Kubernetes与IaaS资源融合实践--以AWS为例
1 前言
我们知道Kubernetes是强大的声明式容器编排工具,而计算、存储、网络等功能均是通过以接口的形式暴露、以插件的形式实现,这种灵活开放的设计理念使Kubernetes非常容易集成外部工具扩展和强化功能。而IaaS云平台提供的核心功能就是计算、存储和网络,这意味着Kubernetes与IaaS云平台并不是独立割裂的,而是天然非常适合结合在一起,功能和职责互补,二者联合起来既能充分利用底层服务器、网络、存储等基础设施能力又能提供弹性、敏捷的基础架构平台。
目前Kubernetes已经能和OpenStack、AWS、Google云等IaaS云平台很好的集成,比如Volume能和OpenStack的Cinder以及AWS的EBS集成,Pod网络则能和云平台的VPC网络集成,而Kubernetes Service和Ingress则分别适合与IaaS云平台的四层防火墙、七层防火墙集成。
本文接下来主要以Kubernetes融合AWS资源为例,主要通过实验的方式介绍Kubernetes与IaaS资源的结合方式。
2 基础环境配置
2.1 节点配置
首先需要在AWS上创建至少3台EC2实例,需要注意的是由于后面涉及的AWS NLB以及ALB均需要至少跨2个AZ,因此EC2实例需要至少跨2个AZ的子网。
另外Kubernetes自动创建AWS资源时需要调用AWS API,因此需要向AWS IAM进行身份和权限认证,考虑安全的问题,不建议使用AKSK的方式进行配置,而是采用Assume Role的方式使用STS进行登录认证,需要的权限如EBS卷的创建、挂载、安全组配置、标签设置和读取等,实验时为了简化Policy策略配置,直接使用了内置的 AmazonEC2FullAccess Policy策略,创建了EC2 Role后关联到所有的EC2实例,如图:
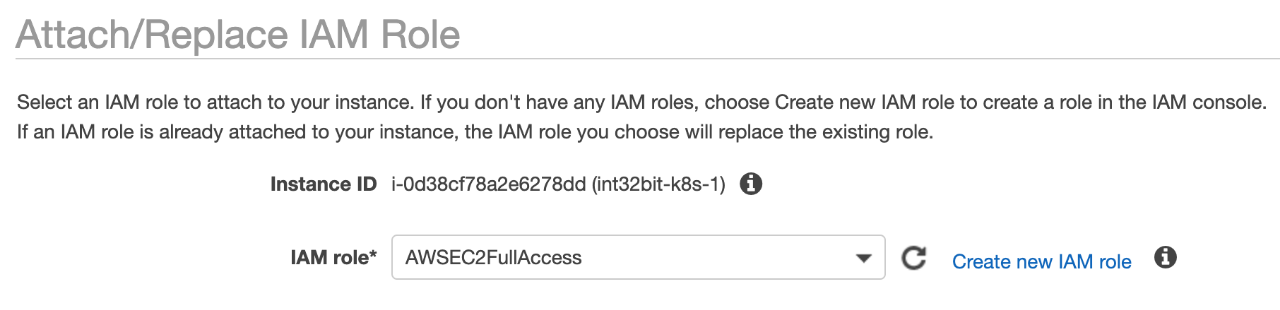
实际生产时需要遵循最小权限授权原则,必须通过自定义Policy的形式仅配置Kubernetes需要的权限,Kubernetes Master节点和Node节点需要的权限不同,需要分别授权,github上有现成的Policy可以用 kubernetes/cloud-provider-aws 。
另外需要注意的是,Kubernetes的所有Node节点hostname必须使用EC2实例的private DNS名,原因可以参考文章:https://blog.juanwolf.fr/post/programming/why-k8s-nodes-changes-name-when-using-aws/。因此需要在所有的Node节点手动配置:
- sudo hostnamectl set-hostname \
- $(curl -sSL http://169.254.169.254/latest/meta-data/local-hostname)
2.2 标签很重要
Kubernetes需要知道哪些AWS资源是属于这个集群的,哪些是可以使用的,比如Kubernetes创建Service时为了暴露互联网访问需要修改EC2实例的安全组,但通常一个EC2实例可能会挂多个安全组,有些安全组是基线安全组,供一些公共服务如堡垒机使用,用户肯定不期望Kubernetes把这些安全组规则也改了。因此Kubernetes要求用户必须给资源打上标签,通过标签的方式告诉Kubernetes哪些资源可以用,其中有两个标签是必须的:
- KubernetesCluster: 配置Kubernetes cluster名称,对应部署Kubernetes时kubeadm的 clusterName参数,因为一个Account下可能有多个Kubernetes集群,通过这个参数用于区分是哪个集群。
- kubernetes . io / cluster / int32bit - kubernetes: 填写 shared或者 owned,即是否允许多个集群共享这些资源。
这些标签需要打到所有要使用的资源上,包括EC2实例、安全组、子网,当然不使用的则不打,比如不需要Kubernetes托管的安全组就不要打上如上标签。
