智能运维AlOps——日志异常检测新方法
一、背景
日志数据是一种广泛可用的数据资源,用于记录各种软件系统中运行时的系统状态和关键事件。开发人员通常利用日志数据来获取系统状态、检测异常和定位根本原因。隐藏的丰富信息为分析系统问题提供了一个很好的视角。因此,通过在大量日志数据中挖掘日志信息,数据驱动的方法可以帮助增强系统的健康、稳定性和可用性。
随着现代计算机系统规模和复杂性的增加,日志数据呈爆炸式增长。有大量数据驱动的方法可以自动检测异常,例如基于主成分分析(PCA)的方法、基于不变挖掘的方法和基于工作流的方法,基于深度学习的方法如:DeepLog、LogAnomaly、LogRobust等在异常检测中取得了显著的效果。
现有方法是基于一些在现实的生产环境中无法满足的强假设而构建的,在生产环境中应用上述方法时,有两个主要挑战:
- 不断变化的日志: 在实际开发和维护中的那些软件系统中,日志格式在实践中不断变化。
- 潜在的性能问题: 性能问题是部分故障的常见表现,指的是部分功能被破坏。为了解决上述挑战,提出了基于深度学习的日志异常检测模型- SwissLog。
大型系统不可避免地会遇到故障,导致日志模式发生变化。主要有如下几种故障:

▲ 四种日志序列变化模式*
故障1:序列顺序变化
图(a)中的异常序列与正常序列相反,如图(b)所示,其中异常日志语句以黄色突出显示。在这种情况下,系统收到了一个冗余的addStoredBlock请求,导致序列顺序发生变化。因此,通常可以从其异常的序列顺序中观察到序列日志异常。
故障2:日志时间间隔变化
如图1(c)所示,那些有性能问题的块通常保持与正常顺序相同的顺序。但是,性能问题会根据特定任务的故障组件减慢其执行时间通常将时间间隔变化称为性能问题.
故障3:不断变化的事件
图1(d)显示了一个常见的更改事件的情况。字符串“from ip”被添加到日志语句中,但它保持原来的含义。
基于现实的生产环境提出了SwissLog,这是一种鲁棒且统一的基于深度学习的针对各种故障的日志异常检测模型。它可以检测日志数据中表现出的序列顺序变化和日志时间间隔变化。此外,它对不断变化的事件具有鲁棒性。
二、整体框架
SwissLog 包括两个阶段,即 离线处理阶段 和 在线处理阶段 。每个阶段包括日志解析、句子嵌入、基于注意力机制的Bi-LSTM阶段,在线阶段特别包含异常检测阶段。
日志解析部分对历史日志数据进行分词、字典化和聚类,提取多个模板,这些日志语句与相同的标识符联系起来构建日志序列,然后将日志序列转化为语义信息和时间信息。
句子嵌入部分使用BERT模型或Word2Vec模型对句子进行编码,转化为词向量,将这些语义信息和时间信息输入到基于注意力机制的 Bi-LSTM模型中学习正常、异常和性能异常日志序列的特征,在在线检测阶段,一旦检测到异常,就会发出警报,主要流程如下:
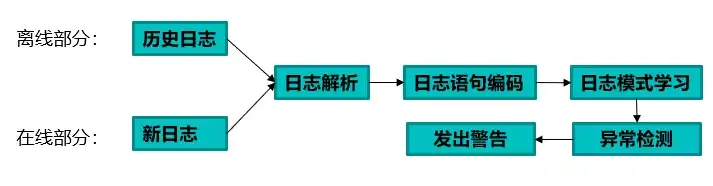
▲ 离线/在线日志异常检测
1. 日志离线/在线解析阶段
日志解析的主要目的是日志模板化。
中心思想:
尽可能将包含语义信息的部分视作日志语句中的常量;
解决方法:
基于字典的日志模板化方法。
主要流程如下:

