Hadoop大数据存算分离需要什么样的存储?
据IDC预测,到2021年,至少 50% 的全球GDP将由数字化驱动。面对海量数据,企业亟需通过更加现代化、敏捷、高性能的IT基础设施来推进业务持续发展。
当今世界,只有很少的数据得到了分析,还有巨大的待开发潜能,在高达 3000亿美元 的以数据为驱动的市场中,中国在人工智能、物联网和5G等技术方面已经逐渐成熟,为中国数字经济蓬勃发展奠定了基础,而那些尚未被充分利用的数据,就是新商业价值的关键元素。
01 数据湖的价值
数据湖支持以其本机或接近本机的格式存储数据,从而为高技能的数据科学家和分析师提供了未完善的数据视图。数据湖提供了一个没有折衷的环境,以及相应的记录分析系统所共有的保证和利益,即语义一致性,治理和安全性。 
因此,数据湖特别适合科学家对未知数据和未知问题的探索。很多暂时得不到分析的数据,可以暂时统一保存在数据湖里。
02 Hadoop是数据湖最常用的解决方案
Hadoop的一个主要优势是支持围绕未知数据和未知问题的这些探索性用例。它在LDW(逻辑数据仓库)中扮演的角色在基于数据管理基础设施模型的右上象限 - 未知数据领域和未知问题。由于Hadoop技术针对语义灵活性进行了优化,因此它可以与传统的结构化数据仓库并列,从而实现更广泛的数据类型,最终用户和用例。 
虽然现在Hadoop没有前几年那么热,但是,它依然是数据湖最常用的解决方案。最近的Gartner研究数据表明,Hadoop的部署和需求仍然很大并且正在增长。在最近的一项调查中,有235名受访者表示,34%的受访者目前正在使用Hadoop进行数据和分析工作,另有55%的受访者计划在未来24个月内进行调查,总计达到 89% 。这是Gartner 2016年研究以来的需求最大幅度增加。
03 HDFS的局限
Apache Hadoop是一个高度可扩展的系统,广泛应用于大数据存储和分析。Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件上的分布式文件系统。 
HDFS主要由三部分构成:
- NameNode:NameNode 上保存着整个HDFS的命名空间和数据块映射关系。所有的元数据操作都将在NameNode中处理;
- DataNode:DataNode将HDFS数据以文件的形式存储在本地的文件系统中,它并不知道有关HDFS文件的信息;
- DFSClient:HDFS的客户端,在Hadoop文件系统中,它封装了和HDFS其他实体的复杂交互关系,为应用提供了一个标准的、简单的接口。
Hadoop为大数据分析带来便利的同时,也面临着一些挑战:
1、Hadoop 的扩展受限
