
常用分布式数据库的分析与比较——NewSQL数据库篇
摘 要:
随着互联网技术的发展,人们对数据库的要求越来越高,新的应用要求数据库不仅具有良好的ACID属性,还要具有良好的扩展性。于是,新一代的数据库——NewSQL数据库应运而生。
业界常用的NewSQL数据库有两种实现方式:1、数据库访问中间件(分库分表)。传统关系型数据库天然具备良好的ACID属性,通过数据库分库分表的方式,满足扩展性要求。应用系统在访问数据库时,首先访问数据库中间件,由中间件根据规则,将数据分散到多个库/表中进行存储,查询时,再将多个库/表的数据聚合在一起,返回给应用。分库分表的数据处理本质上采用的是传统关系型数据库,故常用有存储结构化数据,适用于OLTP应用场景;2、原生分布式数据库方式。该类数据库重新构建,采用分布式部署和分布式存储引擎。由于数据库内部原生支持分布式事务处理与数据切分,故其性能远高于分库分表,且对应用完全透明,使用者无需感知底层数据分布。此外,数据库内核原生具备数据的高可用性和容灾能力。原生分布式数据库适用于OLTP和OLAP的应用场景。
关键词:NewSQL、ACID属性、中间件、原生分布式数据库、OLTP、OLAP、Spanner、F1、OceanBase、TiDB、SequoiaDB
一、 数据库访问中间件(分库分表)
数据库访问中间件(分布分表),是新型分布式数据库的过度阶段。常见的数据库访问中间件有两种形式:客户端程序库和数据库代理服务中间件。
(一) 客户端程序库方式
该方式在客户端安装程序库,通过客户端程序库直接访问数据,该方式的优点是性能高,缺点是对应用有侵入。访问示意图如下: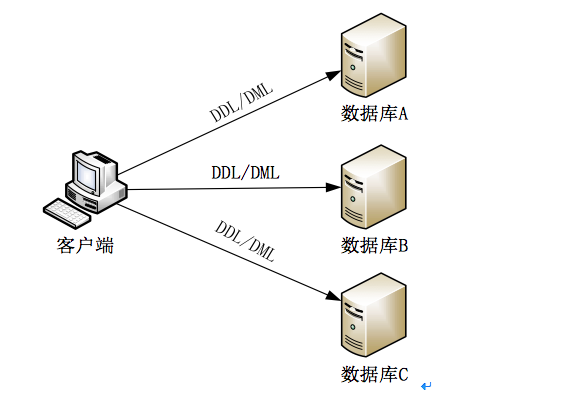
典型客户端程序库中间件如阿里的TDDL,本文以TDDL为例,介绍客户端程序库方式的数据库访问中间件的工作原理。
TDDL采用了客户端库(即Java.jar包)形式,在Jar包中封装了分库分表的逻辑,部署在ibatis、mybatis或者其他ORM框架之下、JDBC Driver之上,是JDBC或持久框架层与底层JDBC Driver之间的交互桥梁。
TDDL的逻辑架构分为三层:Matrix 、Group、Atom。Matrix层负责分库分表路由,SQL语句的解释、优化和执行,事务的管理规则的管理,各个子表查询出来结果集的Merge等;Group层负责数据库读写分离、主备切换、权重的选择、数据保护等功能;Atom层是真正和物理数据库交互,提供数据库配置动态修改能力,包括动态创建,添加,减少数据源等。
当client向数据库发送一条SQL的执行语句时,会优先传递给Matrix层。由Martix 解释 SQL语句、优化,并根据查询条件将SQL路由到各个group;各个group根据权重选择其中一个Atom进行查询;各个Atom再将结果返回给Matrix,Matrix将结果合并返回给client。:
(二) 数据库代理服务中间件。
数据库代理服务中间件部署在客户端与数据库服务器之间,对于客户端而言,它就像数据库服务器,而对于数据库服务器而言,它就像客户端。因所有数据库服务请求都需要经过数据库代理服务中间件,所以,中间件不仅可以记录所有的数据库操作,修改客户端发过来的语句,还可以对数据库的操作进行优化,实现其他如读写分离之类的能力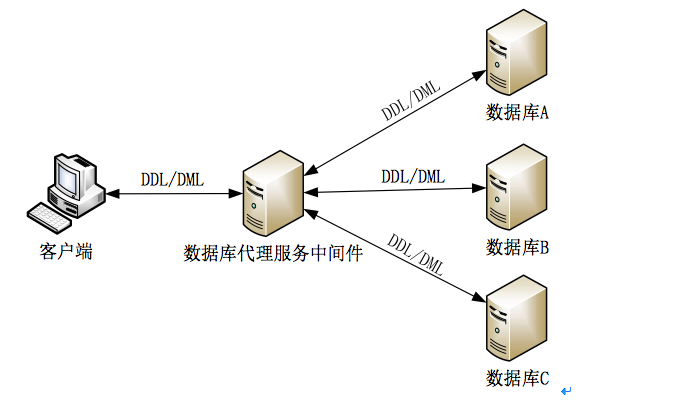
该方式应用程序不需要任何修改,只需把链接指向代理服务器,由代理服务器访问数据库,该方式的优点对应用没有侵入,缺点是性能低。
典型的数据库代理服务中间件有MySQL代理、Cobar、MyCAT、TDSQL等,本文以MySQL代理为例,介绍客户端程序库方式的数据库访问中间件的工作原理。
MySQL代理是MySQL官方提供的MySQL数据库代理服务中间件,其数据查询过程如下:
1、 数据库代理服务中间件收到客户端发送的SQL查询语句;
2、 代理服务中间件对SQL语句进行解析,得到要查询的相关信息,如表名CUSTOMER;
3、 代理服务中间件查询配置信息,获得表CUSTOMER的存储位置信息,如数据库A、B、C;
4、 同时根据解析的情况进行判断,如数据库A、B、C上都可能存在需要查询的数据,则将语句同时发送给数据库A、B、C。此时,如有必要,还可以对SQL语句进行修改。
5、 数据库A、B、C执行收到的SQL语句,然后将查询结果发送给数据库中间件。
6、 中间件收到数据库A、B、C的结果后,将所有的结果汇总起来,根据查询语句的要求,将结果进行合并。
7、 中间件将最后的结果返回给客户端
不同的数据库代理服务中间件,根据其支持的协议,可代理的数据库不同,如Cobar只能代理MySQL数据库,而MyCAT除了可代理MySQL外,还可代理其他关系型数据库吗,如Oracle、SQL Server等。
