金融企业容器云建设中资源智能优化实践分享
摘要:
降本增效从云计算发展至今一直都是企业上云最核心的关注点,无论是在线业务还是大数据、AI业务,都非常依赖算力的消耗,成本问题都是企业上云进行决策的核心因素,而资源优化则是降本增效的有效手段;本文通过设计容器云平台并从Pod压缩、Node压缩、水平/垂直扩缩容等方面作为切入点,通过基于intel架构容器云平台实践可将整体资源利用率可提高10%至20%左右,可供相关行业实践提供参考。
1背景
降本增效从云计算发展至今一直都是企业上云最核心的关注点,无论是在线业务还是大数据、AI业务,都非常依赖算力的消耗,成本问题都是企业上云进行决策的核心因素,而资源优化则是降本增效的有效手段。
从云计算本身来看,单纯把业务从传统虚拟机搬迁上云不修改任何业务架构,提高计算资源利用率需要非常大的运维成本和人力成本投入到改造业务适配弹性伸缩和业务可调度性中。随着云原生技术的普及和推广,容器kubernetes等技术能够天然的与业务、基础设施结合,简化资源管理、感知业务类型、自动弹性扩容和调度。
实现企业容器云中资源的智能优化,进一步更好的实现降本增效,需要进行一系列的资源优化,包括且不限于基于成熟度模型提供资源利用率提升建议、多维度弹性资源使用建议、Pod/Node资源使用识别与压缩等。
2需求分析
2.1 资源利用率成熟度模型
充分利用弹性伸缩能力,是提高资源利用率、降低资源成本的关键点之一。对比未使用弹性伸缩的情况,整体资源利用率能够提高20-30%以上。因此提出了容器化资源利用率成熟度模型,如下图所示:
图 1 资源利用成熟度模型
- 第一阶段
传统部署模型,业务为应对不同时间段计算资源使用不同的情况,必须以最高使用资源的峰值加一定的余量进行基础设施的采购,平均利用率降低。 - 第二阶段
简单容器化改造后的业务,上云并容器化改造,利用了容器进行业务混合部署,一定程度提高了资源利用率。 - 第三阶段
业务进行微服务改造,业务可利用容器和云的弹性伸缩能力,结合 Kubernetes 的 HPA、VPA、CA 等能力,高峰扩容、空闲缩容,极大提高资源利用率。 - 第四阶段
极致利用云和容器化后的弹性,提高弹性伸缩灵敏度和精度,有离线业务的进行在离线混布,极致提高平均资源利用率。
2.2 集群资源利用率
我们的目标是要提高集群资源利用率,那么我们首先来分析一下集群资源利用率低下的原因,对症下药方能提高集群资源利用率。
- 第一点,是Node节点资源的碎片,在我们那么多的集群里面会发现,往往分配比整个集群到90%多的时候,就会创建不了Pod了,其实每个Node都会有一些零碎的资源,目前在某些行业中,基于裸金属(如Intel X86架构)部署多个容器云集群已经成为一种趋势,与传统基于虚拟机形式不同,基于裸金属部署在虚拟化层面的损耗会更小,但相应来看,因直接使用裸金属能力,其资源的碎片利用也更加重要。
- 第二点,Pod Resource配置不合理。业务在创建Pod的时候,都不清楚自己到底要设多少,所以往往会设很大,从而造成资源的浪费,而且他们的比例设置的requests和limits得也不太合适。
- 第三点,WorkLoad/HPA 副本数设置不合理。就是我们workload的副本数。很多人在上云的过程中,很多人不知道自己要设置多少的副本才合适,在这里面,也涉及到一个最小副本数设计多大才是合理的。
- 第四点,业务的空闲时间。我们会发现很多业务都是有它固定的特性,比如说游戏,我们会发现晚上会有一个使用高峰期,而在我们白天上班期间,资源使用率相对会低些。
2.3 弹性伸缩
弹性伸缩又称自动伸缩,是云计算场景下一种常见的方法,弹性伸缩可以根据服务器上的负载、按一定的规则、进行弹性的扩缩容服务器。弹性伸缩在不同场景下的含义:
- 对于服务运行在自建机房的公司,弹性伸缩通常意味着允许一些服务器在低负载时进入睡眠状态,从而节省电费(以及用于冷却机器的水费和水费)。
- 对于使用在托管在云上的机房的公司而言,自动扩展可能意味着更低的费用,因为大多数云提供商都基于总使用量而不是最大容量进行收费。
