黄东旭:可插拔性 × 调度能力 × 云上几乎无限的资源 = ?丨PingCAP DevCon 2021

这次我分享的主题和 2019 年还是一样的——《The Future of Database》,如果你是 PingCAP 的老朋友,参加过之前几次 DevCon 就会知道,这是我的一个保留节目。如果要说我哪里有一些与众不同的气质,我觉得除了发型之外,还有一个是对技术的信仰和执著。这个保留节目我们还是聊聊技术。
过去两年,TiDB 在技术上发生的最大变化是什么?可能有很多同学觉得性能变得越来越好,功能变得越来越多,生态功能越来越大,其实不是。

从一个程序员角度看,在过去两年中 TiDB 其实完成了一个很重要的转变,那就是开发模式的转变。上图中左边是一个工程师对着屏幕在写代码,这是我们早年在第一个办公室里面开始写 TiDB 第一行代码的状态。旁边放了一瓶可乐和披萨,想到什么写什么。现在 TiDB 整个研发流程越来越像右边这张图,一个小工厂流水线化做月饼。虽然现在离中秋节还稍微有点距离,还是很可爱。

TiDB 这两年最重要的一件事情,是研发流程以一个全新的发版模型去做软件工程,我们称它为“火车发版”模型。这个模型的特点,是我们会把很多大的 feature 以小的迭代进行逐步增量发布,意味着更易于管理发布周期。
很多人可能会说“关我什么事?”,这件事情非常重要的意义在于,TiDB 从一个纯粹社区的开源软件开始慢慢变成面向企业级的数据库产品。说得再接地气一点,用户真实场景里面需要的 feature 最快两个月就能合并到 TiDB 的主干,并交付给用户。

两年前,我的演讲题目也是《The Future of Database》,上图是两年前演讲的截图。向量化,当时这是一个挑战,现在已经完成了;TiFlash ,当时只是在草图上设计的一个架构,在 5.0 引入 MPP 后让它变成了一个真正的 Real-time HTAP 的数据库;IPC /异步提交,5.0 的性能和稳定性都得到了稳步提升;TiDB DBaaS,现在 TiDB Cloud 已经是服务千家万户,服务全球各个地方的真实产品;本地事务异地多活,两年时间也做完了。
两年前的五大构想,今天都变成了现实。
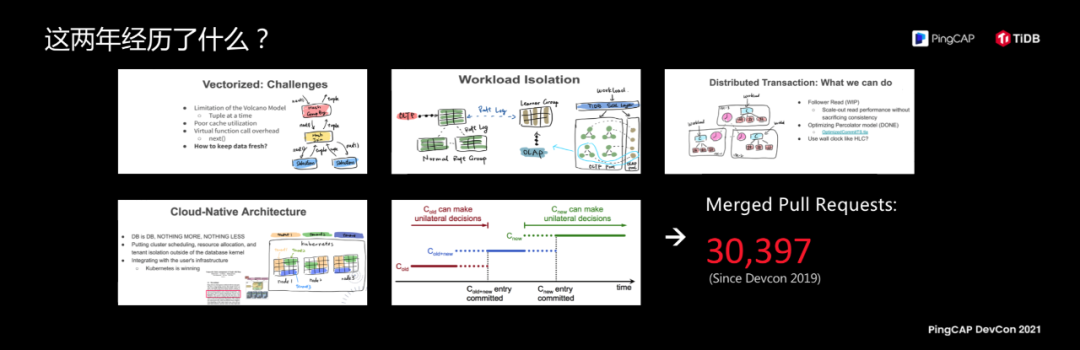
从 2019 年到现在的两年时间中,在这些 feature 背后我们经历了什么?是两年时间超过三万个 PR 的合并。人总是有成长的,两年前的我和现在的我区别是什么?发型没有变,T 恤也是一样的,变化的是 TiDB 合并了三万多个 PR。回头看我两年前的 PPT,我在思考一个问题,TiDB 的竞争力或核心优势是什么?很多数据库都说自己的核心优势是性能好、功能多。那么,TiDB 的优势是什么?

