金融业全链路日志分析解决方案
您是否了解运维环境的网络架构和业务系统架构?当业务升级或变更时,是否对已有的架构图及时作出更新?当发生故障时,是否能够快速判断哪个业务系统模块或接口出现了问题,是否能够快速判断故障影响范围?
要回答以上问题,就需要对各业务的调用关系有着精准、实时的掌握,但在实际工作中,即使是业务系统开发者,也很难清楚地说出某个服务的调用链路,况且服务调用链路还是动态变化的,遇到问题也只能去查看代码。
随着微服务、容器等新型架构技术的流行,分布式系统环境的调用链追踪问题也变得愈加复杂。2010年,谷歌开源了其内部使用的分布式追踪系统Dapper,此后很多企业和组织发布了各自的分布式追踪系统,其中比较知名的开源项目包括Zipkin、Pinpoint等。
链路追踪的概念原理
在这里,我们对链路追踪、调用链、全链路、分布式链路追踪的概念不做区分,可以理解为整个链路,一个链路会经过如下图的调用过程:

典型的业务调用链示意图
该图表示一个最典型的请求调用过程,所谓链路就是把(1-6)这6个环节串连起来。在进行链路分析时,需要为每次请求定义一个唯一标识traceid,这样才能根据traceid查出本次请求调用的所有服务。
图中标示的 (1-6) 分别代表两服务之间的一个请求-应答对,我们把它定义为一个span,每个span包含以下字段:
- spanid:请求-应答对的唯一标识;
- name:span的名称;
- parentspanid:父span的id,根据spanid能区分调用的先后顺序,但无法体现调用层级关系,例如上图中多个服务,可能是逐级调用的链条,也可能是同时被同一个服务调用,应该每次都用parentspanid记录下是谁调用的;
- timestamp:span的起止时间戳(starttime、endtime);
- duration:span的持续时间;
- other fields:成功状态status、错误类型errortype等。
有了timestamp字段,就可以计算出从服务调用到服务返回的总耗时,但是这个时间包含了服务的执行时间和网络延迟,有时候我们需要区分出这两类时间以方便做针对性优化。那如何计算网络延迟呢?我们可以把调用和返回的过程分为以下四个事件:
- Client Sent,cs事件,指客户端发起调用请求到服务端;
- Server Received,sr事件,指服务端接收到了客户端的调用请求;
- Server Sent,ss事件,指服务端完成了处理,将信息返回给客户端;
Client Received,cr事件,指客户端接收到了服务端的返回信息。
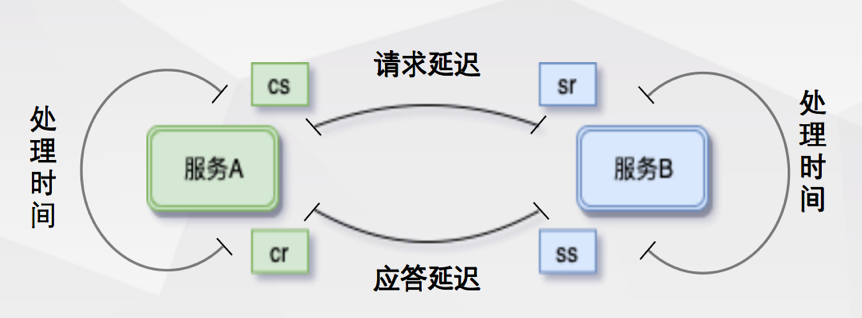
四类事件示意图
我们将span的四个基本事件补充到调用链图上,得到以下图示:

包含四类调用事件的调用链图
在上图中,对服务器Service0来说,会产生两个事件,一个是发起事件cs,另一个是接收事件cr。对Service1来说,首先要接收Service0请求,即事件sr,当处理完成时,作为服务端对服务器Service0进行响应,即事件ss。其它服务之间的交互事件以此类推。
