云管平台监控探索与实践
本文作者:昆仑银行许中华、常晓斌
前言
随着云计算技术的发展,越来越多 的云平台和服务类型出现 , 如VM 、 KVM 、 PAAS等 ,各大企业都在纷纷建设自己私有云平台包括IAAS、PAAS,同时IAAS也有自己的云管理平台如Openstack,另外PAAS也有自己的云管理平台如 Kubernetes , 但是如何有效的监控VM 、 KVM 、 Openstack 、 Kubernetes和PAAS平台上的微服务 ,以及如何有效的将云管平台监控集成到现有的集中监控平台也是目前云管平台建设过程中遇到的各种问题,笔者将从以上几个方面进行讨论。
1、 VM监控和KVM监控实践
1.1通过使用 pyVmomi 采集 vSphere 监控指标
vSphere需要监控的内容包含:
- ESXi —— 主机的状态 ;
- datastore —— 所有挂载的存储,要监控他们的使用情况,剩余空间 。
- vm —通过 vSphere 来获取租户服务器的相关指标。
如何 将这些监控数据从 vCenter 里取出来呢?
pyVmomi]是 VMware vSphere API 的一个 python sdk,我们可以利用它来与 vCenter 交互,获取我们需要的信息.使用 pyVmomi 连接 vCenter 。
在连接上 vCenter 之后,我们就可以开始获取各项指标了。我们从 content 下的根目录逐级开始遍历,他的第一个 childEntity 就是我们的datacenter 。 我们可以通过 datacenter.name,获取 datacenter 的名字,在组织数据上报的时候,可以作为 tag打在 datastore 上,可以区分 datastore 来自哪个 datacenter 。datastore 的容量,类型等数据,则都在 datastore.summary 之中 。 ESXi即我们 vSphere 集群中的主机信息,vSphere 中内置了大量的性能指标,可以从perfManager.perfCounter 中获取 。
- content —— 就是连接 vCenter后返回的那个 content
- vchtime —— 当前的时间,用来计算查询的时间范围,可以通过 si.CurrentTime() 去拿 vCenter的当前时间,规避时间同步问题
- counterId —— 需要查询的 counter 所对应的 ID 号
- instance —— 需要返回的实例,某些指标会有多个实例。比如网络指标就对应有多张网卡。*则表示全部返回
- entity —— 查询的对象,比如 ESXi 主机或者某个 虚拟机
- interval —— 查询的间隔,用来产生查询的时间范围。和我们上报监控的 step 保持一致。
使用perfManger 查询性能时,需要给出查询的时间范围和查询的颗粒度。我这里使用的颗粒度是 intervalId = 20,也就是 20 秒一个点。提供的时间范围提前了 1 分钟,避免太接近当前时间的点上查不到数据。
类似的, vm 的数据都在 Datacenter.vmFolder 下面,当然也会碰到Folder嵌套的问题。不过我们之所以遍历 Folder 去获取主机信息,主要是为了能够在遍历过程中,拿到主机上级的 Datacenter和Cluster等信息,作为数据的tag一同报送给监控系统。我们可以通过更简单的办法拿到所有的 vm 清单 。
VMware ESXi虚拟机监控指标列表
| 监测点 | 监测指标 | 指标含义 |
| CPU | CPU使用率(%) | CPU处理任务的繁忙程度 |
| CPU使用量(MHz) | CPU处理任务时占用的兆赫兹数量 | |
| 内存(这里指物理内存) | 内存使用率(%) | 内存使用数和内存总量的比值 |
| 活动内存(MB) | 正在使用的内存数 | |
| 内存总量(MB) | 物理内存总数 | |
| 磁盘 | 磁盘读IO(次/20s) | 每20s磁盘读的次数 |
| 磁盘写IO(次/20s) | 每20s磁盘写的次数 | |
| 磁盘读速率(KBps) | 每秒磁盘读的K字节数 | |
| 磁盘写速率(KBps) | 每秒磁盘写的K字节数 | |
| 网卡 | 网络接收速率(KBps) | 每秒网卡接收的K字节数 |
| 网络发送速率(KBps) | 每秒网卡发送的K字节数 | |
| 硬盘性能 | 读取滞后时间(毫秒) | 单个硬盘读取滞后的时间 |
| 写入滞后时间(毫秒) | 单个硬盘写入滞后的时间 | |
| CPU核心 | 已使用(毫秒) | 单个CPU核心的已使用时间 |
| 闲置(毫秒) | 单个CPU核心的闲置时间 | |
| 虚拟机 | ||
| CPU使用率(%) | 虚拟机的CPU处理任务的繁忙程度 | |
| CPU使用量(MHz) | 虚拟机的CPU处理任务时占用的兆赫兹数量 | |