2. 日志语句编码阶段
异常检测的最终目标是检测我们前面描述的各种故障。我们可以观察到,仅凭语义信息不足以检测多种类型的故障。因此,还引入了时间信息作为特征来补充异常检测方法。日志解析后,我们通过将日志与相同的标识符(如HDFS日志中的block id)或滑动窗口相关联来构建会话。我们将序列转换为语义信息和时间信息。然后我们用下面的方法对这两种信息进行编码。
中心思想:
日志序列是一组有时序特征的自然语言;
解决方法:
同时考虑日志语句的时序特征和语义特征。
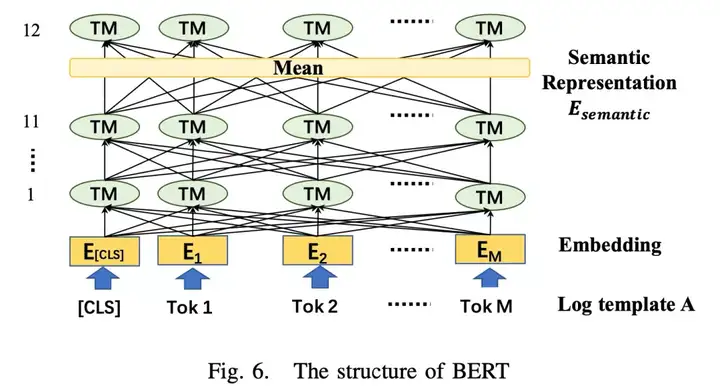
▲ 利用BERT学习一条日志语句的语义信息*

▲ 利用日志序列的打印时间间隔作为时序特征*
3. 日志模式学习阶段
在句子嵌入之后,每条日志消息被转换成一个语义向量和一个时间嵌入向量。将二者串联,每个日志序列都表示为一个向量列表,SwissLog以此类向量为输入,采用基于注意力机制的双向LSTM神经网络模型来检测各种异常,如图所示:
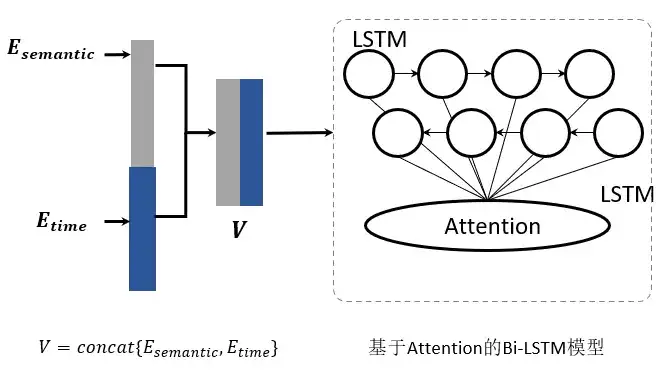
中心思想:
模糊日志序列中不重要的日志语句;
解决方法:
基于注意力机制的双向LSTM模型,学习日志序列的模式。
4. 异常检测
在离线阶段,我们使用历史日志训练获得了一个双向LSTM的预训练模型,可以用此模型进行异常检测。当一组新的日志语句到达时,它首先经过日志解析和句子嵌入阶段。然后将上面阶段获得的输出向量作为输入,输入到预训练模型中。最后,通过双向LSTM模型可以检测是否发生异常。SwissLog根据由共同标识符(例如block ID)关联的日志语句做出预测。
三、总结
本文介绍了一种针对各种故障的强大且统一的基于深度学习的日志异常检测方法,包括以下几个方面:
① 基于字典解析日志消息的方法,它不需要任何参数调整过程。
② 通过引入BERT来编码日志模板,该方法对日志格式变化具有鲁棒性。③ 结合时间嵌入和语义嵌入方法,通过统一的深度学习模型检测顺序日志异常和性能问题,通过这种方法可以对日志进行异常检测。
该方法根据共同标识符(例如如HDFS日志中的block ID)对日志进行关联,结合神经网络模型,综合考虑了日志的时间信息和语义信息,构建了一种有监督的深度学习方法,同时解决了日志检测中常见的一些故障问题,相比于传统的日志检测方法和深度学习检测方法有着更好的效果。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞0作者其他文章
评论 1 · 赞 1
评论 0 · 赞 0
评论 0 · 赞 1
评论 0 · 赞 2
评论 1 · 赞 1
添加新评论0 条评论