
DB2数据库SQL调优技巧
本文的目标
• 了解是什么让查询、程序和应用程序执行的效率很差。
• 帮助开发人员、 DBA 更好地理解 SQL 优化是什么,包含哪些内容
• 开始学习 SQL 编程标准和指南
• 学习新版本上的一些新的优化特性
优化 sql 的必要性
DBA 应该给开发人员给出 sql 方面的优化建议。数据库管理员在日常工作中,除了在数据库层面如给出调整 bufferpool 、 sortheap 、 locklist 、索引和统计信息等建议外,有时有必要告诉或者提醒开发人员怎样优化 sql 。因为如果要彻底解决某些应用的性能或者效率低的问题,必须要优化 sql 才能解决。
另外数据库的开发人员也应该始终将 SQl 性能考虑在内。程序员在开发程序或应用时有两个目标,第一是快速的完成某个功能,获取正确的数据结果 二是尽快得到结果。但是常常忽略了第二个目标。他们要么不知道如何让程序运行得更快,要么就责怪运行环境中的其他部分 ( 如数据库、网络、工作站、操作系统等等 ) 。要么基于数据量认为处理数据所花费的时间是已经很不错了。那么这时开发人员怎么来发现问题,怎么提高应用的执行效率呢?
从那些方面考虑提高 sql 的性能
那么到底从那些方面来考虑如何提高 SQL 或者程序执行的性能呢?我们看一个简化的访问图: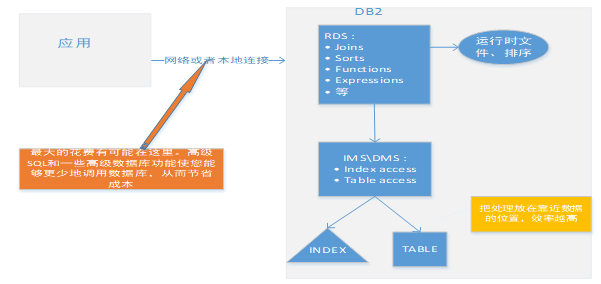
应用程序通过网络或者本地连接来访问数据库,通常最大的开销有可能是在花费在应用和 db2 之间的切换,或者说如果程序和 db2 之间往返的太多,也会影响到效率。我们应该最小化 db2 的 sql 请求次数 ,应该将一些代码交个 db2 来做而不是让程序来做,这对于程序的性能调优非常重要,尤其是批处理程序,因为它们倾向于处理更多的数据。每次将 SQL 发送到数据库管理器执行时,事实上是从操作系统中的一个地址空间到 Db2 的地址空间,然后再执行,这种情况是会有性能开销的。另外,一般来说,应需要尽量减少打开 / 关闭时间游标的数量以及随机 SQL 请求的数量 ,尽量多行获取、更新和插入、使用递归的 SQL 、 Select from insert 、 merge 处理、。(当然这些修改和程序员的经验和业务处理 有很大的关系)。
当然除了应用和 db2 交互之间的消耗, SQL 本身的效率也至关重要。那我们再来看看在 db2 内部到底是什么导致了 SQL 查询效率低下 ? 在这之前我们先看看 sql 是怎么执行的。 Sql 执行包含了解析查询、检查语义、重写查询、聚合、优化访问计划、远程 SQL 生成(仅限联合数据库)最后生成可执行代码(这个是 db2 的 rds 组件生成的, RDS 是 Db2® 处理访问或操作数据库内容的请求的组件)。
其中在访问计划生成的时候, Db2 的优化器综合 sql 、对象的定义及统计信息等信息,生成访问数据的路径。
在某些情况下,优化器可以选择将排序或聚合操作从 RDS 下推到数据管理服务( DMS )。( DMS 是控制创建,删除,维护和访问数据库中表和表数据的 Db2 组件。)压低这些操作通过允许 DMS 将数据直接传递到排序或聚合例程来提高性能。没有此下推功能, DMS 首先将这些数据传递给 RDS ,然后由 RDS 与排序或聚合例程对接。 RDS 处理更复杂的谓词,比如 join 、 sort 、 function 、 expression 等。 rds 要比 dms 、 ims 花费更大的开销 ,主要由于附加的处理和额外的代码路径。
RDS 不能有效地使用索引。如果你的 sql 包含了 Residual 谓词 (ANY, ALL, SOME, or IN, 或者访问了 lob 的数据 ) 或者做了额外的 sort 、 Distinct / Group By / Order By ,或者使用了 union ( 原本使用 UNION ALL 就足够)。等等这些情况都会造成 db2 消耗过多的资源,导致效率低下 .