两年前我的 PPT 里面有一页叫 Everything is Pluggable,我觉得特别有味道,TiDB的真正优势在于技术开放性。架构开放就意味着能够产生更多的连接,更多连接意味着更快的迭代速度、更多的可能性。
为什么 TiDB 的系统核心优势是开放性?大家可以花几秒钟时间去思考一下,这一个思考的角度,让我这两年慢慢开始变成一个哲学家。这个角度是:单机数据库和分布式数据库最本质的区别是什么?做分布式数据库的工程师的这些痛苦和幸福的根源在哪里?我们真正的敌人是什么?我们要解决什么样的问题?我们怎么解决这些问题?

作为一个系统的设计者,在思考系统的时候,我觉得我们真正的敌人是复杂性。TiDB 这么一个几百万行代码的软件,跑在 3 台机器上,跑在 30 台、300 台、3 万台的服务器上还是这一套代码。大家想象一下, 3 台机器的复杂性和 3 万台机器的复杂性是一样的吗?
我们生活中见过最复杂的系统是什么?就是活生生的生命,生命是最复杂的系统。包括每个人每天在和这个世界发生各种各样的交互,我们没有办法预料明天。我们去看生命这么一个复杂的系统,我们往里看人的生命最开始就是一个受精卵,细胞不停分裂,很简单。再往下看 DNA,排列组合,所以我觉得从生命和自身的角度看,才能真正找到解决对抗复杂性的办法,这就简单了。

这里有肖邦老师的一句话,真正难的事情是把系统做简单,简单意味着美。TiDB 在这方面的设计理念和很多的常规做法还是有点不一样的,刚才我提到一句话,我们幸福和痛苦的根源在哪?刚才也提到我们是一个不一样的公司,技术上往深去思考我们到底和其他的数据库区别是什么?最根源的区别我觉得在于核心的设计理念,当理解了 TiDB 核心设计理念再去看 TiDB 的技术架构设计,有很多具体技术问题大家自然就能够想通了,也能想到为什么我们会这么做。
左边这是一个惯常思维,1) 我要做一个数据库,2) 做一个分布式数据库会怎么做,3) 我试着把这些数据库上面的表给做分片,分区表,不同的分区放在不同的服务器上就是分布式了。
我们过去从来没有做过数据库,但是我们有一个疯狂的想法,这个想法就是我们要做一个分布式数据库,我们开始是去定义数据最小的流转单元,像刚才看到的那张动图里面的细胞一样,我们去定义这些细胞的分裂、合并、移动,复制,繁殖。把这些规则用最极简,正交,自洽的规则赋予这些细胞生命,让这些细胞长成一个数据库,是 TiDB 最核心的理念。单机数据库和分布式数据库本质区别在什么,分布式数据库在一台台机器上是可以生长的。
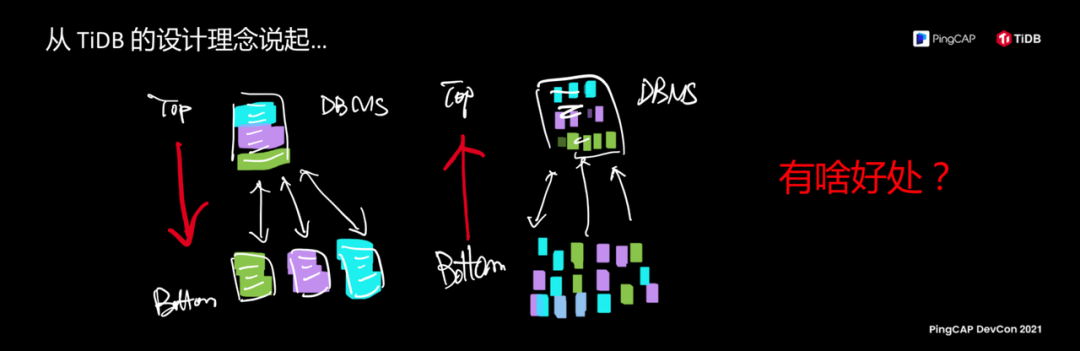
左边这张图解释了一下,常规是这样去设计,几乎所有的数据库都是从上往下设计的,TiDB 是一个 bottom-up 的设计,先定义底层细胞,在让它长成一个数据库的样子。

下一个问题,让大家思考几秒钟,给大家铺垫一下,左边的名词,两地三中心,异地多活,跨地域数据分布能力,本地事务,动态热点打散,实时在线捞数,只读表。这些功能的共同点是什么?
问:如果我要去实现这些功能该怎么去实现?这些功能背后的共同点是什么?有没有一个关键的点,解决了这个点所有能力都能马上拥有,有没有这样的东西?