| 内存利用率(%) | 虚拟机内存使用数和虚拟机内存总量的比值 | |
| 活动内存(MB) | 虚拟机正在使用的内存数 | |
| 内存总量(MB) | 虚拟机的内存总数 | |
| 硬盘读速率(KBps) | 每秒虚拟机硬盘读的K字节数 | |
| 硬盘写速率(KBps) | 每秒虚拟机硬盘写的K字节数 | |
| 硬盘读IO(次/20s) | 虚拟机每20s硬盘读的次数 | |
| 硬盘写IO(次/20s) | 虚拟机每20s硬写的次数 | |
| 网络接收速率(KBps) | 虚拟机每秒网卡接收的K字节数 | |
| 网络发送速率(KBps) | 虚拟机每秒网卡发送的K字节数 | |
| 数据存储 | 使用率(%) | (总容量-剩余容量)/ 总容量 |
| 总容量(GB) | VMware数据存储的总容量 | |
| 剩余容量(GB) | VMware数据存储的剩余容量 |
1.2通过Libvirt-python监控KVM
KVM(Kernel-based Virtual Machine)作为一个开源的系统虚拟化模块,已经成为虚拟机虚拟化技术的主流,在越来越多的Cloud环境中使用。为了保证Cloud环境的正常运行,需要在运维过程中对Cloud环境中的VM状态进行监控,比如CPU,内存,Disk,Disk I/O,Network I/O等信息,可以利用这些信息及时的调整分配Cloud环境的资源,保证VM的正常运行。Libvirt是基于KVM的上层封装,提供了操作KVM的原生层接口,可以实现对虚拟机的日常管理操作,如虚拟机的生命周期(创建,删除,查看,管理),开机,关机,重启,网络管理,存储管理等。Libvirt提供一种虚拟机监控程序不可知的 API 来安全管理运行于主机上的客户操作系统,是一种可以建立工具来管理客户操作系统的 API。Libvirt 本身构建于一种抽象的概念之上。它为受支持的虚拟机监控程序实现的常用功能提供通用的API,适用于包括基于KVM/QEMU, Xen, LXC, OpenVZ, Virtualbox, VMware, PowerVM等多种虚拟机化技术的虚拟机。Libvirt-python是基于libvirt API的python语言绑定工具包,通过该包,可以使用python对VM进行日常管理操作和监控数据获取。需要运行的Python监控程序可以在KVM的HOST中运行,也可以在基于KVM虚拟机化的任意环境运行。
利用Python调用API获取 VM相关监控信息代码如下:
2.1创建连接
from future import print_function
import sys
import libvirt
conn = libvirt.open('qemu:///system')
2.2 列出Domains
conn.listAllDomains(type)方法返回指定类型的domains列表,type参数可以设置以下类型
2.3 获取监控数据
VM的监控信息主要是CPU使用率,内存使用率,Disk使用率,Disk I/O,Network I/O。其中,CPU的使用率,Disk I/O,Network I/O并不能直接获取,需要经过计算获得。
另外 , openstack的ceilometer组件也能实现KVM监控 ,感谢的同学可以自己研究一下。
2、 Openstack监控实践
OpenStack是由控制节点,计算节点,网络节点,存储节点四大部分组成。(这四个节点也可以安装在一台机器上,单机部署)其中:控制节点负责对其余节点的控制,包含虚拟机建立,迁移,网络分配,存储分配等等 , 计算节点负责虚拟机运行 , 网络节点负责对外网络与内网络之间的通信 , 存储节点负责对虚拟机的额外存储管理等等 。 在这里主要是探索了一下openstack的监控,采用prometheus社区里面一个openstack-exporter ,需要根据自己实际的需求,从exporter里面暴露的众多metrics进行展示。 另外虚拟机也需要监控,这里使用的openstack-exporter是通过客户端api接入到openstack环境中对一些通用的参数进行采集,对于openstack自身的组件没有监控,对于kolla部署出来的openstack,需要监控容器,这里也没有涉及,对于虚拟机的内部运行情况监控,也需要规划设计,这里也没有涉及,如果要对openstack生产环境进行监控,还有很多工作需要做。
· OpenStack exporter
· 一个是:sum(nova_instances{instance_state="ACTIVE"}) //总活动VM数
· 一个是:sum(hypervisor_vcpus_used) by(hypervisor_hostname) //每台物理机上已经使用的vcpu数
步骤1: 开启一个线程默认每隔30秒轮询:
步骤1.1: openstack各组件api服务的状态,
步骤1.2: 获取nova/neutron/cinder组件下面在每个host上具体服务的状态