在数据访问阶段, 索引管理器负责评估谓词是否可以索引, 一些简单的谓词(可索引)在这个阶段通常评估为使用相对较少的开销, DMS 负责将其中的数据将页转换为行和列的结果集。 但是如果你的使用了较差的谓词那么数据管理服务有可能评估为较大的开销 ,执行计划的效率会很差,例如:你的 SQL 没有使用索引而执行表扫描,或者你的 SQL 没有使用索引来满负荷运行 ( 或者索引扫描执行了过多的筛选 ) ,或者你的 SQL 语句获取了额外的列或者额外的行。
总结,从上来看,程序执行效率低涉及的调优的地方包括统计信息、谓词、索引、排序等,另外应用和数据库太频繁的交互也会造成效率底下,那么到底有哪些调优技巧呢?
具体的调优技巧
应用开发人员或者 dba 在日常的工作中,到底用哪些 sql 相关的调优技巧呢?
关于统计信息的调优
调优技巧 1 基本的 runstats
所有环境中的所有表都应该运行以下统计信息 :
- 所有表中所有列的基数统计 包括表的大小 ( 行数 ) 、列的基数 数据和索引文件的物理特性
runstats on table tabname and indexes all
- 分布统计信息 包括分布不均匀的任何列的频率值统计 、分位数统计 ( 统计的进一步细分 )
runstats on table tabname with distribution and indexes all
分布统计信息对于不使用主机变量的动态和静态查询最有用。在评估包含主机变量的查询时,优化程序会限制使用分布统计信息 所以分布统计信息对于 java 等动态的 sql 是非常有用的。另外分位数统计 ( 统计的进一步细分 ) ,帮助处理 range 谓词、 between 谓词 和 like 谓词。特别是在存在数据分布“热点”的地方。
调优技巧 2 确保正在处理的表中的数据分布统计信息是最恰当的。
通常我们听到最多的就是保持表的统计信息是最新的,但是应该把这个分开来看,对于重要的有专门维护人员的系统,因该保持不要轻易更新统计信息,因为我们我们知道业务数据的变化情况,在大多数的情况下是在一个较稳定的范围内的。对于那些没有专人维护的系统,那么统计信息因该周期性的或者自动的更新统计信息,这个时候你应该关注下 表的 stats_time (syscat.tables) 应保持最新。注意声明为 Volatile 的表,不管统计信息怎样会一直使用索引访问。
Select tabname,stats_time from syscat.tables order by stats_time
关于表扫描和索引调优
调优技巧 3 注意表扫描。
当你的执行某个功能或者 sql 的时候发现大量的 io ,并且看到了表的扫描。那么有什么情况会导致这样呢,
谓词可能以不可索引的方式进行编码。
查询中的谓词不匹配表上的任何可用索引。
表可能很小, Db2 认为表空间扫描可能比索引处理更快。
目录统计信息显示表很小,或者表上没有统计信息。
某些谓词的使用,使 Db2 认为查询将检索足够多的数据,所以出现表扫描
某些谓词的使用,使 Db2 选择一个非集群索引,要检索的页面数是相比表中的总页数足够高,所以需要进行表空间扫描。
表文件或索引文件可能在物理上残生大量的碎片,需要 reorg 。
注意:大量 index scan 随机 io 可能比表扫描带来更大的 io 问题 顺序的 io 消耗的资源少
调优技巧 4 尽量让谓词可索引