另外Kubernetes创建负载均衡时需要知道哪些子网是私有子网(挂的是NAT Gateway路由表),哪些是公有子网(挂的是Internet Gateway路由表),因此需要给所有使用的子网打上如下标签:
- 私有子网: kubernetes . io / role / internal - elb : 1。
- 公有子网: kubernetes . io / role / elb : 1。
参考EKS集群VPC注意事项。
2.3 安装与配置Kubernetes
目前安装与配置Kubernetes主要使用kubeadm工具,不过现版本kubeadm还不支持直接传递 cloud provider参数,因此需要自己写配置文件,建议先使用kubeadm生成默认的配置文件:
kubeadm config print init-defaults >kubeadm.yaml
修改 kubeadm . yaml配置文件,控制平面需要修改 controllerManager,Node平面需要修改 nodeRegistration,添加 kubeletExtraArgs的 cloud - provider参数:

当然为了更适合国内网络环境,建议使用阿里云的Kubernetes容器镜像,修改 imageRepository参数为 registry . aliyuncs . com / google_containers。
另外需要记住配置的 clusterName,默认为 kubernetes,后面打标签和配置需要使用。
首个节点初始化:
kubeadmin init --config kubeadm.yaml
当首个节点完成init后,其他Node节点需要join,同样需要修改 nodeRegistration参数指定cloud provider,生成默认配置文件方法如下:
1、kubeadm config print join-defaults >kubeadm.yaml
2、# 修改kubeadm.yaml的nodeRegistration以及apiServerEndpoint
3、kubeadm join --config kubeadm.yaml
3 通过块存储实现动态PVC卷
Kubernetes通过StorageClass实现动态PVC,目前支持AWS EBS、OpenStack Cinder、Ceph等驱动,利用这些云平台提供的底层存储,Kubernetes可实现按需创建持久化存储的Volume,以创建AWS EBS StorageClass为例,声明文件如下:
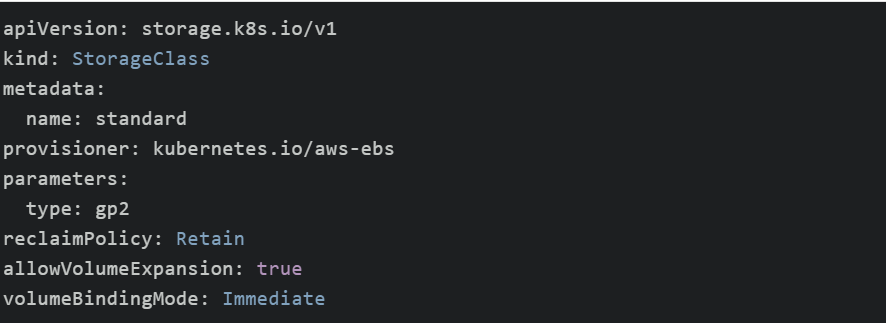
type参数可配置选择不同的EBS卷类型。
声明StorageClass后就可以使用PVC了,如下申请30GB的volume。
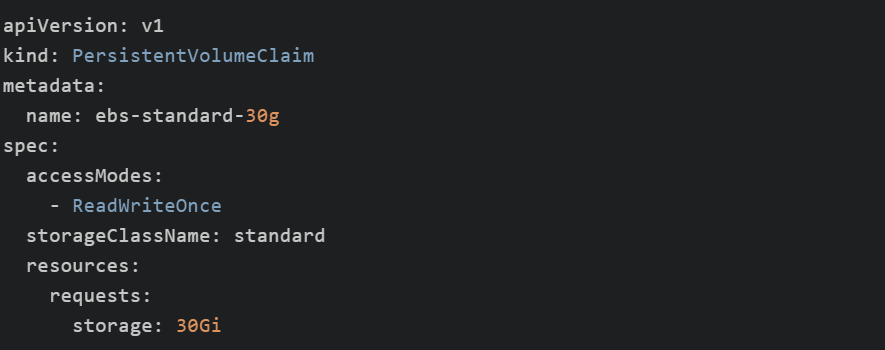
查看kuberctl资源:
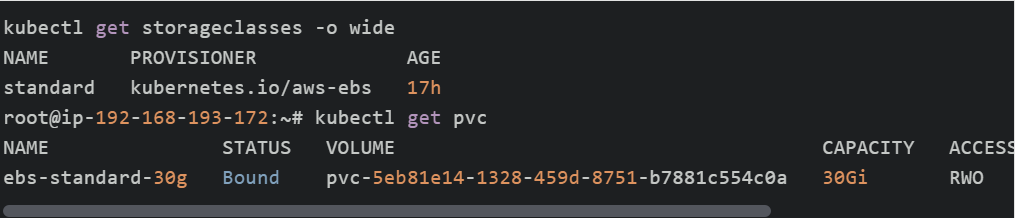
在AWS上可以发现对应的volume已经创建出来:

volume会自动打上Kubernetes集群以及PVC的元数据标签。
创建一个ngix Pod使用这个PVC:

在AWS上查看volume状态:
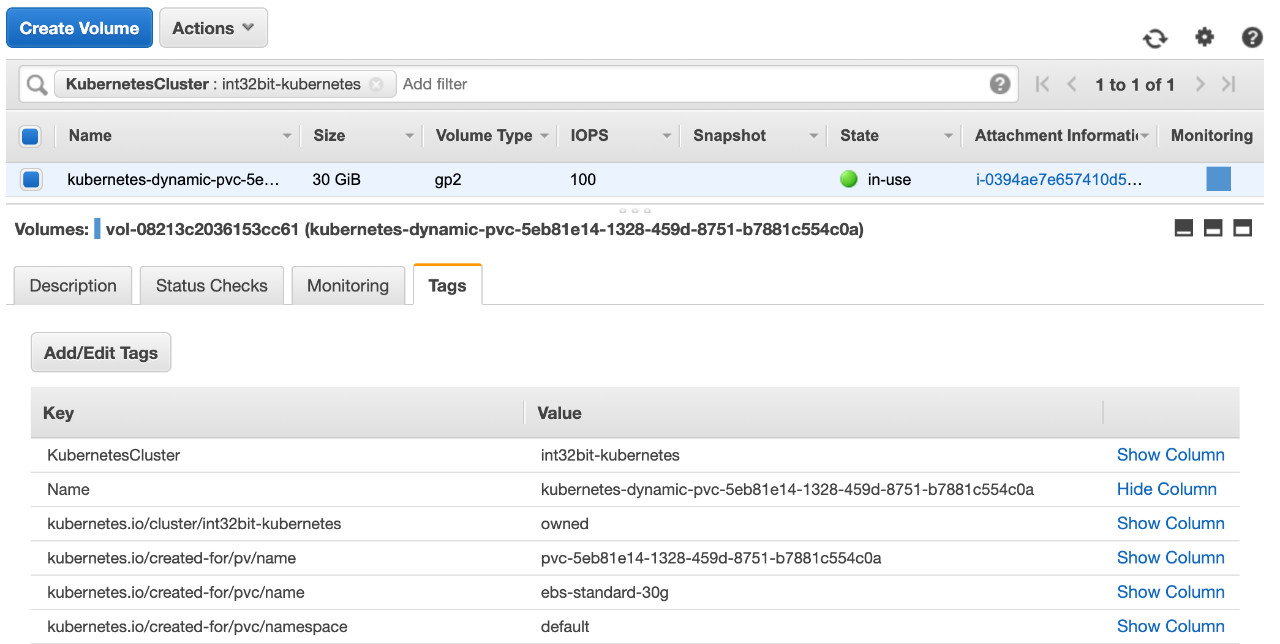
我们发现EBS volume自动挂载到了Pod所在Node的EC2实例上,在Node节点上可以确认:
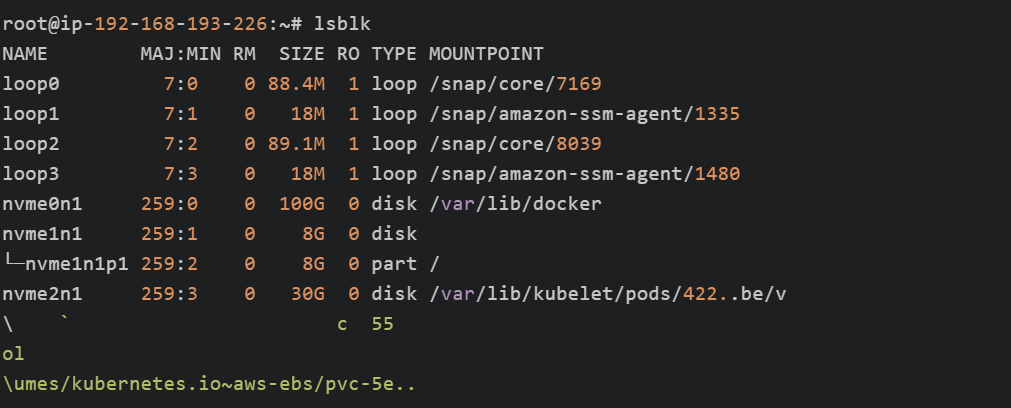
需要注意的是,由于EBS不支持跨AZ挂载,因此当Pod漂移到其他Node时可能导致Volume无法挂载的情况,不过Scheduler会自动根据Node的AZ元数据规避这种情况。
由上面的实验可知,Kubernetes通过声明一个AWS StorageClass指定EBS的卷类型,然后当声明一个PVC实例时,Kubernetes会自动根据StorageClass配置的元数据创建指定大小的Volume,当Pod声明使用Volume时,Kubernetes会把Volume挂载到Pod所在的Node EC2实例上,如果没有文件系统,则会自动创建文件系统,默认的文件系统类型为ext4.
