聊一聊Redis持久化开与关
经常能碰到这样的问题:
A: Redis开持久化了吗?
B: 没有
A: 你们为什么不开?数据丢了怎么办?数据不一致怎么办?
Redis的持久化功能被夸大和误解了,这个问题我解释过无数遍了,早就想写个说明了,今天“忍不了”,和大家聊聊我的一些认知,欢迎大佬们吐槽。
一、Redis”3“种持久化方式
1. RDB
简单来说,对Redis做一个快照(利用fork)保存在磁盘上

(1) 优点:
- 结构紧凑体积小,加载速度快(相比AOF)
- 可以做定期备份:例如低峰期(顺便搞个数据分析也行)
(2) 缺点:
- 动作大、消耗大:全量操作对于磁盘、CPU、内存等均有消耗
- 无法做到"实时"备份
- 格式多变(Redis 3 4 5 6版本多次修改)
2. AOF
简单说把Redis的每条写操作记录到日志中,例如set hello world
*3
$3
set
$5
hello
$5
world
简单说,落盘策略有三种:
appendfsync always:每次事件循环都进行一次同步操作(主线程)
appendfsync everysec:每秒进行一次同步操作(另一个线程)
appendfsync no:由操作系统控制同步操作(操作系统)
(1) 优点:
- RESP标准格式:无版本兼容性问题
- 实时性更高且成本较小
(2) 缺点:
- 体积大:协议 + 明文
- 加载慢:利用fakeclient做回放
- AOF重写还是动作不小(本文不讨论AOF重写)
3. RDB-AOF混合
持久化文件全量使用RDB,增量使用AOF,保证体积、实时性、加载速度。(Redis 4提供,本文不讨论)
二、开AOF性能会差多少?(注:AOF重写也是资源消耗大头,这里不讨论)
1.测试环境:
- CPU: Intel(R) Xeon(R) Gold 6248 CPU @ 2.50GHz
- 机械磁盘
- Redis版本:4.0.14(未测试Redis 6多线程)
- 压测工具:redis-benchmark
- AOF策略:appendfsync everysec
2.压测方法:
测试Redis在”开和关“AOF情况下,在不同size(64字节、128字节、512字节)的OPS和耗时
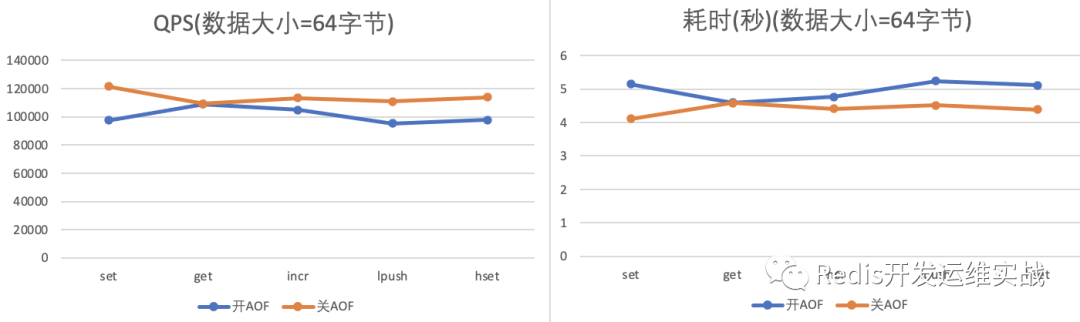
(1) d=64字节
| 命令 | ops(开AOF) | ops(关AOF) | 耗时(开AOF) | 耗时(关AOF) |
|---|---|---|---|---|
| set | 97352 | 121624 | 100.00% <= 0 milliseconds(总:5.14s) | 100.00% <= 0 milliseconds(总:4.11s) |
| get | 108979 | 109241 | 100.00% <= 0 milliseconds(总:4.59s) | 100.00% <= 0 milliseconds(总:4.58s) |
| incr | 104755 | 113301 | 100.00% <= 0 milliseconds(总:4.77s) | 100.00% <= 0 milliseconds(总:4.41s) |
| lpush | 95347 | 110889 | 100.00% <= 0 milliseconds(总:5.24s) | 100.00% <= 0 milliseconds(总:4.51s) |
| hset | 97770 | 113791 | 100.00% <= 0 milliseconds(总:5.11s) | 100.00% <= 0 milliseconds(总:4.39s) |
(2) d=128字节
| 命令 | ops(开AOF) | ops(关AOF) | 耗时(开AOF) | 耗时(关AOF) |
|---|---|---|---|---|
| set | 108908 | 114077 | 100.00% <= 1 milliseconds100.00% <= 2 milliseconds(总:4.59s) | 100.00% <= 0 milliseconds(总:4.38s) |
| get | 107388 | 111756 | 100.00% <= 1 milliseconds(总:4.66s) | 100.00% <= 0 milliseconds(总:4.47s) |
| incr | 105042 | 113430 | 100.00% <= 0 milliseconds(总:4.76s) | 100.00% <= 0 milliseconds(总:4.41s) |
| lpush | 103114 | 114025 | 100.00% <= 0 milliseconds(总:4.85s) | 100.00% <= 0 milliseconds(总:4.39s) |
| hset | 101440 | 113791 | 100.00% <= 1 milliseconds(总:4.93s) | 100.00% <= 1 milliseconds(总:4.93s) |

