性能测试中的存储高可用切换
一般情况下,我们压力测试关注的都是交易系统吞吐量、业务的响应时间,批处理系统的处理时间,但是我们很少关注某一个计算机部件的故障而导致的高可用切换过程的业务中断时间,以及切换过程中的性能表现。这其实也是我们性能测试所关注的,因为在有压力和没有压力的情况下,这个业务中断的时间是不一样的;切换过程和正常处理过程中系统性能的表现也是不一样的。
本章节介绍在有业务压力下的存储高可用切换测试,从中发现的影响切换时间的问题,以及对问题的分析。
一、 存储服务器高可用的类型
存储的高可用类型很多,先来介绍一种存储的高可用类型 GAD
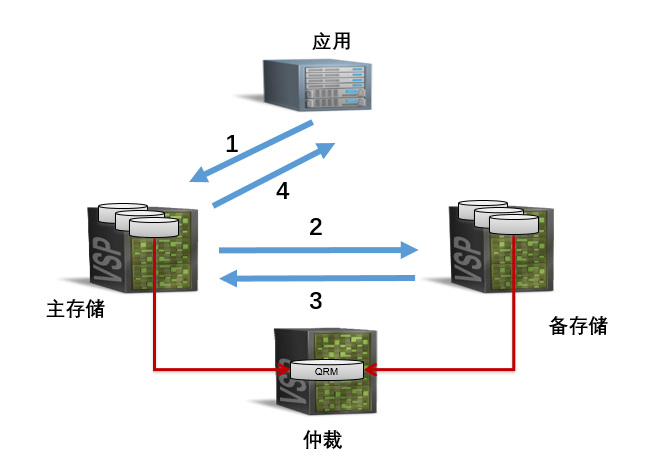
连接备存储也类似,但不论应用指向主存储还是备存储,先落盘的都是主存储。然而这些不是本文的关键。
二、 单台故障后会发生什么?
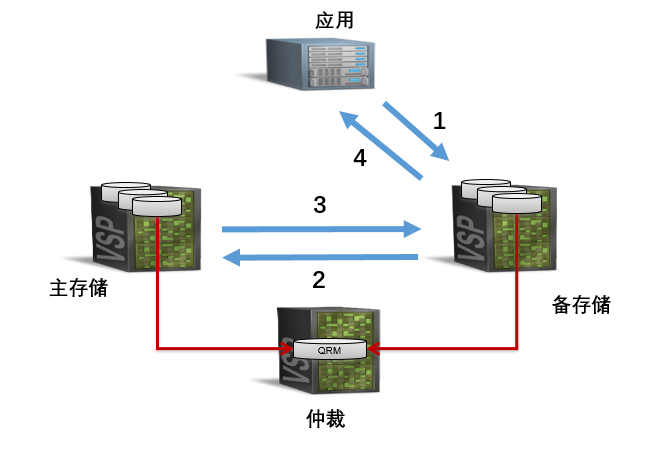
当主存储故障,备存储会自动切换为主存储(改变了身份),并且应用会通过多路径软件识别出主存储故障(当到达超时时间),切换到备存储。
当备存储故障,应用也会通过多路径软件识别出备存储故障,把 IO 路径切换到主存储。
三、 测试结果
在这个测试当中,我们除了关注我们通常所关注的一定吞吐量情况下业务响应时间、数据库 IO 响应时间、磁盘 IO 响应时间,我们还会关注单台存储故障后的切换时长和切换过程的性能表现。
下面是带着压力,存储高可用切换过程中的 CPU 利用率的图。

在主存储故障后大约 40 多秒后,似乎应用发现了主存储故障,之后切到备存储做业务,但似乎直到 3 分钟之后,业务量才完全起来,中间 40 秒 ~3 分钟的过程中,有毛刺状 CPU 。但即使是吞吐量恢复之后,仍然偶尔有吞吐量突然下降的情况
四、 问题分析
一般来说,存储高可用的过程 40 秒就足够了,我们做了 LVM 模式高可用的测试,的确在 40 秒完成存储切换,那么
1. 为什么 GAD 切换时间比 LVM 长?
首先从原理上讲, LVM 模式是这样的