步骤1.3: 获取nova的hypervisor信息
获取上述的信息,分别建立<缓存名称,缓存结果>存放在字典中
步骤2: 开启一个TCPServer服务器,监听9103端口,
prometheus默认每隔60秒向prometheus-openstack-exporter服务发送请求,该请求会被上述TCPServer服务器处理。请求处理见步骤3
步骤3: 遍历缓存结果,获取每个缓存名称对应的结果列表(是数组),
步骤3.1: 对该缓存结果列表遍历,对每个缓存结果(是字典), 调用prometheus_client的方法设置监控项名称,监控项对应的值,以及标签列表
步骤3.2: 最后调用prometheus_client.generate_latest(registry)方法产生最终结果(是一个字符串)并返回
对上述每个缓存结果产生的字符串进行拼接,最终做为一个大字符串返回给prometheus。
3、 PAAS与PAAS管理平台K8S
目前很多的容器云平台通过Docker及Kubernetes等技术提供应用运行平台,从而实现运维自动化,快速部署应用、弹性伸缩和动态调整应用环境资源,提高研发运营效率。从宏观到微观(从抽象到具体)的思路来理解:云计算→PaaS→ App Engine→XAE[XXX App Engine] (XAE泛指一类应用运行平台,例如GAE、SAE、BAE等)。
3.1.PaaS概述
3.1.1.PaaS概念
- PaaS(Platform as a service),平台即服务,指将软件研发的平台(或业务基础平台)作为一种服务,以SaaS的模式提交给用户。
- PaaS是云计算服务的其中一种模式,云计算是一种按使用量付费的模式的服务,类似一种租赁服务,服务可以是基础设施计算资源(IaaS),平台(PaaS),软件(SaaS)。租用IT资源的方式来实现业务需要,如同水力、电力资源一样,计算、存储、网络将成为企业IT运行的一种被使用的资源,无需自己建设,可按需获得。
- PaaS的实质是将互联网的资源服务化为可编程接口,为第三方开发者提供有商业价值的资源和服务平台。简而言之,IaaS就是卖硬件及计算资源,PaaS就是卖开发、运行环境,SaaS就是卖软件。
3.1.2.PaaS的特点(三种层次)
| 特点 | 说明 |
| 平台即服务 | PaaS提供的服务就是个基础平台,一个环境,而不是具体的应用 |
| 平台及服务 | 不仅提供平台,还提供对该平台的技术支持、优化等服务 |
| 平台级服务 | “平台级服务”即强大稳定的平台和专业的技术支持团队,保障应用的稳定使用 |
3.2.容器云平台技术栈
| 功能组成部分 | 使用工具 |
| 应用载体 | Docker |
| 编排工具 | Kubernetes |
| 配置管理 | Etcd |
| 网络管理 | Flannel |
| 存储管理 | Ceph |
| 底层实现 | Linux内核的Namespace[资源隔离]和CGroups[资源控制] |
· Namespace[资源隔离] Namespaces机制提供一种资源隔离方案。PID,IPC,Network等系统资源不再是全局性的,而是属于某个特定的Namespace。每个namespace下的资源对于其他namespace下的资源都是透明,不可见的。
· CGroups[资源控制] CGroup(control group)是将任意进程进行分组化管理的Linux内核功能。CGroup本身是提供将进程进行分组化管理的功能和接口的基础结构,I/O或内存的分配控制等具体的资源管理功能是通过这个功能来实现的。CGroups可以限制、记录、隔离进程组所使用的物理资源(包括:CPU、memory、IO等),为容器实现虚拟化提供了基本保证。CGroups本质是内核附加在程序上的一系列钩子(hooks),通过程序运行时对资源的调度触发相应的钩子以达到资源追踪和限制的目的。
3.3.Docker概述
3.3.1.Docker介绍
- Docker - Build, Ship, and Run Any App, Anywhere
- Docker是一种Linux容器工具集,它是为“构建(Build)、交付(Ship)和运行(Run)”分布式应用而设计的。
- Docker相当于把应用以及应用所依赖的环境完完整整地打成了一个包,这个包拿到哪里都能原生运行。因此可以在开发、测试、运维中保证环境的一致性。
- Docker的本质:Docker=LXC(Namespace+CGroups)+Docker Images,即在Linux内核的Namespace[资源隔离]和CGroups[资源控制]技术的基础上通过镜像管理机制来实现轻量化设计。
3.3.2.Docker的基本概念
3.3.2.1.镜像