二、 原生分布式数据库方式
(一) Spanner
Megastore、Spanner都是谷歌推出的分布式数据库,Megastore提供的是半关系型数据模型,支持同一实体组内事务的ACID属性和跨实体组事务的最终一致性,但写操作的吞吐量不高,且缺乏类似SQL的查询语言,于是,谷歌又推出了Spanner。因Spanner是Megastore的下一代产品,在Megastore的基础上进行了优化,故本文只介绍Spanner的技术实现原理
- Spanner的部署架构

相关概念如下: - Universe:指Spanner集群,一个Spanner集群的部署我们称之为一个Universe。一个Universe由若干个Zone组成。
- Zone:是Spanner的基本管理单元,也是物理隔离单元。一个Zone由ZoneMaster、Location proxy和若干个SpanServer组成。一份数据可以在若干个Zone之间同步。
一个数据中心可以划分为一个Zone,或若干个Zone。 - Universemaster:用于监控该Universe中Zone的状态信息;
- l Placement driver:提供跨Zone数据迁移时的管理功能,并自动进行跨Zone的数据迁移。
- Zonemaster:相当于BigTable的Master。管理Spanserver上的数据,负责数据分配。
- Location proxy:存储数据的Location信息。客户端访问数据时,先访问Location Proxy,由此获得数据所在的Spanserver信息。
- Spanserver:相当于BigTable的ThunkServer。用于数据的存储,为Client端提供数据。
2、spanner数据模型
Spanner存储的数据是Key-value。主键为Key,其他列为Value。其数据模型是建立在directory和key-value模型的抽象之上的。一个应用可以在一个universe中建立一个或多个 database,在每个database中建立任意的table。Table中包含行、列、版本等。
3、SpanServer
Spanner的几个概念:
- Tablet:Spanner中的Tablet用于存储数据,是物理的概念,实质上是数据文件,存储在分布式存储Colossus (GFS II)上。因Tablet中存储的KV是String,包含了时间戳,因此天生支持多版本;多个副本之间的数据同步采用Paxos机制。
- Partitons:也是物理概念,在Tablet中,具有连续Key的行组成的存储空间,不同的Partition的key的范围不需要连续。一个Tablet可能包含多个Partitions
- Paxos Group:Paxos Group是逻辑概念。数据以副本(replica)的方式存储在Tablet上。同一组数据的多个副本称为一个Paxos Group。在每个Paxos Group中,都有一个leader,负责数据的读写,其他副本从Leader中复制数据,可支持数据的读请求。
- Directory:是一批连续的、具有相同前缀的key的集合(也叫bucket),Directory也是逻辑概念,是。一个 Paxos group可能会包含多个directory
Directory是数据控制、存储和异动的基本单元,也是记录地理位置的最小单元。同个directory 中的所有数据有相同的副本。当数据在Paxos group之间移动时, 是以directory为单元,整体移动的。如下图所示: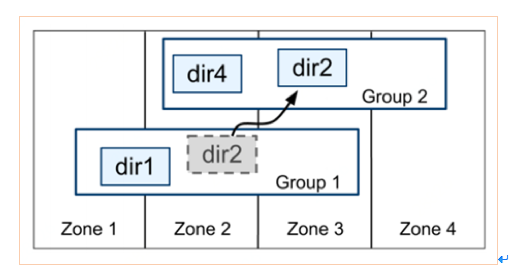
Tablet、Partitions与Paxos Group、Directory之间的关系:
Tablet与Partitions是物理概念,Paxos Group与Directory是逻辑概念。每个Paxos group中可以包含多个directory;每个Tablet可以包含多个partition,
实际使用时,每个Paxos Group与一个Tablet对应,而每个Directory与一个Partition对应。
四者之间的对应关系如下图所示: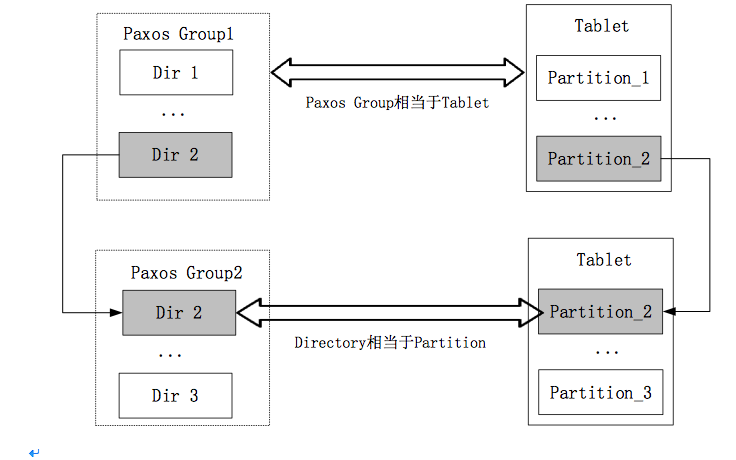
4、TrueTime
TrueTime 认为,任何服务器上获取的时间与实际时间都存在误差,所以时间应该被表述成一个有边界的不确定时间区间,而不是一个时间点,这个时间区间称之为TTinterval。
TrueTime API 主要有三种方法:
TrueTime API实现依赖GFS和原子钟。当GPS失灵的时候,原子钟仍然能保证在相当长的时间内,不会出现偏差。
每个数据中心都有一系列的 time master服务器,配置GPS时钟或原子时钟,为TrueTime提供时钟服务。