- 即使对于不能在任何给定时间减少运行或支付的总计算能力的公司,它们也可以在低流量时降低服务器的负载。
- 弹性伸缩解决方案还可以用来替换异常状态的实例,从而在一定程度上防止硬件,网络和应用程序故障。
- 在生产工作负载经常变化且不可预测的情况下,弹性伸缩可以提供更长的正常运行时间和更高的可用性。
弹性伸缩的三大关键要素分别是:基于什么特征和属性、采取什么策略、伸缩的对象是什么。
2.4 成本控制
成本控制(Cost Control)的过程是运用系统工程的原理对企业在生产经营过程中发生的各种耗费进行计算、调节和监督的过程,也是一个发现薄弱环节,挖掘内部潜力,寻找一切可能降低成本途径的过程。
在容器云中,需要进行如下举措以控制成本:
- 资源限制:有效的资源约束,能够确保容器云系统的资源使用不会超出成本预算。但是,请注意不要无限制地限制你的资源。如果资源限制太低,软件将无法正常运行。
- 弹性伸缩:自动扩展意味着允许容器云自动扩缩以适应快速变化。水平和垂直自动扩缩是可用的两种自动扩缩类型。简而言之,水平自动扩缩涉及根据负载是高于还是低于指定水平来新增和移除Pod。各个Pod的比例与垂直自动扩缩比例保持平衡。
- 资源标记:在任何环境中,无论是云,还是本地器,标记资源都是一个明智的主意。组织在有多个测试,开发和生产环境中,更应使用标记来确保所有服务均受到控制。
- 定期清理:如果让工程师有权按需构建命名空间,或者有权构建CI/CD流水线,则最终可能会产生许多未使用的对象或集群,但这些仍然在花费资源,因此,当发现某些资源长时间处于非活动状态时,删除它们将是一件很明智的事情。。
3容器云平台建设架构设计
3.1 总体架构设计
容器云支撑平台以统一门户为入口,提供多集群管理、统一模板、应用市场等功能;可选择以Kubernetes、OpenShift等作为容器编排,提供应用编排、资源控制、健康检查、弹性扩容等功能,从业务需求管理、应用开发、系统集成、持续构建、持续部署到应用运维保障方面为应用提供全生命周期的支撑管理能力。
在部署模式上,选择基于英特尔®至强®可扩展处理器架构的裸金属部署,根据企业实际需求(如业务安全等级、业务隔离性要求等)在多个“区域”进行建设。
3.2 网络架构设计
早期的容器云平台建设中,受限于容器网络技术发展的限制,一般采用的都是Overlay 的网络模式,Overlay 无可厚非有其技术优势,但对于一个大型企业、特别是有自建数据中心的企业,要充分考虑到Overlay 网络带来的技术和管理成本,对某类应用有高可用等要求,一旦网络出现异常,Overlay 在故障排查等方面有不少局限。在本方案中,则结合实践经验,提出calico+vlan的双栈模式,pod既可使用calico网络,也可使用VLAN网络,既能从网络角度有效支撑各类容器应用对网络的管控,也能满足大型企业中对网络的精细度管控,其具体方案示意如下:
其实现原理为每台宿主机上 OVS 实现二层转发(给 Pod 分配 VLAN IP),OVS VLAN基于VLAN CNI,使用了 OVS 的 VLAN bridge功能,免除了 vxlan 等隧道封装开销,保障了高效的转发性能。
在底层虚拟化层面上,优先选用支持SR-IOV虚拟化技术的网卡设备。SR-IOV 全称 Single Root I/O Virtualization,是 Intel 在 2007年提出的一种基于硬件的虚拟化解决方案。
在虚拟化应用中,CPU与内存是最先解决的,但是 I/O 设备一直没有很好的解决办法,Intel 有 VT-d(Virtualization Technology for Directed I/O)可以将物理服务器的 PCIe 设备直接提供给虚拟机使用,也就是常说的“直通”(passthrough),但是直通面临一个问题是 PCI-e 设备只能给一个虚拟机使用,其他虚拟机就使用不了,所以有了 SR-IOV,一个物理设备可以虚拟出多个虚拟设备给虚拟机使用。使用SR-IOV有以下优点:
- 高性能:从虚拟机环境直接访问硬件。
- 成本降低:包括节点、减少了适配器数量、简化了布线、减少了交换机端口等。

3.3 存储架构设计
存储可根据场景分为本地磁盘存储、集中式存储、分布式存储,应根据不用的使用场景选择不同的存储方案。
- 本地磁盘存储
本地磁盘是最容易想到的方式,也是从物理机时代就一直在使用的方式。由于磁盘和应用系统中间的 IO 路径最短,本地磁盘可以提供最佳的性能。然而本地磁盘方案存在无法提供节点级别的高可用和敏捷性差的问题。因此本地磁盘存储的方案比较适合多容器之间共享缓存或者对存储IO要求很高的场景下。
本方案中,通过emptyDir或者hostPath进行使用,前者适合多容器之间进行缓存共享,使用节点自身的临时存储;后者适合对IO要求很高的场景,搭配节点选择器或者节点标签指定节点进行使用。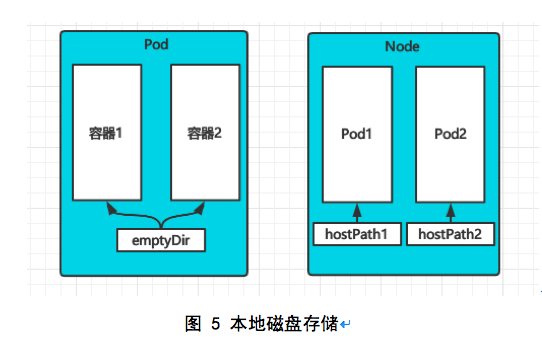
- 集中式存储
集中式存储如NAS、NFS、SAN,提供了可远程访问共享存储的能力。和本地磁盘的方案相比,集中式存储解决了应用系统高可用的问题,当业务系统所在的服务器发生故障时,由于数据不再存储在服务器本地,而是存储在远端的共享存储中,所以可以在其他节点上把应用拉起来,以实现业务系统的高可用。此外,由于数据集中存储,也一定程度解决了本地存储对磁盘空间浪费的问题。
本方案中,通过NFS或者NAS实现集中式存储,在应用的不同副本见进行共享。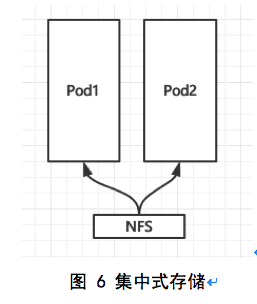
- 分布式存储
分布式存储天然具有横向扩展能力,在性能和高可用方面优于集中式存储,非常适合应对大规模虚拟化场景,分布式存储的诞生就是为了解决集中式存储无法解决的问题,与此同时,分布式存储也逐渐具备了企业级存储的能力,包括快照、克隆等等。适用于对于存储IO要求较高,并且支持单节点挂载的场景。
本方案中,使用Ceph 实现分布式存储。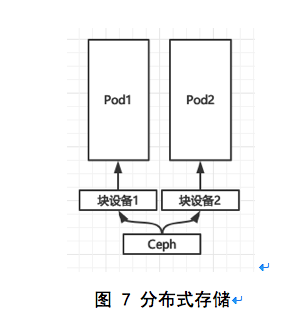
- 持久内存(PMEM)存储
PMEM是驻留在内存总线上的固态高性能按字节寻址内存设备。和传统闪存不同,PMEM 位于内存总线上,支持像 DRAM 一样访问数据,兼具低时延与持久化的特性,适合一些实时性要求比较高且数据量巨大的工作负载,需要使用专用的PMEM-CSI驱动。
英特尔®傲腾™持久内存CSI是一个CSI存储驱动程序,用于像Kubernetes这样的容器编排器。 它可以将本地持久内存(PMEM)作为文件系统卷提供给容器应用程序,并且支持LVM和直接访问模式。
LVM模式下无需修改应用,直接声明即可使用。此模式是把节点上PMEM资源统一成VolumeGroup,然后通过声明PVC类型和容量,使用PMEP-LVM。适用于无服务器化应用,CICD短生命周期高速临时存储,以及低延迟高吞吐的数据类应用,无需修改应用,即可实现IO性能的2~10倍的提升。
直接访问模式下,需要对应用的内存分配部分函数做有限的修改,目的是为了达到极致、可以媲美DRAM的访问性能。对内存数据库Redis、HANA等大内存低成本需求,同时满足对TB级别的DRAM和成本的诉求,降低了内存成本30%~50%。
3.4 日志架构设计
OpenShift使用EFK来实现日志管理平台。该管理平台具备以下能力:
■ 日志采集,集中存放日志
■ 索引日志内容,快速返回查询结果
■ 具有伸缩性,在各个环节都能够扩容
■ 强大的图形查询工具、报表产出工具
EFK是Elasticsearch + Fluentd + Kibana的简称。ES负责数据的存储和索引,Fluentd负责数据的调整、过滤、传输,Kibana负责数据的展示。
Openshift部署环境使用EFK进行日志管理。其流程如为:Fluentd以DaemonSet方式部署,将收集宿主机中的docker和OCP日志,并发送到ES。OCP集群内的每个节点都会启动一个Fluentd容器。