Docker 镜像就是一个只读的模板,可以把镜像理解成一个模子(模具),由模子(镜像)制作的成品(容器)都是一样的(除非在生成时加额外参数),修改成品(容器)本身并不会对模子(镜像)产生影响(除非将成品提交成一个模子),容器重建时,即由模子(镜像)重新制作成一个成品(容器),与其他由该模子制作成的成品并无区别。例如:一个镜像可以包含一个完整的 ubuntu 操作系统环境,里面仅安装了 Apache 或用户需要的其它应用程序。镜像可以用来创建 Docker 容器。Docker 提供了一个很简单的机制来创建镜像或者更新现有的镜像,用户可以直接从其他人那里下载一个已经做好的镜像来直接使用。
3.3.2.2.容器
Docker 利用容器来运行应用。容器是从镜像创建的运行实例。它可以被启动、开始、停止、删除。每个容器都是相互隔离的、保证安全的平台。可以把容器看做是一个简易版的 Linux 环境(包括root用户权限、进程空间、用户空间和网络空间等)和运行在其中的应用程序。
3.3.2.3.仓库
仓库是集中存放镜像文件的场所。有时候会把仓库和仓库注册服务器(Registry)混为一谈,并不严格区分。实际上,仓库注册服务器上往往存放着多个仓库,每个仓库中又包含了多个镜像,每个镜像有不同的标签(tag)。
3.3.3.Docker的优势
- 容器的快速轻量
容器的启动,停止和销毁都是以秒或毫秒为单位的,并且相比传统的虚拟化技术,使用容器在CPU、内存,网络IO等资源上的性能损耗都有同样水平甚至更优的表现。
- 一次构建,到处运行
当将容器固化成镜像后,就可以非常快速地加载到任何环境中部署运行。而构建出来的镜像打包了应用运行所需的程序、依赖和运行环境,这是一个完整可用的应用集装箱,在任何环境下都能保证环境一致性。
- 完整的生态链
容器技术并不是Docker首创,但是以往的容器实现只关注于如何运行,而Docker站在巨人的肩膀上进行整合和创新,特别是Docker镜像的设计,完美地解决了容器从构建、交付到运行,提供了完整的生态链支持。
3.4.Kubernetes概述
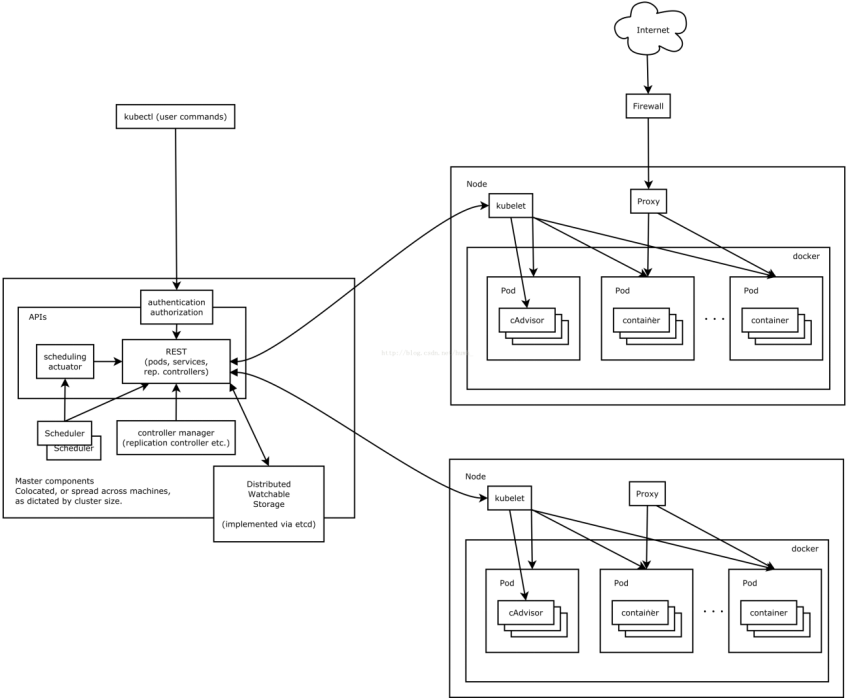
3.4.1.Kubernetes介绍
Kubernetes是Google开源的容器集群管理系统。它构建Docker技术之上,为容器化的应用提供资源调度、部署运行、服务发现、扩容缩容等整一套功能,本质上可看作是基于容器技术的Micro-PaaS平台,即第三代PaaS的代表性项目。
3.4.2.Kubernetes的基本概念
3.4.2.1.Pod
Pod是若干个相关容器的组合,是一个逻辑概念,Pod包含的容器运行在同一个宿主机上,这些容器使用相同的网络命名空间、IP地址和端口,相互之间能通过localhost来发现和通信,共享一块存储卷空间。在Kubernetes中创建、调度和管理的最小单位是Pod。一个Pod一般只放一个业务容器和一个用于统一网络管理的网络容器。
3.4.2.2.Replication Controller
Replication Controller是用来控制管理Pod副本(Replica,或者称实例),Replication Controller确保任何时候Kubernetes集群中有指定数量的Pod副本在运行,如果少于指定数量的Pod副本,Replication Controller会启动新的Pod副本,反之会杀死多余的以保证数量不变。另外Replication Controller是弹性伸缩、滚动升级的实现核心。
3.4.2.3.Service
Service是真实应用服务的抽象,定义了Pod的逻辑集合和访问这个Pod集合的策略,Service将代理Pod对外表现为一个单一访问接口,外部不需要了解后端Pod如何运行,这给扩展或维护带来很大的好处,提供了一套简化的服务代理和发现机制。
3.4.2.4.Label
Label是用于区分Pod、Service、Replication Controller的Key/Value键值对,实际上Kubernetes中的任意API对象都可以通过Label进行标识。每个API对象可以有多个Label,但是每个Label的Key只能对应一个Value。Label是Service和Replication Controller运行的基础,它们都通过Label来关联Pod,相比于强绑定模型,这是一种非常好的松耦合关系。
3.4.2.5.Node
Kubernets属于主从的分布式集群架构,Kubernets Node(简称为Node,早期版本叫做Minion)运行并管理容器。Node作为Kubernetes的操作单元,将用来分配给Pod(或者说容器)进行绑定,Pod最终运行在Node上,Node可以认为是Pod的宿主机。
3.4.3.Kubernetes架构
4、 docker监控与K8S监控实践
4.1、 容器的监控方案
4.1.1.单台主机容器监控:
(1) docker stats
1、 单台主机上容器的监控实现最简单的方法就是使用命令Docker stats,就可以显示所有容器的资源使用情况.
