加速证券极速交易系统
近年来随着我国金融市场的不断发展、市场交易结构的不断完善、交易品种的日趋多样化以及计算机及网络技术的发展,越来越多的投资者参与到量化交易中。据 Wind 数据介绍,2010年国内市场上仅有11只量化基金,总规模不足100亿元,到2017年年底市场上已有142只量化基金,总规模1000亿元左右。10 年不到的时间,量化的规模扩大了10倍。其业绩稳定,市场规模和份额不断扩大,得到了越来越多投资者的认可。
量化交易关键在于通过流动性的不对称,以及交易对手速度的延缓,来获取转瞬即逝的套利机会。因此这种非传统性的交易方式使得量化交易对订单处理系统提出了更高的要求,集中体现在提升交易速度和支持程序化交易接入方面。传统的集中交易模式已无法满足量化投资者的迫切需要,急需针对量化投资者的新型交易系统,能实现高速生成、申报订单并获取回报信息等功能。
基于市场上量化投资爆发式发展及其对交易速度的极致需求,近几年各券商纷纷上线和升级基于内存数据库、低延时网卡、以及 FPGA 等潮流技术的极速交易系统。目前市场上极速交易系统非常多,包括恒生、华锐、宽睿、顶点、金证、金仕达等都推出了自己的极速交易系统。
极速交易系统具有灵活的用户接入方式,如 API 接口及客户端等,完全符合量化投资者的使用习惯。在交易权限方面,进行严格的验资验券、相关业务的资金冻结以及交易的权限控制等。在监管方面,严格遵循监管机构对于量化交易的各项前端规范要求。市面上绝大部分极速交易系统为量化机构投资者提供更低延时、更高效率、更优用户体验的整体技术产品解决方案。
极速交易系统一般部署架构如下: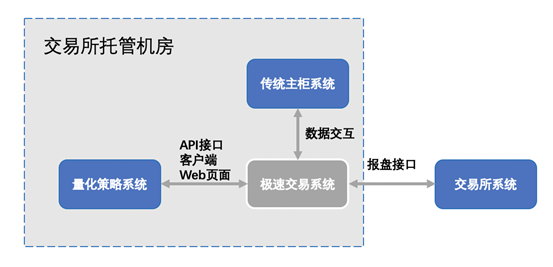
为打造低延迟的环境,将投资者订单以最快的速度送到交易所系统,极速交易系统一般部署在上交所或者深交所托管机房,投资者需要将自己的策略服务器 托管在机房,通过 VPN 方式访问自己的策略服务器。从上图可以看到,对于投 资者来说,其自身的量化策略系统可通过 API 接口或者客户端方式对接极速交易系统,享受系统所提供的低时延、高效率的极致订单通道服务。
极速交易系统性能评价依据:
各时间戳记录位置:
A1 :调用发送委托 API 之前。
A2 : API 收到委托确认之后,确认消息收到后记录时间。
B1 :收到委托消息后,在确认处理前,记录时间。
B2 :委托确认后,发送委托确认消息前,记录时间。
G1 :服务端收到委托上报的时间点。
O6 :委托上报完成的时间点。
O7 :服务端收到委托确认时间点。
G12 :服务端推送委托确认回报给客户时间。
一般评分是对于以下每个指标,计算平均值。
可加速部分: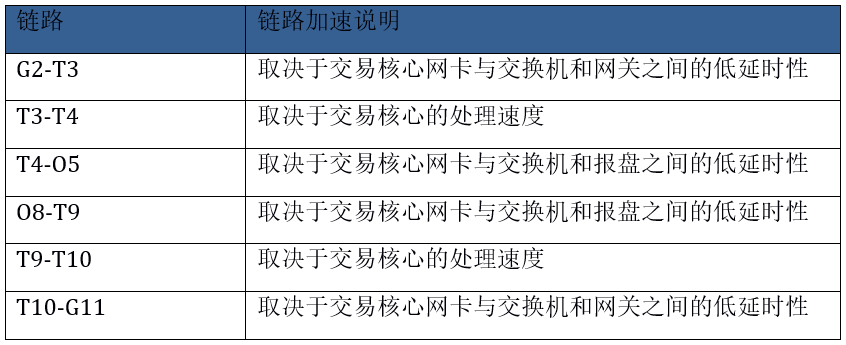
主机加速办法主要有两种:
Ø 采用高主频、低延时的处理器
Ø 低延迟通信网络,如采用低延时的网卡或 FPGA 加速卡
处理器优化方案
选择高主频、低延时的处理器方案时,通常有两种选择:
1) 采用高主频的 Intel CPU ,通过超频的方式, 2 台机器热备的方法。该方案的优势在于成本相对较低,一般桌面级 CPU 也可满足要求,劣势在于稳定性非常差,由于极速交易系统一般在系统运行时,就采用 CPU 绑定的方式,所以 CPU 一般是高负荷运行,对于 x86 平台而言,始终难以维持高效稳定地运行。