4 Pod网络与VPC集成
在之前的文章聊聊几种主流Docker网络的实现原理中介绍了使用Flannel的aws-vpc后端实现容器的跨主机通信,其原理是把路由配置到AWS VPC路由表中。容器使用的网络IP地址是Flannel分配和维护的,和VPC的网络地址完全独立。这就会有一个问题,AWS VPC Peer为了防止IP/APR欺骗会强制检查目标IP地址,如果不是对端VPC的IP,则会直接丢弃,因此Flannel aws-vpc虽然能实现跨子网通信,但无法实现跨VPC的通信。
amazon-vpc-cni-k8s是AWS自己维护的开源项目,实现了CNI接口与AWS VPC集成,Pod能直接分配到与Node节点相同子网的IP地址,和EC2虚拟机共享VPC资源,使得Pod和EC2实例实现网络功能上平行,能够充分复用VPC原有的功能,如安全组、vpc flow logs、ACL等。并且由于Pod IP就是VPC的IP,因此能够通过VPC Peer隧道实现跨VPC通信。
4.1 amazon-vpc-cni-k8s配置
配置使用amazon-vpc-cni-k8s很简单,需要注意的是由于使用这种方案,Node节点可能会自动添加多张网卡,因此在kubeadm配置中最好选择主网卡的IP作为Node IP,另外podSubnet需要配置为VPC的CIDR,如下:

kubeadm init之后需要部署aws-node daemonset,下载yaml声明文件如下:
curl -sSL -O https://raw.githubusercontent.com/aws/amazon-vpc-cni-k8s/master/config/v1.5/aws-k8s-cni.yaml
国内网络环境需要把image从 602401143452.dkr . ecr . us - west - 2.amazonaws . com / amazon - k8s - cni : v1 . 5.3改为 lmh5257 / amazon - k8s - cni : v1 . 5.3。
使用如下命令部署:
kubectl apply -f aws-k8s-cni.yaml
部署完后由于版本的问题,所有的Node节点可能需要修改 /etc/ cni / net . d / 10 - aws . conflist文件,添加 cniVersion版本信息并重启kubelet服务:
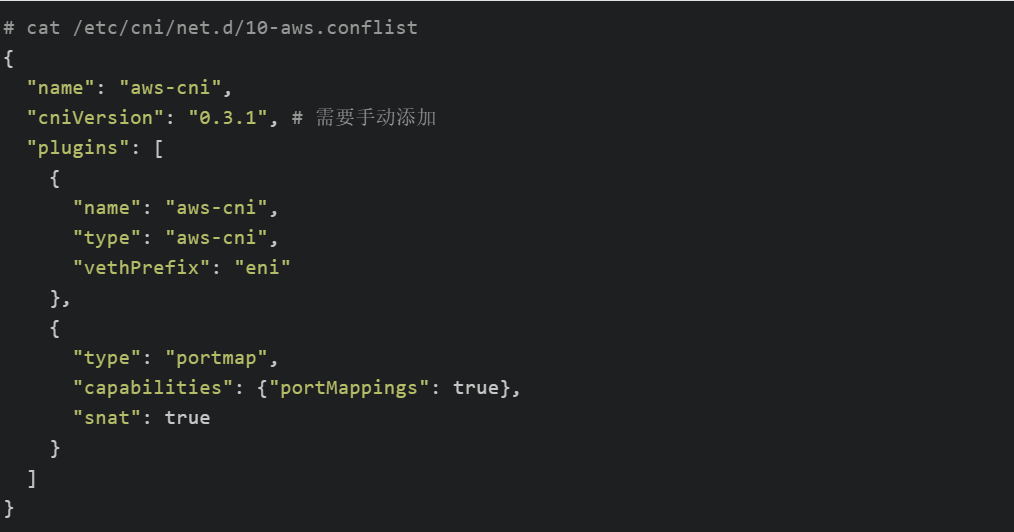
使用Ubuntu AMI的EC2实例建议关闭ufw功能,新版本的Docker会把iptables的FORWARD Policy设置为DROP,参考https://github.com/moby/moby/issues/14041,这将导致Node节点无法转发包,需要手动调整所有Node节点FORWARD policy为ACCEPT:
iptables -P FORWARD ACCEPT
AWS EKS AMI则是通过iptables restore持久化如上配置:

4.2 amazon-vpc-cni IP地址分配原理
前面提到Pod使用的是AWS VPC的子网IP地址,而Pod是运行在EC2实例上,因此首先需要把IP分配给Pod所运行的EC2实例。如何实现?答案是给EC2实例的eni配置多IP,eni(Elastic Network Interfaces )即虚拟网络,类似OpenStack Neutron的port,而AWS所谓的给eni分配多个IP地址,其实就是类型于OpenStack Neutron port的allowed address pairs功能。