答案揭晓,刚才所有这些技术的名词和所有的这些刚才提到的用户看到的东西,背后都依赖一个能力就是“调度”,刚才我提到了那个问题,一个单机数据库,一个单机系统和分布式系统最本质的区别到底是什么?我给出答案是可调度能力,这是区别于单机系统最主要的能力。可调度能力是开放的基础,开放架构不能让这个数据库以不变应万变,这个万变就像把自己重塑成更适合用户的场景的数据库,如果没有这样的能力分布式系统就变得没有意义,就不能说自己是一个开放的系统。
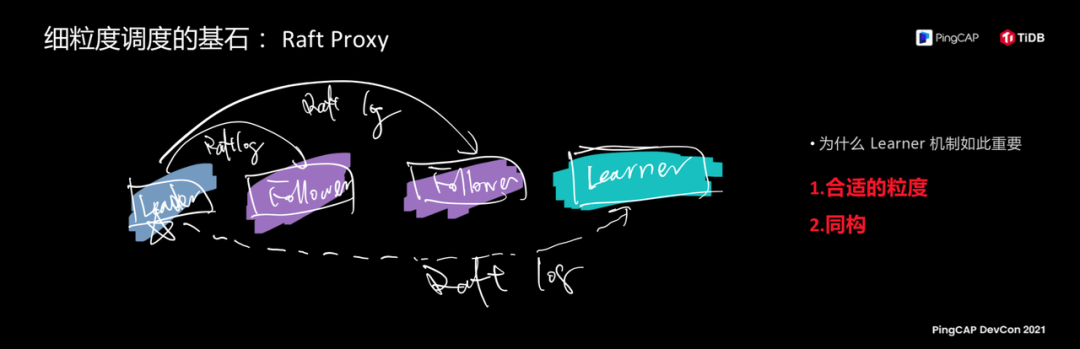
所以,这个其实是 TiDB 在技术架构上最核心最闪光的价值。今天聊技术,我们在可调度性上做了哪些事情,这是一盘大棋,不是一个 feature,这是一个理念,我们看这个理念过去现在和未来会长成什么样子。熟悉 Raft Proxy 技术的朋友,底层架构上,刚才我提到的细胞是基于 Raft 复制协议的复制组,这其实是我们整个调度最细粒度的单元,我们在这些一个个数据复制组上赋予它自我繁殖、分裂、合并、移动的能力。右边这张图有一个 Learner,用户会心一笑,选择这样的单元作为细胞是很合适的,每一个细胞的行为都是一样的,它是同构的。
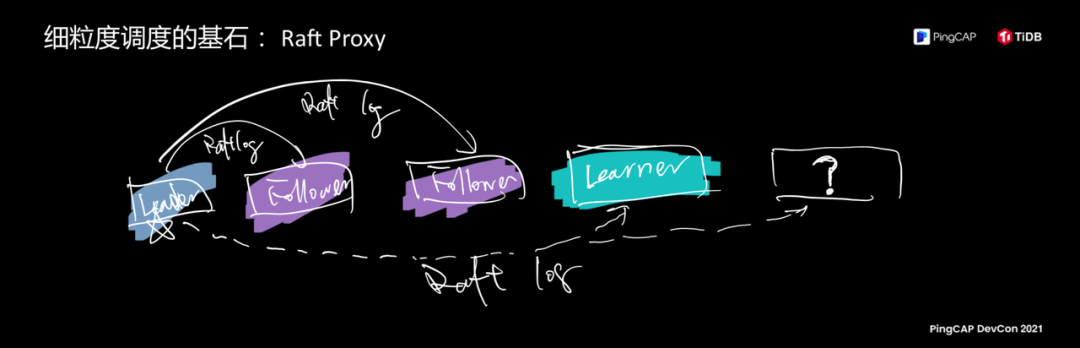
我们再放飞一下,原来 Learner 这个技术的第一次引用我们想给它找一个应用场景,这个应用场景就是 TiFlash,本来只是我们脑中一个小实验,我能不能在这个细胞上让它多复制一小块,让它干点别的事情? 当时,我们觉得 AP 能力不太强,需要底层数据存储列存的数据结构,我们把这个架构在副本上让它支持列存,于是 TiDB 就有了 HTAP 的能力,在这个基础上不到两年时间一个小团队把整个 Real-Time HTAP 这个系统就做出来了。