(3) d=512字节
| 命令 | ops(开AOF) | ops(关AOF) | 耗时(开AOF) | 耗时(关AOF) |
|---|---|---|---|---|
| set | 96581 | 108790 | 99.99% <= 1 milliseconds99.99% <= 2 milliseconds99.99% <= 3 milliseconds99.99% <= 5 milliseconds100.00% <= 6 milliseconds100.00% <= 7 milliseconds100.00% <= 8 milliseconds100.00% <= 8 milliseconds(总:5.18s) | 100.00% <= 1 milliseconds(总:4.60s) |
| get | 107898 | 105374 | 100.00% <= 0 milliseconds(总:4.63s) | 100.00% <= 0 milliseconds(总:4.74s) |
| incr | 102438 | 107991 | 100.00% <= 0 milliseconds(总:4.88s) | 100.00% <= 0 milliseconds(总:4.63s) |
| lpush | 93231 | 105064 | 99.98% <= 2 milliseconds99.98% <= 3 milliseconds99.99% <= 4 milliseconds99.99% <= 5 milliseconds99.99% <= 6 milliseconds100.00% <= 7 milliseconds100.00% <= 8 milliseconds100.00% <= 8 milliseconds(总:5.36s) | 100.00% <= 0 milliseconds(总:4.76s) |
| hset | 96955 | 108225 | 100.00% <= 6 milliseconds100.00% <= 8 milliseconds100.00% <= 9 milliseconds100.00% <= 9 milliseconds(总:5.16s) | 100.00% <= 0 milliseconds(总:4.62s) |

3. 总结说明:(注意此处没有考虑AOF重写,只能更差)
(1) 开启AOF后,Redis的写性能下降了8~25%,读性能未下降(注意此处测试为非读写混合场景)
(2) 开启AOF后,随着数据量的增加相关读写性能会下降。
(3) 开启AOF后,实际测试中发现单核CPU也会少量上涨。
三、一些问题的讨论?
1. aof刷盘策略改为always能保证不丢数据吗?
(1) 答案
会丢。Redis执行一条写入命令时,会将数据写入aof_buf,但写入aof_buf和刷盘还是存在一次事件时间差。
(2) 原理:
Redis处理命令(server.c)processCommand->call(执行命令),其中包含
void propagate(struct redisCommand cmd, int dbid, robj *argv, int argc, int flags)
{
//写入到aof_buf中
if (server.aof_state != AOF_OFF && flags & PROPAGATE_AOF)
feedAppendOnlyFile(cmd,dbid,argv,argc);
...... }
每次文件事件前的beforesleep(ae.c)
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
while (!eventLoop->stop) {
if (eventLoop->beforesleep != NULL)
eventLoop->beforesleep(eventLoop);
aeProcessEvents(eventLoop, AE_ALL_EVENTS|AE_CALL_AFTER_SLEEP);
} }
其中beforesleep包含了aof_buf落盘(server.c)
void beforeSleep(struct aeEventLoop *eventLoop) { ......
//aof落盘
flushAppendOnlyFile(0);
...... }
flushAppendOnlyFile利用操作系统的write和fsync(加上aof的三种策略)完成落盘:

2.Redis是什么一致性?
最终一致性。客户端写主后,不等从写完。(为什么这样?Redis设计目标是什么?快!)
3.master节点故障后Redis怎么恢复?

(1) 关闭AOF:B节点晋升成主节点,对外提供服务。A节点恢复后变为slave,依赖全量复制获取全部数据
(2) 开启AOF:同上...(只不过A节点全量复制后做一次AOF重写)
所以看起来此模式下,对于故障恢复持久化没什么用!
4.我就不想丢理论上最少的数据,怎么办?
开启always,不用主从切换,等待A节点恢复,重新加载AOF在提供服务,老哥这个现实吗???
五、最佳实践?
1.RDB最佳
(1) 自动save:关、关、关(性能杀手)
(2) save命令:同步,忘记它(除非你一点内存没有了,还需要RDB)
(3) bgsave命令:备份可以用,请关注fork时间(info stats可查)
(4) 关闭掉:做不到,因为全量复制默认会用。
2.AOF最佳
(1) always不要用(主线程执行、以及IO影响)
(2) everysec、no按需使用,如果仅仅想不丢数据,AOF做不到。
(3) 除非怕主从都挂了,可以考虑。
不要忘记AOF臭名昭著的:
Asynchronous AOF fsync is taking too long (disk is busy). Writing the AOF buffer without waiting for fsync to complete, this may slow down Redis
3.单机多实例:你玩得起吗?
以一个80 core,500G内存的机器为例子,出于成本考虑至少要部署80~90个* memory(5G)的实例。在此场景下CPU、内存、网络的开销基本还能控制,但如果开了AOF,用普通的磁盘,行不行?
会有:很多公司会为了做持久化,预留“一半”内存,所以就是40~45个
还有:用SSD解决AOF的问题。
4. "旁门左道"用法
(1) RDB:
定期备份(例如低峰期)、数据分析(分析出bigkey、hotkey、idlekey等)(阿里云的做法)
(2) AOF
原生AOF语义太弱,如果想做类似binlog功能可以对Redis内核进行修改,多机房同步会用上。
六、总结
Redis的持久化功能是一个重要功能,但如果想指望它实现“不丢数据”、“一致性”,那可能带来的就是:低性能、高成本。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞1作者其他文章
评论 1 · 赞 8
评论 0 · 赞 4
评论 0 · 赞 0
评论 0 · 赞 3
评论 0 · 赞 4
添加新评论0 条评论