但是AWS的eni能够支持分配的IP个数是有限的,如何解决这个问题呢?答案是给EC2实例再绑定一个eni网卡。这样假设一个EC2实例最多能绑定N个eni网卡,每个eni能给分配M个IP,则一个EC2实例可以最多拥有 N M个IP,除去EC2实例host的每个eni需要占用一个IP,则一个EC2实例可以分配的POD IP地址数量为 N M - N,换句话说,一个Node节点至多同时运行 N * M - N个Pod。不同的EC2实例类型N和M的值都不一样,参考AvailableIpPerENI。以 c5 . large为例,能够支持绑定的eni数量为3,每个eni最多关联10个IP地址,则该节点最多能够运行27个Pod。而 c5 . xlarge能够支持最大的eni数量为4,每个eni最多可关联15个IP,则该节点最多可以运行56个Pod。生产部署时应充分考虑这种限制,选择适合的EC2实例类型。
aws-node agent会维护每个节点的IP地址池,当Node的可用Pod IP小于某个阈值时会自动调用AWS API创建一个新的eni分配IP地址并关联到该EC2实例,而当Node的可用Pod IP大于某个阈值时则会自动释放eni以及IP地址。
我们可以查看Node节点的EC2实例的信息如下:

可见aws-node已经预先添加了一个eni接口并分配了20个IP。
4.3 amazon-vpc-cni网络通信原理
东西流量
为了研究网络原理,我们exec进入容器查看网络信息:
kubectl exec -t -i kubernetes-bootcamp-v1-c5ccf9784-6sgkm -- bash
ip a
- 3: eth0@if10: mtu 9001 qdisc noqueue state UP group default
- link/ether 7a:45:bf:f9:f5:44 brd ff:ff:ff:ff:ff:ff
- inet 192.168.193.214/32 brd 192.168.193.214 scope global eth0
- valid_lft forever preferred_lft forever
ip r
- default via 169.254.1.1 dev eth0
- 169.254.1.1 dev eth0 scope link
ip neigh
- 192.168.193.194 dev eth0 lladdr fe:2c:94:74:24:25 STALE
- 169.254.1.1 dev eth0 lladdr fe:2c:94:74:24:25 PERMANENT
看过我之前的文章聊聊几种主流Docker网络的实现原理可以发现,和Calico非常类似,容器的IP是32位的,网关为一个假IP 169.254.1.1(IP其实是什么无所谓),而这个假IP的MAC地址为veth对端eni eni7efd263cb92的MAC地址。换句话说,从容器出去的包会把MAC地址修改为veth pair对端eni eni7efd263cb92的MAC地址。
我们查看Pod所在的Node节点主机网络信息如下:
1.# ip a | grep -A 10 -B 1 fe:2c:94:74:24:25
- 10: eni7efd263cb92@if3: mtu 9001 qdisc noqueue state UP group default
- link/ether fe:2c:94:74:24:25 brd ff:ff:ff:ff:ff:ff link-netnsid 2
- inet6 fe80::fc2c:94ff:fe74:2425/64 scope link
- valid_lft forever preferred_lft forever
ip r
- default via 192.168.193.129 dev ens5 proto dhcp src 192.168.193.194 metric 100
- 192.168.193.128/25 dev ens5 proto kernel scope link src 192.168.193.194
