Redis 7内存优化--1.简化dict数据结构
dict是Redis的基础数据结构,Redis的键值、hash|set|zset数据结构均用到了dict。本文介绍了Redis7在dict上的优化,思路清晰简单但效果明显,值得重点关注(降本增效)。
来源:Significant memory savings in case of many hash or zset keys (#9228)
一、优化前的dict结构
7.0之前:dict内部包含了两个dictht
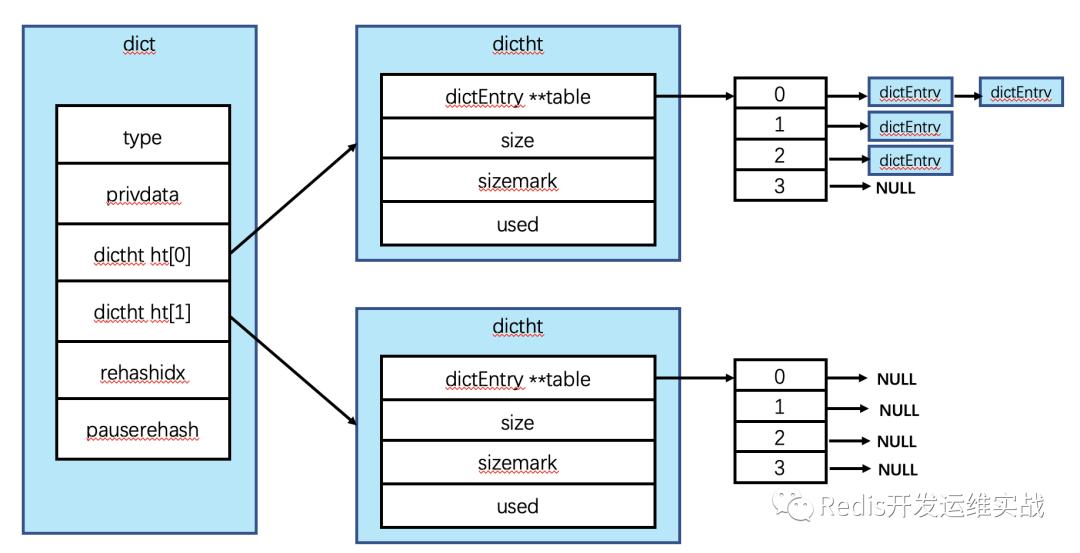
相关代码:
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx;
int16_t pauserehash; } dict;
二、Redis 7.0的相关优化
- 去掉privdata
- 去掉dictht,相关元数据放到了dict中。
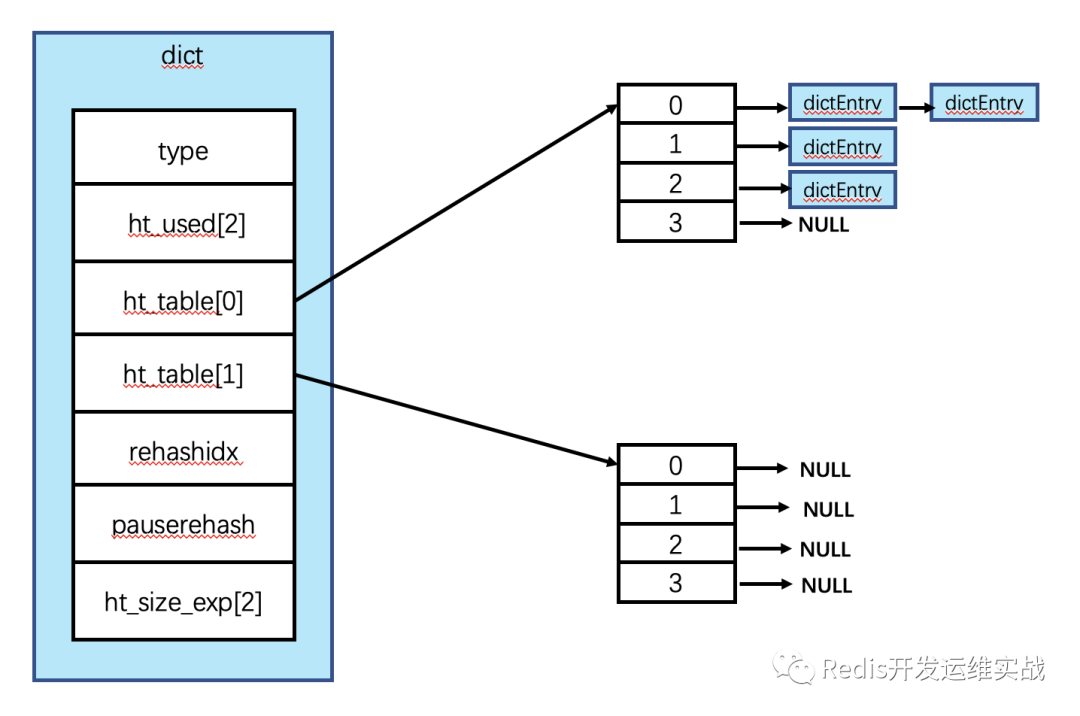
相关代码变为:
struct dict {
dictType *type;
dictEntry **ht_table[2];
unsigned long ht_used[2];
long rehashidx;
int16_t pauserehash;
signed char ht_size_exp[2];
};
- dictht ht[2]用dictEntry **ht_table[2]代替
- 原来两个dictht的used用unsigned long ht_used[2]代替
原来两个dictht的size用signed char ht_size_exp[2]代替,且由8个字节变为1个字节,计算方法如下:
#define DICTHT_SIZE(exp) ((exp) == -1 ? 0 : (unsigned long)1<<(exp))
define DICTHT_SIZE_MASK(exp) ((exp) == -1 ? 0 : (DICTHT_SIZE(exp))-1)
三、效果:
通过数据结构的优化(96->56字节),必然会在hash|set|zset key较多且为小value时,效果更为明显。由于要对单一功能进行测试,所以这里直接使用PR中的测试结果(https://github.com/redis/redis/pull/9228),
(1) 内存优化:提升较为明显
| original dict | original dict | optimized dict |
|---|---|---|
| 1000000 65 byte one field hashes | 290.38M | 252.23M |
| 1000 hashes with 1000 20 byte fields | 62.22M | 62.1M |
| 1000000 sets with 1 1 byte entry | 214.84M | 176.69M |
| dict struct size (theoretical improvement) | 96b | 56b |
(2) 性能变化:除了get random keys外,其他整体有提升。
| dict benchmark 10000000 | Inserting | Linear access of existing | 2nd round | Random access of existing | Accessing random keys | Accessing missing | Removing and adding |
|---|---|---|---|---|---|---|---|
| original | 5371 | 2531 | 2507 | 4135 | 1447 | 2893 | 4882 |
| optimized | 5253 | 2488 | 2481 | 4076 | 1600 | 2841 | 4801 |
| improvement | 2.20% | 1.70% | 1.04% | 1.43% | -10.57% | 1.80% | 1.66% |
四、总结:
这个优化思路清晰,把Redis的基础数据结构dict进行优化,因此会在内存优化上有很大效果,值得学习和使用。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞3作者其他文章
评论 1 · 赞 8
评论 0 · 赞 4
评论 0 · 赞 0
评论 0 · 赞 3
评论 0 · 赞 4
添加新评论0 条评论