NameNode是HDFS中的管理者,主要负责文件系统的命名空间、集群配置信息和数据块的复制等。NameNode在内存中保存文件系统中每个文件和每个数据块的引用关系,也就是元数据。 在运行时,HDFS中每个文件、目录和数据块的元数据信息(大约150字节)必须存储在NameNode的内存中。根据Cloudera的描述,默认情况下,会为每一百万个数据块分配一个最大的堆空间1GB (但绝不小于1GB)。这导致实际限制了HDFS中可以存储的对象数量,也就意味着对于一个拥有大量文件的超大集群来说,内存将成为限制系统横向扩展的瓶颈。 同时,作为一个可扩展的文件系统,单个集群中支持数千个节点。在单个命名空间中DataNode可以扩展的很好,但是NameNode并不能在单个命名空间进行横向扩展。通常情况下,HDFS集群的性能瓶颈在单个NameNode上。 在Hadoop 2.x发行版中引入了联邦HDFS功能,允许系统通过添加多个NameNode来实现扩展,其中每个NameNode管理文件系统命名空间中的一部分。但是,系统管理员需要维护多个NameNodes和负载均衡服务,这又增加了管理成本。
2、计算和存储绑定 在传统的Apache Hadoop集群系统中,计算和存储资源是紧密耦合的。在这样的集群中,当存储空间或计算资源不足时,只能同时对两者进行扩容。假设用户对存储资源的需求远大于对计算资源的需求,那么用户同时扩容计算和存储后,新扩容的计算资源就被浪费了,反之,存储资源被浪费。这导致扩容的经济效率较低,增加成本。 独立扩展的计算和存储更加灵活,同时可显著降低成本。因此,现在Hadoop采用存算分离的架构的趋势越来越明显,Hadoop社区普遍采用S3A客户端来对接外部对象存储。
3、HDFS的性能问题HDFS核心组件NameNode的全局锁问题一直是制约HDFS性能,尤其是NameNode处理能力的主要因素。HDFS在锁机制上使用粒度较粗的全局锁来统一来控制并发读写,这样处理的优势比较明显,全局锁可以简化锁模型,降低复杂度。但是由全局锁的一个比较大的负面影响是容易造产生性能瓶颈。NameNode核心处理逻辑上涉及到两个锁: FSNamesystemLock (HDFS把所有请求抽象为全局读锁和全局写锁)和 FSEditLogLock (主要控制关键元数据的修改,用于高可用),一次RPC请求处理流程经过了两次获取锁阶段,虽然两个锁之间相互独立,但如果在两处中的任意一处不能及时获取到锁,RPC都将处于排队等待状态。等锁时间直接影响请求响应性能。
再有,因为写锁具有排他性,所以对性能影响更加明显。当有写请求正在被处理,则其他所有请求都必须排队等待,直到当前写请求被处理完成释放锁。当集群规模增加和负载增高后,全局锁将逐渐成为NameNode性能瓶颈。