- 192.168.193.129 dev ens5 proto dhcp scope link src 192.168.193.194 metric 100
- 192.168.193.214 dev eni7efd263cb92 scope link
目标为192.168.193.214,转发给 eni7efd263cb92,即容器veth,从而实现了容器入访的流量分发,入访没有问题。
问题是每个Node都有可能有多个相同子网的eni,那容器访问其他Pod容器的出访该如何走呢?我们可能会想到的办法是开启Linux内核rp_filter功能,但更优雅的做法是配置路由策略,根据分配的IP属于哪个eni决定从哪个eni转发出去:
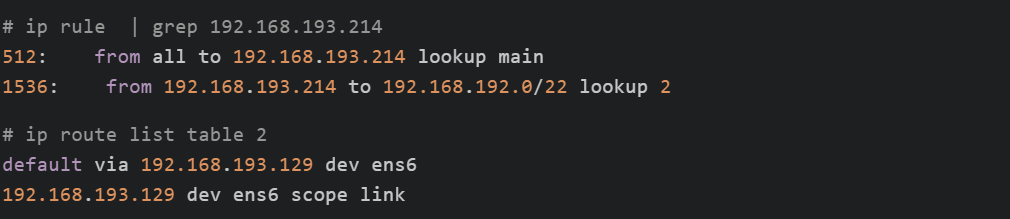
可见凡是Pod 192.168.193.214访问其他容器的出访都使用table 2,而table 2的默认出口为ens6,这个正是aws-node分配的eni。
南北流量
我们查看iptables规则如下:
- -A POSTROUTING -m comment --comment "AWS SNAT CHAN" -j AWS-SNAT-CHAIN-0
- -A POSTROUTING -m comment --comment "AWS SNAT CHAN" -j AWS-SNAT-CHAIN-0
- -A AWS-SNAT-CHAIN-0 ! -d 192.168.192.0/22 -m comment --comment "AWS SNAT CHAN" -j AWS-SNAT-CHAIN-1
- -A AWS-SNAT-CHAIN-1 -m comment --comment "AWS, SNAT" -m addrtype ! --dst-type LOCAL -j SNAT --to-source 192.168.193.194 --random
可见POSTROUTING会跳到AWS-SNAT-CHAIN-0子链,这个子链会判断如果不是VPC网段的(即不是Pod网段),则跳到AWS-SNAT-CHAIN-1子链处理,而这个AWS-SNAT-CHAIN-1子链的任务其实就是把源IP改为主网卡的IP。
更多关于aws-vpc-cni的设计文档可参考Proposal: CNI plugin for Kubernetes networking over AWS VPC。
5 Service与四层负载均衡集成
Kubernetes通过Service暴露服务,这个和传统数据中心暴露服务的方式其实是一样的,这个Service就是类似四层负载均衡的功能,因此可以认为Service就是一个虚拟四层防火墙,理解这个很重要。因为我们经常误以为Service是和Pod绑定的,实际上Service与Pod是完全松耦合的,Service后端其实绑定的是逻辑的Endpoint,这个Endpoint就是类似于负载均衡的Member。
Endpoint除了可以关联Pod,甚至支持关联集群外部已有的服务,Kubernetes做的只是根据Selector自动把Pod IP添加到Endpoint中。prometheus的外部exporter,Kubernetes就显然无法自动发现,必须通过手动修改Endpoint列表实现。
目前Kubernetes Service除了主要支持的类型为ClusterIP、NodePort以及LoadBalancer,但其实后两者都是在ClusterIP实现之上的功能叠加。
ClusterIP默认会分配一个虚拟IP,通过IPtables转发到Pod IP中。NodePort则相当于在ClusterIP的基础之上做了个Node节点的IP NAT映射,使得外部能够通过Node的IP与Service通信,与Docker的 - p参数的实现原理类似。
