GPFS+HDFS Transparency VS HDFS ? CarbonData在K1 Power Linux 服务器上安装和性能
测试背景
Apache CarbonData 是开源的大数据高效存储格式解决方案。针对当前大数据领域分析场景需求各异而导致的存储冗余问题,CarbonData提供了一种新的融合数据存储方案,以一份数据同时支持“交互式分析、详单查询、任意维度组合的过滤查询等”多种大数据应用场景,并通过丰富的索引技术、字典编码、列存等特性提升了IO扫描和计算性能,实现百亿数据级秒级响应,与大数据生态Apache Hadoop、Apache Spark等无缝集成。
正在进行的大数据项目中可能使用CarbonData作为OLAP分析引擎,同时需要使用K1 Power Linux用作计算节点,因此需要验证CarbonData在K1 Power Linux服务器上的兼容性和性能。
测试环境
测试使用的基础架构如下
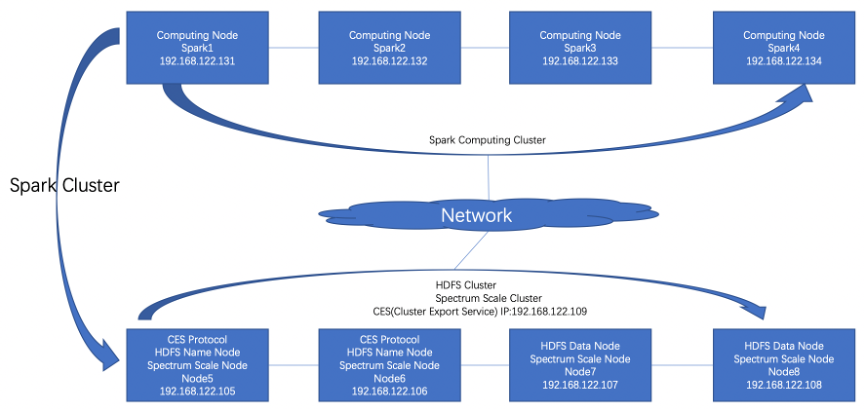
整个基础架构采用计算和存储分离,计算节点4个,存储节点4个,数据网络使用25GB InfiniBand,每个节点配置一块2口Mellanox 25GB InfiniBand网卡。
使用的软硬件栈如下
测试步骤
CarbonData安装
ü 安装好Spark 集群
Spark集群安装在4个计算节点上,保证正常运行,其中Spark1节点为主节点,Spark2,Spark3,Spark4节点为worker节点。
SPARK_HOME路径是 /home/ spark-2.4.6-bin-hadoop2.7
具体安装过程略过。
ü 下载 CarbonData
从 https://dist.apache.org/repos/dist/release/carbondata/2.0.1/
下载 apache-carbondata-2.0.1-bin-spark2.4.5-hadoop2.7.2.jar
登录 Spark1 节点,拷贝 apache-carbondata-2.0.1-bin-spark2.4.5-hadoop2.7.2.jar到 $SPARK_HOME/jars/ 目录下
创建carbonlib目录且生成tar.gz压缩包
1、创建carbonlib目录
mkdir $SPARK_HOME/carbonlib
2、拷贝carbondata jar包到carbonlib
cp apache-carbondata-2.0.1-bin-spark2.4.5-hadoop2.7.2.jar $SPARK_HOME/carbonlib
3、生成tar.gz包
cd $SPARK_HOME
tar -zcvf carbondata.tar.gz carbonlib/
mv carbondata.tar.gz carbonlib/
ü 拷贝carbondata.properties
https://github.com/apache/carbondata/blob/branch-2.0/conf/carbon.properties.template
拷贝carbon.properties.template到$SPARK_HOME/conf目录且命名为carbon.properties
cp ./conf/carbon.properties.template $SPARK_HOME/conf/carbon.properties
ü 配置spark-default.conf
spark.yarn.dist.files $SPARK_HOME/conf/carbon.properties
spark.yarn.dist.archives $SPARK_HOME/carbonlib/carbondata.tar.gz
spark.executor.extraJavaOptions -Dcarbon.properties.filepath=carbon.properties
spark.executor.extraClassPath carbondata.tar.gz/carbonlib/*
spark.driver.extraClassPath $SPARK_HOME/carbonlib/*
spark.driver.extraJavaOptions -Dcarbon.properties.filepath=$SPARK_HOME/conf/carbon.properties
ü 启动 spark-sql
spark-sql –master spark://spark1:7077 --conf spark.sql.extensions=org.apache.spark.sql.CarbonExtensions \
--jars /home/spark-2.4.6-bin-hadoop2.7/jars/
ü 创建数据库
CREATE DATABASE onedb location ‘/gpfspoc/one’;
ü 切换数据库
use onedb;
ü 创建数据表
CREATE TABLE IF NOT EXISTS onetable (
id string,
name string,
city string,
age Int)
STORED AS carbondata;
ü 创建测试数据文件 sample.csv
cd /gpfspoc
cat > sample.csv << EOF
id,name,city,age
1,david,shenzhen,31
2,eason,shenzhen,27
3,jarry,wuhan,35
EOF
ü 加载数据到 onetable
LOAD DATA INPATH '/gpfspoc/sample.csv' INTO TABLE onetable;
ü 查询数据
select * from onetable;
安装,验证结束
CarbonData性能测试
为了测试性能,创建了一个数据表的结构共 101 个列,第一列为 id Int,剩余100列,均为 string 类型。
另外,制作了一个 48GB 的csv 文件,除了第一行为列名,剩余共 1000万行,每一个 string 列均为50个字符。
测试结果显示,数据表和csv文件都放在GPFS上时,加载数据耗时约200秒。数据表
和csv文件都放在HDFS上时,加载数据耗时约300秒。
测试结论
经过上述安装和性能测试,不仅证明了CarbonData运行在K1 Power Linux的兼容性,也说明了此基础架构能够提供很好的性能,满足客户需求,提供更好的客户体验。另外,从性能角度看,使用GPFS+HDFS Transparency 代替 HDFS ,然后将 CarbonData 数据直接存储在 GPFS 上,性能要快 50% 。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞1作者其他文章
评论 0 · 赞 0
评论 0 · 赞 0
评论 0 · 赞 0
评论 0 · 赞 0
评论 1 · 赞 1
添加新评论0 条评论