04 S3A的不足
原生的Hadoop中包含一个的S3A连接器,基于Amazon Web Services (AWS) SDK实现的。Hadoop S3A允许Hadoop集群连接到任何与S3兼容的对象存储。 XSKY的对象存储产品XEOS兼容S3协议,所以可以通过S3A连接器与Hadoop应用进行交互,但这种方式存在比较大的局限性。 
通过上图,可以看到Hadoop应用通过S3A客户端上传数据时,需要调用S3 SDK把请求封装成HTTP然后发送给XEOS对象路由,然后再由对象路由转发到XEOS的S3网关,最后通过S3网关将数据写入XEOS存储集群,从而达到数据上传的目的。下载文件也是一样的道理。 S3A虽然同样可以实现计算和存储分离,但基本架构和协议兼容性上还是存在一些问题:
- 由于所有的数据都需要先经过对象路由和S3网关,所以在IO路径上就会多了对象路由和S3网关这一跳;
- S3A因为通过S3 SDK来实现,所以并不支持标准Hadoop文件系统的追加写操作;
- S3A 因为使用标准的S3协议,所以势必会在一些偏文件风格的接口上做更多的判断,导致客户端逻辑复杂。如判断一个目录,需要多次REST请求才能完成,同时过多的REST请求将会对性能造成影响。
05 XSKY HDFS Client应运而生
为了解决S3A的问题,XSKY开发了 XSKY HDFS Client ——XEOS存储集群和Hadoop计算集群量身打造的连接器。 通过XSKY HDFS Client(简称“XHC”),Hadoop应用可以访问存储在XEOS中的所有数据,这就避免了传统的Hadoop应用在进行数据分析前,还要将数据由业务存储移动到分析存储HDFS中,也就是常见的ETL过程。 
XSKY HDFS Client相当于HDFS的DFSClient,为Hadoop应用提供了标准的 Hadoop文件系统API。在每个计算节点上,Hadoop应用都将使用XSKY HDFS Client (JAR) 执行 Hadoop文件系统的操作,并且屏蔽了Hadoop应用与XEOS集群交互的复杂性。在XEOS集群中,每一个存储节点都等效于HDFS的NameNode和DataNode。
06 XSKY HDFS Client 的架构与实现
相比于S3A通过S3 SDK封装HTTP请求的方式访问XEOS不同,XSKY HDFS Client可以直接访问存储集群的OSD,IO路径上要短得多。 
XSKY HDFS Client通过 XEOS提供的NFS风格的接口与XEOS集群进行交互 ,这种实现方式的优势主要体现在:
- 由于省掉了对象路由和S3网关这一层,所以性能会好于S3A;
- XEOS的NFS网关库的write接口具有追加写的功能,可以匹配Hadoop文件系统对追加写的需求。

