
如何让Oracle RAC数据库能更充分利用高端服务器资源
近年来,高端 CPU 芯片技术不断在突破摩尔定律,核数也越来越多,多路高端服务器的 CPU 处理能力越强。但实际应用却很难把多路高端服务器资源有效利用起来。
以高端服务器用于常见高并发交易的 Oracle RAC 数据库为例,往往会看到数据库服务器 CPU 利用率还较低,内存也有很多富余, Disk IO 响应也很快,网络看似网卡带宽也没用满,查看数据库 AWR 报告, Top Event 中貌似也没有特别突出的等待事件。但即使应用端怎么增加节点、优化配置,并发性能就是上不去了。心理不免担忧在负载高峰来临时如何能应对,总不能把整个架构推翻,进行分库分表或者用分布式吧,那些看着挺好,但应用改造代价太高了,完全不是一朝一夕能解决的事情。
这中间可能忽略了一个问题,那就是高并发交易场景通常传输的是小网络包 ( 几十 - 几百字节不等),而网卡在传输小网络包条件下,在远没达到带宽极限情况下,每秒传输包数量( PPS )先达到了网卡能力上限。出现这种情况怎么办?一种方式是让数据库和应用运行在一起,应用和数据库间通信走 ipc 机制或者用 loopback 环路地址,这种方式至今仍在广泛使用。另一种方式是我们考虑用新型的高带宽低延迟的 10Gb 甚至 100Gb 网卡,并且将多张卡多个网口绑定在一起使用,这种方式能倍增网络带宽,但难以倍增 PPS 能力提升。
如何能让网络 PPS 能力翻倍:
比较简便的是用多个独立的网络接口,配置多个不同的 IP 并行使用了,这种方式我们的数据库应用需要如何改造呢?
Oracle RAC 数据库早已经具备了这样的能力, Oracle 11gR2 时,已经支持对 RAC 私有通信的 HAIP ( Highly Available IP )功能,实现了集群内部通信的高可用及负载均衡。 Oracle 12c(2013 推出 ) 支持多个不同网段的 SCAN IP ( Multiple Subnets SCAN IP ),同时提供对外连接和服务。
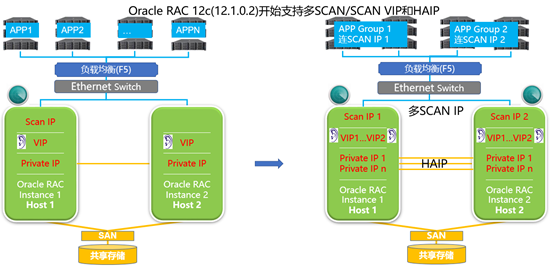
l 左半部分为最常用的 Oracle RAC 1SCAN IP+1Private IP 模式
l 右半部分为 Oracle RAC (12c/18c/19c/20c) 支持的多 SCAN IP+HAIP 模式
采用这种多 SCAN IP+HAIP 模式,除了已提到的解决高端服务器上数据库网络包传输能力不足问题,提升数据库系统整体性能,都有什么好处呢?
HAIP好处
l 多对 Private IP 同时负载均衡的为 Oracle RAC 提供私有数据通信服务
l 倍增 Oracle RAC 私有通信带宽,降低节点间通信延迟
l 数据库应用可以在 RAC 间更好的负载均衡
l 提高 Oracle RAC 数据库的响应速度和整体并发性能
多 SCAN IP 好处
l 多个 SCAN IP 同时对外提供服务
l 提高网络传输能力,提升数据库高并发交易处理能力
l 为数据库应用提供分组负载均衡
l 为数据库部署多服务、多租户 (CDB/PDB) 环境提供网络隔离,更安全
l 不同数据库应用服务可以接入不同网元,实现应用的网元隔离
l 提高 Oracle RAC 数据库的整体并发性能、可靠性和安全性
这种模式的性能能提升多少?可靠性又怎么样呢?