谓词是 SQL 语句中比较操作的搜索条件的元素。谓词可以分为四类,这些类别由在评估过程中使用谓词的方式和时间决定。具体类别如下:
l 范围分隔谓词是用于括号索引扫描的谓词 ; 它们为索引搜索提供开始或停止键值。这些谓词由索引管理器评估。
l 索引 sargable 谓词不用于括号搜索,但如果选择了一个,则从索引中进行求值,因为谓词中涉及的列是索引键的一部分。这些谓词也由索引管理器评估。
INDEX IX1: NAME ASC, DEPT ASC, MGR DESC, SALARY DESC,YEARS ASC
Where name = :hv1 and dept = :hv2 and years > :hv5
如上 name = :hv1 and dept = :hv2 就属于范围定界的谓词 让 years 就属于索引 sargable 优化程序在评估这些谓词时使用索引数据而不是读取基表。 Index-SARGable 谓词减少了需要从表中读取的行数,但它们不会影响访问的索引页数
l 数据 sargable 是索引管理器无法评估的谓词,但可以由数据管理服务( DMS )进行评估。通常,这些谓词需要访问基表中的各个行。如有必要, DMS 将检索评估谓词所需的列,以及满足 SELECT 列表中无法从索引获取的列的任何其他列。
INDEX IX0: PROJNO ASC
select projno, projname, respemp from project where deptno = 'D11'
order by projno
如上 deptno = 'D11' 就属于 数据 sargable
l 剩余谓词是那些除了简单访问基表之外还需要 I / O 的谓词。残差谓词的示例包括使用量化子查询(具有 ANY , ALL , SOME 或 IN 的子查询)或读取与表分开存储的大对象( LOB )数据的谓词。这些谓词由关系数据服务( RDS )评估,是四类谓词中最昂贵的。

由上面可以看到,我们在编写程序中遇到使用谓词的时候尽量使用范围定界、 sargable 的谓词 然后使用剩余谓词。那么哪些谓词是可以索引的呢
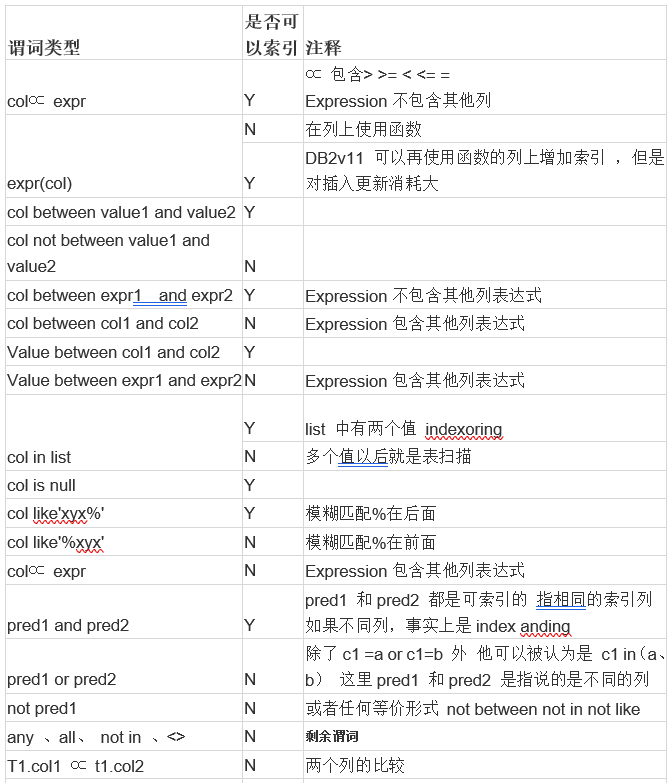
根据以上的原则以下几个例子就需要对应的优化。
例一 、不要在谓词的列上增加任何标量函数。
如前面所述因为这样表即使有索引,也无法使用到索引。例如,这是最常见的 :
SELECT EMPNO, LASTNAME FROM EMPLOYEE WHERE RTRIM(LASTNAME) = ‘Smith’SELECT EMPNO, LASTNAME FROM EMPLOYEE WHERE UPPER(LASTNAME) = ‘SMITH’
lastname 的索引并没有被选择上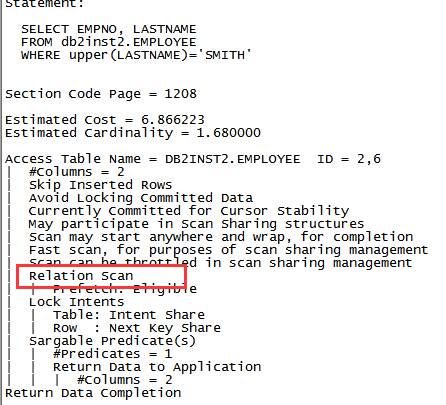
注意虽然 db2 11 支持了在表达上创建索引,但这种索引对插入、更新影响更大。 可能都需要修改下
例二 去掉谓词中列上的数学运算
例如,如下的 SQL 语句 ,虽然在 salary 、 hiredate 上创建了索引但是还是无法使用索引
SELECT EMPN, LASTNAME FROM EMPLOYEE WHERE SALARY * 1.1 > 50000.00
SELECT EMPNO, LASTNAME FROM EMPLOYEE WHERE HIREDATE-7 DAYS> ?
