
基于Rook+Ceph的云原生存储架构剖析
1. 前言
Rook 是一款云原生存储编排服务工具,由云原生计算基金会( CNCF )孵化,且与 2020 年 10 月正式进入毕业阶段。 Rook 并不直接提供数据存储方案,而是集成了各种存储解决方案,并提供一种自管理、自扩容、自修复的云原生存储服务。社区官方资料显示, Rook 1.5 是目前最新的稳定版本,其中只有 Rook +Ceph 存储集成方案处于 stable 状态,版本升级较平滑。
Ceph 是一种广泛使用的开源分布式存储方案,通过 Rook 则可以大大简化 Ceph 在 Kubernetes 集群中的部署和维护工作。基于 Rook+Ceph 的存储方案,能为云原生环境提供文件、块及对象存储服务。
本文将结合个人部署实践和学习心得 , 重点介绍 Rook+Ceph 存储方案的技术架构,剖析 Rook+Ceph 各模块的功能及其运作流程,希望给同行在云原生存储的学习和使用过程中提供一些借鉴。
2. 总体架构
2.1 Ceph 架构
如前文所述, Rook 并不直接提供存储方案,而是用于集成其他存储方案到云原生环境中。了解 Rook+Ceph 的总体架构之前,有必要先了解下 Ceph 存储架构:
如上图所示, Ceph 存储集群组件可大致分为三层组件:
数据存储层 : OSD 直接管理底层存储设备, OSD 之间会互相检测心跳,并各自向管理层汇报自身状态;
应用接口层 :包括 MDS 与 RGW 组件,应用层建立在 OSD 层之上,分别提供文件系统元数据服务和对象存储访问接口;
管理层 :包括 Mon 与 MGR 组件, Mon 组件用于维护集群组件的映射与状态信息, MGR 是新增组件,分担了部分 Mon 组件的功能,对外提供了管理、监控等功能和接口。
2.2 Rook+Ceph 架构
2.2.1 方案价值
Ceph 是一个被广泛使用的可扩展、高性能的分布式存储系统,那么 Rook+Ceph 架构方案的价值体现在什么地方?我个人认为主要是三点价值:一是存储的内置集成会使得 k8s 与 Ceph 深度绑定,且内置插件各种限制,也不利于版本更新与迁移;二是在 k8s 集群上,可以便捷地容器化部署 Ceph 集群;三是使用 Rook 来管理使用 Ceph ,提供自我管理、自我扩展和自我修复的云原生存储服务。
2.2.2 层次结构

结合上图,自底向上的层次来了解 Rook+Ceph 的组件架构:
最下层 Kubelet :即 Rook 的组件是运行与 Kubelet 组件之上,以 Pod 的形式存在于 k8s 集群中;
中间层次 : 这一层是逻辑实现层,运行在 k8s 集群中的 Ceph 存储节点上,包括 Ceph Daemons 、 Rook-discover 、 Ceph CSI Driver 这三种组件。 Ceph Daemons 包括 Ceph 的 OSD 、 Mon 、 MGR 等组件, Rook-discover 用于存储节点上的磁盘设备发现,而 Ceph CSI Driver 组件是 k8s 存储卷管理的插件;
管理层 : 即 Rook Operator for Ceph , Operator 是基于 Kubernetes 的资源和控制器概念之上构建,借助自定义的 CRD (自定义资源)来实现创建、配置和管理 Ceph ;
最上层 Client Pods: 即存储资源的消费层, Client Pods 调用 Ceph CSI Driver 来实现持久化存储卷的添加 / 挂载等操作。
2.2.3 组件间的关联耦合
在了解其组件架构层次后,我们也更容易理清楚各组件之间的耦合关系:首先是所有组件都依赖与 Kubelet 组件服务,这点毫无疑问;其次是 Rook Operator 可以管理配置 Ceph Daemons ,但是 Ceph Daemons 的运行并不依赖于 Rook 的相关组件; Ceph CSI Driver 本身是一个独立组件,主要用于 Ceph 存储资源的消费,不依赖于 Rook Operator ;再看最上层存储资源的消费层, Client Pods 在调用 Ceph 的持久化存储卷的过程中,就依赖于 Ceph CSI Driver 与 Ceph Daemons 这两个组件,而与 Rook Operator 解耦。
3.Rook+Ceph 部署测试
上一节主要从总体架构方面去剖析 Rook+Ceph 各组件之间的关系,而要了解深入学习一种技术架构,最直接有效的方法是使用和测试。对于云原生技术来说,搭建一套简单的 Rook+Ceph 环境并不困难。
3.1 软件版本
| 软件类型 | 版本 |
| CentOS | 7.7.1908 |
| Kubernetes集群 (1个Master 节点,3个Worker节点) | v1.16.9 |
| Rook | v1.3.11 |
| Ceph | v14.2.10 |
Rook 的项目地址: https://github.com/rook/rook
3.2 其他先决条件
- 每个 Kubernetes 集群 Worker 节点都至少一块裸盘,安装 lvm 包
- Kubernetes 集群节点能访问外网或内部镜像仓库
3.3 部署流程
1) 下载对应版本的 Rook
git clone --single-branch --branch v1.3.11 https://github.com/rook/rook.git
2) 部署 Rook Operator
| #cd rook/cluster/examples/kubernetes/ceph |
| #kubectl create -f common.yaml -f operator.yaml |
3)创建 Ceph集群 ( CephCluster)
Ceph 集群默认创建方式下,将会自动扫描管理集群节点中未使用的裸盘。
| # kubectl create -f cluster.yaml |
可查看生成的 CephCluster :
4)存储动态分配
主要介绍 rdb 与 cephfs 两种方式
rbd
用于创建 CephBlockPool 和 StorageClass 两种资源对象
| # kubectl apply –f csi/rbd/storageclass.yaml |
cephfs
MDS 组件部署
| # kubectl create -f filesystem.yaml |
创建存储类
| # kubectl create -f csi/rbd/storageclass.yaml |
5)ceph扩容
三个存储节点都各添加一块盘 sdc ,通过 fdisk –l , lsblk 确认磁盘信息无误
再修改 cluster.yaml 文件,如下图所示:
更新 cephcluster:
| # kubectl apply –f cluster.yaml |
6)其他管理组件安装
toolbox安装
| # kubectl apply -f toolbox.yaml |
通过 kubect exec 可进入 ceph-tools 容器
Ceph Dashboard
创建用于外部访问的 Dashboard service
| # kubectl apply -f dashboard-external-https.yaml |
演示如下图:
4. 过程与模块分析
上节主要介绍的是 Rook+Ceph 的部署测试,部署工作可以再概括为部署 Rook Operator 、 Ceph 集群创建使用过程这两大部分。而本节将结合部署与测试使用过程,详细剖析 Rook+Ceph 架构中的各逻辑模块。
4.1 Rook Operator 部署过程分析

