AIX系统性能调优的一些建议
AIX系统性能调优的一些建议
对于一个系统而言资源总是有一定限度的,而任务总是要消耗系统资源的。关键是要找出哪些资源不能满足应用程序运行的需求。这里存在一个性能瓶颈的问题。不同的应用程序可能会有不同的资源要求,可能会产生不同的瓶颈。系统资源中的CPU、内存、磁盘或是网络都有可能成为瓶颈。系统性能调优需要找出这些资源成为瓶颈的原因,是资源的不足,是系统设置不合理,还是应用程序的问题。
查找性能瓶颈的顺序非常重要,正确的顺序是:CPU > 内存 > I/O > 网络,如下图所示:
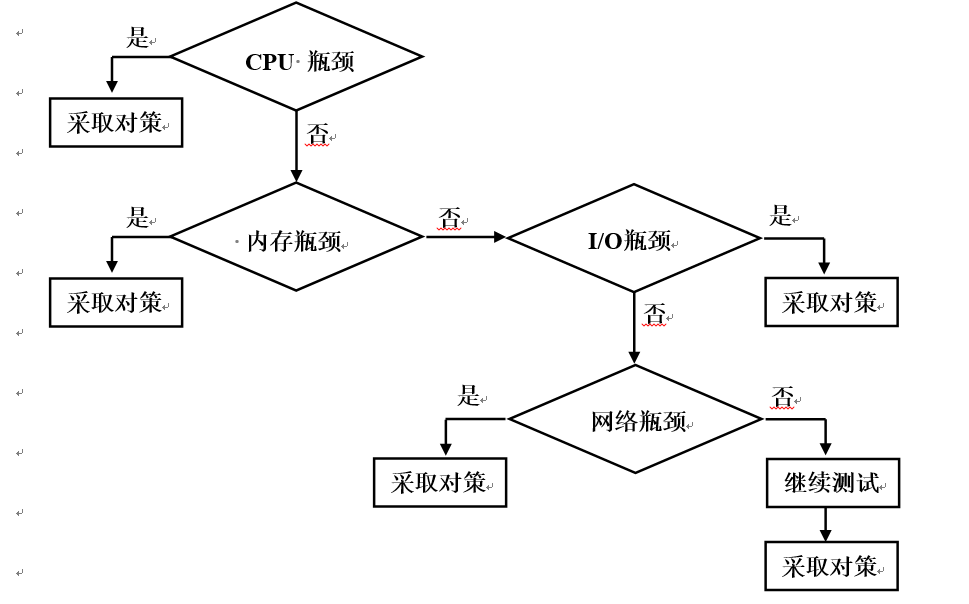
要使用系统性能分析工具需要安装以下文件组:
l bos.acct
l perfagent.tool
查找性能瓶颈的工具:
vmstat 命令
性能分析应该从vmstat命令开始。通过该命令我们可以找到大致的方向。
# vmstat 2 10(每隔两秒采样一次,一共采样10次)
kthr memory page faults cpu
----- ----------- ------------------------ ------------ -----------
r b avm fre re pi po fr sr cy in sy cs us sy id wa
0 0 3269 10342 0 0 0 0 0 0 130 36 2 00 0 99 0
0 0 3275 10336 0 0 0 0 0 0 132 40 2 60 1 99 0
0 0 3 282 10326 0 0 0 0 0 0 128 6996 27 3 8 90 0
先看是否CPU瓶颈:
从"vmstat"的输出我们可以看"cpu"的使用情况 **
当 us+sy 的使用量持续超过80%(多处理器机型), 可以认为是CPU瓶颈。
说明:
us 程序在用户模式(user)下运行对CPU的占用。
sy 程序在核心模式(kernel)下运行对CPU的占用,一般值us应大于sy值。
r (runable threads)可运行的线程, 一般应不大于 5*(_Total_Proc_ - _Bind_Proc_)。
b (threads in wait queue)在等待系统资源或I/O的线程,当前不在CPU中运行。
cs (context switch) 进程切换,如果进程切换数值较高则进程的运行效率不高。通常进程切换数在( 120~150 ) * Total_Proc 时,CPU利用率较高。
如需要进一步了解 CPU 的使用情况 , 可使用 "sar" 命令 , 如 :
# sar -P ALL 1 10 ( 每隔 1 秒采样一次 , 一共采样 10 次 )
在多处理器机器上查看CPU的使用是否平衡
如果CPU使用不平衡,则应用程序多半是单线程程序,不能充分利用多CPU系统的优势。这样就需要从应用程序的调优着手。
如需要了解哪个进程使用了最多的CPU资源,可使用"tprof"命令,如:
#tprof -x sleep 60(采样 60 秒)
在输出文件__prof.all中可以找出最占用CPU资源的进程。对最占CPU资源的进程进行分析,优化应用程序使CPU的利用率提高。
如果问题不是CPU瓶颈,可以再看是否内存问题:
查看"vmstat"的输出
fre 系统当前空闲的物理内存的页面数(一个内存页面为4K字节)
pi 每秒钟从内存交换区载入的页面数
po 每秒钟写入内存交换区的页面数
fr 每秒钟内存管理程序释放出来的空闲页面
sr 每秒钟内存管理程序扫描过的内存页面数
cy 内存管理程序扫描过整个内存页面表的次数
内存瓶颈通常表现为: fre值持续在minfree值(默认为120)上下波动,同时又有大量的po(持续在2位数以上)和pi操作。此时内存管理程序试图扫描更多的内存页面以释放空间,所以sr值会急剧上升。在内存不足的情况下sr与fr的比值会较大,cy也可能大于0 。此时用lsps命令检查内存交换区的使用,会发现使用率较高。
由于有大量的内存页面写入内存交换区,这会导致wa(I/O等待)值上升,但此时并非I/O瓶颈引起。
当内存交换区使用率超过70%时需要增加交换区的大小。但增加内存交换区的大小并不会提高系统的性能。相反,内存交换区使用越多,系统性能下降越多。当内存不足时,正确的方法是增加物理内存的数量或优化应用程序。