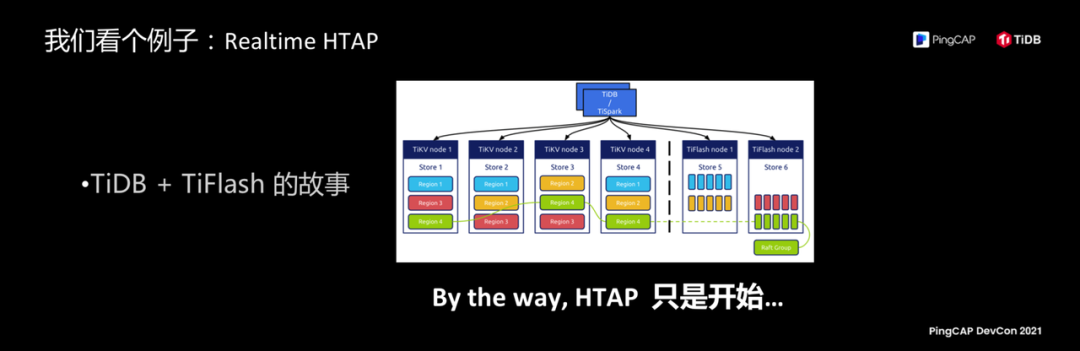
为什么这么快做出来?TiFlash 是可调度性的理念绝佳的一个例子,而且我脑子里还有很多很奇怪的想法,Real-Time HTAP,TiFlash 只是开始。
最细粒度的调度能力,可调度上的调度能力,我们再进一步往上看,有一些朋友熟悉 Foreign Data Wrapper(FDW),现在 TiDB 还不支持 Foreign Data Wrapper。这个功能比较好理解的一个说法,让 TiDB 把其他的数据源当作它内部一张表来进行查询,比如说当这个功能支持了以后,我可以把 Redis 作为 TiDB 中的一张外表,把 MySQL 数据作为一张外表,可以一起关联分析 HBase 这些数据。
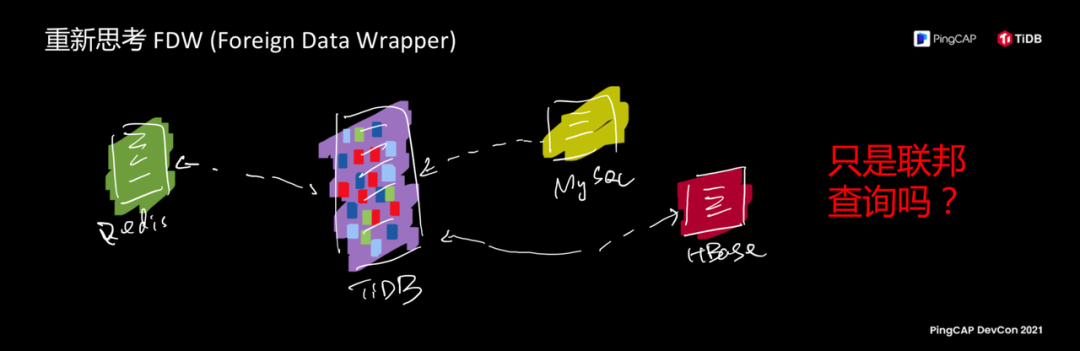
但是,FDW 意义仅仅停留在"联邦查询"吗?我在思考这个 feature 是为什么?因为我在看这个 feature 的时候联想到关于数据库的本质,数据库这种软件的本质是什么?当你抛开所有的数据结构,存储的能力,抛开所有功能,数据库里面到底存了什么东西?数据库把所有刚才我说的概念都剥离开,它只干两件事情,一是存储真实的数据,另外一部分是叫做索引,数据库无非就是数据和索引,怎么在这两种概念中辗转腾挪。按照刚才的思路把整个数据库当成数据和索引的容器,索引这个概念其实就是一种特殊映射的表关系,索引也是一张表,你要索引的内容对应到数据上的映射关系。

