应用执行慢的问题排查路径
在OLTP系统的运维过程当中,可能最“讨厌”的一种场景,就是碰到应用执行慢,因为表象是应用执行慢,或者定位到某条SQL语句执行慢,但根源未必就是数据库,或者不完全就是数据库,例如一次简单的数据检索,可能就会涉及到多个应用、不同的操作系统、网络环境、数据库等资源,可以说环环相扣,毕竟不是“一体机”,任何一个环节的问题,都可能导致相同的现象。
在这个《一次Oracle bug的故障排查过程思考》中,表象是应用执行慢了,再推一下,某条SQL执行慢了,导致应用hang了,但根源是一个Oracle的bug,同时应用起到了推波助澜的作用,足以看出一个“慢”的问题排查,有时候挖掘起来,确实不容易的。
《 应用执行慢的定位案例 》,就介绍了一种定位问题的思路,可以向程序增加一些断点,无论是要打印到控制台,还是应用日志,通过断点,逐步定位,其中需要注意的一点,就是断点的粒度,如果断点粒度很粗,很可能就无法精确定位。 要是复杂一些,打出dump文件,从程序的调用栈,一步步进行判断,是另一种方式,当然这对人员的技术要求更高。
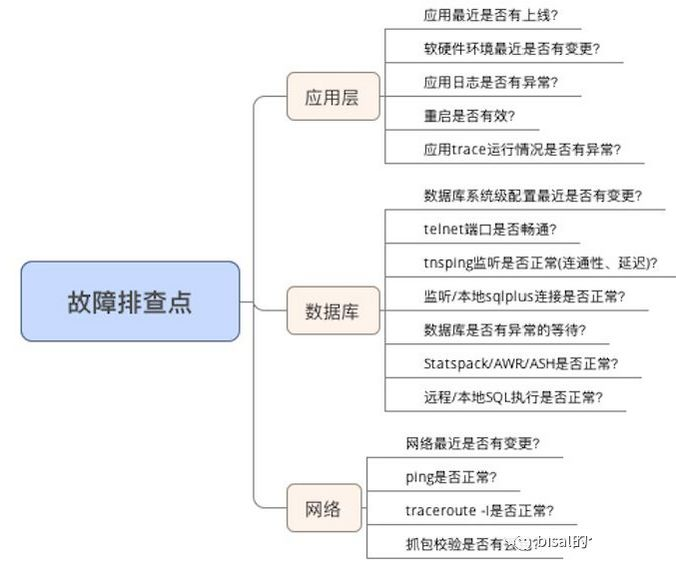
《 一次惊心动魄的问题排查 》, 这次碰到的问题, 同样值得借鉴,当时整了张图,蜻蜓点水般地梳理下应用层、数据库和网络层的排查路径,
除了技术因素,还有一些非技术因素,可能左右问题的排查,例如:
- 是否能做到团队间亲密协作,有甲方,有乙方,有DBA,有中间件,有网络,有业务,尤其是临时组成的虚拟团队,信息资源的共享,操作上的互补,都很重要。2. 是否能清楚地阐述问题,无论是技术人员,还是业务人员,在紧急的情况下,能否言简意赅地表达,提供其他人判断问题的素材,非常重要。
《数据库连接池配置参考》则以druid作为示例,介绍了连接池的一些配置,换句话说,连接池配置异常,是导致应用慢的原因之一。
北在南方这篇《数据库连接池配置(案例及排查指南)》,提供了个非常经典的“数据库慢查的排查过程”,在排查思路上,值得学习,

因此,排查一个数据库交互的“慢”,或者应用执行慢的问题,除了需要数据库的知识,应用、网络、操作系统等方面的知识,可能都会用到,这就对人员的知识体系,提出了更高要求,正所谓“一专多能”,才是王道。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞1作者其他文章
评论 1 · 赞 5
评论 0 · 赞 2
评论 0 · 赞 1
评论 0 · 赞 2
评论 0 · 赞 1
添加新评论0 条评论