5、Spanner并发控制
Spanner使用TrueTime来控制并发,并利用Paxos协议和两阶段提交来保证外部事物的一致性。支持以下几种事务。
- 读写事务
- 只读事务
- 快照读,客户端提供时间戳
- 快照读,客户端提供时间范围
6、Spanner与BigTable, Megastore的比较
- BigTable不能提供较为复杂的Schema,无法实现跨数据中心下数据的强一致性;
- Megastore 支持RDBMS的数据模型,同时也支持同步复制,但吞吐量差;
- Spanner支持临时多版本数据存储,是下一代BigTable,也是Megastore的继任者。
(二) F1
Spanner虽然具有外部一致性、类SQL接口和常见的事务支持,但和传统关系型数据库相比,功能仍不够丰富,F1是在Spanner的基础上,扩展了Spanner的已有特性,成为名副其实的NewSQL数据库。和关系型数据库相比,功能毫不逊色。
F1是谷歌设计的用于支持其核心广告业务的分布式关系型数据库。用Spanner作为其存储引擎。
1、F1部署架构
F1集群包括:F1 master、F1 Server、Slave Pool、Spanner和CFS,各组件功能如下:
- F1 Server:是并行计算组件,用于客户端服务请求的接收,执行、拆分SQL语句,也负责MapReduce任务的执行和分发;
- Slave Pool:也是并行计算组件,负责SQL语句、MapReduce任务的执行
- F1 Master: 负责slave pool健康情况和剩余可用slave数目的监控。
- Spanner:数据库的存储引擎,用于数据存储,同时负责数据的增、删、改、查等操作。
- CFS:分布式文件存储系统,是GFS的升级版
2、数据的读写流程
客户端通过client library,将服务请求通过负载均衡分发到某个F1集群的某个F1 Server,F1 Server收到SQL语句后进行解析。如果收到的SQL可以并行执行,则将该SQL进行分拆,分发到slave pool,再从Spanner上读写数据;如果收到的SQL不可并行执行,则由该F1 Server读写Spanner上的数据。
大部分的F1是无状态的,客户端可以发送不同请求到不同F1 server,当客户端事务使用悲观锁时,则不能进行任务的分发,后续事务只能在这台F1 server上处理。
除了SQL外,MapReduce任务也可用F1来分布式执行。
3、F1的技术特点
- 支持关系型数据库相似的关系模式以及表之间层级性和Protocol Buffer;
- F1支持本地索引和全局索引;
- 支持ACID事务,包括快照事务、悲观事务、乐观事务;
- 具备7×24小时的高可用性、很强的扩展性和很高的吞吐量;
- 数据可以同时提供强一致性和弱一致;
- 支持SQL
(三) OceanBase
1、OceanBase的设计思路:
- OceanBase将数据分成两部分:一部分是相对早些的数据(如一天以前)称为基准数据,另一部分是最近更新的数据,称为增量数据。
- 在每天的业务低估时,将增量数据合并到基准数据中,形成新的基准数据;
- 基准数据被分片存储到多台服务器上;
- 增量数据的处理则由一台服务器完成;
- 查询时,将基准数据和增量数据合并,修改时,只修改增量数据;
- 因为增量数据由一台服务器处理,绕开了分布式事务的难点。
2、数据模型与数据结构
OceanBase的数据采用关系模型,支持SQL92的一个子集,支持大部分的表单操作,也支持表间连接,支持事务语句。
OceanBase底层存储的是一个海量的哈希表,每行数据都有一个行键,根据行键的范围进行分片,每片称为一个Tablet。数据分为基准数据和增量数据两个部分,基准数据分布在多台ChunkServer上,增量数据全部存放在一台UpdateServer上。
增量数据的数据结构如下:
- 增量数据按照时间从旧到新划分为多个版本;
- 最新版本的数据为一颗内存中的B+树,称为Active Memtable;
- 用户的更新操作写入Active Memtable,到达一定大小后,原有的Active Memtable将被冻结,并开启新的Active Memtable接受更新操作;
- 冻结的Memtable将以SSTable的形式转储到SSD中持久化;
- 每个SSTable内部按主键范围有序划分为多个块并内建块索引;
- UpdateServer支持主备,增量数据通常为2个副本,每个副本支持RAID1存储;
基准数据的数据结构如下:
- 每个表格按照主键组成一颗分布式B+树,主键由若干列组成;
- 每个叶子节点称为一个子表(tablet),包含一个或者多个SSTable;
- 每个SSTable内部按主键范围有序划分为多个块(block)并内建块索引(block index);