2) 采用极高主频的 K1 Power Linux 服务器。其实很多券商最核心的集中交易系统都是运行在 K1 Power 服务器上,券商之所以选择 K1 Power 服务器,主要原因就是 K1 Power 服务器的高性能、高可靠性。采用 K1 Power Liunx 服务器来运行极速交易系统,由于小型机的整体性能明显强于 x86 ,而且稳定性非常高,可以保证极速交易系统长期高效、稳定运行。另外, K1 Power Linux 服务器已经完全实现本地化,即本地化生产、本地化研发、本地化服务,完整的本地化能力覆盖从产品设计到生产制造再到后期的应用与运维的全生命周期管理,可以让极其注意安全性、可靠性与可用性的金融机构真正放心,而且整体成本也和 x86 平台差不多。
低延时通讯网卡解决方案:
证券交易网络通信通常具有一个非常明显的特征: Microburst 。即从宏观结构上来看,平均每秒流量非常小,优化上来看主要 2 个方向:
1) 低延时网卡解决方案,目前主流的方案是采用 Solarflare 的网卡及配套交换机,或者 Mellanox CX 系列网卡配合相应的交换机。
2) 另一方的优化在系统侧,大量的交易应用程序基于 TCP 通信,而经典的 Linux 内核实现也使得 TCP 通信延迟相对较高,同时伴随着多对一通信模式下的 TCP incast 带来的延迟。
业界为了解决这个问题,通常采用如下几种做法:
- 使用 InfiniBand 网络重构通信,但是由于交易所开发资源受限和项目潜在风险较高,且 IB 网络成本等多种因素的影响,仅有极少数交易所采用。
- ROCE ( RDMAover Converged Ethernet ):大量的对于通信有低延迟需求的行业( AI/ 存储 / 消息队列)已经开始使用,例如在存储和 AI 训练等众多方案中都开始采用, Nvidia 甚至因为这个技术收购了 Mellanox 。阿里云等企业也开始大面积部署 ROCE 等技术。但对于交易所行业而言,同样需要在传统的 TCP 通信代码上进行较大的改动,因此进展缓慢。
- Kernel Bypass :这种技术是交易所现阶段使用较多的技术,通过特定的网卡和驱动实现,上层应用则继续仅作较小的修改,这类技术包括 Solarflare 的 Onload 和 Exablaze 的 ExaSOCK 。
- TCP Offload :即在 FPGA 上构造 TCP 状态机和应用逻辑,完全脱离于主机执行交易相关的数据处理,交易所可以在这个场景中实现对交易订单的价格优先 / 时间优先定序,并在满足可执行撮合条件时通知主机进行撮合。
选择系统侧优化方案时, K1 Power 服务器因为其强大的 IO 性能,因此相比 x86 也有明显的性能优势。 K1 Power 服务器的 IO 子系统采用了 PCIe Gen4 技术,为业内独有,比上一代 PCIe Gen3 带宽提升了一倍。另外, K1 Power 服务器还提供了包括 NVLink 2.0 和 CAPI 等技术。 OpenCAPI 是一个开放的独立接口架构,是由 OpenCAPI 联盟(一个独立的非盈利联盟,初创成员包括 AMD 、 Google 、 IBM 、 Mellanox 、 Micron )制定的接口标准。 OpenCAPI 是一种高速低延迟的互联机制,可以使异构加速器( FPGA/ASIC )和其他 IO 子系统(内存、磁盘、网卡)等与 CPU 共享内存地址,让计算能力更靠近数据,消除传统系统架构中的低效率,帮助打消系统瓶颈,大幅度提升服务器性能。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞2
添加新评论1 条评论
2023-08-10 16:03