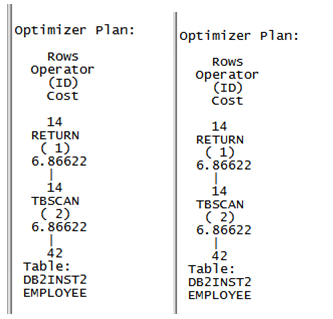
因该写成这样 , 然后才可以走到索引
SELECT EMPN, LASTNAME FROM EMPLOYEE WHERE SALARY > 50000.00 / 1.1
SELECT EMPNO, LASTNAME FROM EMPLOYEE WHERE HIREDATE > DATE(?) + 7 DAYS
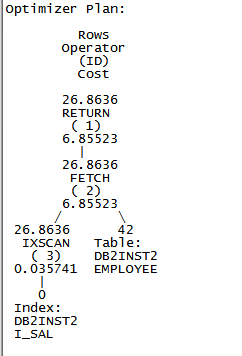
这样如果 salary 、 hiredate 上有索引那么很容易使用到索引。
例三 重写谓词
谓词写的不对就会有表扫描的情况 。根据上面的原则以下 sql 应稍作修改
WHERE value1 BETWEEN COLA and COLB
应该写成这样
WHERE value1 >= COLA and value1 <= COLB
WHERE COLA NOT BETWEEN value 1 and value2
应该写成这样
WHERE COLA < value1 or COLA > value2
WHERE HIREDATE + 1 MONTH > value1
应该写成这样
WHERE HIREDATE > value1 – 1 MONTH
SELECT EMPNO, LASTNAME FROM EMPLOYEE WHERE YEAR(HIREDATE) = 2005
应该写成这样 SELECT EMPNO, LASTNAME FROM EMPLOYEE WHERE HIREDATE BETWEEN ‘2005-01-01’ and ‘2005-12-31’
调优技巧 5 尽可能利用“ index-only ”处理
l Db2 不需要离开索引文件,索引的叶子结点包含了需要处理的结果集。
例如:
如果我们查找以 A 开头的 lastname 那么创建如下的索引后 , 访问计划就可以变成
index-only ,这个对 Io 消耗是最小的。另外对于应用中频繁调用的 sql 语句,
SELECT LASTNAME, MIDNIT, FIRSTNME FROM EMP WHERE LASTNAME LIKE ‘A% ORDER BY LASTNAME, FIRSTNME
Create index i_last on EMP LASTNAME, FIRSTNME, MIDINIT

l 可以使用 include 把 select 的列加入,以保证 sql 的执行计划 index-only 。 **
l 索引相关子查询 执行次数多,确保使用 index only
为了实现 SQL ,可以多次执行相关子查询请求。考虑到这一点,必须使用索引来处理子查询来缓解多个查询表扫描。如果相关的子查询执行了数十万或数百万次通常,最好确保子查询使用 index only 。这可能需要修改已经存在的索引。
比方说:
SELECT E.EMPNO, E.LASTNAME FROM EMPLOYEE E WHERE EXISTS (SELECT 1 FROM DEPARTMENT D WHERE D.MGRNO = E.EMPNO AND D.DEPTNO LIKE ‘D%’)
调优技巧 6 可能的话创建群集索引
表应该按照通常处理它们的顺序进行物理集群,确保表中数据的集群顺序可以处理大部分的频繁的数据查询,这确保了 “Get pages” 的数量最少处理,并可以利用顺序和动态预取。
群集索引的特点:
l 提高查询速度,数据页以键的顺序排列;避免排序
l 范围谓词大概率使用群集索引,速度快
l 另外对有价值的低基数值的查询是非常有效的
l 插入和更新需要做更多的事情,不建议经常插入和更新的表上做群集索引;
如果在系统运行中 有很多 带有“ List Prefetch ”和“ sort ”的查询,并且性能较差,那么群集索引可能会有用,另外如果有很多 join 是以外键进行的那么群集索引也有优化效果。如果使用非群集索引返回了大量的查询,这样改成群集索引也是有效的。
关于避免排序的调优
调优技巧 7 注意任何数据排序
排序成本较高。有时,一个 SQL 查询可能会执行多个排序以获取根据需要返回结果。