我们在 K1 Power9 高端服务器上做了 Oracle 19c RAC on AIX 7.2 做了全面验证,分享结果如下:
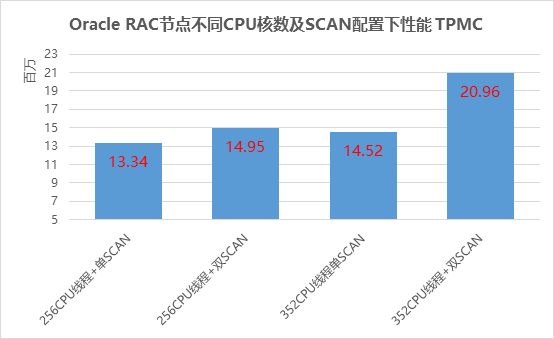
1.性能提升
如下图:
p 256CPU 线程配置下
Ø 单 SCAN ,网络性能勉强够用的
p 提高到 352CPU 线程(增加 37% )
Ø 单 SCAN ,网络有明显网络瓶颈
Ø 配上双 SCAN ,性能比单 SCAN 时提升了( 20.96 vs 15.52 )44%
1.可靠性验证
对 HAIP 和双 SCAN IP 共做了 22 组故障场景下 RAC 可靠性和服务连续性验证,结果全部通过。
l HAIP验证:
Oracle RAC 用了 en4 和 en5 两个网口做 HAIP 私有网络通信(测试条件有限,没有更多张卡了)
| 序号 | HAIP over (en4+en5)故障场景 | 故障模拟方式 | 期望效果 | 结果 |
| 1 | 节点1的en5故障 | en5网口down | 两个节点私有通信都飘到en4上,对性能影响有限 | 通过 |
| 2 | 节点1的en5故障后恢复 | en5网口线恢复并up | en5私有通信自动恢复,en4,en5恢复负载均衡 | 通过 |
| 3 | 节点1的en4,en5同时故障 | en4,en5网口down | 数据库节点1 down,节点1所有vip,scan ip, Oracle服务飘到节点2上。剩余节点2继续运行 | 通过 |
| 4 | 节点1的en4,en5恢复 | 节点1恢复,en4,en5网口线恢复并up | 数据库节点1恢复后,节点1上原有vip,scan ip, Oracle服务器自动从节点2漂移回来,节点1可继续承接负载 | 通过 |
| 5 | 节点1和2的en4同时故障 | 节点1和2的en4网口同时down | 两个节点私有通信都飘到en5上,对性能影响有限 | 通过 |
| 6 | 节点1和2的en4恢复 | 节点1和2的en4网口线恢复并up | en4私有通信自动恢复,en4,en5恢复负载均衡 | 通过 |
l 多 SCAN IP 验证:
Oracle RAC 用了 en0 和 en1 两个网口做对外服务器双 SCAN IP (测试条件有限,没有更多张卡了)
| 序号 | SCAN IP over (en0+en1)故障场景 | 故障模拟方式 | 期望效果 | 结果 |
| 1 | 节点1的en1故障,故障前en1的SCAN IP在节点2 | 节点1的en1网口down | 属于节点1的en1上VIP漂移至节点2,负载影响较小 | 通过 |
| 2 | 节点1的en1恢复 | 节点1的en1网口线恢复并up | 属于节点1的en1上VIP自动从节点2漂移回来,且侦听与服务恢复正常,负载正常 | 通过 |
| 3 | 节点2的en1故障,故障前en2的SCAN IP在节点2 | 节点2的en1网口down | 属于节点2的en1上VIP漂移至节点1,负载影响较小 | 通过 |
| 4 | 节点2的en1恢复 | 节点2的en1网口线恢复并up | 属于节点2的en1上VIP,SCAN IP自动从节点1漂移回来,且侦听与服务恢复正常,负载正常 | 通过 |
| 5 | 节点1的en0,en1同时故障,故障前en0的SCAN IP在节点1,故障前en1的SCAN IP在节点2 | 节点1的en0,en1网口down | 属于节点1的en0上VIP,SCAN IP漂移至节点2,en1上VIP,SCAN IP漂移至节点2,负载影响较小 | 通过 |
| 6 | 节点1的en0,en1恢复 | 节点1的en0,en1网口线恢复并up | 属于节点1的en0上VIP,SCAN IP自动从节点2漂移回来,en1上VIP自动从节点2漂移回来,且侦听与服务恢复正常,负载正常 | 通过 |
| 7 | 节点1和2的en1同时故障,故障前en1的SCAN IP在节点2 | 节点1和2的en1网口down | 节点1和2的en1上VIP,SCAN IP都不能工作,还剩en0对外提供服务,负载影响较小 | 通过 |
| 8 | 节点1和2的en1恢复 | 节点1和2的en1网口线恢复并up | 属于节点1的en1上VIP恢复起来,属于节点2的en1上VIP,SCAN IP恢复起来,且侦听与服务恢复正常,负载正常 | 通过 |