ES用于日志存储,会部署在infra结点,同时配置成replicas=2,实现高可用。其部署架构如下图所示: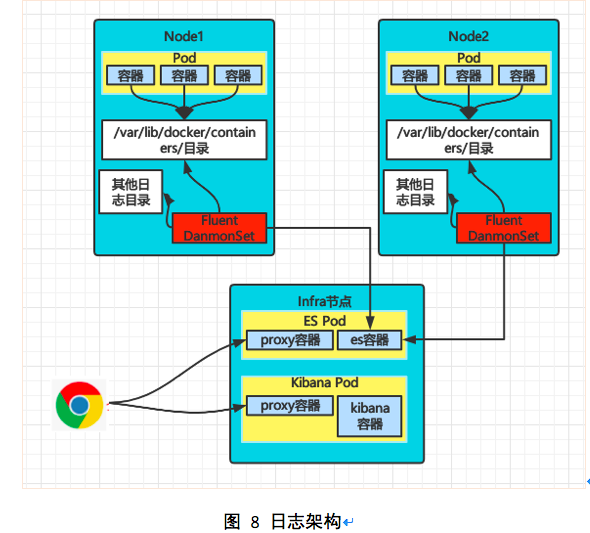
3.5 监控告警架构设计
OpenShift 提供了基于 Prometheus + Grafana 的监控系统。针对每个需要被监控的指标,都利用了Prometheus提供的某个功能来实现对它的监控,通过拉取指标数据保存在时序数据库TSDB中,其提供计量数据查询功能,实现了类似于 SQL 的查询语法PromSQL,可以实现灵活的查询,最后通过Grafana在页面上进行展示。
其也通过AlertManager组件提供了告警功能,能根据已定义的告警规则向外输出告警,可接入多种告警渠道(邮件、短信、微信等)
整体架构如下图所示: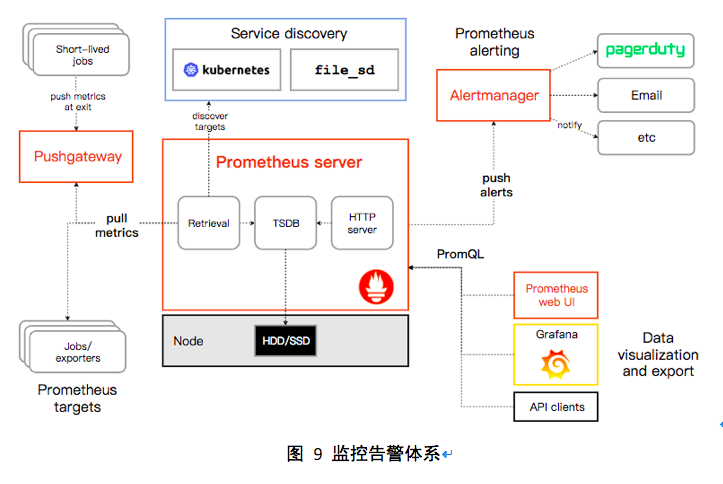
3.6 工作负载设计
数字化转型的浪潮持续席卷着各路市场和企业。基于云的 IT 战略有望带来敏捷性、安全性和效率方面的提升;与此同时,工作负载本身也变得越来越复杂,无论是新的云原生应用、人工智能还是既有的服务,都是如此。
那么如何无缝迁移我们的工作负载?如何确保基础设施能够满足用户或应用的要求?长期的灵活性、成本和可扩展性问题又如何解决?这些问题的答案与底层云基础设施服务(包括硬件和软件)及所涉及的工作负载息息相关。
每个应用和工作负载都对基础设施有着不同的要求,且会随时间的推移而不断变化。例如,科学建模、数据分析、安全和数据压缩等工作负载可用如英特尔® 高级矢量扩展 512(英特尔® AVX-512)指令集来实现加速。而人工智能工作负载的性能则可以利用如英特尔® 深度学习加速(英特尔® DL Boost)实现显著提升。根植于芯片且基于英特尔硬件的安全功能创造了一个可信基础,有助保护空闲中、传输中和使用中的各个阶段的数据,并且优化在云中运行的应用,帮助降低风险和复杂性,优化性能并提高整个数据中心和云服务的运营效率。
在对一些实时性要求比较高且数据量巨大的工作负载(如实时欺诈检测、实时金融交易等)可将数据存放在PMEM(持久内存)中进行访问,和传统将实时数据存放于DRAM中的方案相比,PMEM具有如下特点:
- 成本更低:在同样的容量下,PMEM的成本仅为DRAM的一半至三分之一
- 容量更大:PMEM主流规格为128G/256G/512G,而DRAM主流规格为8G/16G/32G/64G,其容量远远高于传统的DRAM。
- 低时延:PMEM位于DRAM内存总线上,支持像DRAM一样访问数据,和DRAM时延相当,比传统闪存(如SSD)快得多,传统闪存位于PCIe总线上,和PMEM具有本质的区别。
- 数据持久化:在断电后仍然可持久化数据,这个特性和传统闪存一致
- 硬件加密:PMEM配备行业标准的 256-AES 硬件加密功能。加密密钥存储在模块的安全元数据区域中,只能由特定控制器访问,提高了数据安全性。
PMEM是驻留在内存总线上的固态高性能按字节寻址内存设备。PMEM 位于内存总线上,支持像 DRAM 一样访问数据,如下图所示,其位于闪存与内存之间,意味着它具备与 DRAM 相当的速度和延迟,而且兼具 NAND 闪存的非易失性。
图 10 存储金字塔
3.7 硬件配置规划
根据集群规模选择需要的服务器数量,其中一台工作负载节点服务器可参考如下配置:
- CPU:单机配置2颗英特尔®至强®可扩展处理器金牌系列,24C/48T、2.3GHz处理器,最大支持2颗CPU,支持PMEM持久内存;
- 内存:配置128GB DDR4 ECC REG,基于后期扩展,最大支持≥8 根;
- 内存插槽,最大可支持 1TB 内存,支持内存保护、内存镜像、内存热备和内存热插拔;
- 硬盘:配置3 块1.2T(热插拔)10000RPM/2.5寸SAS盘(根据实际需求选择);
- 持久内存:配置256GB持久内存用于实时性要求较高的负载(根据实际需求选择);