XSKY HDFS Client本身是一个由Java实现的JAR包。作为Hadoop兼容的文件系统,XSKY HDFS Client需要按照Hadoop FileSystem API规范来实现,也就是实现抽象的Hadoop FileSystem、OutputStream和InputStream。其中,XSKY HDFS Client的FileSystem主要实现了Hadoop FileSystem的list、delete、rename、mkdir等接口,而InputStream和OutputStream主要实现了对XEOS对象的读写功能。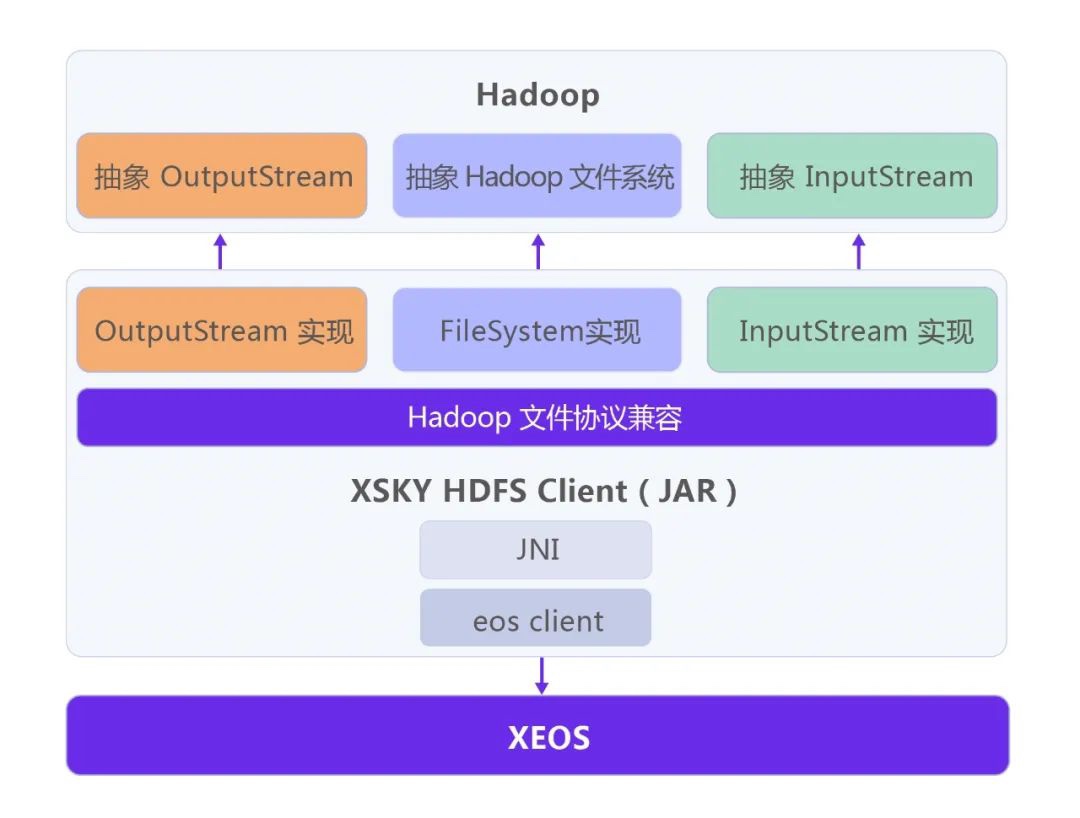
XSKY HDFS Client会将Hadoop应用的Java调用,通过JNI (Java Native Interface) 技术转换为本地librgw.so的调用,并最终访问到XEOS集群。在计算节点上,需要部署XSKY HDFS Client JAR包、librgw.so及其依赖的so库和配置文件。
07 XSKY HDFS Client的自动化部署
XSKY HDFS Client应该在所有需要访问XEOS存储的计算节点部署。XSKY提供了自动化部署工具,用于简化部署的过程。 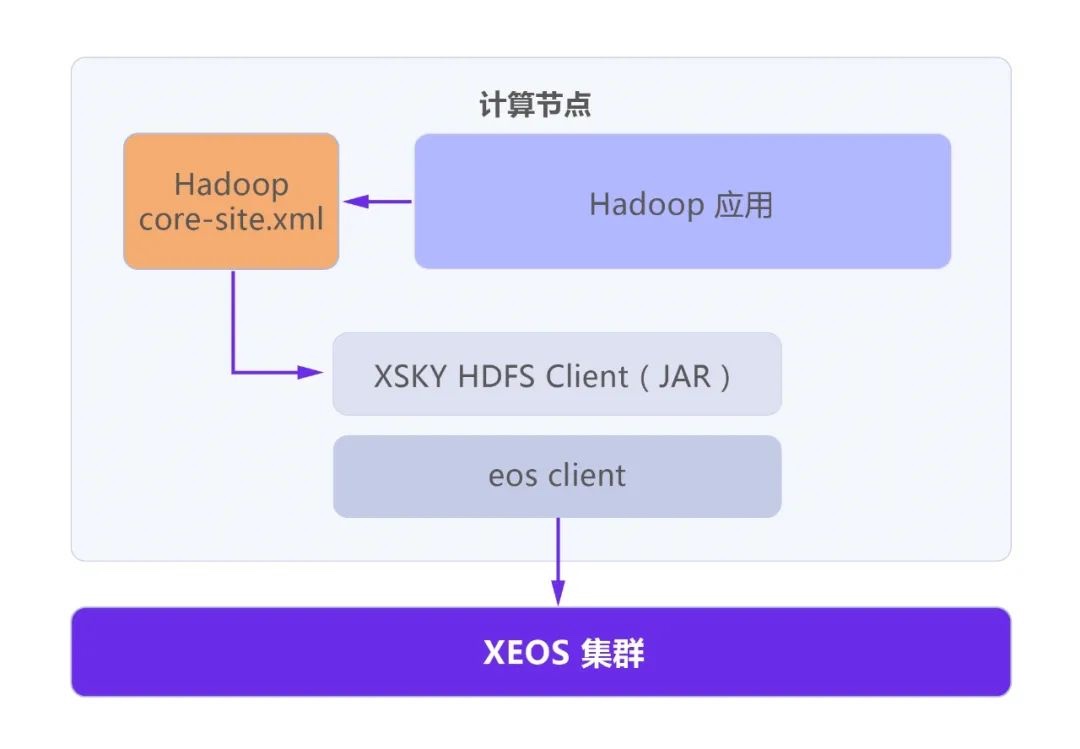
在使用时,需要将XSKY HDFS Client配置到计算节点的core-site.xml文件中。Hadoop应用加载core-site.xml配置后,便会获得scheme与XSKY HDFS Client的映射关系。如访问时使用“eos://localhost/user/dir/”,Hadoop会获取到“eos”这个scheme并通过映射关系,选择XSKY HDFS Client来处理请求。最终XSKY HDFS Client调用XEOS的NFS接口来处理完成与XEOS的通讯。 以YARN(MapReduce2)为例,在Hadoop中使用XEOS的示例如下。JobClient将Job提交给YARN,YARN将Job拆分成多个Map和Reduce子任务并执行。在Map或Reduce阶段均可通过XSKY HDFS Client访问XEOS,进行读写等操作。 
08 XSKY MergeCommitter文件秒合技术