- 数据压缩以块为单位,压缩算法由用户指定并可随时变更;
- 叶子节点可能合并或者分裂;
- 所有叶子节点基本上是均匀的,随机地分布在多台ChunkServer机器上;
- 通常情况下每个叶子节点有2~ 3个副本;
- 叶子节点是负载平衡和任务调度的基本单元,支持bloom filter过滤;
3、OceanBase架构
OceanBase集群包含根服务器、合并服务器、数据块服务器和更新服务器,整体架构图如下:
OceanBase各功能组件功能如下:
- OceanBase客户端:OceanBase客户端与合并服务器通讯支持Mysql客户端、Java客户端和C客户端三种方式,而与更新服务器通信只支持Java客户端和C客户端:故基于MySQL数据库开发的应用程序、工具能够直接迁移到OceanBase
- 数据块服务器:存储OceanBase系统的基准数据。基准数据一般存储两份或者三份,可配置。
数据块服务器功能包括:存储多个tablet、提供读取服务、执行定期合并以及数据分发。 - 根服务器:维护和管理系统中的元数据信息,如Tablet的分布信息、更新服务器地址、数据块服务器地址、表的模式信息等。此外,根服务器还管理管理集群中的所有服务器,子表(tablet)数据分布以及副本管理。 RootServer一般为一主一备,主备之间数据强同步。
根服务器功能主要包括:集群管理、数据分布以及副本管理。 - 更新服务器:存储OceanBase系统的增量更新数据,并处理来自客户端的所有更新(增、删、改)请求,提供跨行跨表事务,以及快速的查询、修改。更新服务器上的数据会定期合并到数据块服务器上的基准数据中。更新服务器一般为一主一备,主备之间可以配置不同的同步模式。 部署时,更新服务进程和根服务进程往往共用物理服务器。
更新服务器是集群中唯一能够接受写入的模块。更新操作首先写入到内存表,当内存表的数据量达到指定值时,生成快照文件并转储到SSD中。 快照文件为SSTable。 - 合并服务器:接收并解析用户的SQL请求,经过词法分析、语法分析、查询优化等一系列操作后转发给相应的数据块服务器或者更新服务器。如果请求的数据分布在多台数据块服务器上,合并服务器还需要对多台数据块服务器返回的结果进行合并。 客户端和合并服务器之间采用原生的MySQL通信协议,MySQL客户端可以直接访问合并服务器。
MergeServer的功能主要包括:协议解析、SQL解析、请求转发、结果合并、多表操作等。
4、客户端变更(增、删、改)请求的处理过程
- 客户端向根服务器发送请求,查询更新服务器地址
- 根服务器查询自己的元数据,返回更新服务器地址给客户端
- 客户端发送变更请求给更新服务器
- 收到变更请求后,更新服务器更新自己维护的内存记录,返回更新成功。
5、客户端查询请求的处理过程
- 客户端向根服务器发送请求,查询合并服务器地址。请求中有欲查询的行键
- 根服务器查询自己的元数据,返回处理相应行键的合并服务器地址给客户端
- 客户端发送查询请求给合并服务器,请求中有欲查询的行键
- 收到查询请求后,合并服务器向根服务器查询负责某行键的数据块服务器地址
- 根服务器查询自己的元数据,返回处理相应行键的数据块服务器地址给合并服务器
- 合并服务器向数据块服务器查询某行键的基准数据
- 数据块服务器向合并服务器返回基准数据
- 合并服务器向更新服务器查询某行键的增量数据
- 更新服务器向合并服务器返回增量数据
- 合并服务器将基准数据和增量数据进行合并,然后将查询结果返回给客户端库
6、定期合并&数据分发
定期合并和数据分发都将更新服务器中的增量更新数据分发到数据块服务器中,过程如下:
- 更新服务器冻结当前活跃内存表,即Active Memtable,生产冻结内存表,并开启新的内存表,后续的更新操作都写在新的活跃内存表中
- 更新服务器通知根服务器数据版本发生变化,然后根服务器通过心跳消息通知数据库服务器,
- 每台数据块服务器定期启动合并或者数据分发操作,从更新服务器获取每个Tablet对应的增量更新数据。
定期合并与数据分发两者之间的不同点在于,数据分发过程中数据块服务器只是将更新服务器中冻结内存表中的增量更新数据缓存到本地,而定期合并过程中数据块服务器需要将本地SSTable中的基准数据与冻结内存表的增量更新数据执行一次多路归并,融合后生成新的基准数据并存放到新的SSTable中。定期合并对系统服务能力影响很大,往往安排在每天服务低峰期执行,而数据分发可以不受限制。
7、OceanBase与谷歌Bigtable、Megastore、Spanner的比较
- OceanBase与Bigtable一样,存储的是海量哈希表,但Bigtable不支持跨行的事务,而OceanBase则支持
- Bigtable建立在GFS上,数据库的可靠性(多副本)由GFS实现,而OCeanBase直接建立在Linux,需要解决数据的多副本问题