- 网络接口:配置双口千兆以太网控制器,支持虚拟化、网络加速、负载均衡、冗余、SR-IOV等高级功能;
- I/O 扩展:基于应用,支持≥8个PCIE3.0插槽
4资源智能优化方案设计
4.1动态准入控制
Kubernetes 提供了需要扩展其内置功能的方法,最常用的可能是自定义资源类型和自定义控制器了,除此之外,Kubernetes 还有一些其他非常有趣的功能,比如 admission webhooks 或者 initializers,这些也可以用于扩展 API,动态准入控制即通过admission webhooks达到修改 Kubernetes 资源的基本行为,是实现资源智能优化的有效手段之一。
准入控制器是在对象持久化之前用于对 Kubernetes API Server 的请求进行拦截的代码段,在请求经过身份验证和授权之后放行通过。准入控制器可能正在validating、mutating或者都在执行,Mutating 控制器可以修改他们的处理的资源对象,Validating 控制器不会,如果任何一个阶段中的任何控制器拒绝了请求,则会立即拒绝整个请求,并将错误返回给最终的用户。这意味着有一些特殊的控制器可以拦截 Kubernetes API 请求,并根据自定义的逻辑修改或者拒绝它们。当然也可以编写自己的控制器,虽然这些控制器听起来功能比较强大,但是这些控制器需要被编译进 kube-apiserver,并且只能在 apiserver 启动时启动。
由于上面的控制器的限制,因此就需要用到“动态”的概念了,而不是和 apiserver 耦合在一起,Admission webhooks和initializers就通过一种动态配置方法解决了这个限制问题。对于这两个功能,initializers属于比较新的功能,平时用得非常少,还是一个alpha特性,所以后续会更多的介绍Admission webhooks。
在Kubernetes apiserver中包含两个特殊的准入控制器:MutatingAdmissionWebhook和ValidatingAdmissionWebhook。这两个控制器将发送准入请求到外部的 HTTP 回调服务并接收一个准入响应。如果启用了这两个准入控制器,Kubernetes 管理员可以在集群中创建和配置一个admission webhook。
这两种类型的 admission webhook 之间的区别是非常明显的:validating webhooks 可以拒绝请求,但是它们却不能修改在准入请求中获取的对象,而 mutating webhooks 可以在返回准入响应之前通过创建补丁来修改对象,如果 webhook 拒绝了一个请求,则会向最终用户返回错误。
因此本文主要通过mutating webhooks来实现对资源的智能控制。
4.2 Pod压缩
Pod压缩有个前提条件,在于limits是给用户保证的一个资源值,也就是单个Pod最多能够使用多少核CPU和多少G内存。Request会影响调度,调度时scheduler组件会使用每一个node中的可分配资源和已分配的Pod Requests做来计算。当已分配requests等于或者接近于可分配资源的话,那就不会再调度Pod进来了。它主要解决的是Pod本身的一个资源的调整。
当创建一个Pod的时候,会设计一个ratio值,当用户有Pod创建请求过来的时候,我们会帮他篡改Pod的数据,然后按照我们设计的比例,用ratio来限制Pod的request值,所以无论这个值设的多少,最后都会被我们改掉。这样做的原因就是为了将requests和limits拉开一定的空间,从而达到超分的效果。
整体实现流程如上图所示,第零步mutating webhooks相关逻辑控制服务,并使用MutatingWebhookConfiguration资源对象进行配置并且部署该服务。
第一步则是使用常规的方法创建一个Pod。
