运维智能服务台的探索和实践
摘要
运维服务台提供了统一对外的服务窗口,但存在沟通成本高、人员流动性大,服务请求的整体交付周期普遍较长,难以保证服务质量的问题。同时,知识库不完善等问题也限制了服务台作为一线服务的工作能力,往往需要通过二、三线人员的专业知识解答问题,构建完整的运维服务闭环。因此,为了缩短运维响应时间、提升服务质量,同时降低沟通成本、缩短服务路径,光大证券信息技术总部建设了运维智能服务台,重点聚焦运维服务知识库的构建及搭建智能服务台。首先创新地使用“知识众包”形式构建运维知识库,然后将fastText、注意力机制等人工智能技术应用在识别用户意图,快速定位问题并提供解决方案中。通过智能服务台的成功应用,多种渠道对外提供月访问服务次数约700次,有效问题一次解决率约58.6%,其中在服务营业部的云桌面领域问答一次解决率高达83%,大大提高了运维服务的质量和效率。
前言
随着国内金融市场的快速发展,技术的迭代升级掀起了新一轮的金融科技创新浪潮,生产系统的双态运维压力也在不断增加,在传统运维思路中,系统管理员集中于一线大量繁琐重复运维工作的工作模式已不符合当前的发展要求。为提升IT服务能力及效率,光大证券信息技术总部提出了“服务标准化、流程自动化、管理数字化、决策智能化”的运维要求,结合ISO20000国际标准建设的IT服务管理体系,建设了光大证券信息技术总部运维服务台。服务台提供了统一对外的服务窗口,但存在沟通成本高、人员流动性大,服务请求的整体交付周期普遍较长,难以保证服务质量。同时,知识库不完善等问题也限制了服务台作为一线服务的工作能力,往往需要通过二、三线人员的专业知识解答问题,构建完整的运维服务闭环。因此,IT运维服务的服务台更应关注缩短运维响应时间和提升服务质量,降低沟通成本和缩短服务路径,提高用户满意度。
基于大数据、云计算和深度学习等领先的人工智能技术,不断的向产业互联网应用赋能,进一步提升行业的各项能力,服务台领域也在发生着快速的变化,大多传统型服务台向智能化转型。人工智能在赋能服务台领域的过程中,已经可以实现自主问答、故障引导等一系列基础任务,满足大部分的应答需求,快速高效的引导用户解决问题。结合市场调研和运维的实际工作,参照对比多家智能客服解决方案,IT运维服务台通常需要负责多套系统的运维工作,存在着系统覆盖面广、知识分散、解决问题实时性要求高等特点,目前市场上很多智能客服领域的产品不能满足运维智能服务台的需求。
本文立足于人工智能等技术,对运维领域的智能服务台进行了积极的探索,通过构建扁平化的数据处理模式和建立环状的系统管理员交互机制,力求可以构建一个证券业标准化、可推广的智能服务台体系。
1、设计思路
基于服务台运行现状和需求分析,光大证券调研多种前沿解决方案、技术及算法,从运维服务的维度出发做了一系列的探索,主要包括运维服务知识库的构建及搭建智能服务台。
1.1 构建运维知识库
结合目前运维工作实际,运维知识分散性较大,具有多而广的特点。为有效建立运维服务的智能知识库,充分调动运维服务梯队的力量,创新性提出“知识众包”的形式,即由运维一线根据工作实际,充当知识贡献者角色提交知识,由运维二线的系统管理员充当专家角色审核知识。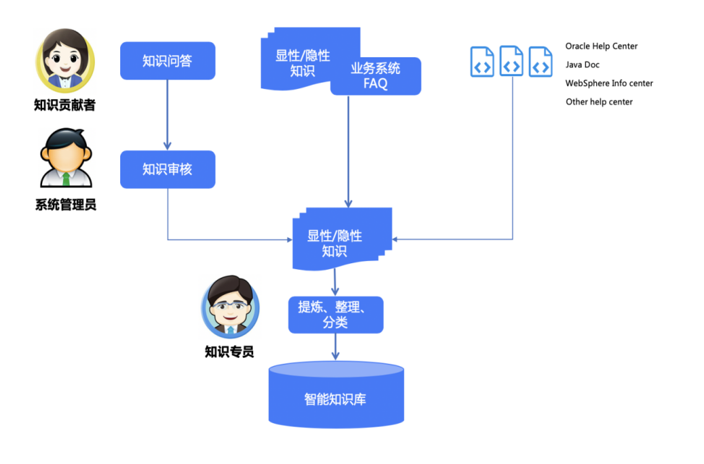
图1 运维知识库数据流
如图1所示,构建运维知识库,主要从数据收集、数据清洗、数据标签等三个方面重点开发:
数据收集。主要从以下三个渠道维度进行收集显性和隐形知识:
• 充分利用运维系统现有的QA知识。收集现有各运维系统已有的QA知识,进行数据梳理,导入知识库中作为智能学习模型训练基础;
• 第三方接入形式进行数据采集。通过对接现有ITSM平台等知识库,采集CMDB数据,实现知识库的动态更新;
• 通过爬虫形式扩充数据采集点,获取Oracle、操作系统等运维专业文档的数据采集。
数据清洗。构建多种数据清洗因子实现对现有知识库的切分、格式化、去除和修正,达到数据清洗的目的;
数据标签。根据现有知识库建立自动化学习模型,通过传统服务台模拟真实场景进行模型训练,构建数据标签,区分意图理解错误、答案质量问题、未登录知识点、持续运营、训练提高知识库命中率。
1.2 搭建智能服务台
完善好运维知识库后,智能服务台基于机器学习等算法对问题进行分析和聚类、要素提取、模糊识别、算法匹配等数据处理,帮助用户快速定位问题并提供解决方案。
智能知识库的对外输出渠道具备多样化,整个交互过程为:终端用户通过QQ、微信、网页等多渠道形式提问,智能服务台通过智能语义识别后,根据机器学习等算法进行置信度匹配知识库答案实时返回给用户。若未匹配到合适答案,智能服务台则对外吐出通用性回复,这时则需传统服务台介入干预。其目的一方面是充当智能服务台的有效补充,提供运维闭环服务;另一方面,进行智能知识库的完善与补充。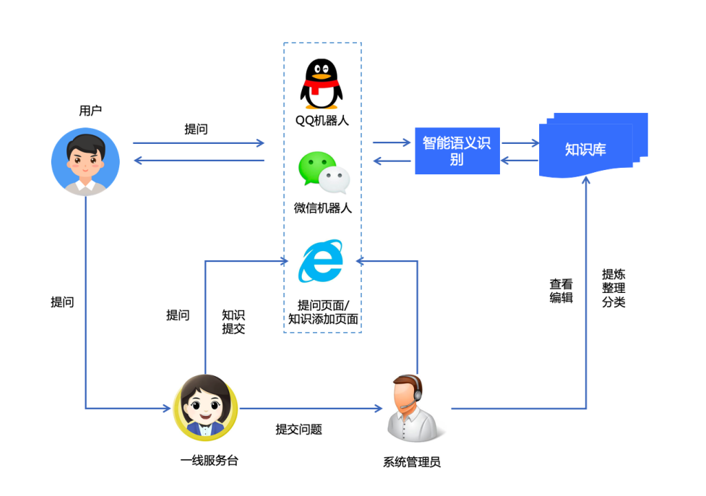
图2 智能服务台的服务渠道框架图
智能知识库的完善程度和语义识别准确性是智能服务台支持力度的关键因素。综合考虑到运维解决问题的紧迫性,人机辅助相结合的形式是智能服务台推广初期的有效解决方案,有利于高效训练智能学习模型,提升运维服务的解决效率。
2、核心算法技术
智能服务台的核心服务模块是问答引擎,该引擎用于识别用户意图。其中的关键技术包括:分词、词语相似度(词嵌入模型)、分类预测、相似问句计算。
2.1 基于统计算法的领域分词技术
词语组成句子,句子再组成段落、篇章、文档,因此分词和词性标注是中文自然语言处理的基础。分词技术已非常成熟,目前主流的可分为三大类:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法。
表1: 三种分词方法的对比表
运维领域知识特性及业务术语具有较强的专业性,所以分词这一自然语言处理的基础服务必须要具备较强的领域敏感性。特别考虑到运维领域的专有名词多等现象,为达到更好的自然语言研究效果,需要更精准的领域分词结果。经过综合考虑,本课题采用基于统计的中文分词方法,可以加载默认分词词典和自定义分词词典,发挥匹配分词切分速度快、效率高的特点,又利用了无词典分词结合上下文识别生词、自动消除歧义的优点。
2.2 基于Word2vec的词语相似度
基于运维系统说明书和知识库中的知识点等大量语料,我们采用Word2vec这种词嵌入工具训练出证券运维领域的词向量。通过词向量计算词语相似度,也是数据处理中句子相似度的基础。
Word2vec分两种模型:CBOW(Continuous Bag of Words)和Skip-gram。CBOW是拿一个词语的上下文作为输入,来预测这个词语本身;Skip-gram刚好相反,用一个词语作为输入,来预测它周围的上下文。
这两种方法都利用人工神经网络作为它们的分类算法。起初每个单词都是一个随机N维向量。经过训练之后,该算法利用CBOW或者Skip-gram的方法获得了每个单词的最优向量。训练过程如下图所示:
图3 Word2vec 算法模型图
本课题的研究目标是证券行业的NLP,选用的训练语料为运维系统说明书、知识点和问答记录,基于上述的分词算法对语料进行分词后,通过Gensim工具包训练词向量Word2vec。
2.3 基于fastText的分类算法
在识别意图时,我们需要对产生的问题进行预分类,确认该问题所属系统,缩小运维问答领域,提高运维准确度。
词嵌入算法会为每个词语生成一个向量,这可能忽略了词语内部的形态特征,比如:“光大证券”和“光大”,两个单词有较多公共字符,即它们的内部形态类似,但是在传统的词嵌入中,这种单词内部形态信息因为它们被转换成不同的id丢失了。而fastText使用了字符级别的n-grams来表示一个词,这样因为n-gram可以和其它词共享,对于低频词生成的词向量效果会更好。同时,fastText在输出时采用了分层Softmax,大大降低了模型训练时间。
本课题在研究过程中,也经过多次试验,尝试了TF-IDF、fastText、TextCNN、Transformer、Bert等多种算法,在业务日志历史数据测试集下的分类效果如下:
图4 各分类算法的训练结果
如图所示:TF-IDF算法表现不佳;TextCNN、Transformer、Bert均为深度学习算法,语料少的情况下容易过拟合,训练时间相对较长,并且对硬件要求较高;fastText在短文本处理上效果好,收敛快,预测快。
综合考虑到样本集的数量要求、硬件要求、和训练时长,对运维系统简单的分类均采用fastText算法。
2.4 基于注意力机制的句子相似度计算
随着深度学习技术的发展,基于神经网络的算法可以从大量的语料库中自动学习文本特征,训练得到文本分类模型,实现中文文本自动分类。同时,注意力机制的引入,已成为一种有效的策略用于动态学习不同特征对特定任务的贡献程度,在自然语言处理中也获得优异的效果。本质上句子相似度计算也是一个分类问题,即对于问题Q,如何在已知的Q1~Qn中,寻找最相似的Qk,1< =k< =n。
在通用领域,我们可以获得大量数据,但是行业领域尤其是运维领域,往往没有足够多的语料,因此为了更好的学习到问句特征,获得较快的收敛,本课题采用了基于领域注意力机制语义嵌入模型,将领域术语作为特征输入。其模型架构图如下:
图5 领域注意力机制语义嵌入模型
如上图所示,首先将领域知识体系构建为领域特征知识图谱,建立领域概念的属性及关系拓扑结构,并基于领域语料知识进一步训练知识之间关系的概率图模型,作为知识相关性因子。对用户的问题首先进行业务领域分类和业务实体识别,并将业务分类和实体识别的结果作为领域注意力特征加入到用户意图理解的特征表达,并在后续训练过程中持续迭代,经过实测该模型能够较快的达到收敛,有效抓住用户问题的核心业务诉求。
该算法不但可以有效提升意图识别的准确率,而且提高了中台运营的能力,业务人员可以通过补充领域术语来快速实现领域意图理解效果的调优。
3、功能展示
运维智能服务台采用自然语言处理和机器学习技术,将公司全面运维的生产系统的知识点纳入知识库体系,构建了扁平化的数据处理模式,完善运维服务维度的知识库标准体系结构,如图所示:
图6 智能服务台的数据运营展示图
通过用户不断的提问和使用,基于服务台内置的新增知识点、自动新词/业务关键词发现、自动引导场景发现、自动关联知识点发现、自动计算准确率等功能,不断的反馈优化,建立环状的系统管理员交互机制,实现了智能问答、问题引导等功能。
3.1 智能问答