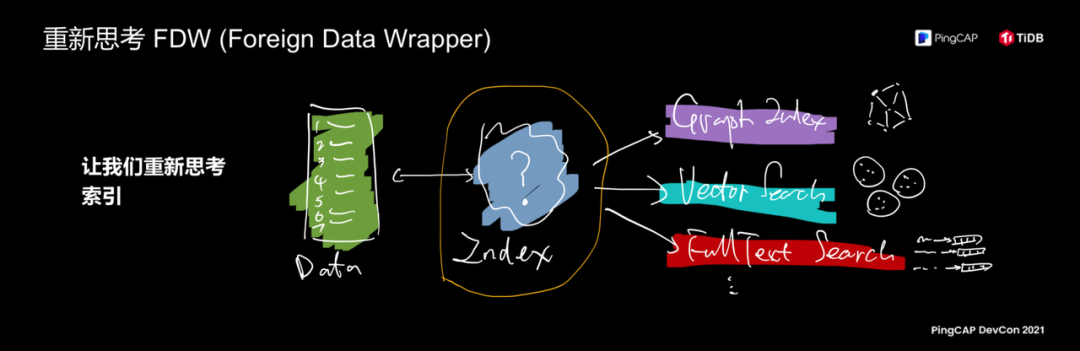
那我们就跟着这个思路重新思考 FDW。右边是我的灵魂画风,有点难以看懂,今天整个数据库行业的趋势,其中一个趋势是各种各样的细分领域的数据库诞生,图数据库,向量搜索数据库,全文检索数据库,TiDB 能不能把这些数据库的能力变成它的索引能力?比如说我有一张表这里面存储着用户的关系,用户的信息,大家知道在一个关系上的搜索、查询用图的模型更好,如果是用传统的比如说我用索引的数据结构查询得很慢,用图模型可以极大加速这个性能。如果从这个角度去思考,TiDB 的索引能够接入其他的这些数据库,让其他的数据库作为 TiDB 的索引,同时以一个统一的接口给用户提供服务,是不是打开了新世纪大门的感觉?
今天大会的主题是开放×连接×预见。
我觉得特别有意思就是这个“×”号,我也不知道这些东西加进去以后能对 TiDB 的生态带来多大的可能性,任何人试图去预估它的价值都是傲慢的,我们能做的就是把这些基础给开发者打好,这是索引的部分。
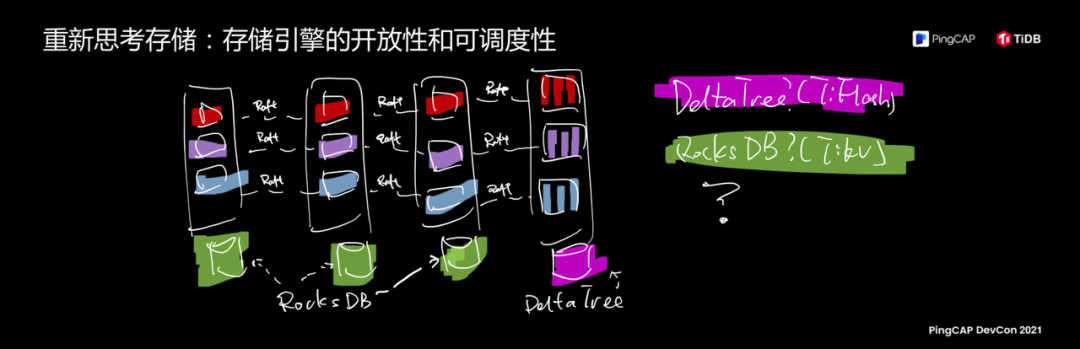
我们再把目光往下看,数据库的本质一个是数据,一个是索引,现在我们看数据,关于数据大家第一个联想就是存储引擎,数据的存储是最关键的一个话题。熟悉 TiDB 整体系统架构的同学肯定对左边这张灵魂画风的图不会陌生,刚才我提到 TiDB 在内部其实是把数据已经拆分成了无数个小小的细胞,每个细胞是一个复制组,分裂,合并,移动。但是在物理层面上存储我们现在是使用基于 Database 的 Real-time HTAP。TiKV 底层用的是 Rocks DB ,TiFlash 用的存储引擎我们命名叫 Delta tree,两种引擎。
还能不能有更多?
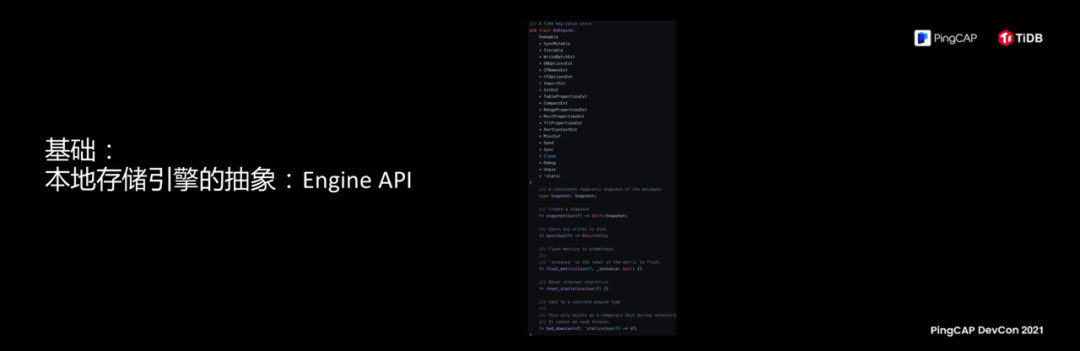
在存储上去体现开放性和可调度性的能力,有一个基础的前提就是对存储引擎进行抽象,熟悉 TiDB 的代码的同学如果去看它的代码仓库,发现有一个很有意思的文件夹叫Engine API,这件事情特别有意思,我直接把代码放上了,意思就是我们试图去对存储本身的能力进行抽象,这个抽象是一个基础。