order by 、 group by 、 distinct 、 union 、 join 、或者子查询中都会产生排序 。用 Db2 explain 工具,看看是否有排序正在执行,然后查看 SQL 语句并确定是否可以执行其他的操作来避免排序。。
查看访问计划
db2expln -d sample -f 8.sql -g -t -z ";"

调优技巧 8 减少或者避免排序
如下** “ Distinct ” / “ Group By ”会导致排序,那么我们有没有其他的办法可以减少、或避免排序,‘ Distinct ’ or ‘ Group By ’ 会利用任何关联索引以消除用于惟一性的排序。
如上
select job from emp group job
db2 "create index i_job on employee(job)"
在使用了索引后就消除了排序, 并且 distinct 也被重写为 group

调优技巧 9 排序的时候不要多增加不需要排序的列,不要按你不需要的列来“排序”。
SELECT EMPNO, LASTAME, SALARY, DEPTNO FROM EMP ORDER BY EMPNO, LASTNAME, SALARY
这个例子中,我们只需要“ ORER BY EMPNO ”,因为它是惟一的列。
关于应用请求调优最小化对 Db2 的 SQL 请求
调优技巧 10 最小化对 Db2 的 SQL 请求
最小化对 Db2 的 SQL 请求 , 这对于程序的性能调优非常重要,尤其是批处理程序,因为它们每次向数据库管理器发送 SQL 调用时,有发送 SQL 语句到 Db2 的开销,实际上从操作系统一个地址空间到 Db2 地址空间然后执行 SQL 。一般来说,开发人员需要尽量减少 : 打开 / 关闭游标的数量,随机 SQL 请求的数量 尽量多行获取、更新和插入,使用递归的 SQL , Select from insert , merging 处理(当然这些修改和程序员的经验有很大的关系)。
另外反复访问相同的数据会消耗更多的资源, • 尽可能地注意你的代码,避免反复发出相同的 SQL 语句,避免多次处理相同的数据。如下的访问就可以合并为一个 sql
Select firstname,midinit,lastname,empno from emp where workdept=’A01’ AND SEX=’F’;
Select firstname,midinit,lastname,empno from emp where workdept=’A01’ AND YEAR(hiredate)>1999;
可以合并为
Select firstname,midinit,lastname,empno from emp where workdept=’A01’ AND
Sex=‘F’ OR YEAR(hiredate)>1999;
另外 可以将 • 将 UNION 更改为 CASE 语句可以提高性能,减少访问表的次数。
Select creator,TABNAME,'table' from sysibm.systables where type='T'
UNION
Select creator,TABNAME,'VIEW' from sysibm.systables where type='V'
UNION
Select creator,TABNAME,'ALAIS' from sysibm.systables where type='A'
ORDER BY TABNAME
Select creator,TABNAME,case type when 'T' THEN ‘table’
when 'V' THEN ‘table’
when 'A' THEN ‘table’ from sysibm.systables ORDER BY TABNAME
有时候,您可以重写和 SQL 语句来一次传递数据,否则会导致多次传递数据。
当然, db2 的优化器在重写查询以获得最佳访问路径方面变得越来越智能,所以这可能无关紧要。尽管如此,编写的效率越高,一次通过的 SQL 语句就会越好 !
