了 。Google Spanner实现“稳定地慢”因为它可以把TrueTime的瞬时误差边界ε控制在7ms以内来保证事务执行的效率。相反最近和两家Spanner架构(TiDB和OceanBase)数据库的用户讨论,一个觉得不错,但必须在网络条件非常好的情况下才能达到,另一个因为跨机房(15公里,运营商自建网络,时延很低)性能下降比较多而没有用多数据中心并发访问。一正一反充分说明了网络对分布式数据库能力起到的决定性作用。
网络和存储快到一定程度,分布式系统在感知上就变成了“集中式”。100G ROCE+保电内存(用备用电池保证掉电后可以把内存数据保存到非易失性介质)可以实现数据在缓存中持久化,使存储的性能在使用分布式架构同时达到“集中式存储”的性能。这一组合的成本较高,一般用于高端存储,不过采用RDMA或ROCE网络的分布式存储已经很常见了。
存储的例子可以看到RDMA、ROCE对性能的巨大提升。RDMA本来主要用于分布式计算,在以太网承载RDMA技术逐渐成熟后,其应用有爆发的趋势。如阿里的测试将RDMA应用在Redis,AI和Spark上,性能提升分别为130%/30%/30%,华为采用NOF替代FC性能可提升约30%。
可以甩锅给“专业系统”了
早在2009年AWS就在其 Amazon Elastic MapReduce(EMR)数据湖架构中使用S3专业存储替代了HDFS,但之后应者寥寥。然而到了2015年前后EMC、华为、Facebook、阿里等厂商纷纷推出类似方案,似乎受到一种“神秘力量”的推动。如今像Snowflake干脆就直接用存算分离架构来设计“云原生”数据仓库了。
后来FaceBook在一篇论文中的分析揭示了HADOOP诞生十年之后的“神秘力量”就是以太网性能追上了存储形成的“技术拐点”:
| 对比项 | 2005年水平 | 2015年水平 |
|---|---|---|
| 主流单磁盘容量(盘多更快) | 0.5T | 4-8TB |
| 最佳检索速率(retrieval rates) | 100MB/s | 100MB/s |
| 数据中心主流网络端口速率 | 1 Gbps | 40-100 Gbps已比较常见 |
| 网络汇聚收敛比 | 1:40 | CLOS无阻塞组网实现全速互连 |
对此有兴趣可以参考我的 对FaceBook下一代HADOOP数据仓库存储方案的初步解读 一文。此外从 在 Facebook,我是这样做运维的 可以看到CLOS组网组成的分解式网络如何支持大规模扩展的同时保证性能的。
分离架构的最大意义不在于更容易甩锅构建无状态应用,而首先在于“分解”。因为只有分解之后无状态的计算层才能随意增减节点、故障后快速切换而不需要复制/迁移数据,从而实现可靠性提升以及降低成本。另一方面分离架构可以把数据处理交给专业存储来做。 在实现分离架构时,所有厂商都没有选择简单把HDFS单独部署,而是以专业存储代替它,毕竟HADOOP“顺便”做的HDFS不可能比专业存储能力强,以FaceBook温存储为例,看一下能力提升:
| 对比项 | HDFS能力 | 温存储能力 |
|---|---|---|
| 文件数 | 1亿以上性能下降 | 万亿文件处理能力 |
| 可用性 | 多副本,磁盘多故障数量多 | 纠删码,磁盘数下降,冗余度提升,可用性数量级提升 |
| 性能 | 小IO性能差 | 专门优化小IO性能 |
| 成本 | 多副本,利用率低 | 纠删码,利用率高 |
| 其它 | -- | 多租户,资源隔离等 |
最终在网络催动下,各种云原生架构数据平台应运而生,除了云原生数据湖和数据仓库,还有阿里的云原生数据库PolarDB,云原生消息中间件Pulsar等等, 继FC网络推动关系数据库IOE架构出现后,网络两次成为架构变革的决定性因素。
后记
网络能力是分布式系统的基石,网络好则赢在起跑线上,反之则被迫要做各种“穷”折腾。用优化网络来解决分布式系统中的问题往往收益可观,但同时也困难重重。本来想写一下网络创新的重点工作与技术方向,但看篇幅,决定下(再)回(水)分(一)解(篇)。先剧透一下《分布式系统中网络创新的“道”与“术”的主要内容:
创新之道:
- 让马跑得更快不如换个汽油机:换解题思路是第一步
- 从马车型汽车到当代汽车:生态系统的创新迭代
- 伟大的探亲路:如何在实践中发现问题完善产品
创新之术:哪些技术是你最需要的?
- 提升速率看上去很好,但可能不是关键,提升稳定性、无阻塞组网、阻塞处理一样重要
- 新的协议可能有奇效,比如RDMA,ROCE,当然也更难伺候
参考材料:
最形象描述计算机各组件速度差异的文章:我是一个CPU:这个世界慢!死!了!
MySQL MGR"一致性读写"特性解读 - 腾讯云开发者社区-腾讯云 (tencent.com)
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞5本文隶属于专栏

作者其他文章
评论 2 · 赞 6
评论 1 · 赞 5
评论 2 · 赞 7
评论 0 · 赞 3
评论 0 · 赞 1
添加新评论1 条评论
2022-08-16 14:21