第二步则是经过认证授权后,apiserver会以https的方式对MutatingAdmissionWebhook进行调用,Pod资源对象的内容则包含在http的body中,以json的方式进行传输,MutatingAdmissionWebhook会根据策略对修改该Pod资源对象的内容,对Pod进行资源压缩,也就是上文提到的ratio值,主要是对request资源进行压缩。
第三步则是对处理过后的Pod资源对象内容以AdmissionReview Response的形式进行返回,最终将返回的数据保存到Etcd中。
通过以上这种方式,如果某个请求中request的值超过了设计的值,就会对Pod进行压缩,整个集群的资源的request给压缩下来,当request压缩下来之后,就可以创建跟多的Pod。
4.3 Node压缩
kubelet默认每隔10秒就会重新计算自身Node的可分配的资源并发生一个patch的请求给kube-apiserver,来上报自身的状态,在这个过程中,主要做两个方面的实践。
第一是由一个组件,通过Prometheus来获取Node历史使用数据,然后根据node当前的资源分配和使用情况来自动计算压缩比例。比如当Node资源已分配非常多,但是使用率又相对比较低的时候,则认为该Node的实际利用率很低,可以进行压缩。
第二点就是和上面Pod压缩类似,根据Mutating Admission Controller机制,在kubelet每隔10秒默认的周期发生Patch请求时,根据上述计算出来的压缩比例,对Node可分配资源进行修改。
整体实现流程如上图所示,第零步依然是使用MutatingWebhookConfiguration资源对象进行配置并且部署Node压缩的服务。
第一步则是kubelet每隔10秒就会重新计算自身Node的可分配的资源并发生一个patch的请求给kube-apiserver,Node压缩正是对该patch操作做处理。
第二步则是经过认证授权后,apiserver会以https的方式对MutatingAdmissionWebhook进行调用,Node状态的内容则包含在http的body中,以json的方式进行传输,MutatingAdmissionWebhook会根据Prometheus获取到的Node的历史使用数据计算出压缩比列,对Node可分配资源进行修改。
第三步则是对处理过后的Pod资源对象内容以AdmissionReview Response的形式进行返回,最终将返回的数据保存到Etcd中。
通过以上这种方式,当Node资源已分配非常多,但是使用率又相对较低的时候,则会对Node资源进行压缩,达到资源智能控制的目的。
4.4水平自动伸缩HPA
容器云带来的最吸引企业的优势之一即是其为应用架构带来的动态水平扩缩容能力,而在kubernetes中,其的关键实践就在于HPA(Horizontal Pod Autoscaler)控制器。它根据观察到的CPU使用率(或使用自定义指标支持,基于某些其他应用程序提供的指标)自动缩放 replication 控制器,deployment,副本集或状态集中的 pod 数量,该类特性也是容器云企业应用最多、最为成熟的特性之一,如下也给出了我们某些场景的测试情况: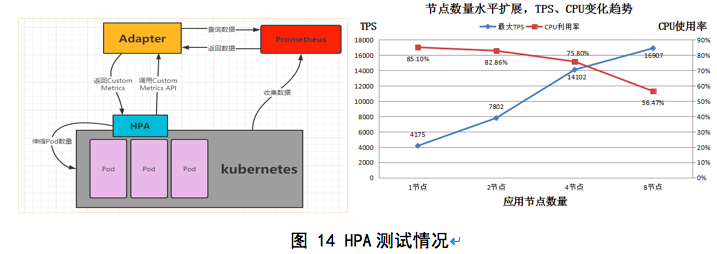
在HPA实施中,我们一般建议企业进行一定的定制优化,以实现更加智能的动态横向伸缩能力,这里建议在自动伸缩的基础上,基于历史监控数据以及与企业大数据平台的整合,实现按计划伸缩、基于预测的伸缩等高阶能力,如下示意: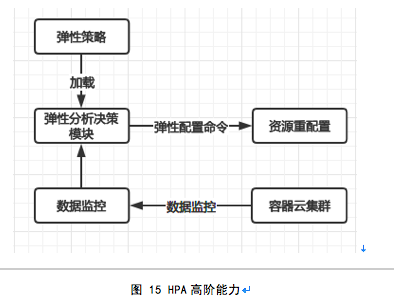
其中可结合企业的数据分析以及算法能力,从经济价值、业务支撑等多个维度设计适应企业的伸缩算法。
HPA的实现思路很容易想到:通过监控业务繁忙情况,在业务忙时,就要对workload扩容副本数;等到业务闲下来时,自然又要把副本数再缩下去。所以实现水平扩缩容的关键就在于:
- 如何识别业务的忙闲程度
- 使用什么样的副本调整策略