- Bigtable存储的是SSTable文件,采用LSM结构存储数据,而OceanBase采用的是更新服务器和数据块服务器方式存储数据
- 为了支持跨行事务,Megastore采用了Paxos协议,Spanner采用TrueTime API,而OceanBase采用单个更新服务器方式。
(四) TiDB
TiDB 是 PingCAP 公司受 Google Spanner / F1 论文启发而设计的开源分布式数据库,结合了传统的 RDBMS 和NoSQL 的最佳特性。TiDB 兼容 MySQL,支持无限的水平扩展,具备强一致性和高可用性。TiDB 的目标是为 OLTP(Online Transactional Processing) 和 OLAP (Online Analytical Processing) 场景提供一站式的解决方案。
1、TiDb 整体架构
TiDB采用计算、存储分离的架构,主要有三部分组件构成,各组件功能如下:
- TiDB Server。TiDB Server 负责接收 SQL 请求,处理 SQL 相关的逻辑,并通过 PD 找到存储计算所需数据的 TiKV 地址,最终从TiKV获取数据。
TiDB Server无状态,其本身并不存储数据,节点之间完全对等,只负责计算,可以无限水平扩展。 - PD Server(Placement Driver)。集群管理模块,其作用:一是存储集群的元信息(某个 Key 存储在哪个 TiKV 节点);二是对 TiKV 集群进行调度和负载均衡(如数据的迁移、Raft group leader的迁移等);三是分配全局唯一且递增的事务 ID。
PD 是一个集群,需要部署奇数个节点,一般线上推荐至少部署 3 个节点。 - TiKV Server。负责数据的存储。
TiKV 是分布式、支持事务的 Key-Value 存储引擎。数据存储的基本单位是 Region。每个 Region 负责存储一个 Key Range的数据,每个 TiKV 节点可存储多个 Region 。
2、TiDB数据的读写流程
- 用户的 SQL 请求直接或者通过 Load Balancer 发送到 tidb-server;
- tidb-server 解析 MySQL Protocol Packet,获取请求内容,然后做语法解析、完成SQL与KV的映射、制定和优化查询计划;
- TiDBServer向PDserver查询该SQL语句对应KV所涉及的TiKV Server,返回所在的TiKVServer位置信息;
- TiDBServer向相应的TiKVServer获取数据,并执行查询计划获取;
- tidb-server将查询结果返回给用户。
3、TiKV Server的技术特性:
1) 数据模型
TiKV 数据选择的是 Key-Value 模型,并且提供有序遍历方法。实质上存储的是键值对
2) 存储引擎
TiDB采用RocksDB作为其存储引擎,关于RocksDB的技术原理,参见《常用NoSQL数据库的分析与比较》一文
1) 数据一致性和容灾
TiDB采用Raft保持副本间的数据一致和容灾,副本以region为基本单元进行管理。不同节点上的多个 Region 构成一个 RaftGroup,互为副本。Raft主要作用是Leader 选举、成员变更、日志复制
数据在多个 TiKV 之间的负载均衡,也是以 Region 为单位,由 PD进行 调度。
2) 数据的分片策略
KV系统的数据分片策略同常有两种:一种是按照Key做Hash,根据Hash值选择对应的存储节点;另一种是按Key的范围进行分片,将某一段连续的 Key划分为一个region,再将region按一定的策略分散到不同的存储节点上。
TiKV 选择了第二种方式。
3) TiDB采用MVCC避免TiDB数据并行写时的冲突
4) 事务一致性。TiKV 的事务采用的是 Percolator 模型,并且做了大量的优化。
4、关系模型与Key-Value模型的映射
关系型数据库按表、行、索进行数据的组织、存储和操作,而TiKV是按Key-Value进行数据的组织、存储和操作,故需建立二者之间的映射关系。
TiDB 为每个表分配一个 TableID,每一个索引分配一个 IndexID,每一行分配一个 RowID(如果表有整数型的 Primary Key,那么会用 Primary Key 的值当做 RowID),其中 TableID 在整个集群内唯一,IndexID/RowID 在表内唯一,int64 类型。TiDB为表、行、索引制定了相关编码规则:
1) 行—键值对的编码规则:
Key: tablePrefix{tableID}_recordPrefixSep{rowID}
Value: [col1, col2, col3, col4]