为了研究LoadBalancer实现原理,首先以AWS为例创建一个LoadBalancer Service:

以上需要注意的是要添加 service . beta . kubernetes . io / aws - load - balancer - type注解,否则创建的是AWS Classic Load Balancer,这种负载均衡AWS已经废弃不推荐使用了,因此需要指定创建的Load Balancer类型为 nlb(Network Load Balancer)。
查看创建的Service:
kubectl get service kubernetes-bootcamp-v1
- NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
- kubernetes-bootcamp-v1 LoadBalancer 10.105.6.241 a...3.elb.cn-northwest-1.amazonaws.com.cn 8080:31905/TCP 13h
可见Service的 External - IP为 nlb的域名,在 Port ( s )中我们发现该Service分配了一个NodePort。
我们在AWS上查看该负载均衡如下:
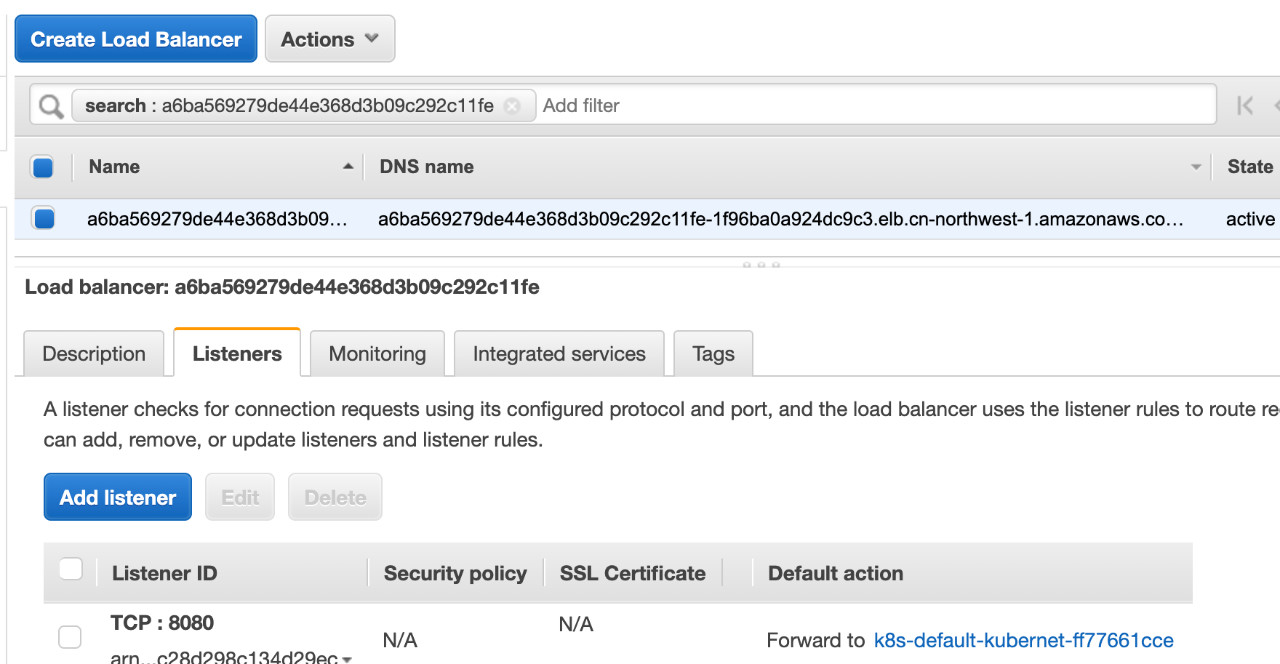
Listener为Service指定的Port值。 我们查看其target group如下:
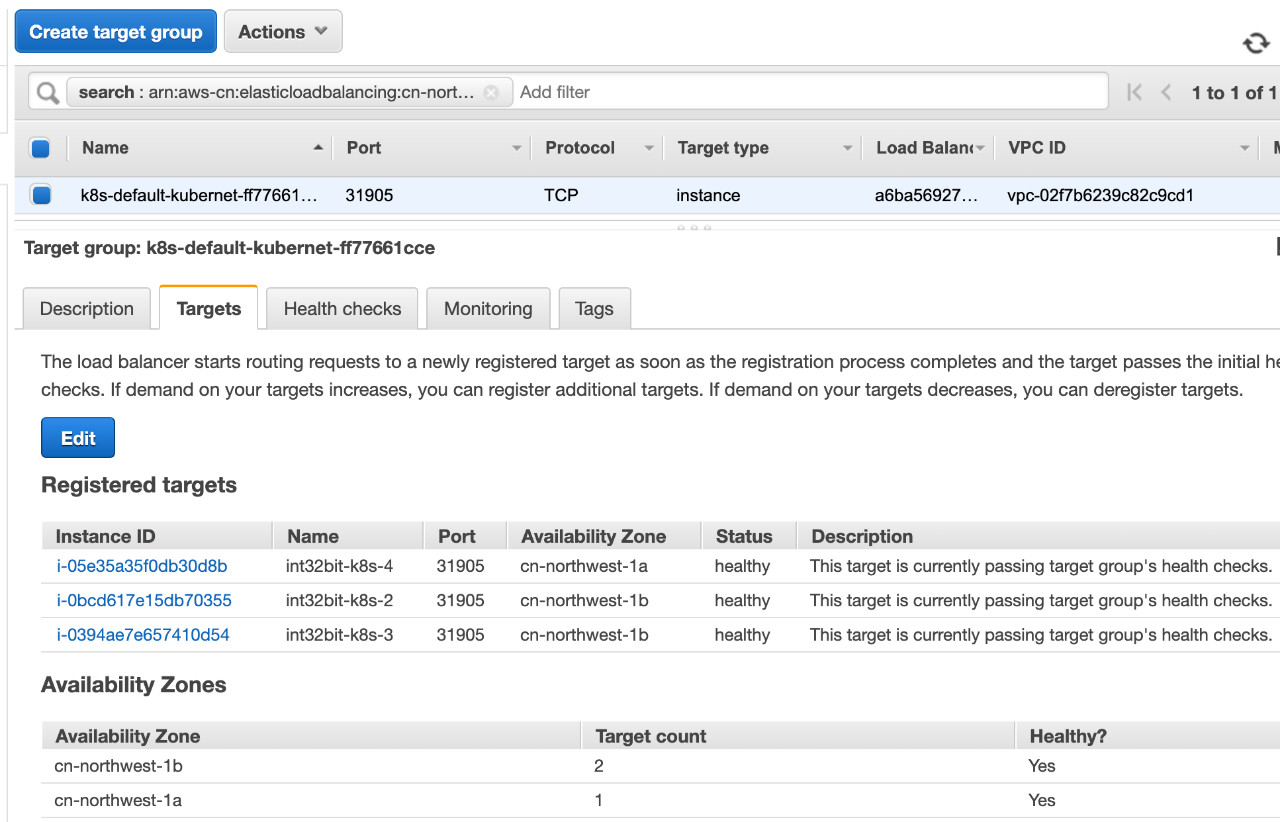
可见Targets为Node节点的IP以及Node Port端口。
由此可见LoadBalancer是在NodePort的基础之上,再通过IaaS云平台创建一个四层负载均衡,并把Node以及Node端口添加到后端Member列表中。
6 Ingress与七层负载均衡集成
Service是基于TCP协议的4层端口分发服务,而Ingress则使用了七层的应用层协议进行服务分发,这里的应用指基于HTTP或者HTTPS协议的Web服务。Ingress可以认为是对Service的再次包装转发,支持基于主机名和URL路径匹配的规则转发。
目前支持基于Haproxy、Ngnix、Kong等实现Ingress,但使用比较多的Ingress是基于Nginx的反向代理实现的NginxController。而本文将使用AWS ALB Ingress Controller,从名字上可看出是基于AWS的ALB(Application Load Balancer)实现的。
Kubernetes的所有Ingress都需要手动配置安装,AWS ALB Ingress Controller也不例外。
首先配置RBAC角色:
kubectl apply -f https://raw.githubusercontent.com/kubernetes-sigs/aws-alb-ingress-controller/v1.1.3/docs/examples/rbac-role.yaml
下载ALB ingress controller声明文件:
之所以不是直接 kubectl apply而是先要下载下来,是因为我们需要稍微修改下配置。
首先需要去掉 -- cluster - name =注释,并填写cluster name。其次如果Node节点EC2实例没有配置IAM Role,则需要在声明文件中配置AKSK,我们已经关联了IAM Role,因此会自动从metadata中获取STS,不需要配置AKSK。
完成配置之后apply创建controller:
kubectl apply -f alb-ingress-controller.yaml
此时会在kube-system namespace下创建一个 alb - ingress - controller Deployment,Deployment会通过ReplicaSet基于 amazon / aws - alb - ingress - controller镜像启动Pod。