2、 这样就可以查看每个容器的CPU利用率、内存的使用量以及可用内存总量。请注意,如果你没有限制容器内存,那么该命令将显示您的主机的内存总量。但它并不意味着你的每个容器都能访问那么多的内存。另外,还可以看到容器通过网络发送和接收的数据总量
3、 虽然可以很直观地看到每个容器的资源使用情况,但是显示的只是一个当前值,并不能看到变化趋势。
(2)Google的 cAdvisor 是另一个知名的开源容器监控工具:
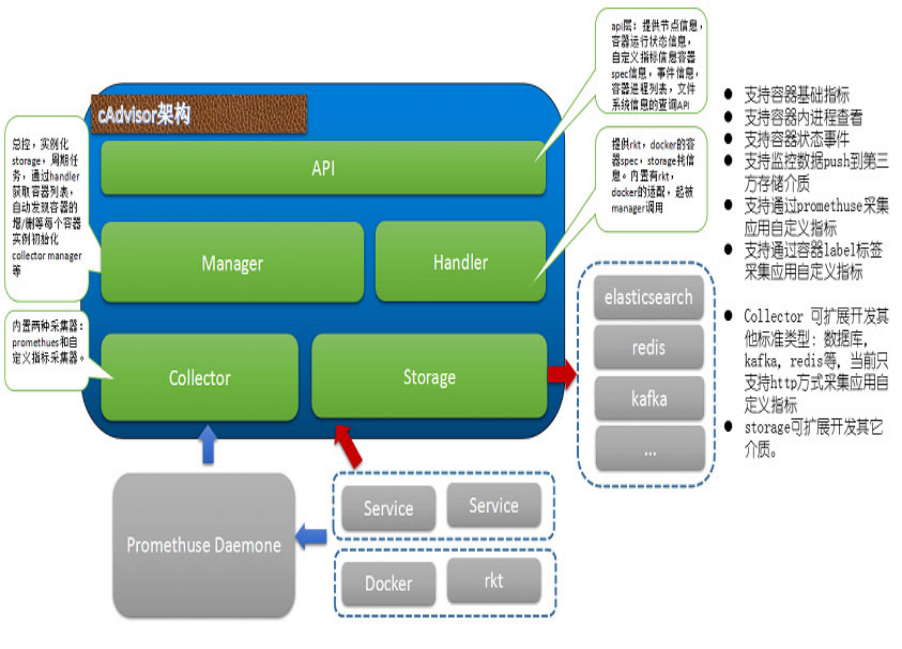
只需在宿主机上部署cAdvisor容器,用户就可通过Web界面或REST服务访问当前节点和容器的性能数据(CPU、内存、网络、磁盘、文件系统等等),非常详细。
它的运行方式也有多种:
a.直接下载命令运行
1、 下载地址: https://github.com/google/cadvisor/releases/latest
2、 格式: nohup /root/cadvisor -port=10000 &>>/var/log/kubernetes/cadvisor.log &
3、 访问:http://ip:10000/
b.以容器方式运行
docker pull index.alauda.cn/googlelib/cadvisor
c.kubelet选项:
1) 在启动kubelete时候,启动cadvisor
2) cAdvisor当前都是只支持http接口方式,被监控的容器应用必须提供http接口,所以能力较弱。在Kubernetes的新版本中已经集成了cAdvisor,所以在 Kubernetes架构下,不需要单独再去安装cAdvisor,可以直接使用节点的IP加默认端口4194就可以直接访问cAdvisor的监控面板。UI界面如下:
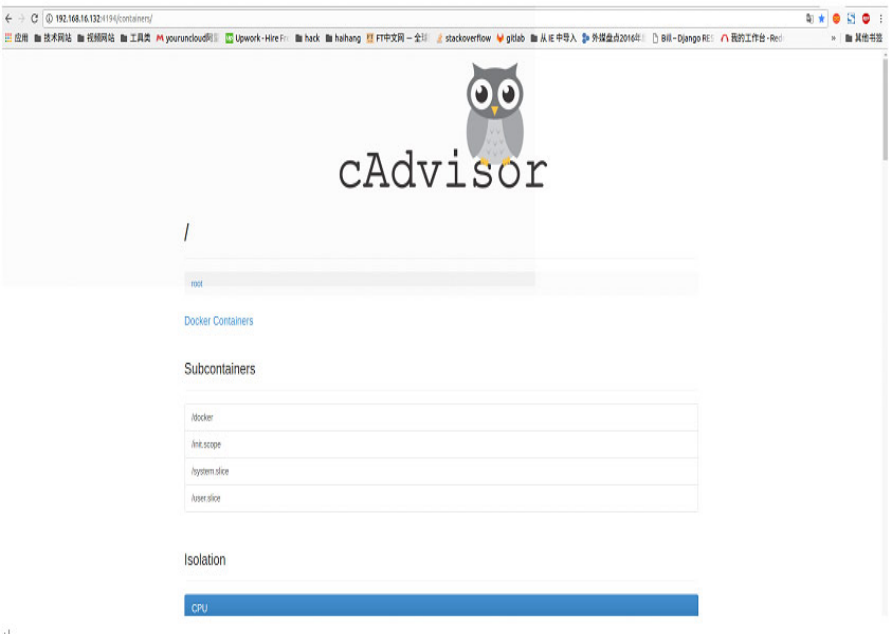
1) 因为cAdvisor默认是将数据缓存在内存中,在显示界面上只能显示1分钟左右的趋势,所以历史的数据还是不能看到,但它也提供不同的持久化存储后端,比如influxdb等,同时也可以根据业务的需求,只利用cAdvisor提供的api接口,定时去获取数据存储到数据库中,然后定制自己的界面。
2) 如需要通过cAdvisor查看某台主机上某个容器的性能数据只需要调用: http://:4194/v1.3/subcontainers/docker/
3) cAdvisor的api接口返回的数据结构可以分别计算出 CPU、内存、网络等资源的使用或者占用情况。
4.2、K8S监控
1.容器的监控
在Kubernetes监控生态中,一般是如下的搭配使用:
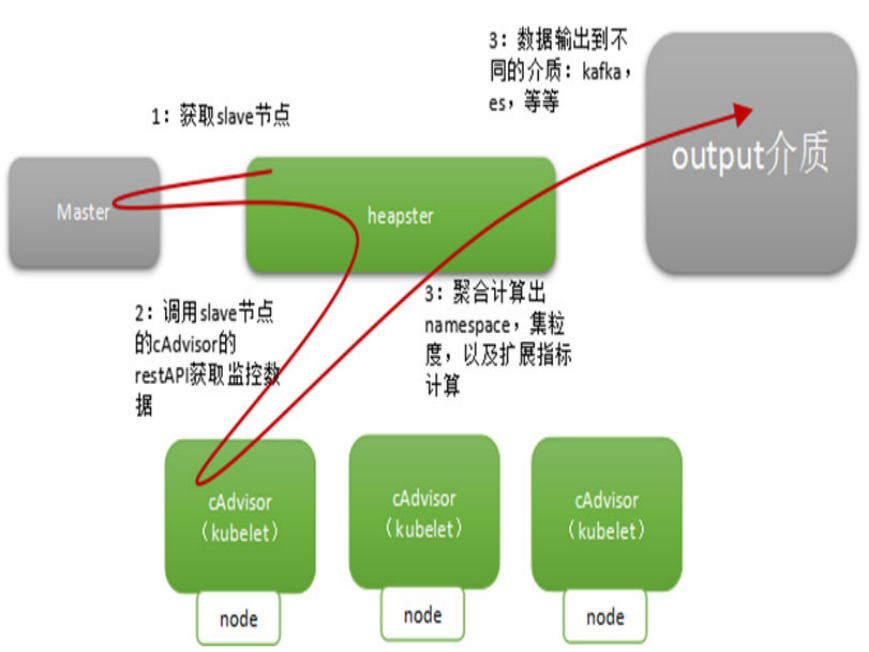
(1)Cadvisor+InfluxDB+Grafana:
Cadvisor:将数据写入InfluxDB ;
InfluxDB :时序数据库,提供数据的存储,存储在指定的目录下 。
cAdivsor虽然能采集到监控数据,也有很好的界面展示,但是并不能显示跨主机的监控数据,当主机多的情况,需要有一种集中式的管理方法将数据进行汇总展示,最经典的方案就是 cAdvisor+ Influxdb+grafana,可以在每台主机上运行一个cAdvisor容器负责数据采集,再将采集后的数据都存到时序型数据库influxdb中,再通过图形展示工具grafana定制展示面板。
在上面的安装步骤中,先是启动influxdb容器,然后进行到容器内部配置一个数据库给cadvisor专用,然后再启动cadvisor容器,容器启动的时候指定把数据存储到influxdb中,最后启动grafana容器,在展示页面里配置grafana的数据源为influxdb,再定制要展示的数据,一个简单的跨多主机的监控 系统就构建成功了。