其中 Key 的 tablePrefix、recordPrefixSep都是特定的字符串常量,用于在 KV 空间内区分其他数据。
2) 唯一索引—键值对的编码规则:
Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue
Value: rowID
3) 非唯一索引—键值对的编码规则:
Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue_rowID
Value: null
5、Sql到TIDB数据的映射
按以上编码规则构建键值对后,我们对数据库的Insert/Update/Delete/Select操作,就转化成对KV数据库的相应操作。
1) Insert/Update/Delete
这类语句处理简单,只需要Insert/Update/Delete相应的行的同时,建立/更新/删除相应的索引。
2) select语句复杂,分以下几种情况:
- 不带条件的查询,如下:select * from table;这种查询只需要提供table就行,是个Range映射;
- 带主键或唯一索引条件的点查:select * from table where id=100;这种查询映射:tableid + rowid即可;
- 带索引条件的范围查:select * from table where name='tom';这种查询映射:tableid + indexid + indexvalue ,这样就能查出多条数据;
- 带条件的Range查:select * from table where age >30 and age <40;这种查询映射:tableid + indexid + indexvalue(30) ~ tableid + indexid + indexvalue(40);
6、TiDB 的核心特点:
- 高度兼容 MySQL。大多数情况下,无需修改代码即可从 MySQL 轻松迁移至 TiDB,分库分表后的 MySQL 集群亦可通过 TiDB 工具进行实时迁移。
- 很强的水平扩展能力,包括计算能力和存储能力。通过添加TiDB Server 节点,提高整体的处理能力,提供更高的吞吐。通过部署更多的 TiKV Server 节点,解决海量数据的存储问题
- 支持标准的 ACID 事务。
- 提供真正金融级的高可用。支持数据的强一致性,且在不丢失大多数副本的前提下,可以实现故障的自动恢复 (auto-failover),无需人工介入。
- 一站式 HTAP 解决方案。TiDB 作为典型的 OLTP 行存数据库,同时兼具强大的 OLAP 性能,配合 TiSpark,可提供一站式 HTAP解决方案,一份存储同时处理OLTP & OLAP(OLAP、OLTP的介绍和比较 )无需传统繁琐的 ETL 过程。
- 云原生 SQL 数据库。TiDB 是为云而设计的数据库,同 Kubernetes (十分钟带你理解Kubernetes核心概念 )深度耦合,支持公有云、私有云和混合云,使部署、配置和维护变得十分简单。
(五) SequoiaDB
SequoiaDB是由巨杉公司研发的国产、开源、原生分布式数据库,采用计算与存储分离架构,支持完整 ACID属性,具备弹性扩展、高并发和高可用特性。
1、SequoiaDB架构
巨杉数据库分数据库实例层和数据库存储引擎层两部分,数据库实例层支持 MySQL、PostgreSQL 和 SparkSQL的结构化实例,以及S3、JSON、Posix FS的非结构化实例,数据库存储引擎层包含三大组件:协调节点、数据节点和编目节点。架构图如下:
1) 数据库实例层
- 结构化实例兼容性,
大部分的国产数据库兼容MySQL,而巨杉支持常用的开源数据库(MySQL、PostgreSQL、SparkSQL)。为了实现与常用的开源数据库,巨杉数据库增加了SQL层。都有相应的安装包。对相应的开源软件进行了修改、定制。
Ø 与MySQL的兼容。在MySQL技术栈中,增加SequoiaDB存储引擎,用于替换 innoDB,从而实现与MySQL 100%的兼容。
Ø 与PostgreSQL的兼容,采用外部表方式
Ø 与SparkSQL的兼容。通过增加SequoiaDB存储引擎(用于替换HIVE)实现。另外,SparkSQL依赖SequoiaDB 的索引能力,可以拥有快速的索引查询能力。同时在SparkSQL引擎中,增加了执行计划分析器,使得SparkSQL 实例能够自动根据查询的条件,智能选择索引扫描还是表扫描。 - 非结构化实例兼容性
服务器端提供S3、JSON、Posix相应的接口,客户端按接口标准,直接访问SequoiaDB。另外,JSON 实例接口,能够完全兼容MongoDB 驱动与语法。
2) 数据库存储引擎层
- 协调节点
