记一次Impala真实性能调优
开展本次性能调优原因是发现我们目前有些OLAP的分析查询,数据流是从Hive-->oracle回环。为什么会有这种回环链路依赖,大家都说是Impala有不少查询很不稳定,性能低,可能是资源不足造成。所以又把Hive的数据再反向导回oracle。
真相究竟如何?我们来找找。
借用cloudera Manager,可以看到我们Impala上确实存在很多很慢的查询,大家都一直在默默接受着。打开每个慢查询的profile文件,仔细分析下执行计划,发现绝大多数慢SQL都存在一个问题,那就是The following tables are missing relevant table and/or columnstatistics.
首先,我们得知道Impala的查询计划器是可以利用表和分区的各项统计信息进行优化。
The Impalaquery planner can make use of statistics about entire tables and partitions.This information includes physical characteristics such as the number of rows,number of data files, the total size of the data files, and the file format.For partitioned tables, the numbers are calculated per partition, and as totalsfor the whole table. This metadata is stored in the metastore database, and canbe updated by either Impala or Hive. If a number is not available, the value -1is used as a placeholder. Some numbers, such as number and total sizes of datafiles, are always kept up to date because they can be calculated cheaply, aspart of gathering HDFS block metadata.
我们来看一张库mkt的表A(图1-1),默认统计信息是-1,每字段平均长度等也全为-1。我们对统计信息进行计算后发现,每个字段(哪怕同样String类型)平均大小差距也是巨大的。
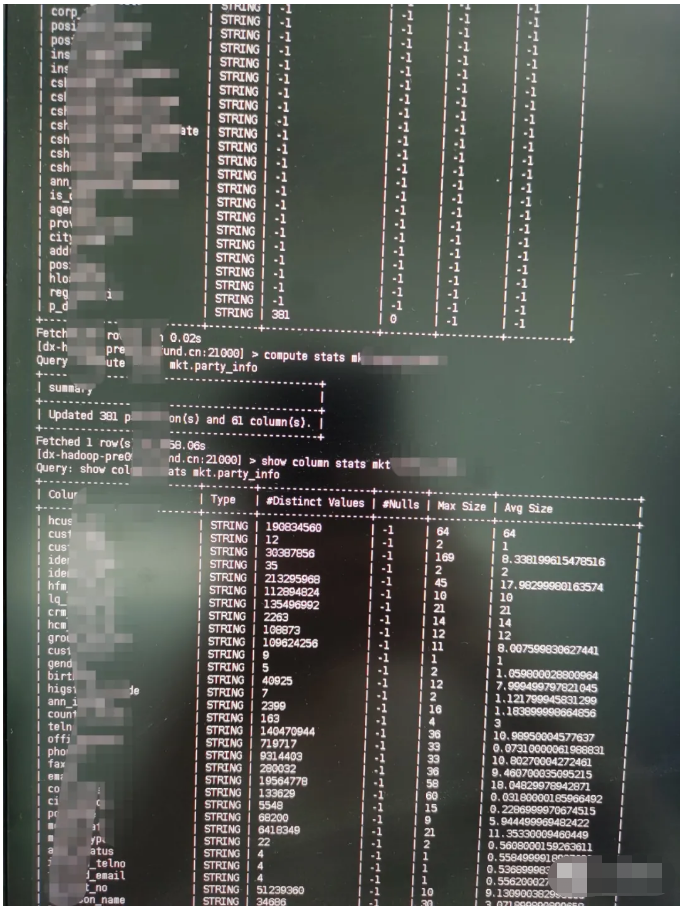
图1-1
那么区区的统计信息,对Impala的执行计划影响有多大呢? 让我们来上实际的生产案例。(行业敏感性,不陈述具体业务,只抽象,望谅解)
典型案例一:
SELECT t4.conf_date as conf_date ,t1.cust_id ascust_id , sum(nvl(t4.pres_share,0)) AS pres_share FROM (SELECT t1.cust_id FROM ods.imp_cust_id_fxqt1 WHERE t1.dtype in ('同法人') GROUP BY t1.cust_id)t1 INNER JOIN mkt.v_party_infot2 ON t1.cust_id =t2.hfm_cust_id INNER JOIN mkt.v_acct_infot3 ON t2.hcust_id=t3.hcust_id INNER JOIN (SELECT * FROM mkt.ast_posi t4 WHEREt4.p_dt=from_unixtime(unix_timestamp('2021-05-22','yyyy-MM-dd'),'yyyyMMdd') and t4.conf_date=from_unixtime(unix_timestamp('2021-05-22' ,'yyyy-MM-dd' ),'yyyyMMdd') ) t4 ON t3.hacct_id=t4.hacct_id GROUP BY t4.conf_date ,t1.cust_id执行情况:
Fetched 22 row(s) in 224.58s
内存占用峰值:64GB,Cpu线程总和:28.6min 从HDFS读取字节:42GB
优化后执行情况:
Fetched 22 row(s) in 9.31s
内存占用峰值:1.8GB,Cpu线程总和:3min 从HDFS读取字节:42GB