Output Committer 是 Hadoop 中 MapReduce 的提交协议。实际是一组抽象接口,包括 Job Setup、Task Setup、Task Commit、Task Abort、Job Commit、Job Abort、Job Cleanup、Job Recovery。 Hadoop 中 MapReduce 将用户提交的 job 拆分成多个 task (分别是 map task 和 reduce task)并在多个节点上执行这些 task,task 在执行完成后,将执行结果的输出通过 output commit 协议存储于最终的结果目录。 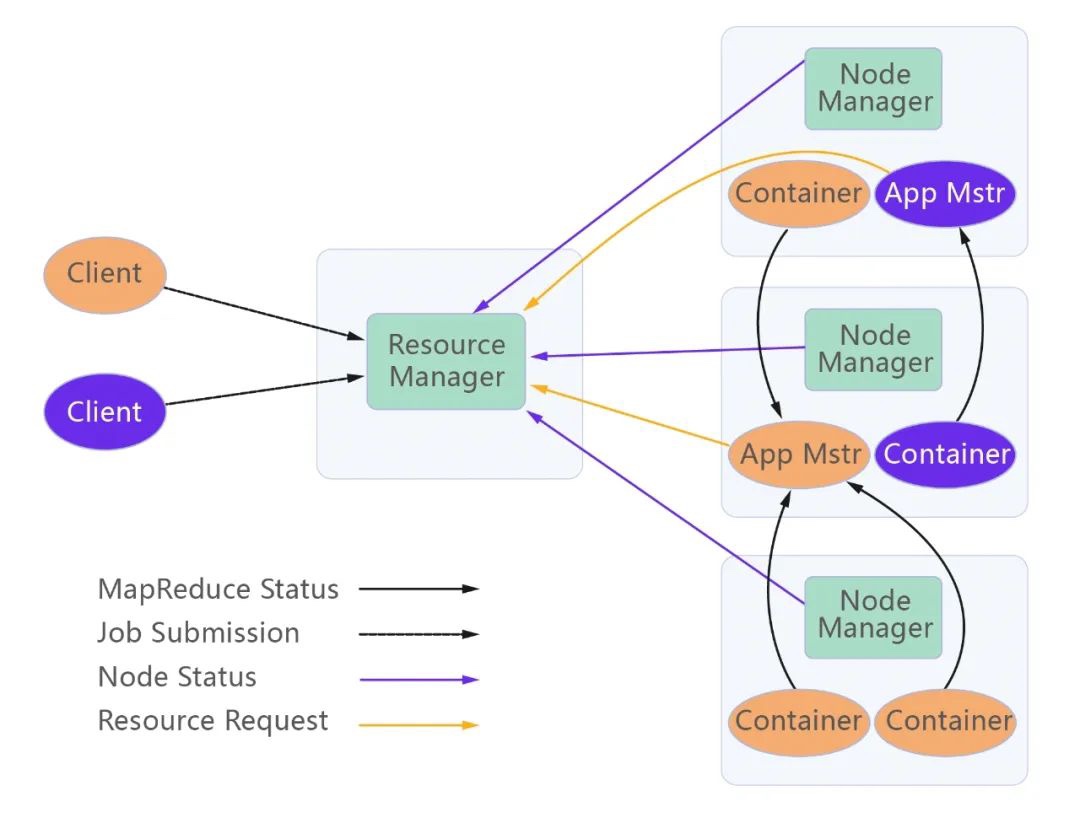
任何 job 端提交工作都将跨集群中的节点执行,并且可能发生在 job 执行的关键部分之外。然而,除非 output commit 协议要求所有 task 等待 job driver 的信号,否则 task 的提交不能在最终目录中实例化它们的输出,可用于将成功 task 的输出提升到可以提交 job 的状态,解决投机性执行和失败问题。
因此 output commit 需要能够处理当 job driver 出现故障并且重新启动时,重新启动的 job driver 仅重新运行未完成的 task;当重新启动的 job 完成时,将恢复已完成 task 的输出以供提交。
FileOuptputCommitter 是 Hadoop 中 MapReduce 默认的 committer。它的算法分为两个版本,分别是 “V1” 和 “V2”。
“V2” 算法与“V1”算法大体流程相似,不同之处是“V2”直接将任务输出由taskAttemptPath 提交到$dest目录。在执行期间,中间数据变得可见。Job失败时,必须删除所有输出并重新启动 job。
与 “真正的” 文件系统相比,S3A 对象存储 (与大多数其他对象类似) 根本不支持 rename()。为了模拟 rename,Hadoop S3A connector 必须将数据复制到目标文件名的新对象中,然后删除原始条目。这个复制可以在服务器端执行,但是由于它要等到集群内的复制完成后才会完成,所以它所花费的时间与数据量成正比。
Rename 开销是最明显的问题,但最危险的是路径列表没有一致性保证。S3对象存储是弱一致性的,是异步操作,所以 copy 操作虽然返回执行成功,但 client 在执行 list 目录时,是有可能看不到这个文件的。如果没有列出文件,commit 操作将不会复制它们,因此它们不会出现在最终输出中。
对于 S3 协议兼容的对象存储的 committer 主要有两种开源实现:Staging Committer 和 Magic Committer。 S3 协议兼容的对象存储在一致性的表现上,大致分为最终一致性(弱一致性)和强一致性两种。Staging Committer 和 Magic Committer 都是偏重于对弱一致性的存储系统的支持。而对于强一致性的 S3 协议兼容的对象存储,是不需要引入一致性组件的。