规范地记录以上日志,通过日志易SPL(Search Processing Language)进行分析统计,进而实现可视化呈现,将帮助金融企业更好地监控业务调用状态及健康度,快速实现故障定位,分析及优化业务性能瓶颈。
调用链分析的实现效果
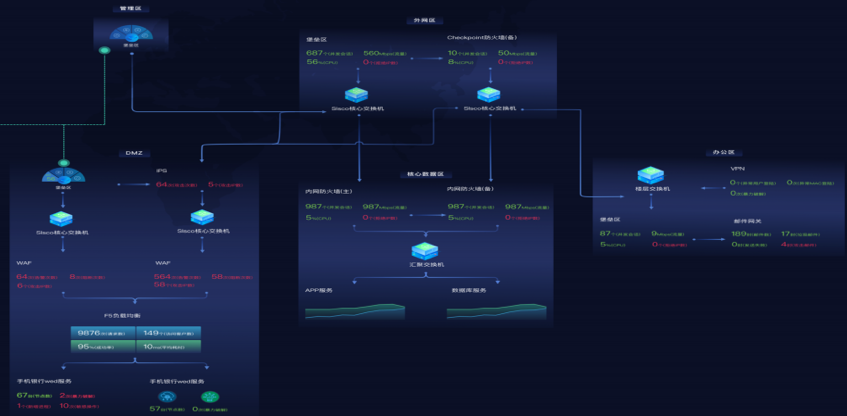
01 静态拓扑
静态拓扑是从系统或网络结构层面上进行呈现,能体现业务系统的架构、从上游到下游的流转、分流的情况,每个节点上包括曲线、指标统计等信息。在运维以及安全态势方面,指标统计可以发现异常问题。
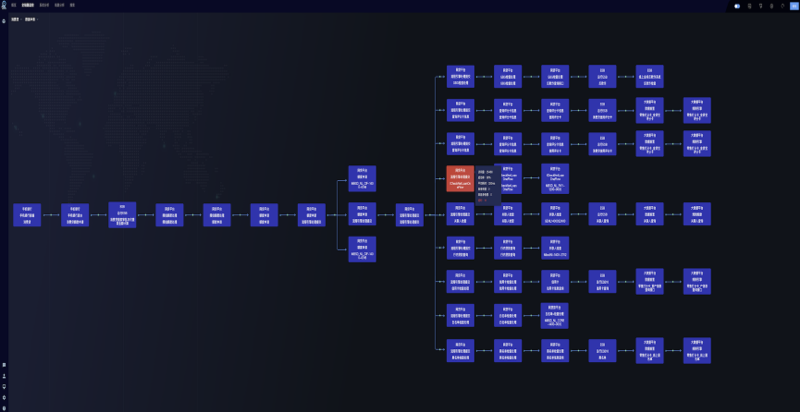
02 动态拓扑
例如下图是基于日志改造的链路动态自动拓扑图,我们可以看到一笔交易经历的各个接口,通过选择不同的交易业务类型,动态拓扑图会自动的展示1分钟内这类交易所有的流程。
03 链路+业务日志分析
链路分析日志需要和业务日志做联动,业务日志包括系统分析日志以及追溯涉及的日志,调用链日志包括全链路监控的拓扑以及单笔调用链和呈现方式。全链路交易监控由五大组成部分:
全局概览
通过系统维度、产品维度、异常维度三大维度展示整体运行状况。
- 系统维度呈现的是成功率的同环比,可以钻取到每个系统专题分析页面;
- 产品维度呈现的是黄金指标,比如交易量、平均耗时、成功率、错误等指标;
- 异常维度呈现的是发现问题的概览统计,它按系统维度对错误进行趋势图展示,可以钻取到链路分析页面。
全链路监控
通过动态拓扑图形式(即 02 动态拓扑)对整个交易路径进行全局监控,异常节点快速标识。
- 宏观监控:监控交易的接口级运行状况;
- 指标统计:将接口的调用量、成功率、平均耗时、自身错误、非自身错误、超时错误等指标做统计,进行浮窗展示;
- 异常标注:当出现不同错误时,可以用不同颜色来标记;
- 历史追溯:追溯时间轴历史及标注,比如历史拓扑播放、时间轴异常点标记、已知异常标注等。
系统分析
对单系统的关键指标进行接口级分析展示。比如可以对系统调用总量、系统调用失败总量、当前耗时最高接口及耗时、接口错误类型统计、接口平均耗时等指标进行分析。
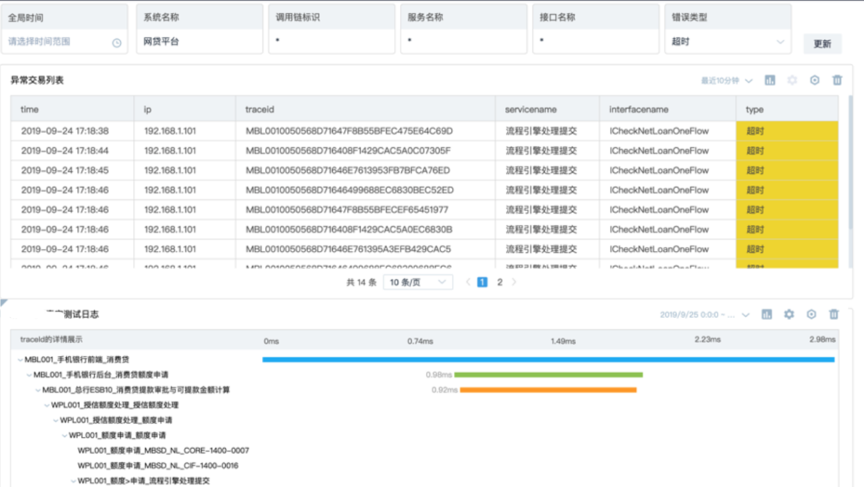
链路分析
通过关键性信息针对单笔交易进行调用链分析,快速定位到异常主机和接口。可以进行字段过滤筛选,呈现单笔交易跟踪链视图等。
追溯
全链路原始日志查询。例如,可通过remask字段进行相应关联日志的查询。
全链路分析的价值
1 可观察性
Logging、Tracing、Metrics融合,提升服务可观察性;
2 开发测试及链路优化
异常监控数据二次统计分析,优化异常节点;
开发过程中查看关联模块的日志和作为测试提单线索;
3 拓扑模式异常检测
拓扑结构形成基线,异常发现与告警;
影响范围快速确认,启动应急预案;
4 个例分析及宏观监控
点面结合,快速故障定位;
统计为多维数据用于监控告警和原因分析。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞0作者其他文章
评论 0 · 赞 0
评论 0 · 赞 0
评论 0 · 赞 0
评论 0 · 赞 0
评论 0 · 赞 0
添加新评论0 条评论