(2)Kubernetes——Heapster+InfluxDB+Grafana:
Heapster:在k8s集群中获取metrics和事件数据,写入InfluxDB,heapster收集的数据比cadvisor多,却全,而且存储在influxdb的也少。
InfluxDB:时序数据库,提供数据的存储,存储在指定的目录下。
Grafana:提供了WEB控制台,自定义查询指标,从InfluxDB查询数据,并展示。
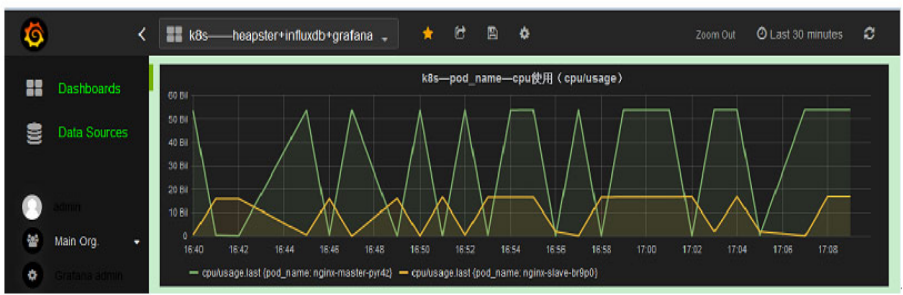
Heapster是一个收集者,将每个Node上的cAdvisor的数据进行汇总,然后导到InfluxDB。Heapster的前提是使用cAdvisor采集每个node上主机和容器资源的使用情况,再将所有node上的数据进行聚合,这样不仅可以看到Kubernetes集群的资源情况,还可以分别查看每个node/namespace及每个node/namespace下pod的资源情况。这样就可以从cluster,node,pod的各个层面提供详细的资源使用情况。
2、kubernetes中主机监控方案:
(1) 部署node-exporter容器
node-exporter 要在集群的每台主机上部署,使用主机网络,端口是9100 如果有多个K8S集群,则要在多个集群上部署,部署node-exporter的命令如下:
# kubectl create -f node-exporter-deamonset.yaml
获取metrics数据 http://ip:9100/metrics , 返回的数据结构不是json格式,如果要使用该接口返回的数据,可以通过正则匹配,匹配出需要的数据,然后在保存到数据库中。
(2) 部署Prometheus和Grafana
Prometheus 通过配置文件发现新的节点,文件路径是/sd/*.json,可以通过修改已有的配置文件,添加新的节点纳入监控,命令如下:
# kubectl create -f prometheus-file-sd.yaml
(3)查看Prometheus监控的节点
Prometheus 的访问地址是:http:// xxx.xxx .xxx.xxx:31330
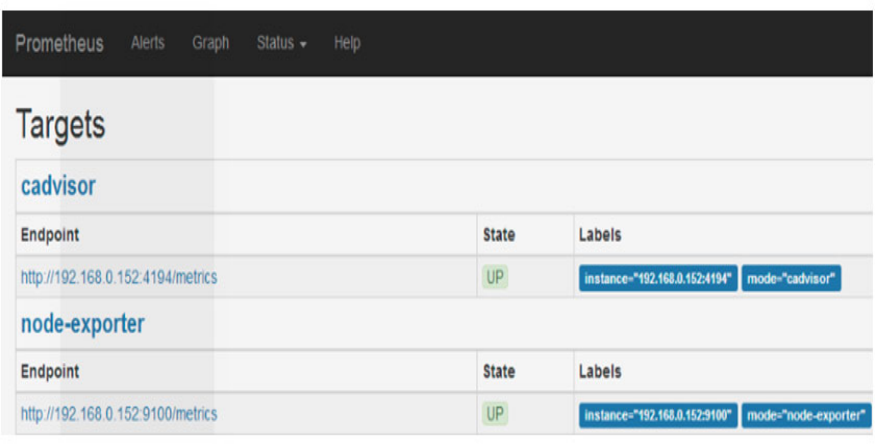
通过网页查看监控的节点Status –> Targets
· 使用metric-server收集数据给k8s集群内使用,如kubectl,hpa,scheduler等
· 使用prometheus-operator部署prometheus,存储监控数据
· 使用kube-state-metrics收集k8s集群内资源对象数据
· 使用node_exporter收集集群中各节点的数据
· 使用prometheus收集apiserver,scheduler,controller-manager,kubelet组件数据
· 使用alertmanager实现监控报警
· 使用grafana实现数据可视化
prometheus-operator是一个整合prometheus和operator的项目,prometheus是一个集数据收集存储,数据查询,数据图表显示于一身的开源监控组件。operator是由coreos开源一套在k8s上管理应用的软件,通过operator可以方便的实现部署,扩容,删除应用等功能。prometheus-operator利用k8s的CustomResourceDefinitions功能实现了只需要像写原生kubectl支持的yaml文件一样,轻松收集应用数据,配置报警规则等,包含如下CRDs :