Staging Committer:该 committer 在是用过程中需要先将数据写入本地,再提交到 S3 对象存储中,效率低下。而且需要引入第三方的强一致性存储系统(如 HDFS),所以会带来架构的复杂性,提高运维难度。 Magic Committer:该 committer 使用分段上传来提交 task 的输出文件,但是并不会区分文件大小,一般情况下建议在对大文件(如 100M以上)使用分段上传来提高上传效率,而 Magic Committer 无论多小的文件都使用分段上传,造成 IO 效率低下。
在 task commit 和 job commit 阶段需要不停的读、写、合并 .pendingset 文件,影响 IO 效率。该 Committer 是在 Hadoop3 版本中发布的,并不支持当前市场主流的 Hadoop2 版本。
XSKY Merge Committer ,通过使用对象存储的自定义元数据,与文件秒合功能解决上述问题。文件秒合可以将一个或多个对象合并为一个新对象,并保存到指定的目录中。这个新对象的内容,是被合并的所有文件内容的集合,按照输入文件列表的顺序组织。并且秒合是一个时间复杂度 O(1) 的原子操作。
09 小结
XSKY HDFS Client从原理上看,功能和性能都要比S3A的要强大很多,在某金融机构的实际测试表现也没有令人失望。
1、性能测试根据中国信息通信研究院的《Hadoop平台性能测试方法》,一般情况下大数据平台性能测试主要考虑四个方面:SQL任务、NoSQL任务、机器学习、批处理。这里主要选择在SQL任务、NoSQL任务、批处理与开源Hadoop平台进行对比测试。
2、用例说明其中批处理用例主要选择了1T数据排序的TeraSort标准测试工具;NoSQL任务选择了使用HBase Blukload工具对400G .csv文件进行数据导入测试;Hive Join的测试使用了500G+500G大表join,500M+500G大小表join,及500M+500G大小表MapJoin几个子测试用例。
3、测试结果XEOS不仅在DFSIO上面表现优异,在SQL、NoSQL、批处理上的性能都有部分提升。结果如下:
而采用XEOS对象存储代替HDFS还具有存算分离的好处,配合XEOS强大的企业特性和灾备能力,XEOS必将成为企业数据湖的理想底座。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞0作者其他文章
评论 0 · 赞 0
评论 1 · 赞 0
评论 0 · 赞 1
评论 0 · 赞 0
评论 0 · 赞 0
添加新评论0 条评论