这个抽象的意义在哪?我们为什么做这件事情?我对未来的一个判断,为什么一般来说数据库技术负责人总会谈到性能、功能,为什么今天我们来讨论哲学?因为我觉得从更长的一个维度来看,当你的软件在保持高速迭代能力的时候,它是一个动态的进化过程,进化的终局是什么?
先来看性能,在 TiDB 发展过程中,每一个版本都保持着 100% 性能提升的速度往前走,可以保持到 6.0,7.0 每次都是百分之百增长,未来优化是无止境的。我个人认为,不会说发明了一种新的硬件和算法解决了全世界所有应用场景的性能问题,粒度会变得越来越细,有一些优化用于某些具体场景,比如用来存用户的关联和关系就是图的模型最好。但是有一点,我觉得用户不用去关心他在使用什么样的数据库的结构,哪一块数据在使用哪一种数据结构,这些都不重要。
右边的图透露了 TiDB 在做的巨大的一个事情,信息量非常大,我们做的事情,刚才 Engine API 的抽象让我们能做一件事情,熟悉 TiDB 的朋友都知道,我们在一台存储节点上是共享一个存储引擎,现在我们慢慢对每一块数据分片,每一个细胞让它能够自己拥有自己的存储引擎,这个事情在我们实验室里已经做完了,效果非常棒,当时都震惊了。
下一步发展,当我把数据的细胞存储拆分了以后,下一步到底是不是 Delta tree 这件事情不重要了,比如我有一部分数据在业务场景里面一年只访问一次,但是不能丢,我又不希望用 SSD 来存,我能不能用云上 S3 的存储,甚至在一张表里面的一个数据特别热,对一致性要求没有那么高,是不是能在内存中对这一块数据的形态做一个变换。而且更有意思的是,这些所有的变换都是动态的,对业务都是透明的,回想刚才我说的可调度性和细胞这几个概念。
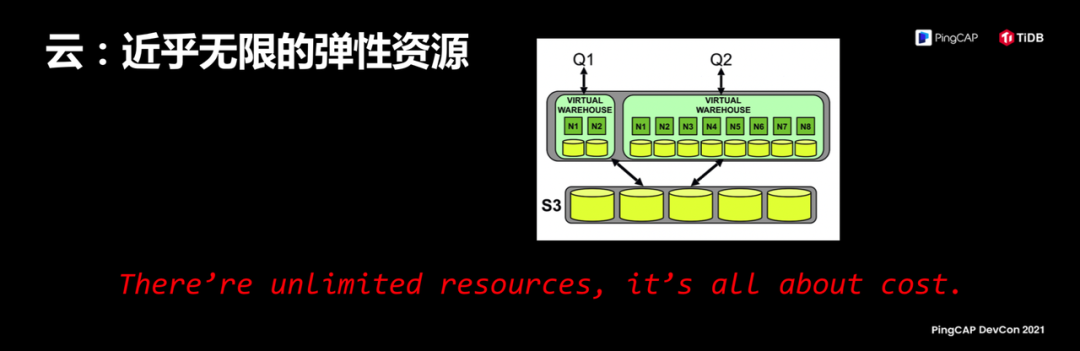
我刚才说所有这些技术都是为了一件事情,都需要构建在一个基础上,刚才我说了分布式系统的终局,分布式系统可调度是它的核心优势,这个基础我相信各位大概能够猜出是什么,我需要有一个近乎无限的弹性资源池,就是云。关于云的重要性我觉得现在整个行业还在低估,现在天天说云,但是我觉得云其实是构建未来新一代软件的最重要的一个基石。
我觉得对于云有一个很好的说法,我作为一个软件工程师看待云就像什么?我用了无限的资源,就像一堆积木我怎么去拼,手上有多少钱能拼成什么样子。右边这张图是 Flink 的架构,Flink 是一个很有意思的产品,它上市有各种各样的新闻,但是我最早注意到它是在 2016 年,它发表第一篇论文的时候,我看那篇论文,是我这几年最喜欢的论文之一,那篇论文更大意义在于它开创了一种新的软件设计的思路,开创了新的物种,基于云的服务去构建的基础软件,它是第一个,但绝对不是最后一个,TiDB 在这个领域是走在最前面的软件之一。