都是主存储,一个存储坏了,只要应用自己发现了,多路径软件直接切到另一个存储就大功告成了。
而 GAD 的主存储出了故障,不但应用要把路径切换到备存储,并且,存储本身要做调整。即备存储要把自己的身份变成主存储。为什么要变身份呢?因为,在一个存储故障的情况下,写 IO 的逻辑也和平时不一样。仲裁要告诉备存储,你现在变成主了,而且是没有备机的主机。
这么一来,就会多一些时间上的耽搁。当然,这个耽搁也本不该这么长( 2 分钟)
2. 为什么有 CPU 的毛刺, 3 分钟之后才完全恢复
这是这个 CPU 图中的疑点。明明故障发生 40 秒之后,已经在备存储上看到了有 IO 读写,并且,业务系统也开始做业务了,为什么 CPU 忽高忽低呢?业务的吞吐量也没有完全起来,直到 3 分钟以后。
那么,我们做个推理
1) CPU 高的时候,是有业务做成功,即可以做写 IO ,而 CPU 低的时候,没有业务做成功,即不能做写 IO 。
2) 那么为什么有时候能写 IO ,有时不能写呢?
是不是因为业务系统中用到了多个 LUN ,这些 LUN 并不是同一时间在备存储启动的,而是一个一个慢慢启动的?
这个推理其实很好理解,因为,我们在 Windows 开机的时候,很早就可以看到 Windows 的桌面了,但这时候开启应用可能失败。因为 Windows 为了让用户体验更高,采用了先展示桌面,后面慢慢启动那些服务的策略。那么存储系统是不是也是这样的呢?
我们做一个小实验,把业务系统写日志的那个盘( LV ),在建盘的时候,把它条带化(打散)到 3 个 LUN 上面。写日志时候,在 LUN1 写 4M 数据(举例),之后就切到 LUN2 上写数据,写满 4M 之后,又去 LUN3 上面写。
注:应用的逻辑是,业务完成的标志是写日志完成,如果写不了日志,这个业务就 Hang 住。

这个图就完美的验证了上面的猜想。
- CPU 明显的忽高忽低就是业务量时而有,时而没有,对应的就是日志一会儿可以写,一会儿不能写。
- 为什么时而不能写呢?因为写完 LUN1 ,要切换到 LUN2 上面写,而 LUN2 这时候还没有在存储层面完成主备切换,应用在下 IO 的时候,存储才意识到自己这个 LUN 应该做切换了,而且应该尽快切换(有点像催单的意思),之后 LUN2 优先完成启动,继续做业务。以此类推, LUN3 也是一样。
五、 调优
基于上述猜想,如何做调优呢?
1) 多路径软件( HDLM )探测存储是否活着,有一个超时时间的设置。把这个超时时间缩短,可以尽早发现存储的故障。
2) 让存储自己尽早发现自己的故障。多路径软件中有一个 HealthCheck 的选项,大概的意思是每隔多久去看一看自己的 LUN 是不是还活着。如果不活着就在另一台存储上把对应的备份激活。把这个 HealthCheck 的时间缩短,从默认的 60 分钟改为 1 分钟。那么存储在发生故障最多一分钟之后,将获得消息,并把故障的 LUN 在另一台存储上拉起。
六、 调优后的结果
完美的验证。

中断时间只有不到一分钟,恢复之后也没有出现吞吐量突然下降的情况。
七、 后续
事实上,这其实是 GAD 在某个 AIX 版本上的 bug ,但通过这样的性能测试,我们不但发现了 bug ,还通过外部的参数优化了切换的效果。
作者微信公众号:性能测试与调优
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞2本文隶属于专栏

作者其他文章
评论 0 · 赞 2
评论 0 · 赞 2
评论 1 · 赞 4
评论 0 · 赞 1
评论 0 · 赞 4
添加新评论2 条评论
2020-11-30 11:05
2020-11-26 17:03