典型案例二:
select T7828.NGDP客户IDas F7829,T7828.客户ID as F7830,T7828.证件号码 as F7831,T7828.客户名称 as F7832,T7828.确认日期 as F7833,T7828.渠道编码 as F7834,T7828.渠道名称 as F7835,T7828.分中心代码 as F7836,T7828.分中心名称 as F7837,T7828.网点代码 as F7838,T7828.网点名称 as F7839,T7828.基金账户 as F7840,T7828.交易账号 as F7841,T7828.交易类型代码 as F7842,T7828.交易类型 as F7843,T7828.确认份额 as F7844,T7828.确认金额 as F7845,T7828.数据来源 as F7846 from (SELECT t1.hcust_id NGDP客户ID, t1.hfm_cust_id AS 客户ID, t1.identi_no as 证件号码 ,t1.cust_cname as 客户名称, t3.conf_dateAS 确认日期,t4.ta_agency_id as 渠道编码,t4.ta_agency_nameas 渠道名称,t4.js_center_id as 分中心代码, t4.js_center_name as 分中心名称, t4.js_net_id as 网点代码, t4.js_center_name as 网点名称, t3.ta_acct as 基金账户, t3.trade_acct as 交易账号, t3.htran_type as 交易类型代码,t5.c_businnameas 交易类型 , t3.conf_share as 确认份额,t3.conf_amt as 确认金额, CASE WHENt3.p_tatype='T' THEN 'HSTA' WHENt3.p_tatype='R' THEN 'RTA' WHENt3.p_tatype='E' THEN 'ETFTA' WHENt3.p_tatype='L' THEN 'LOFTA' WHENt3.p_tatype='LQ' THEN 'CTA' END AS 数据来源 FROM (SELECT * FROM mkt.v_party_info t1 WHERE t1.identi_no in ( '152601199010141611') ) t1 INNER JOIN mkt.v_acct_info t2 ON t1.hcust_id=t2.hcust_id INNER JOIN (SELECT * FROM mkt.tran_conf t3 WHERE t3.p_dt>=from_unixtime(unix_timestamp('2021-05-13' ,'yyyy-MM-dd'),'yyyyMMdd') AND t3.p_dt<=from_unixtime(unix_timestamp('2021-05-25','yyyy-MM-dd'),'yyyyMMdd') ) t3 ONt2.hacct_id=t3.hacct_id LEFT JOIN mkt.v_chnl_reg_infot4 ON t4.hagency_id=t3.hagency_id LEFT JOIN dim.v_tran_typet5 ON t5.htran_type=t3.htran_type) T7828 order by T7828.NGDP客户ID limit 240001 OFFset 0 执行情况为:
Fetched2 row(s) in 252.84s;
内存占用峰值:643.1GB; Cpu线程总和: 54.7min; 从HDFS读取字节: 54.2 GB
如图2-1

图2-1
优化后执行情况:
Fetched2 row(s) in 23.56s
内存占用峰值:3.3GB;Cpu线程总和: 6.2min;从HDFS读取字节: 57.1GB
我们再看下clouderea的慢日志图2-2:

图2-2
效果比对如下:

到这里,可能会有童鞋有疑问了,性能都是几十倍几十倍的提升,是不是有点夸张了?
哈,怀疑有一定的道理,查询嘛,会不会受文件系统缓存影响才提升如此巨大?
好。我们妄自菲薄,先执行优化后的查询,再回退优化,执行常规查询。把文件缓存交给优化前的查询。让我们再来看看结论如何。
先优化然后查询:
Compute stats mkt.party_info;等5张表(如为视图,需要把视图中的表优化)
或采用compute incremental stats mkt.ast_posipartition(p_dt>’20210501’);进行增量优化
优化后查询情况:
Fetched2 row(s) in 92.32s
内存占用峰值:14.1GB, CPU线程总和: 14.8min,从HDFS读取字节: 54.2GB
优化回退,通过
Drop stats mkt.party_info;
Drop stats mkt.acct_info;等进行统计信息复原后
回退后查询情况:
Fetched2 row(s) in 238.4s
内存占用峰值642.9GB,CPU线程总和: 53.1min,从HDFS读取字节: 54.2GB
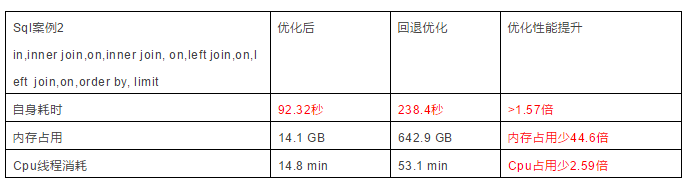
我们来直观看下主动自我挑战的顺序操作过程指标图:

图2-3
担心并非多余,哈哈。本组类型sql在Impala调优后,真实性能提升会介于 1.57-9.7倍 之间(还做了很多组的SQL,也存在一些提升只有百分之几十甚至没有什么提升的情况,就不一一列举了)。Impala优化后,这些SQL在内存方面的节约无疑是巨大的, 这势必会对整个Impala集群QPS有极大提升 (让出的内存可以让其他SQL得到充分资源执行)。当然,我们还可以通过每次查询都清空系统page cache(linux2.4.10后buffer cache已叫buffer page,都存在page cache中了)来测量出更精准的数据。
本轮调优过后,我们将采用ETL后增量计算刷分区统计信息的办法来工程化落地。同时,也会开发程序,结合将来建成的日志云对Impala的慢日志进行多维统计分析,进而提供处理决策。
尽管接下来我们还会建设统一的资源管控平台。但很多时候,慢,真不一定就是资源问题,我们都需要多分析思考,持续改进。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞4作者其他文章
评论 2 · 赞 14
评论 10 · 赞 24
评论 0 · 赞 4
评论 0 · 赞 1
评论 0 · 赞 6
添加新评论0 条评论