不存储任何用户数据。作为外部访问的接入与请求分发节点,协调节点将用户请求分发至相应的数据节点,最终合并数据节点的结果应答对外进行响应。 - 编目节点
主要存储系统的节点信息、用户信息、分区信息以及对象定义等元数据。在特定操作下,协调节点与数据节点均会向编目节点请求元数据信息,以感知数据的分布规律和校验请求的正确性。 - 数据节点
数据节点为用户数据的物理存储节点,海量数据通过分片切分的方式被分散至不同的数据节点。在关系型与 JSON 数据库实例中,每一条记录会被完整地存放在其中一个或多个数据节点中;而在对象存储实例中,每一个文件将会依据数据页大小被拆分成多个数据块,并被分散至不同的数据节点进行存放。
2、SQL语句的执行过程
1) SQL层
完成SQL语句的解析,如数据库、表、行、索引建立、查询等语句,生成执行计划,并将SQL语句翻译成SequoiaDB语句,下发至协调节点;
2) 协调节点
将分区键(id属性)映射为一个hash值,随后查看编目节点的集合信息,确认这个hash值在哪个数据组当中。将这条数据发往该数据节点,
3) 数据节点
负责SDB语句的执行,数据、索引、日志的管理。
SQL实例的元数据保存在本地服务器,多个实例之间的元数据信息通过audit log,实现多个实例之间元数据的同步
3、SequoiaDB数据架构
- 文档——记录
SequoiaDB采用非关系的数据模型,是文档型数据库,数据为XML、JSON等格式。一个文档为一个记录,支持嵌套结构与数组。
一条记录就是一个对象,其值可以是数组和其他如字符串、数值、日期等 - 集合——表
集合是数据库中存放文档的逻辑对象、由“<集合空间名>.<集合名>”构成。除名称外,每个集合还拥有分区键、分区类型、写副本数、数据压缩属性: - 集合空间——数据库
集合空间是数据库中存放集合的物理对象,一个集合空间可以包含4096个集合
一个集合空间对应一个数据存储文件和一个索引存储文件(数据文件名格式为“<集合空间名>.1.data”、索引文件名格式为“<集合空间名>.1.idx”)
一个数据节点可以包含16384个集合空间。 - l 域——用于多模管理
由若干复制组组成的逻辑单元, 一个域可以包含多个集合空间,每个域都可以根据定义好的策略自动管理所属数据,如数据切片和数据隔离。
4、存储架构
数据的存储有两种格式:记录存储格式和对象存储格式
1) 记录存储格式——BSON存储
- 对于结构化数据,单条记录较小,SequoiaDB采用行存储方式存储记录,数据库内部使用BSON。
- 一条记录(文档)由一个或多个字段构成,每个字段分为键与值两个部分,一条记录最大长度为16M。(一条记录就是一个对象)
- 每个字段的键(字段名)为字符串,而值则可以为数字,字符串,嵌套 JSON,嵌套数组等对象。
- 物理上,采用BSON 数据格式记录数据,每个BOSN由若干个数据页组成,每个数据页大小由PageSize 参数设置,默认为 65536(64KB),一个BSON最大为16MB,由多个连续的page组成extent
- 物理上,采用BSON格式记录数据。一个BOSN由1个或若干个连续的Page页组成(多个连续的Page与组成一个extent)。对于小记录,一个page可以包含多条记录,对于大于PageSize的记录,一个extent存储一条大记录。
- 每个数据页大小由PageSize 参数设置,默认为 65536(64KB),一个BSON最大为16MB,
- 可以指定几个键作为分区键,存储时,根据分区键,采用一致性HASH函数,将数据存储到不同的复制组,编目节点记录复制组与hash分区的映射
2) 对象存储格式——LOB块存储
- 对于非结构化数据,单条记录数据较大,SequoiaDB采用对象存储方式存储记录,数据存储采用LOB块存储.
- LOB 和BSON的调用方式和存储方式都不同,实际使用时,需要用户自己指定,SequoiaDB无法自动匹配。
- 一条记录就是一个LOB对象,LOB 记录的大小不受限制。
- 当记录大小超过指定值时,SequoiaDB会自动按照LobPageSize(如64,128KB)的数据块进行切分,
- 每条LOB 记录都有一个OID,分片时,每一个分片会加分片序号
- OID和分片序号组成分区键,存储时,根据分区键进行HASH计算,读编目节点上的分区信息,再根据OID+分区组信息,把分区数据下发到数据节点(oid+分片号+分片的数据)
SequoiaDB的LOB存储结构分为元数据文件(LOBM)与数据文件(LOBD)。
- l 元数据文件存储整个LOB数据文件的元数据模型,包括每个页的空闲状况、散列桶、以及数据映射表等一系列数据结构。
- l 数据文件存储用户真实数据。
5、数据的分区策略:
SequoiaDB支持三种数据分区方式:
- 水平分区:也叫一致性散列分区,即一个集合中的数据切分到多个复制组中,以达到并行计算的目的,这种数据切分的方式称为水平分区。
