
五种业界主流存储双活方案解析之故障转移
在前面的三篇文章《五种业界主流存储双活方案解析(方案特点)、(仲裁与两地三中心)和(读写性能)》中,笔者对华为 HyperMetro 、 EMC Vplex 、 IBM SVC 、 HDS GAD 和 NetApp MetroCluster 等五个厂商多种存储双活方案的特点、仲裁机制、两地三中心扩展及两个站点主机的读写 I/O 流程和时延进行了详细的解析。在本篇文章中,笔者将从最后一个角度,也是存储双活方案的另一大关键点 --- 故障转移入手,剖析这五种存储跨中心双活方案的高可用保护特性和仲裁处理。
故障转移之所以成为建设存储跨中心双活方案的关键点在于,双活存储不仅仅需要两个存储并行对外提供读写服务,提升整体读写服务能力和存储资源利用率,更为重要的是建立足够可靠、稳定的存储间相互保护能力,以满足 RPO ( Recovery Point Objective ), RTO ( Recovery Time Objective )的严苛的要求,将企业业务系统连续性提升至一个更高的台阶。因此,各类存储双活解决方案必须要具备足够充分的高可用特性和合理的容灾保护与仲裁机制,以应对各种各样复杂的的灾难故障场景,以极短的故障恢复时间和几乎为零的故障恢复目标,解决可能遇到的故障灾难。下面公正客观地就这五钟业界主流存储双活方案在各类故障转移场景下的表现一一展开解析。
一、华为 HyperMetro
华为 HyperMetro 具有独特的双仲裁机制,能够提供静态优先与仲裁服务器两种仲裁模式,且这两种模式可以共存 , 但优先通过仲裁服务器模式仲裁,这样可以在不同故障场景下,最大限度保障存储双活方案的高可用性。
1 、静态优先级模式
静态优先级模式主要应用在无第三方仲裁服务器的场景,在发生链路中断脑裂现象时,强制使优先的存储节点继续提供服务。如下表所示为,静态优先模式仲裁示意图,列举了三个故障场景和对应的仲裁处理结果:( 1 )当两个站点间链路出现故障时,静态优先模式设置为 H1 站点为静态优先站点,此时 H1 站点将继续对外提供读写服务, H2 站点将停止读写服务,在主机端 I/O 访问策略设置为优选阵列模式时, H1 站点的主机将继续本地读写 H1 站点存储, H2 站点主机既无法读写 H2 站点存储也无法通过切换跨站点链路访问 H1 站点存储;( 2 )当非静态优先的站点 H2 存储出现故障时, H1 站点存储同样继续提供读写服务,但 H2 站点主机可通过配置的 Ultrapath 多路径 I/O 策略,通过跨站点链路继续读写 H1 站点存储;( 3 )当静态优先的站点 H1 存储出现故障时, H1 和 H2 站点均不再对外提供读写服务,两个站点主机的读写将完全中断,此时,只能通过人工的方式,将 H2 站点的存储激活,继续提供读写服务。