| 9 | 节点1和2的en0同时故障,故障前en0的SCAN IP在节点1 | 节点1和2的en0网口down | 节点1和2的en0上VIP,SCAN IP都不能工作,还剩en1对外提供服务,负载影响较小 | 通过 |
| 10 | 节点1和2的en0恢复 | 节点1和2的en0网口线恢复并up | 属于节点1的en0上VIP,SCAN IP恢复起来,属于节点2的en0上VIP恢复起来,且侦听与服务恢复正常,负载正常 | 通过 |
| 11 | 节点1的对外en0和私有通信en4同时故障,故障前en0的SCAN IP在节点1 | 节点1的en0,en4网口down | 节点1和2的私有通信都飘到en5,属于节点1的en0上VIP和SCAN IP漂移到节点2,负载影响较小 | 通过 |
| 12 | 节点1的对外en0和私有通信en4恢复 | 节点1的en0,en4网口线恢复并up | 节点1和2的私有通信恢复到en4+en5,属于节点1的en0上VIP和SCAN IP从节点2漂移回来,且侦听与服务恢复正常,负载正常 | 通过 |
| 13 | 节点1的所有对外en0,en1和私有通信en4,en5同时故障,故障前en0的SCAN IP在节点1, en1的SCAN IP在节点2 | 节点1的en0,en1,en4,en5网口全部down | 节点1私有通信全断。属于节点1的en0上VIP和SCAN IP漂移到节点2,节点1的en1上VIP漂移到节点2。剩余节点2对外服务器,负载影响较小 | 通过 |
| 14 | 节点1的所有对外en0,en1和私有通信en4,en5恢复 | 节点1的en0,en1,en4,en5网口线全部恢复并up | 节点1私有通信恢复。属于节点1的en0上VIP和SCAN IP从节点2漂移回来,节点1的en1上VIP从节点2漂移回来。节点1数据库实例启动后,侦听与服务恢复正常,2个节点同时对外服务,负载正常 | 通过 |
| 15 | 模拟节点1挂账 | 节点1 halt -q | 节点1故障后。剩余节点2对外服务器,负载影响较小 | 通过 |
| 16 | 节点1重启恢复 | 节点1重启恢复 | 节点1恢复后,属于节点1的en0上VIP和SCAN IP从节点2漂移回来,节点1的en1上VIP从节点2漂移回来。节点1数据库实例启动后,侦听与服务恢复正常,2个节点同时对外服务,负载正常 | 通过 |
最后您可能要问,它会对数据库应用的开发、部署和运维带来什么影响。
l 对数据库应用开发过程是透明的,与单 SCAN 时用法基本一致
l 数据库系统架构设计要考虑双 SCAN IP 在对网络架构带来的变化,以及数据库服务部署是否针对多 SCAN 方式做相应调整(默认多个 SCAN 均等,接入所有数据库服务)
l 上线前需要对这种架构多做带负载的功能测试及性能验证,消除部署过程可能发生的错误
如果使用高端服务器上 Oracle RAC 数据库,在高并发下遇到类似网络性能问题,不妨试试这种方式。
附录:
多 SCAN 参考:
https://support.oracle.com/knowledge/Oracle%20Database%20Products/2138078_1.html
https://www.oracle.com/technetwork/products/clustering/overview/scan-129069.pdf
HAIP参考:
https://docs.oracle.com/database/121/CWADD/GUID-478452E9-5A0B-4B36-BF82-CDF585007D14.htm#CWADD92358
实验环境说明
| RAC LPAR | Hostname | 系统版本 | Boot网口及IP_1 | Boot2网口及IP_2 | RAC心跳网口 HAIP | 服务VIP 1 & 2 | SCANIP 1 & 2 | 共享存储 |
| dblpar1 | dbnode1 | 7200-04-01-1939 | en0:172.16.102.221 | en1: 172.16.103.221 | en4:192.168.102.221 en5:192.168.103.221 | en0:172.16.102.223 en1:172.16.103.223 | en0:172.16.102.225 | 5*350GB =1.65TB |
| dblpar2 | dbnode2 | 7200-04-01-1939 | en0:172.16.102.222 | en1: 172.16.103.222 | en4:192.168.102.222 en5:192.168.103.222 | en0:172.16.102.224 en1:172.16.103.224 | en1:172.16.103.225 |