- 垂直分区:又称为集合分区或纵向分区,将一个集合全局关系的属性分成若干子集,并在这些子集上作投影运算,将这些子集映射到另外的集合上,从而实现集合关系的垂直切分。
- 多维分区:也可以称为混合分区,采用以上两种分区方式。
6、SequoiaDB的事务支持能力和并发控制机制
SequoiaDB分布式事务采用二段提交(2PC)的机制。其中采用全局时间来实现全局事务的统一协调管理,使分布式集群中的不同节点进行事务的统一操作。在整个事务操作过程中,客户端发起的事务分为三个部分:事务开始;事务的增删改查操作;事务完成。
SequoiaDB采用MVCC实现并发控制
7、关于数据的读写过程:
1) 结构化数据的写流程
- SQL实例层收到SQL语句,进行语法解析、制定SQL执行计划,并将SQL语句翻译成SequoiaDB语句,下发给协调节点
- 协调节点收到SequoiaDB语句后,对分区键进行HASH计算,根据hash值,将数据下发到不同的数据节点的复制组。
- 数据节点复制组写入日志和数据
2) 结构化数据的读流程
- SQL实例层收到SQL语句,进行语法解析、制定SQL执行计划,并将SQL语句翻译成SequoiaDB语句,下发给协调节点
- 协调节点收到SequoiaDB语句,对分区键进行HASH计算,协调节点根据hash值,先在本地缓存上查找该HASH分区对应的数据节点复制组信息,如存在,则在对应数据节点上读取数据;如不存在,则到编目节点查询,然后再从对应的数据节点上读取数据
3) 对象的写入流程 - 协调节点收到来自客户端的请求,如果文件小于或等于LobPageSize,则不进行分片,(分片序号为0);如果文件大于LobPageSize,则对文件进行切分。
- 协调节点根据OID和数据的分片序号进行hash计算。
- 根据HASH(oid+分片号)值,在编目节点上找到分片数据对应的分区组信息
- 根据OID+分区组信息,把分区数据下发到数据节点(oid+分片号+分片的数据)
- 数据节点接收到协调节点发送的数据请求,完成日志与数据(包括LobM和LobD)的写入
4) 对象的读取流程
对象数据的读取流程与写入流程类似。
- 协调节点收到来自客户端的请求,对OID和0(分片号)进行HASH计算;
- 根据HASH(oid+分片号)值,在编目节点上找到所需读取数据的分区组信息;
- 根据OID+分区组信息,找到第0片对应的数据节点,读取第0片数据,获取该数据的数据分片信息(分片数,文件大小);
- 如果不止一个分片,则继续以下操作;
- 协调节点根据OID和数据的分片序号进行hash计算。
- 根据HASH(oid+分片号)值,在编目节点上找到分片数据对应的分区组信息;
- 根据OID+分区组信息,把数据请求下发到数据节点(oid+分片号+分片的数据);
- 数据节点接收到协调节点的数据请求,读取数据返回给协调节点;
- 协调节点合并数据,并返回给调用者。
(六) 几种常见NewSQL数据库的分析与比较

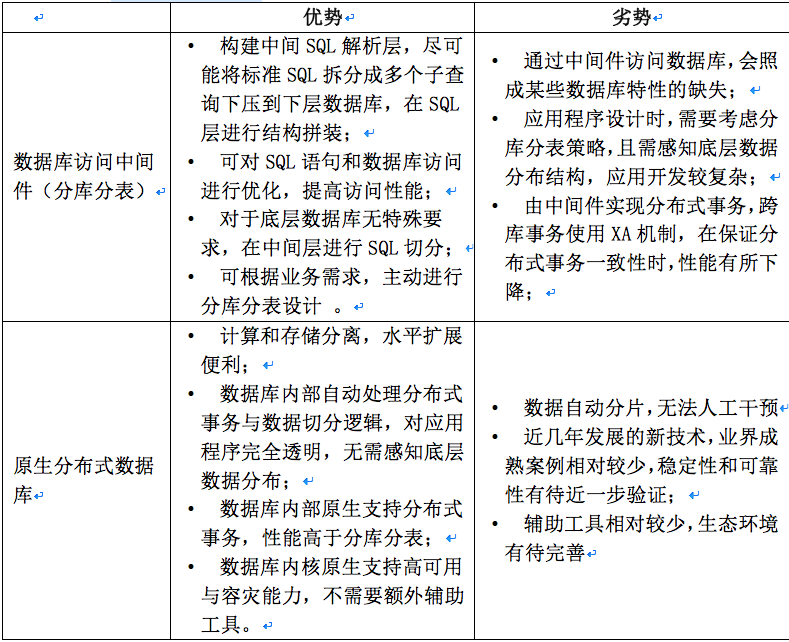
三、 数据库访问中间件(分库分表)与原生分布式数据库的优、劣比较
四、 原生分布式数据库的选型要求
在选择NewSQL数据库时,我们既要考虑到与传统技术的兼容性,也要考虑到新技术的前瞻性,具体包括以下几个方面:
- ACID支持性。因NewSQL数据库要用于处理OLTP,故要求对ACID属性有良好的支持;
- SQL的兼容性。为了降低运维和开发成本,我们需要NewSQL数据库与传统SQL数据库(如MySQL、PostgreSQL)有良好的兼容性。兼容性越好,应用系统从传统SQL数据库迁移到NewSQL数据库就越方便。如能做到100%的兼容,就可实现应用系统的无缝迁移。
- 分布式与扩展性。分布式是新一代架构的基础,扩展性能应对海量的数据量。因此,分布式与扩展性是新一代NewSQL数据库的基本要求
- OLTP和OLAP的支持。NewSQL数据库既要能处理OLTP,同时也能处理OLAP,适应更多的数据应用需求
- Multi-model与多租户。NewSQL数据库应该是Multi-model多模的数据库引擎,能处理多种数据的应用场景,符合微服务和云数据库的架构理念。
常用分布式数据库的分析与比较系列篇
常用分布式数据库的分析与比较 ——NoSQL数据库:
https://www.talkwithtrend.com/Article/247707
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞11作者其他文章
评论 3 · 赞 15
评论 3 · 赞 11
评论 3 · 赞 13
评论 2 · 赞 21
评论 1 · 赞 9
添加新评论2 条评论
2022-10-10 13:58
2020-04-20 11:46