Kubernetes提供了一种标准metrics接口(整个HPA及metrics架构如下图所示),HPA controller通过这个统一metrics接口可以查询到任意一个HPA对象关联的deployment业务的繁忙指标metrics数据,不同的业务的繁忙指标均可以自定义,只需要在对应的HPA里定义关联deployment对应的metrics即可。
标准的metrics查询接口有了,还需要实现metrics API的服务端,并提供各种metrics数据,我们知道k8s的所有核心组件之间都是通过apiserver进行通信,所以作为k8s API的扩展,metrics APIserver自然选择了基于API Aggregation聚合层,这样HPA controller的metrics查询请求就自动通过apiserver的聚合层转发到后端真实的metrics API的服务端(对应下图的Promesheus adapter和Metrics server)。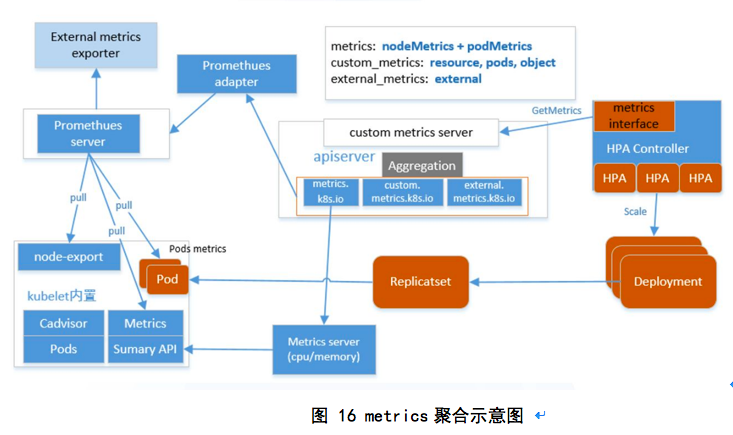
这里简单说一下Aggregator ,Aggregator 允许开发人员编写一个自己的服务,把这个服务注册到 Kubernetes 的 APIServer 里面去,这样就可以像原生的 APIServer 提供的 API 使用自己的 API 了,我们把自己的服务运行在 Kubernetes 集群里面,然后 Kubernetes 的 Aggregator 通过 Service 名称就可以转发到我们自己写的 Service 里面去了。这样这个聚合层就带来了很多好处:
- 增加了 API 的扩展性,开发人员可以编写自己的 API 服务来暴露他们想要的 API。
- 丰富了 API,核心 kubernetes 团队阻止了很多新的 API 提案,通过允许开发人员将他们的 API 作为单独的服务公开,这样就无须社区繁杂的审查了。
- 开发分阶段实验性 API,新的 API 可以在单独的聚合服务中开发,当它稳定之后,在合并会 APIServer 就很容易了。
- 确保新 API 遵循 Kubernetes 约定,如果没有这里提出的机制,社区成员可能会被迫推出自己的东西,这样很可能造成社区成员和社区约定不一致。
4.5垂直自动伸缩VPA
在企业应用云环境中,往往还会面临一个实际的问题,也即是容器的高资源利用率无法有效发挥在基础设施效能方面的作用,研发项目依然习惯性以4C/8G、8C/6G的传统IaaS的模式进行资源申请和使用,该模式下其实无法很好的发挥在极致资源利用率方面的优势,故在容器云实践中,我们强烈建议启用VPA纵向扩缩容机制。
垂直自动伸缩(VPA,Vertical Pod Autoscaler) 是一个基于历史数据、集群可使用资源数量和实时的事件(如 OMM, 即out of memory)来自动设置Pod所需资源并且能够在运行时自动调整资源基础服务。简单来说是 Kubernetes VPA 可以根据实际负载动态设置 pod.resource.requests。
VPA使用户无需为 Pod 中的容器设置最新的资源limit和request的大小。配置后,VPA将根据使用情况自动设置请求,从而允许对节点进行适当的调度,以便每个 Pod 都可以使用适当的资源量。它还将维护在初始容器配置中指定的limit和request之间的占比。因此VPA它既可以缩小资源请求过多的 pod,也可以根据一段时间内的使用情况扩大资源请求不足的 pod。
它还将维护在初始容器配置中指定的limit和request之间的占比。因此VPA它既可以缩小资源请求过多的 pod,也可以根据一段时间内的使用情况扩大资源请求不足的 pod。Autoscaling 配置了一个 名为VerticalPodAutoscaler的 自定义资源定义对象。它允许指定哪些 pod 应该垂直自动缩放以及是否/如何应用资源。
通过Prometheus监控可以看到VPA对于资源使用为例的动态控制效果: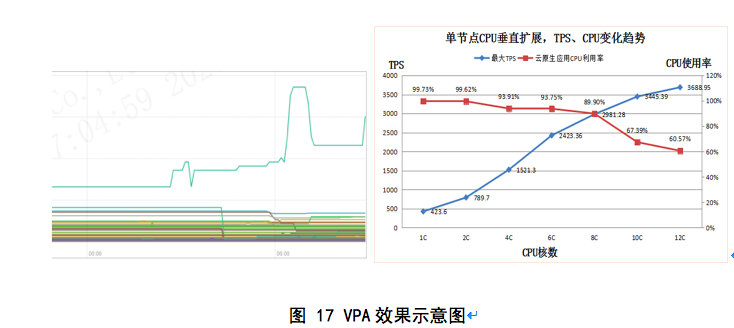