配置双 SCAN+HAIP 参考
l 分配新增的 SCAN IP 和 HAIP 用的 public ip 2,vip 2, scan ip2 和 Private IP 2 …
l 完成网络交换机配置和布线改造
l 给 AIX 系统配置新增的 IP 地址
cat /etc/hosts
172.16.102.221 dbnode1
172.16.102.222 dbnode2
172.16.102.223 dbnode1_vip
172.16.102.224 dbnode2_vip
172.16.102.225 dbscan102
192.168.102.221 dbnode1_priv
192.168.102.222 dbnode2_priv
172.16.103.221 dbnode12
172.16.103.222 dbnode22
172.16.103.223 dbnode1_vip2
172.16.103.224 dbnode2_vip2
172.16.103.225 dbscan103
192.168.103.221 dbnode1_priv2
192.168.103.222 dbnode2_priv2
l 给 Oracle RAC 配置 SCAN IP & HAIP ,然后重启生效
[root]# ./oifcfg setif -global en5/192.168.103.0:cluster_interconnect
[root]# cd /oracle/grid/bin; ./oifcfg setif -global en1/172.16.103.0:public
[root]# ./oifcfg getif – global
en0 172.16.102.0 global public
en4 192.168.102.0 global cluster_interconnect,asm
en5 192.168.103.0 global cluster_interconnect
en1 172.16.103.0 global public
[root]# ./srvctl add network -netnum 2 -subnet 172.16.103.0/255.255.255.0/en1
[root]# ./srvctl config network -netnum 2
[root]# ./srvctl add vip -node dbnode1 -netnum 2 -address dbnode1_vip2/255.255.255.0
[root]# ./srvctl add vip -node dbnode2 -netnum 2 -address dbnode2_vip2/255.255.255.0
[grid]$ srvctl add listener -listener listener2 -netnum 2 -endpoints "TCP:1522"
[root]# ./srvctl add scan -scanname dbscan103 -netnum 2
[root]# ./srvctl start vip -vip dbnode1_vip2; ./srvctl start vip -vip dbnode2_vip2
[grid]$ srvctl start listener -listener listener2; srvctl status listener -listener listener2
[root]# ./srvctl start scan -netnum 2
[grid]$ srvctl add scan_listener -netnum 2 -listener LISTENER_SCAN2 -endpoints "TCP:1522"
[grid]$ srvctl start scan_listener -netnum 2
[root]# ./srvctl config scan -netnum 2; ./srvctl status scan -netnum 2
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞3作者其他文章
评论 0 · 赞 2
评论 1 · 赞 2
评论 0 · 赞 0
评论 0 · 赞 1
评论 0 · 赞 1
添加新评论0 条评论