采用Oracle12c In memory特性一定能提高性能吗?
Oracle 12c 中的 In memory 选件通过在 SGA 中分配独立的内存区域 (In Memory Area) ,对数据使用列式压缩存储来提高查询性能。
那么,这个 In memory 特性,到底能对性能有多大提升,我们做了一系列的实验,来看看不同场景下的性能表现。但首先要说的是,采用了 In memory 特性,性能并不一定提高,后面我会举例子。
相关参数
SQL> show parameter inmemory;
inmemory_clause_default string
inmemory_force string DEFAULT
inmemory_max_populate_servers integer 2
inmemory_query string ENABLE
inmemory_size big integer 2G
inmemory_trickle_repopulate_servers_percent integer 10
In Memory 区的大小由参数 inmemory_size 控制,该参数是一个静态参数 , 修改后需要重启数据库方可生效。
修改命令:
SQL> alter system set inmemory_size=2G scope=spfile;
System altered.
重启之后
SQL> show sga;
Total System Global Area 5721030656
Fixed Size 5369536
Variable Size 1023410496
Database Buffers 2533359616
Redo Buffers 11407360
In-Memory Area 2147483648
普通场景下,数据库采用 In-memory 特性后,应用查询速度都有明显提升。
应用查询测试结果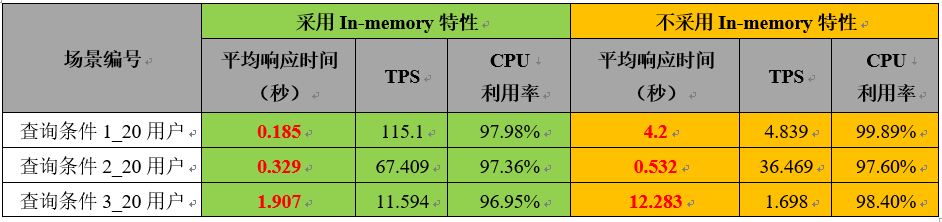
可以看出,三种查询条件,采用了内存特性之后,响应时间分别提升了 23倍、2倍和6倍。
数据库采用 In-memory 特性后,增删改的执行速度差异不大。
增删改测试结果

某些场景插入的速度仍然有较大提升
不过在某些场景下(比如,单用户大批量插入,后面的案例均采用单用户),插入的速度还是可以提升不少的, 如下图。
测试案例中准备了 100 万笔数据,采用 Insert into Select 方式插入两张表,测试结果如下:
| 表 | 耗时(秒) | 结论 |
| 普通表 | 185 | |
| 内存表(DML) | 65 | 提升2.8倍 |
| 内存表(Query Low) | 41 | 提升4.5倍 |
有其他业务压力干扰下的查询性能对比
某复杂的联合查询,内存表比普通表的查询速度提升 20倍。那么,在有其他业务压力干扰下,他的查询性能是怎么样的?
带着这个问题,我们以每秒 5000 笔的速度向内存表和普通表插入数据。在该压力下测试这个复杂联合查询的性能
复杂 SQL :此处略过,写出来有好几行,看不懂
| 表(163万笔) | 耗时(秒) | 结论 |
| 普通表 | 39.63 | |
| 内存表(DML) | 9.12 | 提升4.3倍 |
可以看出,在这个压力干扰下(每秒 5000笔插入数据的干扰),这个查询性能的提升,从原来的 20倍,变成了 4.3倍
DML v.s. QUERY LOW 方式
Oracle 有不同的压缩方式,我们先看看有哪些,都是怎么介绍的。

关注一下“ MEMCOMPRESS FOR QUERY LOW ”,咱们简称 QUERY LOW 吧,这个是缺省方式,号称查询性能最优。
上面的实验中我们是采用 DML 的方式的内存表,现在采用 QUERY LOW 方式试试:
内存表采用 QUERY LOW方式后,性能提升变成了 3.5倍,似乎还不如 DML的提升 4.3倍。看来官方文档也只能参考参考,具体您的环境、您的场景是什么参数性能好,那还得去调优。
| 表(440万笔) | 耗时(秒) | 结论 |
| 普通表 | 21 | |
| 内存表(Query Low) | 6 | 提升3.5倍 |
DML v.s. QUERY LOW方式的性能的确有差异,这种差异的固定的吗?
我们换一个 SQL 语句,换成一个比较简单的 SQL 查询看看
在这个简单 SQL查询的场景中, QueryLow方式性能提升效果更明显。因此,谁快谁慢 it depends。
| 表(163万笔) | 耗时(秒) | 结论 |
| 普通表 | 58 | |
| 内存表(DML) | 3.85 | 提升15倍 |
| 表(440万笔) | 耗时(秒) | 结论 |
| 普通表 | 15.27 | |
| 内存表(Query Low) | 0.4 | 提升38倍 |
跨分区查询
在两实例均开启 In-Memory 特性的情况下,跨分区查询的效率竟然不如只在一个实例使用 In-Memory 特性。
| 场景说明 | 平均响应时间(秒) |
| 将两个分区分别放入两个实例In-Memory内存中,同时查询两个分区的数据量总数 简称为:放二查二 | 4.08 |
| 将一个分区放入一个实例In-Memory内存中,而另一个分区并未使用In-Memory,同时查询两个分区的数据量总数 简称为:放一查二 | 2.462 |
综上
总体来说, In-Memory 特性是可以提升大部分查询场景的性能,但增删改场景很可能是混个持平,对于一些特殊场景,竟然还不如不使用 In-Memory 。不同的压缩方式下,性能的确不同,但有些场景下并不是官方介绍的那个性能结果,如果要得到最佳的性能,还得靠调优。
作者微信公众号:性能测试与调优
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞4本文隶属于专栏

作者其他文章
评论 0 · 赞 2
评论 0 · 赞 2
评论 0 · 赞 1
评论 1 · 赞 4
评论 2 · 赞 2
添加新评论0 条评论