
海量小文件备份难?四大关键技术带你逐个击破
当下,非结构化数据已逐渐占据新增数据量的主要成分,而海量小文件是非结构化数据中的一个典型场景,其最大的特征就是在一个复杂的目录结构中,遍布着大量规模为KB级的小文件。
对于海量小文件的备份保护,历来是备份业界的一个难点。今天,让我们走近海量小文件备份,看看这个困扰业界的问题究竟有哪些难题,华为OceanProtect又能给出怎样的答案呢?

01 备份效率低下
在海量小文件场景下,传统备份方式需要遍历目录里每一个子目录与文件,对每一个文件进行打开、读取、关闭操作,比对每个文件数据是否有变化,然后抓取需备份的数据,逐个移动到备份存储,从而备份时间基本都消耗在打开/关闭的操作上,导致备份效率极其低下。
02 勒索软件盛行
勒索病毒的广泛爆发,使个人或企业的关键数据惨遭其害,它会自动识别用户的高价值数据,并将其加密,要求其支付赎金才能解锁,到目前为止,还没有出现较好的勒索软件破解方法。
03 备用数据利用难
对于海量小文件场景,备份数据的利用也是一个难题,传统备份数据恢复方式需要将数据全部复制到生产存储并转化为可供应用识别的格式才能使用,这一过程跟备份过程本身一样会消耗大量时间,导致备份数据基本难利用,数据价值难挖掘。
针对海量小文件备份难题,华为OceanProtect提出四大关键技术,将疑难杂症逐个击破:
01 流式备份技术+AggregateCRC算法
目前常见的备份节奏为每周一全备,每天一增备。相比于传统的备份方式费时费力,华为OceanProtect备份方案提供两种解决技术:
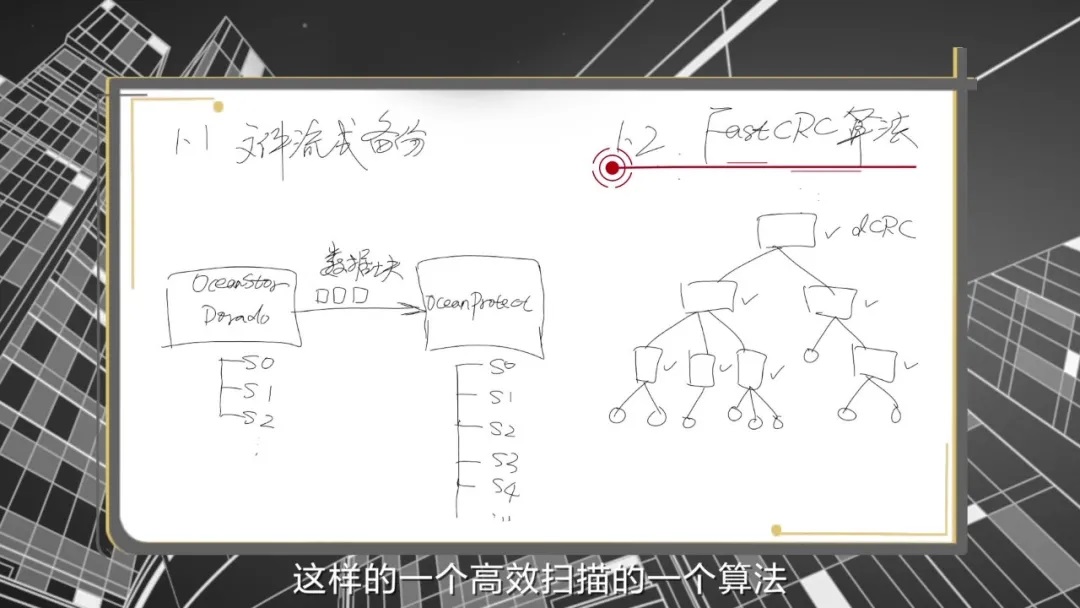
生产存储为华为OceanStor Dorado存储,则采用流式备份技术。该技术主要利用生产存储产生的定时快照,使用华为特有的snap diff算法进行快照前后对比,然后将差异数据块同步至备份存储。这种方式不需要打开和关闭文件操作,大大提升了备份效率。
生产存储为异构存储,华为OceanProtect则采用AggregateCRC高效扫描算法。它能根据生产存储每个目录的特点,生成对应的特征CRC值。该值不仅可以反映该目录的特点,还能反映下层子目录的特点。备份系统通过比对目录的历史CRC值,可以快速发现哪些子目录下的文件有变化,然后只对这些文件进行对比即可。这种高效的扫描算法,不用对所有目录的所有文件进行扫描,大大节省了扫描时间,提升备份效率。
02 全局检索技术
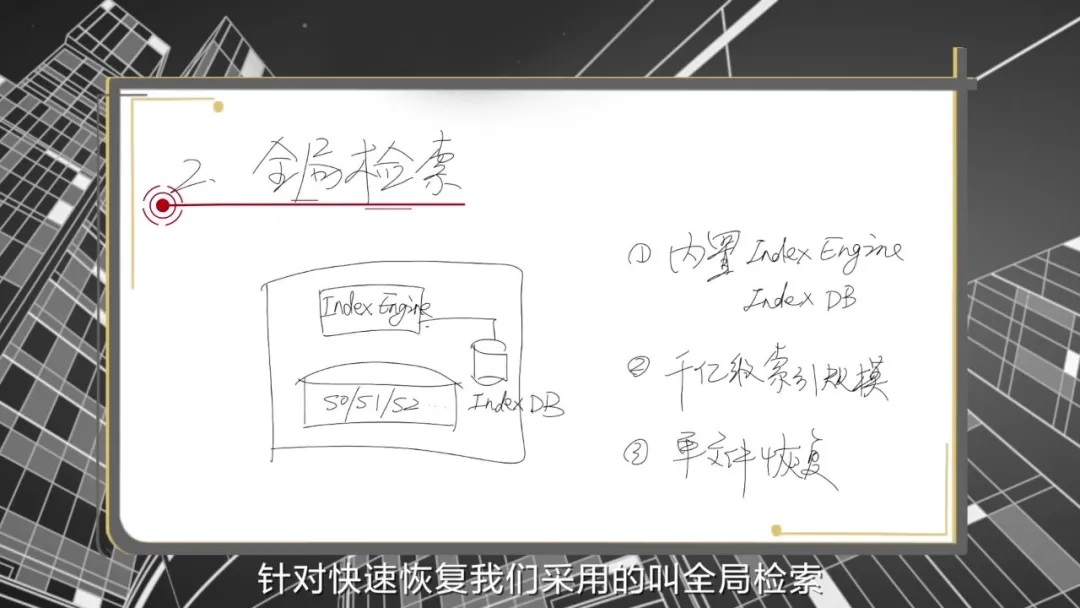
华为OceanProtect备份系统内置索引引擎。在数据进行备份的过程中,备份系统会扫描每个副本里每个文件的元数据,并存在内置的索引数据库里。
该数据库可以提供基于文件名称、时间的高速搜索接口,使得海量数据里也能“大海捞针”,找到所需的文件,并将其恢复至目标系统中。
03 防勒索病毒技术
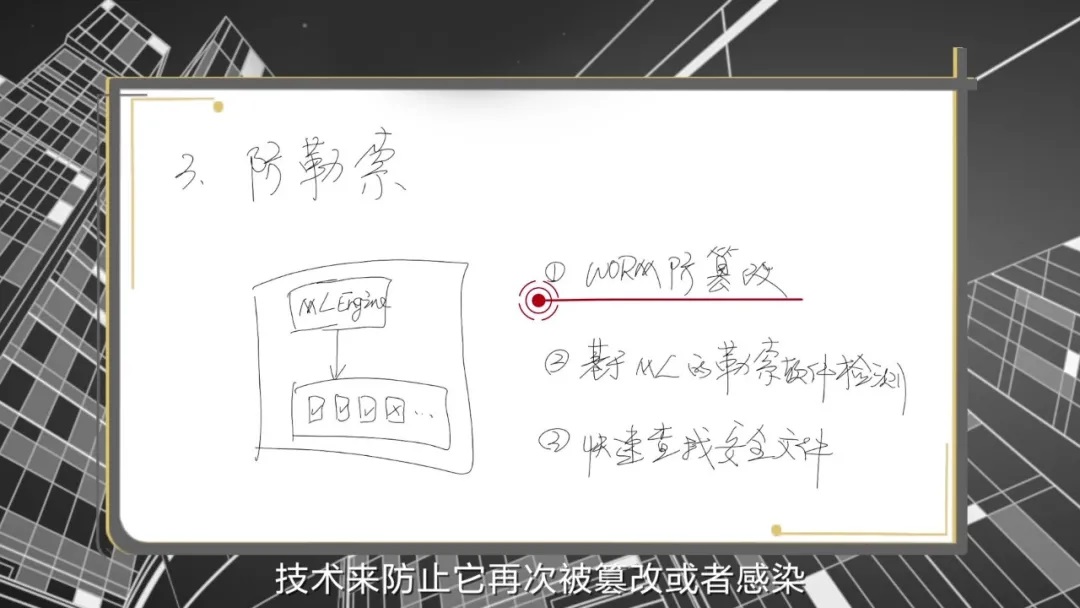