调优技巧 11 最小化对 Db2 的 SQL 请求使用光标时使用多行获取多行更新的行集定位和获取,
Db2 支持在获取、更新插入处理时操作多行,旧版本的 Db2 只允许程序进行处理在游标处理期间,一次一行。现在具有获取、更新或一次插入超过一行可以减少网络流量和其他相关成本,每次调用 Db2 时。建议从 100 行获取、插入或更新开始,然后测试其他数字。
调优技巧 12 最小化对 Db2 的 SQL 请求 使用 select 刚刚插入 / 更新 / 删除的内容
使用 INSERT , UPDATE 或 DELETE 语句修改表的应用程序可能需要对已修改的行进行其他处理。为了便于此处理,可以在 SELECT 和 SELECT INTO 语句的 FROM 子句中嵌入 SQL 数据更改操作。在单个工作单元中,应用程序可以从 SQL 数据更改操作修改的表或视图中检索包含已修改行的结果集。这个功能利用到了 db2 的中间结果表:
SELECT 语句的 FROM 子句中 SQL 数据更改操作所针对的表或视图的已修改行组成了一个中间结果表。除了 SQL 数据更改操作中定义的任何包含列之外,中间结果表还包括目标表或视图的所有列。您可以在选择列表, ORDER BY 子句或 WHERE 子句中按名称引用中间结果表中的所有列。
中间结果表的内容取决于 FROM 子句中指定的限定符。必须在 SELECT 语句中包含以下 FROM 子句限定符之一,以将结果集检索为中间结果表。
OLD TABLE
中间结果表中的行将包含紧接在执行 before 触发器和 SQL 数据更改操作之前的点处的目标表行的值。 OLD TABLE 限定符适用于 UPDATE 和 DELETE 操作。
NEW TABLE
中间结果表中的行将包含在执行 SQL 数据更改语句之后,但在参照完整性评估和触发任何后触发之前的点处的目标表行的值。 NEW TABLE 限定符适用于 UPDATE 和 INSERT 操作。
FINAL TABLE
此限定符返回与 NEW TABLE 相同的中间结果表。此外,使用 FINAL TABLE 保证不会在触发器或参照完整性约束之后进一步修改 UPDATE 或 INSERT 操作的目标。 FINAL TABLE 限定符适用于 UPDATE 和 INSERT 操作。
FROM 子句限定符确定中间结果表中目标数据的版本。这些限定符不会影响目标表行的插入,删除或更新。
可以 select 以下信息:
l Db2 自动分配的标识列或序列值
l 开发人员不知道的用户定义的默认值和表达式
l 由触发器修改的列,根据值的不同,触发器可以在不同的插入之间进行修改
l 自动分配的 CURRENT TIMESTAMP ROWIDs
比方说:
db2 "select done_id from FINAL TABLE (insert into test (stock_name) values('123456'))"
DONE_ID
-----------
3
1 record(s) selected.
Db2 允许选择更新或更新之前的数据在同一语句中删除。
通过删除获取键值
db2 "SELECT done_id, stock_name FROM OLD TABLE (DELETE FROM test WHERE done_id= 2)"
DONE_ID STOCK_NAME
----------- ----------
2 123456
1 record(s) selected.
db2 "SELECT done_id, stock_name FROM OLD TABLE (UPDATE TEST SET STOCK_NAME='789' WHERE done_id= 3)"
DONE_ID STOCK_NAME
----------- ----------
3 123456
1 record(s) selected.