接下来我们创建一个Ingress实例如下:
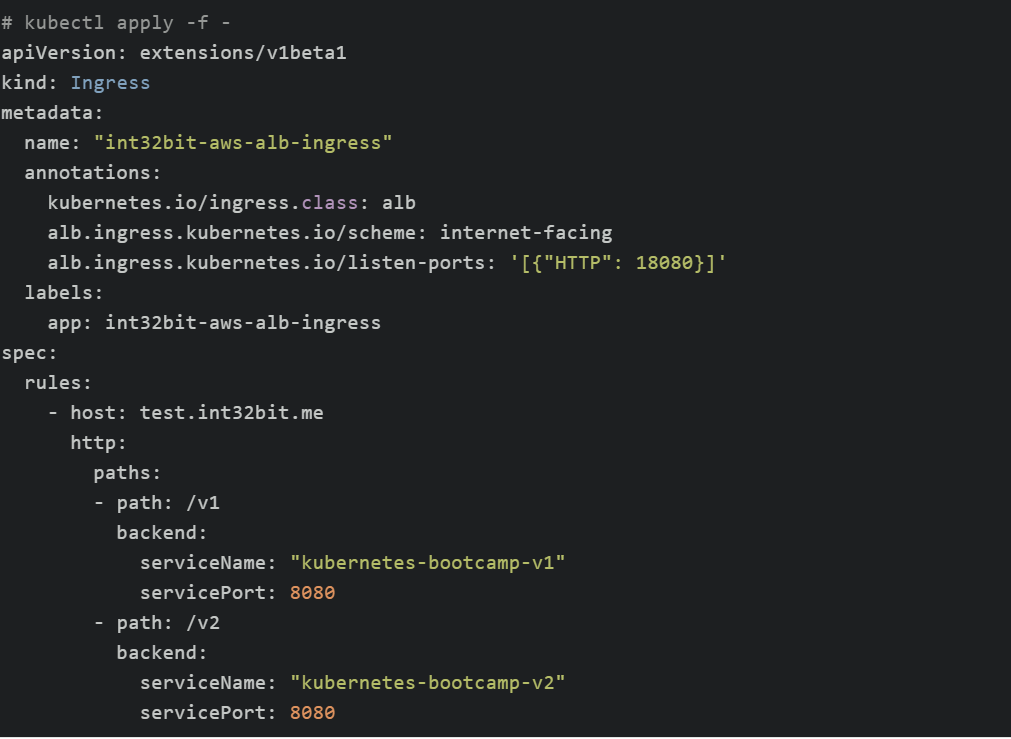
如上定义的访问规则为:
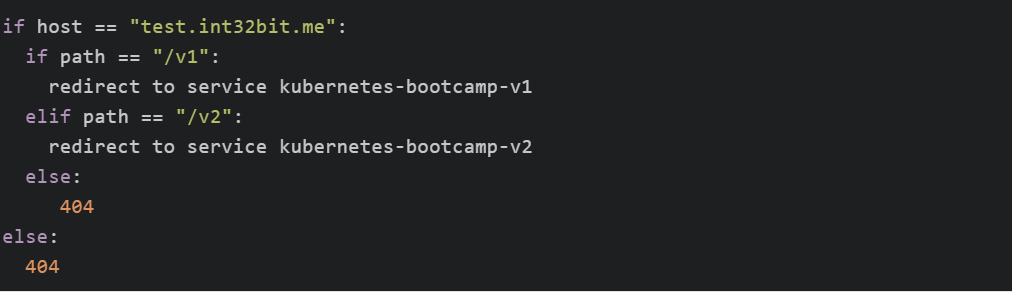
另外需要注意的是Kubernetes默认创建的是 internal alb,只能VPC内部访问,如果需要暴露给互联网,需要通过 alb . ingress . kubernetes . io / scheme注解配置alb类型为 internet - facing。ALB默认监听的HTTP端口为80,HTTPS端口为443,由于这些端口均需要ICP备案,因此这次测试通过 alb . ingress . kubernetes . io / listen - ports配置监听器的HTTP端口为 18080。
我们查看创建的Ingress实例:
kubectl describe ingresses.
- Name: int32bit-aws-alb-ingress
- Namespace: default
- Address:82e05f75-default-int32bita-5196-1991518503.cn-northwest-1.elb.amazonaws.com.cn
- Default backend: default-http-backend:80 ()
- Rules:
- Host Path Backends
- test.int32bit.me
- /v1 kubernetes-bootcamp-v1:8080 (10.244.3.241:8080,10.244.4.6:8080,10.244.5.2:8080)
- /v2 kubernetes-bootcamp-v2:8080 (10.244.3.242:8080,10.244.4.7:8080,10.244.5.3:8080)
- Annotations:
- alb.ingress.kubernetes.io/scheme: internet-facing
- kubernetes.io/ingress.class: alb
- alb.ingress.kubernetes.io/listen-ports: [{"HTTP": 18080}]
其中Address为ALB的DNS域名。为了访问我们的Ingress服务,通常还需要到域名服务器上添加一个CNAME记录test.int32bit.me到这个域名,这里为了测试直接修改了本地/etc/hosts文件:
dig +short 82e05f75-default-int32bita-5196-1991518503.cn-northwest-1 .elb.amazonaws.com.cn
- 52.83.70.253
- 161.189.46.130
echo "161.189.46.130 test.int32bit.me" >>/etc/hosts
此时我们访问Ingress服务如下:
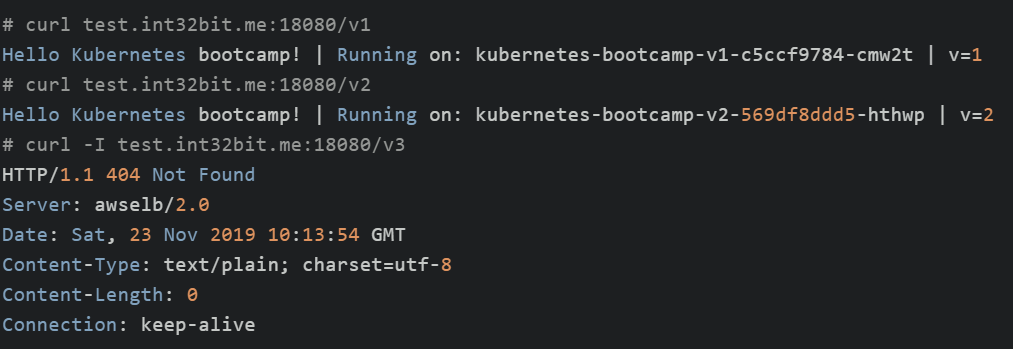
可见Ingress针对我们的访问路径进行了Service正确转发。
我们查看AWS ALB:
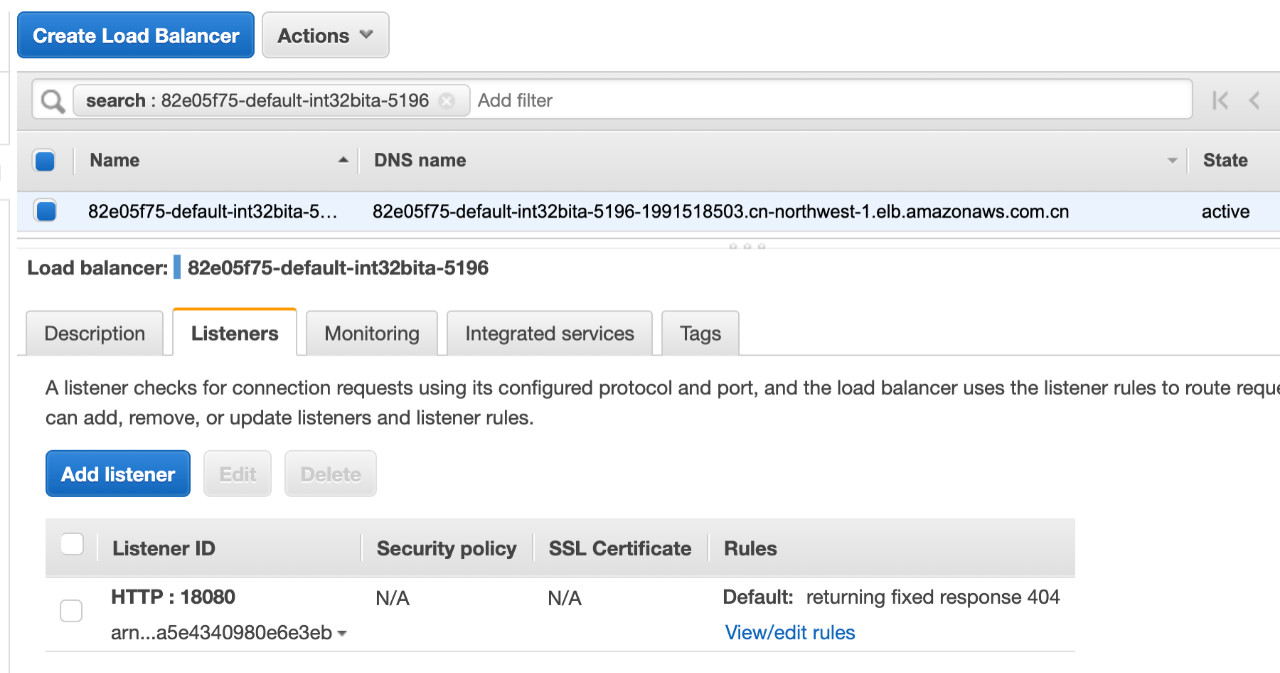
其中Listener监听的端口为我们Ingress配置的HTTP端口。
我们查看规则如下:

和我们Ingress配置的规则一一对应,根据不同的虚拟主机名和路径转发到不同的target group。
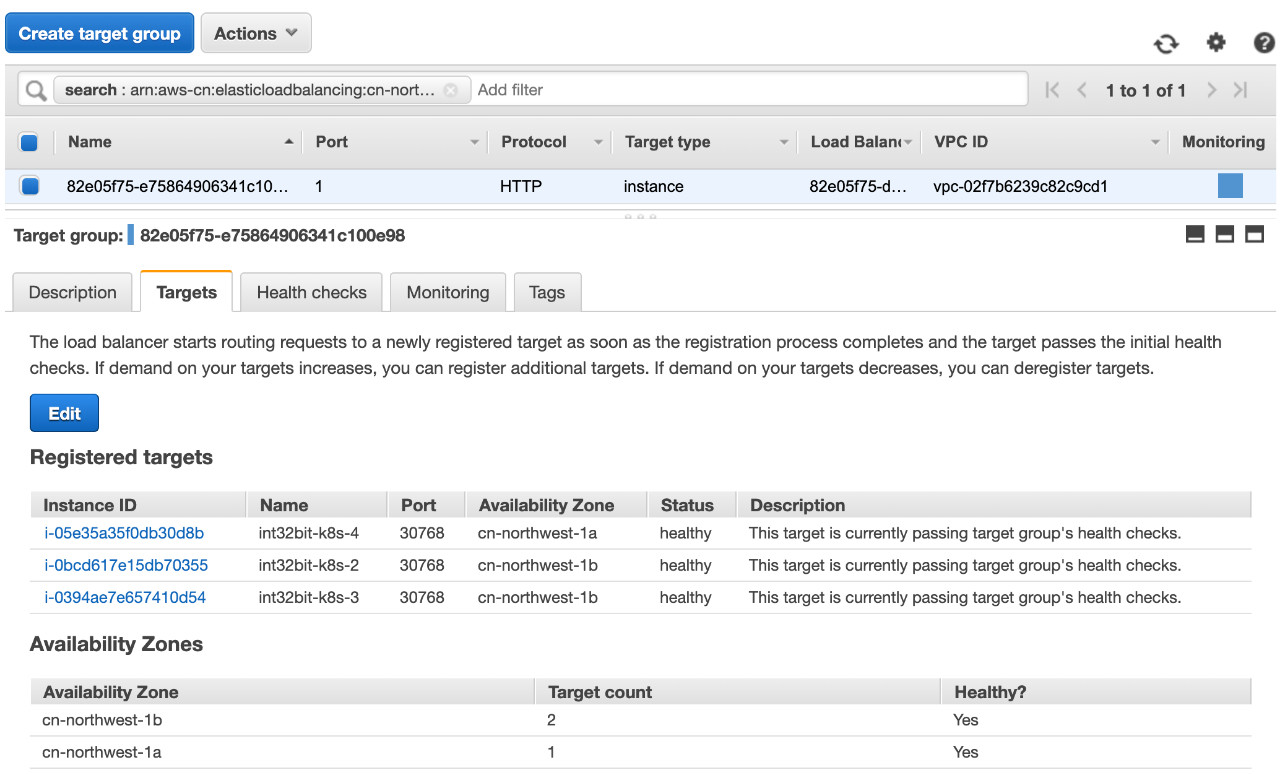