对于已经写入的备份数据,为防止勒索病毒对其进行加密,华为OceanProtect备份系统可以通过WORM(Write once, read many )一次写入,多次读取技术,使文件不可篡改,避免备份副本被勒索病毒加密。
对于备份副本中存在的已感染病毒的文件,华为OceanProtect备份系统通过基于机器学习的特征识别算法,提前识别被感染的文件副本,对其进行标记。
当用户发现被病毒攻击,需要对某个文件恢复时,通过前述的全局数据检索恢复技术,可以快速找到未被感染的安全文件副本进行恢复,从而有效破解勒索病毒危机。
04 快速恢复技术
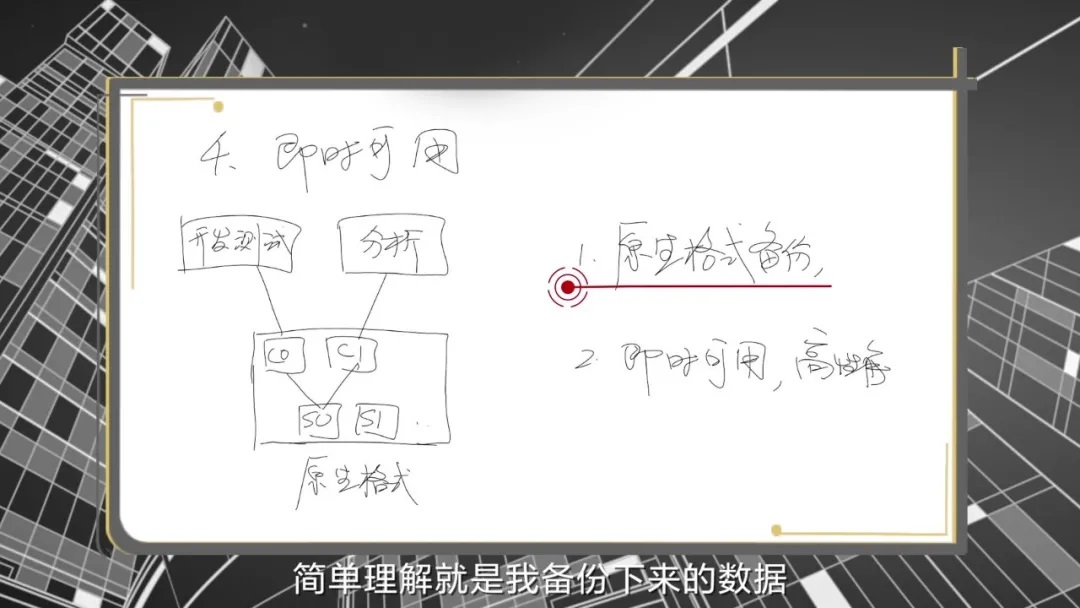
华为OceanProtect备份系统采用原生格式备份技术,将海量小文件以应用可识别的原生格式进行备份。
每个备份可以产生多个可读写的副本,这些副本可以挂载在主机上,让主机快速使用备份数据。备份副本可以挂载到开发测试环境中,供开发测试使用,省去了企业购买开发测试存储环境的费用,有效降低TCO;也可以挂载到生产主机上,用于生产存储数据发生错误时应急容灾。总之,快速恢复技术可以让备份数据不再“冷”,让备份价值得以最大程度被挖掘与发挥。

转载自:华为数据存储与机器视觉公众号
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞0作者其他文章
评论 0 · 赞 0
评论 0 · 赞 0
评论 0 · 赞 0
评论 0 · 赞 0
评论 0 · 赞 0
添加新评论0 条评论