· Prometheus用于部署Prometheus 实例
· ServiceMonitor 用于配置数据收集,创建之后会根据DNS自动发现并收集数据
· PrometheusRule 用于配置Prometheus 规则,处理规整数据和配置报警规则
5、监控容器上微服务
微服务由于服务众多 , 微服务关系交错复杂,微服务部署种类多样 ,所以业务的监控是必不可少的,主要做了几个方面的监控 :
· metrics监控
· trace监控
· 健康性监控
· 日志监控
实现方式
· 通过springboot配合micrometer进行使用,底层存储使用prometheus来进行存储
· prometheus从eureka上面获取服务节点信息,并且每天晚上更新一次
监控指标
· 服务qps
· 服务分位数
· 服务错误返回数
· 服务接口请求次数的top
· 服务接口95%请求时间top
· cpu使用率
· cpu个数和负载
· jvm堆内存/非堆内存
· jvm线程
· jvm的类数
· gc的暂停时间和次数
· tomcat的活跃线程
· 数据库连接数
· 日志行数
· 业务通过api自己上报的业务数据
服务链路监控
· 微服务架构是一个分布式架构,它按业务划分服务单元,一个分布式系统往往有很多个服务单元。由于服务单元数量众多,业务的复杂性,如果出现了错误和异常,很难去定位。主要体现在,一个请求可能需要调用很多个服务,而内部服务的调用复杂性,决定了问题难以定位。所以微服务架构中,必须实现分布式链路追踪,去跟进一个请求到底有哪些服务参与,参与的顺序又是怎样的,从而达到每个请求的步骤清晰可见,出了问题,很快定位。
· 链路追踪组件有Google的Dapper,Twitter 的Zipkin,以及阿里的Eagleeye (鹰眼)等,它们都是非常优秀的链路追踪开源组件,国内商用的产品有听云、博瑞。
· 分布式跟踪系统可以帮助收集时间数据,解决在microservice架构下的延迟问题;它管理这些数据的收集和查找;Zipkin的设计是基于谷歌的Google Dapper论文。每个应用程序向Zipkin报告定时数据,Zipkin UI呈现了一个依赖图表来展示多少跟踪请求经过了每个应用程序;如果想解决延迟问题,可以过滤或者排序所有的跟踪请求,并且可以查看每个跟踪请求占总跟踪时间的百分比。
健康性检查
· 通过从 Spring Cloud Eureka 获取服务节点,并且从服务请求数据和状态
· 如果服务状态不健康,进行报警通知
· 通过接口查看错误码,错误码达到一定比率,进行报警通知
日志监控
· 通过 ELK 来监控error日志或者通过其他监控产品自带的日志产品进行关键字监控,感兴趣的同学可以自行研究ELK 。
6、云管监控平台与集中监控平台集成
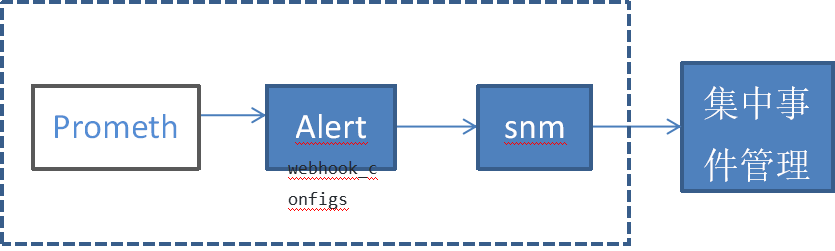
目前一般企业都有集中事件管理平台 , 但是如何将新建的云管平台监控系统与现有事件管理平台集成呢 ?可以使用 Alertmanager 模块的Webhook Receiver ,将其设置为 snmp_notifier , SNMP _ Notifier接收来自AlertManager的告警然后将告警转发给SNMP Traps poller。 Prometheus' Alertmanager 在其HTTP API 上向 SNMP 通知程序发送警报。然后,SNMP notifier 在给定警报的标签中查找OID。每个陷阱都带有一个唯一的 ID 发送,如果警报更新或一旦解决,则允许发送具有更新状态和数据的其他Trap。