我们发现target group和前面的LoadBalance配置完全一样,都是把Node的IP以及NodePort加到targets中。 这也意味着添加到Ingress的Service必须是NodePort类型,当然LoadBalancer也是通过NodePort实现,因此也是没有问题的。
7 Cluster Autoscaler与AUTO SCALING
Kubernetes的Cluster Autoscaler功能能够实现Node节点的弹性伸缩,当Node节点资源不足时能够自动创建新的Node节点来运行Pod,并且自动迁移Pod到新的Node上。
这个功能依赖于云平台的AUTO SCALING功能,目前很多云平台都支持这个功能,比如OpenStack就支持通过Heat或者Senlin实现自动伸缩,社区已经实现运行在OpenStack Magnum之上的Kubernetes平台弹性伸缩,参考Cluster Autoscaler for OpenStack Magnum。
AWS的AutoScaling与CloudWatch、LoadBalancer组合可以实现无状态服务的自动伸缩,目前也已经实现利用AWS的AutoScaling实现Kubernetes的Node节点弹性伸缩,参考Cluster Autoscaler on AWS。
7.1 AWS AutoScaling配置
首先在AWS上创建一个Launch Configuration以及Auto Scaling Group(ASG)
Launch Configuration选择已经安装好Docker和kubelet、kubeadm、kubectl的AMI快照,并传递如下userdata数据:
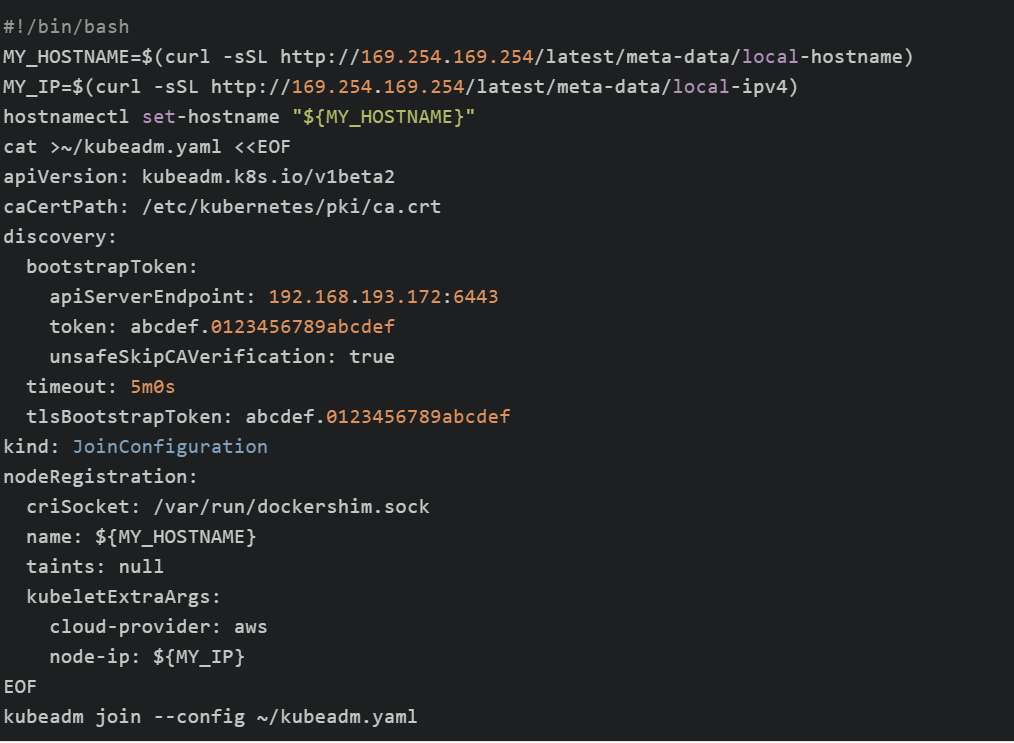
ASG打上如下两个标签:
- k8s.io/cluster-autoscaler/enabled: 1
- k8s.io/cluster-autoscaler/int32bit-kubernetes: 1
7.2 安装Cluster Autoscaler
下载Cluster Autoscaler,修改 -- node - group - auto - discovery参数使结果与ASG打的标签保持一致。
Ubuntu需要修改volume的ssl-certs host-path为/etc/ssl/certs/ca-certificates.crt,另外image建议修改阿里云源: registry . cn - hangzhou . aliyuncs . com / google_containers / cluster - autoscaler : v1 . 12.3。
修改完毕后apply。
7.3 验证AutoScaling功能
我们创建如下nginx Deployment:

此时由于资源不足,Pod状态为pending:
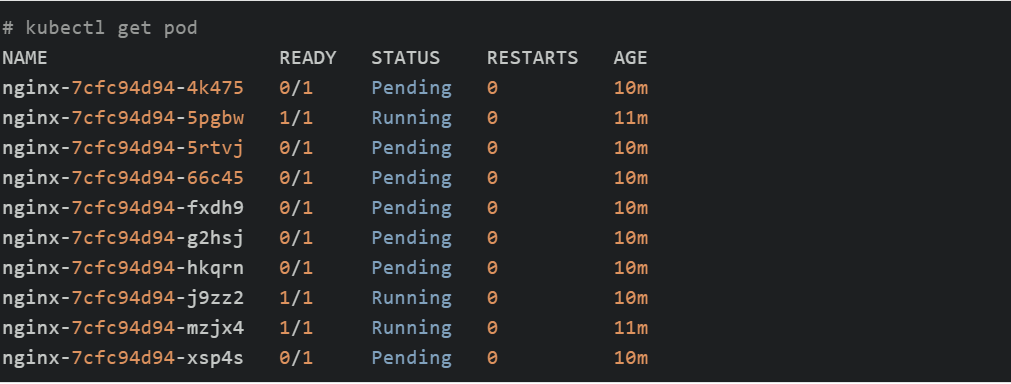
查看cluster-autoscaler日志如下:

可见日志报node资源不足,增加节点个数为4。
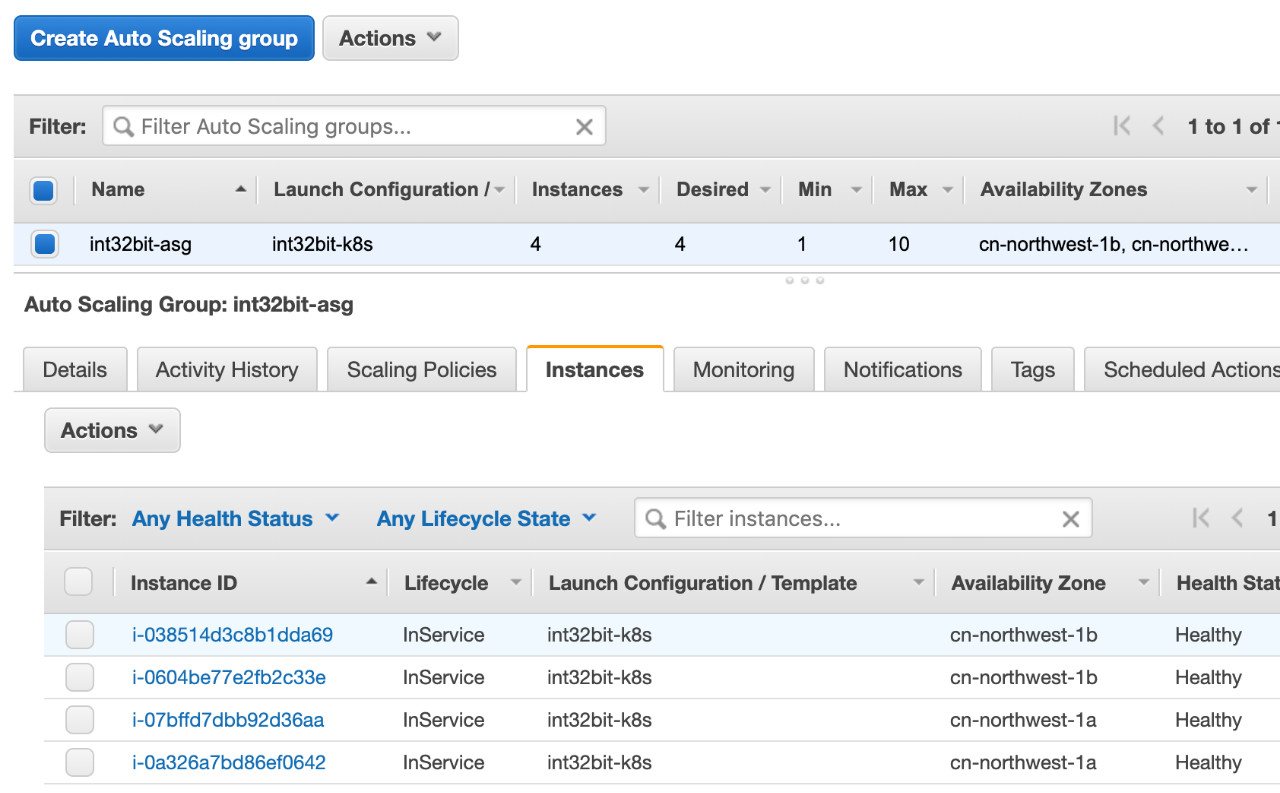
查看AWS ASG发现新启动了4个EC2实例:
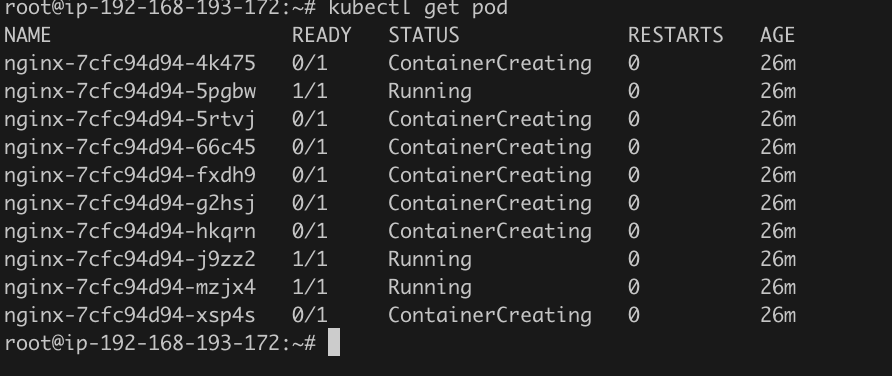
等了大概5分钟后发现新的node添加进来了:

并且nginx Pod也正在创建:
8 总结
本文以AWS为例,介绍了Kubernetes的Pod网络、PVC、Service、Ingress、Cluster Autoscaler与IaaS资源的融合,我们发现Kubernetes和底层IaaS资源不是完全割裂的,而是可以相互配合。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞3作者其他文章
评论 0 · 赞 1
评论 0 · 赞 2
评论 1 · 赞 3
评论 0 · 赞 1
评论 1 · 赞 5
添加新评论0 条评论