智能服务台已经在内部试运行,通过QQ机器人、微信机器人、网页端等渠道对外提供服务,其中QQ机器人服务600多个用户,每个月问答约570多次。问答范围覆盖网上交易、云桌面、三方存管、现金宝、协同OA、数据服务等多个领域。智能问答规则如下:
表2 智能服务台的问答规则及动作表
以QQ机器人为例,实现的功能如图7所示,当用户@光小宝的时候,我们会根据上述的智能问答规则进行自动匹配,反@用户触发动作回答知识库匹配的答案。

图7 IM端智能问答展示
网页端主要是针对运营人员和系统管理员等用户开发,主要是通过提问测试等功能实现问题的场景测试、辨别新增知识点、增加扩展问题等,如图所示:
图8 网页端智能问答展示
3.2 问题引导
用户在提问时,经常会出现无法完整表达意图,或未抓住根本原因的情况,即意图不清。对于智能服务台来说,无法从语义上完全理解这类问题,因此考虑了模拟人工交互的过程,通过多轮交互式的引导,帮助用户定位问题,并引导用户解决。如下图所示:
图9 问题交互引导流程图展示
4、总结
本课题是在智能服务台的深度探索,为面向运维服务的传统服务台起到了很好的辅助作用。通过智能服务台的成功应用,通过多种渠道对外提供月访问服务次数约700次,有效问题一次解决率约58.6%,其中在服务营业部的云桌面领域问答一次解决率高达83%,大大提高了运维服务的质量和效率。通过智能服务台的持续建设,将帮助IT运维优化资源分配,打造一二三线专业服务梯队。本课题为行业内此类业务提供一定的借鉴和参考。
参考文献
[1] 肖剑,《智能时代的客服中心变革与发展》,2019年
[2] 鲸准研究院,《中国智能客服行业研究报告》,2018年
[3] Tomas Mikolov,Kai Chen,Greg Corrado,Jeffrey Dean.Efficient Estimation of Word Representations in Vector Space.arXiv:1301.3781v3(2013)
[4] A.Mnih,Y.W.Teh.A fast and simple algorithm for training neural probabilistic language models.ICML,2012. [5] 周练,Word2vec的工作原理与应用探究[J],图书情报导刊,2015(2):146-148
[6] Quoc Le,Tomas Mikolov.Distributed Representations of Sentences and Documents,ICML,VOL14,2014
[7] Piotr Bojanowski, Edouard Grave,Armand Joulin,Tomas Mikolov.Enriching Word Vectors with Subword Information,arXiv:1607.04606(2016)
[8] 成璐,基于注意力机制的双向LSTM模型在中文商品评论情感分类中的研究,软件工程,Vol.20,No.11(2017)
本文转自微信公众号:上交所技术服务
作者: 杨超 吴浩 耿锋 李沛臻 / 光大证券股份有限公司
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞7作者其他文章
评论 0 · 赞 2
评论 0 · 赞 7
评论 0 · 赞 3
评论 0 · 赞 2
评论 0 · 赞 2
添加新评论0 条评论