调优技巧 13 有时可以使用 merge
不要从表中选择一行来帮助决定代码中的逻辑应该执行更新还是插入 , 这样会增加 db2 的调用,有时可以使用 merge ( 或者叫 upsert )
例如
MERGE INTO EMPLOYEE E USING (VALUES ('000999', 'TONY', 'ANDREWS', 'A00',3445) ) AS NEWITEM (EMPNO, FIRSTNME,LASTNAME , WORKDEPT,EDLEVEL)
ON E.EMPNO = NEWITEM.EMPNO
WHEN MATCHED THEN UPDATE SET FIRSTNME = NEWITEM.FIRSTNME, LASTNAME = NEWITEM.LASTNAME ,EDLEVEL=NEWITEM.EDLEVEL
WHEN NOT MATCHED THEN INSERT (EMPNO, FIRSTNME, LASTNAME, WORKDEPT,EDLEVEL) VALUES (NEWITEM.EMPNO, NEWITEM.FIRSTNME, NEWITEM.LASTNAME, NEWITEM.WORKDEPT,NEWITEM.EDLEVEL);
Merge 可以按照条件实现 update 、 delete 、 ignore
MERGE INTO EMP E1 USING (SELECT EMPNO, SALARY FROM EMP WHERE WORKDEPT = 'A00') AS E2 ON (E1.EMPNO = E2.EMPNO)
WHEN MATCHED AND E1.SALARY >= 50000 THEN UPDATE SET E1.SALARY = E1.SALARY * 5
WHEN MATCHED AND E1.SALARY < 40000 THEN DELETE
WHEN MATCHED AND E1.SALARY < 50000 THEN UPDATE SET E1.SALARY = E1.SALARY * 1.1 ELSE IGNORE
关于应用请求调优不要让 db2 做多余的处理
调优技巧 14 sql 应包含所有的过滤逻辑
通常,最好在 SQL 谓词中包含所有过滤逻辑,不要遗漏一些谓词, 而让数据库管理器引入额外的行,另外如果你想通过程序逻辑检查消除 / 绕过某些行,最好不要这样做,大部分情况下,这样会消耗大量的时间。只有当程序出现性能问题,在 sql 语句性能上已经不好调优,并且你的程序处理逻辑有足够大的改进,同时没有提供所有其他办法时, 才这样做。
调优技巧 1 5 SQL 语句 Select 中应只包含所需的列
添加额外的列会有两个影响,如果选择太多列,优化器很大程度上不能选择 index-only ,另外如果涉及到连接也会影响优化器的连接方法,且增加多的列会增加排序的成本。
例如
SELECT LAST_NAME, FIRST_NAME, JOB_CODE, DEPT FROM EMP WHERE JOB_CODE = ‘A’ AND DEPT = ‘MIS‘;
另外 对于已经在谓词中写明了条件,为什么还有在select中增加呢,所以这个地方也应该注意下
调优技巧 16 sql 语句谓词的俩边类型和长度是匹配的。
编写谓词时,最好确保主机变量数据类型 / 长度与列的数据类型 / 长度匹配或者如果俩个列进行比较运算,每个列的数据类型 / 长度匹配,因为不这样做, Db2 将消耗少量 CPU 以使这两个参数具有可比性。另外对于谓词中包含非列的表达式,应该定义与列相同类型的变量中(提前计算好),可以应用适当的标量函数来匹配列定义。
Select * from emp Where EDLEVEL = 123.45 * 12
应该写成
Where EDLEVEL = SMALLINT(Round(123.45*12,0))
Where LASTNAME like ‘000’ concat ‘%’
应该写成
Where LASTAME like ‘000%’
当你用以下sql的时候 db2会做一个隐式的转换,所以是不可以使用索引的
SELECT * FROM EMP WHERE EMPNO = 10
Db2 会优化成如下的sql
SELECT
Q1."EMPNO" AS "EMPNO",
Q1."FIRSTNME" AS "FIRSTNME",
Q1."MIDINIT" AS "MIDINIT",
Q1."LASTNAME" AS "LASTNAME",
Q1."WORKDEPT" AS "WORKDEPT",
Q1."PHONENO" AS "PHONENO",
Q1."HIREDATE" AS "HIREDATE",
Q1."JOB" AS "JOB",
Q1."EDLEVEL" AS "EDLEVEL",
Q1."SEX" AS "SEX",
Q1."BIRTHDATE" AS "BIRTHDATE",
Q1."SALARY" AS "SALARY",
Q1."BONUS" AS "BONUS",
Q1."COMM" AS "COMM"
FROM
DB2INST2.EMPLOYEE AS Q1
WHERE
(DECFLOAT(Q1."EMPNO", 34) = 10)

参考信息
db2信息中心
IDUG Db2 Tech Conference Tony Andrews SQL Tuning Tips for Developers **
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞5
添加新评论1 条评论
2019-10-07 19:27