以下命令可以进一步对内存的使用进行分析:
# svmon -G -i 1
# svmon -Pvt 10 找出最占内存的10个程序以进一步分析应用程序对内存的使用。(此参数只适用于AIX4.3.3)
如果也不是内存瓶颈则应看看系统的I/O情况:
还是从"vmstat"的输出看,如果wa值持续大于 > 25, 则可能是I/O瓶颈,此时b值也会较高,显示有较多的进程等待系统I/O。
以下命令可以进一步对系统I/O的使用情况进行分析。
# iostat – d 1 10 (只采样硬盘数据,每秒采样 1 次,一共采样 10 次)
Disks: % tm_act Kbps tps Kb_read Kb_wrtn
hdisk0 0.2 2.4 0.2 1192730 706531
hdisk1 0.0 0.3 0.0 60479 190316
hdisk0 35.5 848.0 76.0 1696 0
hdisk1 74.5 790.0 58.0 4 1576
% tm_act 硬盘的繁忙程度,数值越高越繁忙。
Kbps 数据流量,为读操作与写操作的总和。
tps 每秒钟的 I/O 次数。通常一块硬盘每秒的 I/O 次数由硬盘的转速、磁头寻道时间、磁头从盘片表面传输数据的速度决定。
Kb_read 在采样间隔期间读的数据量。
Kb_wrtn 在采样间隔期间写的数据量。
磁盘的数据流量很大程度上与应用程序的 I/O 方式相关。一般硬盘最大的 I/O SIZE 为 128kb 或 256kb ,每秒 I/O 次数一般为 100~150 之间。因此在最理想的情况下数据流量可达到 12mb/sec ~ 37mb/sec (当然也要受制于接口的带宽)。用 Kbps 除以 tps 可以得到平均的 I/O SIZE 。某些应用程序的 I/O SIZE 可能低至 2kb ,而且产生大量的随机读写操作,从而使硬盘的读写效率大大降低,导致 CPU 的 I/O 等待增加。
有时 I/O 问题是 I/O 带宽不足引起的。当所有连接在一块 I/O 卡上的硬盘的流量总和达到 I/O 卡带宽的 70% 以上时,应考虑增加更多的 I/O 卡。
数据的分布也是很重要的因素。通常把数据分布到更多的硬盘上更有利于提高 I/O 性能。
因一部分析 I/O 问题,可用以下命令:
# filemon -o outputfile -O all;sleep 30;trcstop
找出系统中最繁忙的文件、逻辑卷或磁盘。从中可以分析出文件、逻辑卷和磁盘的读写操作是连续的 (sequential) 还是随机的 (randomly) 。
# fileplace -v filename
查看文件数据块的分布 , 从中可以分析文件是否有碎片。
#lslv-p hdiskx__lvname
查看逻辑卷在硬盘上的分布位置,从而分析出逻辑卷是连续分布,还是有碎块。根据逻辑卷的实际使用情况可以对逻辑卷的物理分布作出调整。
如果还不是I/O瓶颈则, 应看看网络的情况:
对于网络问题可以用"netstat"命令进行分析:
# netstat -m
查看有多少对mbufs的请求被拒绝
# netstat -s
查看各个网络协议的统计数据,如IP, TCP, UDP等
# netstat -v
查看块网卡的S/W Trans_Q overflow及 S/W Trans_Q 队列中最多的包是多少。 如果传输队列中有溢出的现象,则应调整网卡的设置。
# netstat -I en0 1
查看以太网接口en0及整个系统的网络数据流量。
# lsattr -El ent0
查看以太网卡ent0的设置信息。
# no -a
查看网络选项,如thewall值的设置等。
如果以上步骤都没有发现系统有资源上的瓶颈,则很可能是应用程序的问题,需要应用程序开发商进行进一步的分析。
对于性能的分析,IBM还提供了"perfpmr"工具。该工具可以对系统性能的各方面信息进行收集,通过IBM实验室的分析可以帮助客户找出导致性能不理想的原因。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞0作者其他文章
评论 4 · 赞 2
评论 0 · 赞 2
评论 0 · 赞 0
评论 0 · 赞 2
评论 0 · 赞 1
添加新评论0 条评论