我们可以看到,VPA控制CPU资源的利用情况,在忙时动态的扩大CPU的分配量,在闲时VPA会维持一个较低的资源占用率,因此VPA在动态的控制应用的资源占用,对集群的资源节约有非常好的效果。但在VPA的机制的应用中,一般建议自行扩展相应的控制器并设计实现一套符合企业自身的伸缩算法,这里给出一些要点:
- 结合企业应用技术特点,分类分场景设定应用资源默认值。
- 建立全面的指标采集体系,并设定VPA准则,如调整时间窗口、前置条件(如POD数量为1则不进行调整、性能测试不调整等)
根据不同的容器云引擎(K8S)版本,优化VPA调整时POD不重启等体验。
就VPA实现原理来讲,其包含以下组件
- Recommender:负责计算推荐资源,该组件启动时会获取所有 Pod 的历史资源利用率(无论是否使用了VPA),以及历史存储(如Promethues,通过参数配置)中的 Pod OOM 事件的历史记录,然后聚合这些数据并存储在内存中。Recommender 会监听集群中的所有 Pod 和 VPA ,对于和某个 VPA 匹配的Pod,它会计算推荐的资源并在对应 VPA 中设置推荐值。
- Updater:监听集群中的所有 Pod 和 VPA,通过调用 Recommender API 定期获取 VPA 中的推荐值,当一个 Pod 的推荐资源与实际配置的资源相差较大时,Updater 会驱逐这个 Pod(注意:Updater并不负责 Pod 资源的更新),Pod 被其控制器重新创建时,Admission Controller 会拦截这个创建请求,并使用推荐值修改请求值,然后 Pod 使用推荐值被创建。
- Admission Controller: 会拦截所有 Pod 的创建请求,如果 Pod 和某个 VPA 匹配且该 VPA 的更新策略不为 Off,Admission Controller 会使用推荐值修改 Pod 的资源请求,否则不会修改。Admission Controller 从 Recommender 获取资源的推荐值,如果获取超时或失败,则会使用缓存在对应 VPA 中的推荐值,如果这个推荐值也无法获取,则使用 Pod 指定的请求值。
以下是架构图: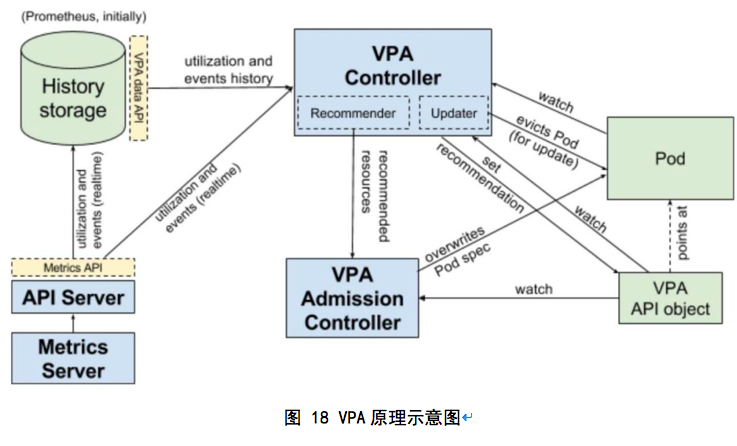
其主要流程为,Recommender在启动时从History Storage获取历史数据,根据内置机制修改VPA API object资源建议值。Updater监听VPA API object,依据建议值动态修改 pod resource requests。VPA Admission Controller则是用Pod创建时修改Pod resource requests。History Storage则是通过Kubernetes Metrics API采集和存储监控数据。
5 总结
在企业上云的过程之中,引入资源智能优化方案以后,将Pod资源压缩交给Pod压缩、VPA进行管理、Pod资源扩展交给HPA管理、节点资源交给Node压缩管理,在本单位的实践中,整体资源利用率可提高30%以上,资源智能优化在企业实现容器云全面支撑转型加速的过程中扮演着重要的作用,是企业降本增效的重要组成部分,在软件和基础设施层面都需要考量。但基于各金融企业各自状况不同,建议通常的建设规划路线如下:
- 一期:逐步完成资源智能优化模块,包括Pod压缩、Node压缩、HPA和VPA,建议找集群进行试点;
- 二期:在第一期的基础之上对各个参数进行调优,包括Pod压缩中request默认值、Node压缩中压缩比例阈值、VPA中request和limit占比值等。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞4
添加新评论3 条评论
2022-02-11 11:49
2022-02-09 16:14
2022-02-09 15:39