TiDB 的核心思想,开放性体现在可插拔,存储和计算可插拔、可调度,借用今天主题“ × ”号,乘以调度能力,可插拔以后还能调度,细粒度,粗粒度调度,乘以云上几乎无限的资源它又等于什么。
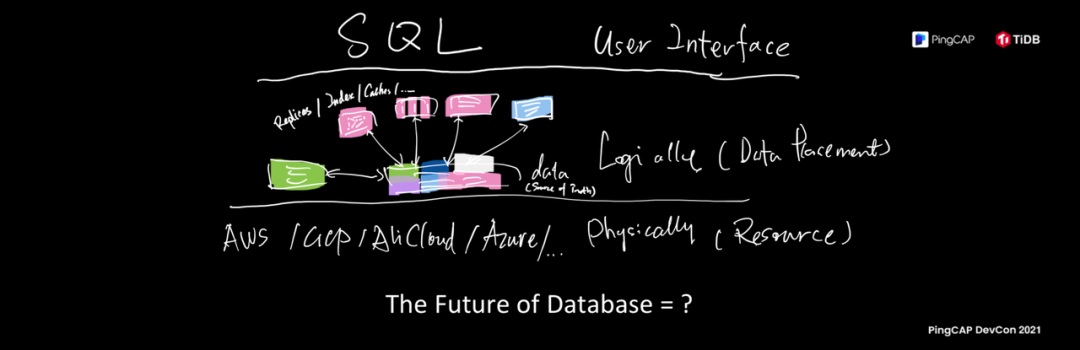
回顾一下我今天的题目,The Future Database,终极的 Future 是什么,这张图是我理想中的数据库的样子:底层各种各样的资源池,各种各样的云,公有云、私有云,混合云;上面中间逻辑这一层是数据平台,用户不同的业务不同数据,对数据库有不同要求,数据库会根据用户的需要自动去重塑自己;在不同的颗粒度上,从副本分布我们去做全球跨数据中心部署,这种能力对于 TiDB 来说工程代价并不是太高,刚我说调度能力,索引,我们通过 FDW 未来可以引入各种各样多种形态的索引。开了一个小小脑洞,图的数据库作为 TiDB 的索引,根据用户需求变换自己的形态。

所以,大胆预测一下,刚才那个公式“可插拔性 × 调度能力 × 云上几乎无限的资源 = ?”,数据库作为一个独立的软件形态我认为会被颠覆,同时意味着整个数据库的“数据服务平台化”会崛起,我们下一代很多在场的各位为人父母,下一代的小朋友可能到他们写程序的年纪,可能不知道什么是 CPU,什么是内存,什么是磁盘,什么是操作系统,可能看到的就是一个个云服务,比如要用数据库的时候好象有一个 TiDB 的东西,我把信用卡绑上去之后就可以直接用一个 SQL 的接口里操作就完了,不需要知道什么叫索引, 什么叫 Delta tree。
我们回头看一下今天我们大会三个关键字,开放,连接,预见,只有开放的架构才能有更多连接,更多的连接才能让我们有更好未来,这是今天我关于 TiDB 的技术和设计理念的分享。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞0作者其他文章
评论 0 · 赞 0
评论 0 · 赞 0
评论 0 · 赞 0
评论 0 · 赞 0
评论 0 · 赞 1
添加新评论0 条评论