Alertmanager 配置 如下 :
receivers:
- name: 'snmp_notifier'
webhook_configs:
- send_resolved: true
url: http://snmp.notifier.service:9464/alerts
同时snmp_notifier配置如下:
usage: snmp_notifier []
A tool to relay Prometheus alerts as SNMP traps
--web.listen-address=:9464
Address to listen on for web interface and telemetry.
--alert.severity-label="severity"
Label where to find the alert severity.
--alert.default-severity="critical"
The alert severity if none is provided via labels.
--snmp.destination=127.0.0.1:162
SNMP trap server destination.
--snmp.trap-oid-label="oid"
Label where to find the trap OID.
--snmp.trap-default-oid="1.3.6.1.4.1.1664.1"
Trap OID to send if none is found in the alert labels
需要 特别注意的地方是: 设置snmp.destination ,这个是指集中事件关联平台的IP,目前商用银行的事件管理平台一般都采用Tivoli OMNIbus,Omnibus提供SNMP探测器接收snmptrap报警。告警数据流向图大概如下:
7、展望未来
目前云计算还处于起步阶段,但它将改变用户对计算资源 的 使用方式 ,云管平台将进一步成熟,能够承担独立云管平台的角色和职责,帮助企业IT云化转型,从传统“监管控”中心,转型为“云服务中心”
以统一的方式在多云环境下实现自动化、自助化的服务交付(例如虚机服务、容器服务、对象存储服务、备份服务、漏扫服务、数据库服务、缓存服务等),同时持续提升我行的安全合规水平和运维运营效率,支持企业从传统IT渐进、无缝低地过渡到多云战略。云管理涉及到众多的云平台的对接和管理,以及从流程、自动化到分析、治理等一系列的功能。对于企业的IT部门来说,需要根据自身的需求,找到合适的多功能和多平台支持的组合,以最大限度地减少工具的泛滥。在大多数现代企业中,应用程序开发项目正在成为主要的需求方,并且消耗了绝大部分IT的时间和资源。因此,IT所选择的云管理平台,不再是仅仅能够解决IT运维和配置的需要,还需要满足业务部门和开发人员的需求,快速地上线应用程序。这也是为什么很多上一代CMP产品不能跟上时代要求的原因,因为它们过于侧重在运维配置,难以扩展,无法提供开发人员需要的持续集成和持续交付(CI/CD)能力。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞7作者其他文章
评论 7 · 赞 4
评论 0 · 赞 2
评论 4 · 赞 10
评论 2 · 赞 7
评论 0 · 赞 1
添加新评论3 条评论
2020-08-10 12:29
2020-01-09 16:54
2020-01-02 00:42