如上图所示,部署 Rook Operator 的过程会在 k8s 集群中新增 rook-ceph 的命名空间,同时也部署了 Rook-ceph-operator 与 Rook-discover 这两种组件。
4.1.1 Rook-ceph-operator 组件
首先从部署截图分析出, Rook-ceph-operator 是 k8s 中的 Depolyment 资源,对应维护着一个 Pod ,可以运行于 k8s 集群中任意或指定的节点。
然后可以查看该 Pod 的配置信息,分析其容器镜像、配置信息等,再查看 Pod 运行日志,如下图所示,日志输出信息较详细,可以看到 Operator 的启动参数,并能推断分析 operator 启动后的运行过程。 
Operator 的启动流程,对应的是 Operator 刚创建或重启的状态,在 Operator 启动后,会紧接着启动 rook-discover 组件,并监视 Cephcluster 等集群资源,启动 operator 内部运行控制器,等待其他驱动事件。
创建 Ceph 集群时,会先创建 CephCluster CRD ,然后启动 ceph-csi 相关组件,同时启动 Ceph daemons , Ceph daemons 会启动 Ceph mon 、 mgr, 然后调用 rook-ceph-osd-prepare 来部署启动 Ceph osd 。
Ceph 集群更新时,需要先更新 Ceph Cluster CR 时, Rook Operator 会先探测到 Cluster CR 发生的变化,生成集群更新的事件,然后会与 Ceph daemon 交互,比对出 Ceph cluster 变更的配置,再发起 Ceph 集群配置更新。
上述过程组件间的交互如下图所示:
4.1.2 Rook-discover 组件
首先由上节可知, Rook-discover 组件由 Rook-ceph-operator 启动,是 k8s 中的 Daemonset 资源,即在所有 Ceph 集群节点上各运行一个 Pod 。
第二步来分析 Pod 的配置信息,同样的可截取出该组件的容器镜像和配置文件信息,可以看出 Operator 与 discover 使用了相同的容器镜像,但容器启动命令和参数不同。
再来分析运行日志,部分截图如下所示:

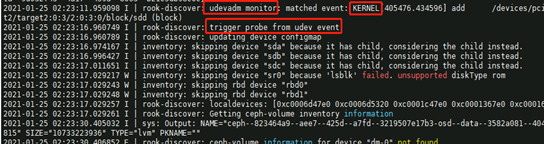
综合日志输出信息,可以分析出三点关键信息:一是 rook-discover 默认每 60 分钟会扫描一次磁盘设备信息,并更新 device configmap ;二是可以看出 rook-discover 主要发现的是符合 ceph 部署条件的 available devices ;三是 rook-discover 会捕获内核发送的 udev event ,这样在存储节点添加新磁盘后, rook-discover 即可立即发现,并更新 device configmap 。
4.2 Ceph 集群创建使用过程分析
Ceph 集群创建过程可以简单描述为 : 创建 CephCluster 的 CRD—> 启动 Ceph CSI—> 启动 Ceph Daemons ( Mon , MGR , OSD ),分别对应的是 Rook Operator 、 Ceph CSI 和 Ceph Daemons 这些组件。
4.2.1 Ceph CSI 组件
根据存储类型不同, Ceph 可分为 rbd 和 cephfs 两种 CSI ,而 CSI 组件按照功能又分为 csi-plugin 和 csi-plugin-provisioner 这两种组件。 csi-plugin 的部署方式是 daemonset ,在所有 k8s 集群节点部署;而 csi-plugin-provisioner 的部署方式是 deployment ,具体统计信息如下表所示:
以 Ceph rbd 为例,这两种 CSI 组件的用途和相互之间的关系如下图所示:

如上图所示, CSI 组件中绿色容器是 ceph 存储对接模块,蓝色容器则是 k8s 的 CSI 功能模块。在上图的架构中, csi-rbdplugin-provisioner 组件由 k8s 集群节点共享使用,其封装了 k8s 与 ceph 的对接过程,使得 k8s 集群得以调用 ceph 存储的挂载、扩容、 snapshot 、挂载等接口; csi-rbdplugin 组件比较简单,主要提供节点服务注册功能,该组件需要在所有 k8s 集群节点上部署。
通过对 Ceph CSI 组件的研究,我们可以进一步分析出 k8s 集群中的 Pod 调用 Ceph 存储的过程: Pod 首先与 k8s 集群 API Server 申请 Ceph 存储资源, k8s 调用 CSI 的存储供给组件,创建 PVC , PVC 绑定并挂载到 Pod ,同时也可以看到 PVC 以 ext4 类型的文件系统挂载到 k8s 节点主机; Pod 重新调度到其他节点的时,在原节点删除 Pod 前,需要先完成 PVC 的 umount , Pod 重新调度后, PVC 继续执行挂载操作。
4.2.2 Ceph Daemons 组件
前文了解到 Ceph Daemons 是 Ceph 存储集群的逻辑模块,主要包括 mgr 、 mon 以及 osd 等组件,下文详细分析下。
ceph mgr
k8s 集群中 mgr 是 deployment 方式部署, mgr 的工作模式是事件驱动型的,等待事件 -> 事件发生 -> 处理事件 -> 继续等待。
继续查看 mgr 的日志,可以发现 mgr 本身导入了很多 python 模块,基于 python 插件来管理跟踪 Ceph 集群的运行状态和集群信息。如下图所示:
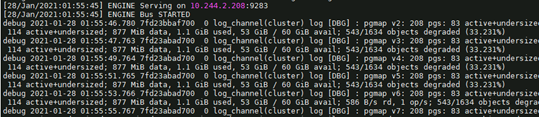
ceph mon
Mon 模块的作用是监控、管理和协调整个集群的 OSD/PG 、 Client 、 MDS 等角色,保证数据的一致性。 k8s 集群中的部署如下图所示,部署多个 deployment ,每个 deployment 对应一个 MON 角色的 pod 。
再查看 Mon 的启动运行日志可分析出: Mon 的后端是一种键值数据库 rocksdb ,兼顾了性能与数据防丢失; MON 采用主备模式( leader/follower ),即使系统中有多个 MON 角色,实际工作的也只有一个 MON ,其它 MON 都处于 standby 状态,当 Ceph 失去了 Leader MON 后,其它 MON 会基于 PaxOS 算法,投票选出新的 Leader 。


ceph osd
分析 osd 模块之前,先分析下集群是如何部署 osd 的。当通过 Rook operator 去新增 ceph osd 时,会同时创建 osd prepare job 。该 job 会在对应集群节点上临时调用 rook-ceph-osd-prepare 的 pod 用于部署 ceph osd 。
再来看 osd 组件,每个 OSD 对应一块磁盘,或者说一个 LVM 设备,并在 k8s 集群中创建对应的 deployment 和 pod 。继续查看 OSD 的启动日志也可以分析出其底层实现逻辑: osd 依托于 bluestore 来管理裸设备,并在 bluestore 的基础上创建 bluefs, 再依托于 bulefs 构建 rocksdb (这点与 mon 模块不同, mon 模块构建于宿主机的 HOSTPATH ),如下图所示:

5. 总结
Rook+Ceph 开源方案践行着自我管理的、自我扩容的、自我修复的云原生存储服务理念,可提供块存储,对象存储和共享文件系统等数据存储服务。按照企业级存储的标准, Rook+Ceph 的存储架构还有一定的局限性,也缺乏完善的企业级存储功能,需要再多一些定制功能,这也是很多开源软件方案的特点。但是在容器云平台的使用场景中,不需要 IAAS 层的支持, Rook+Ceph 方案就能有效提供 k8s 平台的持久化存储服务,这也是它最重要的使用价值。
参考文献:
[1] https://rook.io/
[2] https://cloud.tencent.com/developer/article/1626935
[4] https://blog.csdn.net/zhonglinzhang/article/details/89840133
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞1本文隶属于专栏

作者其他文章
评论 1 · 赞 1
评论 0 · 赞 4
评论 4 · 赞 15
评论 0 · 赞 5
评论 0 · 赞 1
添加新评论0 条评论