2 、仲裁服务器模式
仲裁服务器模式应用在有第三方仲裁服务器的场景,将仲裁服务器部署于第三个站点,在这种模式下,可同时设置静态优先模式,实现双仲裁保护能力。在以下的单故障场景中, QS 为仲裁服务器, S1 为静态优先仲裁方。有以下几种故障场景:( 1 )当仲裁服务器本身出现故障时, S1 和 S2 存储能够持续对外提供读写服务,主机业务无任何影响,此时由于缺少了仲裁服务器,将自动进入静态优先模式;( 2 )当 S1 或 S2 存储出现故障时,仲裁服务器能够及时探测到故障存储,停止故障存储的读写,全部读写均由存活存储提供,在主机端 I/O 访问策略设置为优选阵列模式时,存活存储所在站点的主机可以继续本地读写存活存储,而远端主机则将自动切换至跨站点 I/O 路径继续读写存活存储;( 3 )当 S1 和 S2 存储间的链路出现故障时,等同于单站点存储故障场景,均需要仲裁服务器进行仲裁,判定某个站点存储失效,全部读写服务由一个存储提供,只有此存活的存储所在站点的主机能够读写存活存储,而远端站点主机由于链路故障,无法通过跨站点 I/O 路径继续读写存活存储。在该场景下,存活的存储将通过 DCL ( Data Change Log )空间记录链路故障期间,存储间的数据差异,待链路恢复后,通过差异数据增量同步配置和数据;( 4 )当 S1 或 S2 存储与仲裁服务器间的链路中断时,双活存储间链路正常,不做任何仲裁判断,两端主机正常读写双活存储。
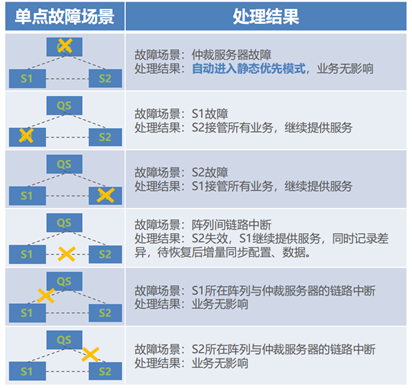
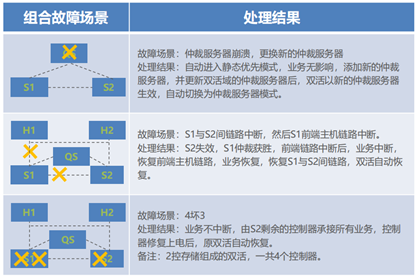
同样在以下双故障场景中, QS 为仲裁服务器, S1 为静态优先仲裁方。有以下几种故障场景:( 1 )当 S1 存储与仲裁服务器, S2 存储与仲裁服务器间的链路同时或者先后中断时,由于 S1 和 S2 间的链路完全正常,主机正常读写双活存储,并且由于缺失了仲裁服务器响应,双活存储将自动进入静态优先模式;( 2 )当 S1 和 S2 存储,其中单个存储与仲裁服务器间的链路同时或者先后中断时,此时仲裁服务器将介入仲裁,判定与仲裁服务器通信正常的存储存活,并对外提供读写服务,且只有存活存储所在站点的主机才能继续访问存活存储;( 3 )当单个存储出现故障,另一个存储仲裁胜利后,存活存储与仲裁服务器间的链路再出现故障时,由于已经仲裁完成,选举了获胜存储,只要不是该存活存储故障,其他仲裁服务器故障和链路故障都不再影响获胜站点主机的读写访问;( 4 )当仲裁服务器出现故障后,单个存储也随后出现故障。该场景下,仲裁服务器故障将使得仲裁模式进入静态优先模式,由 S1 存储继续提供服务,当故障的存储为非静态优先存储时,即 S2 存储故障,此时 S1 存储可继续对外读写, S1 和 S2 站点的主机均可通过多路径访问 S1 存储。当故障的存储为静态优先存储时,即 S1 存储故障,此时无法继续仲裁,所有存储读写访问中断;( 5 )当仲裁服务器出现故障,存储间的链路也也随后中断,此时由于仲裁服务器故障将进入静态优先模式,存储间链路中断不会影响优先站点存储继续提供读写服务,但只有优先站点的主机才能读写该存活存储。

最后在一些极端多故障场景中, QS 为仲裁服务器, S1 为静态优先仲裁方, H1 为主机集群的主机 1 , H2 为主机集群的主机 2 。有以下几种故障场景:( 1 )当在本地机房部署存储双活时,该机房突然断电。恢复电力启动双活存储后,将自动恢复双活,如果此时仲裁服务器未上电,则仲裁模式自动进入静态优先模式。如果此时仲裁服务器上电恢复后,阵列将自动进入仲裁服务器模式;( 2 )当静态优先存储和仲裁服务器同时掉电时,此时无法提供读写服务,业务中断。当重新将优先存储上电后,会自动恢复双活,并按照仲裁服务器恢复与否进入不同的仲裁模式;( 3 )当 S1 和 S2 存储同时故障,读写访问中断,当两个存储恢复后,继续自动恢复双活;( 4 )当仲裁服务器故障、阵列间链路同时中断或者三个站点间链路同时中断时,此时发生脑裂问题, S1 和 S2 存储都中断对外读写服务。当阵列间链路恢复后,需要强制启动 S1 或者 S2 ,手动触发一次双活同步来恢复双活,并按照仲裁服务器恢复与否进入不同的仲裁模式;( 5 )当 S1 和 S2 间链路中断,然后 S1 存储前端主机链路也发生中断。此时 S2 将失效, S1 获取仲裁胜利,前端链路中断后, H1 主机集群业务中断, H2 主机集群也无法切换至跨站点链路路径访问 S1 存储,同样业务中断。( 6 )两个双活的存储阵列中的 3 个控制器故障时,由最后剩余的控制器提供读写服务, H1 和 H2 主机集群均可通过多路径访问存活的存储,待控制器修复上电启动后,原双活将自动恢复。

二、 EMC Vplex
ECM Vplex 同样具备两种仲裁规则,第一种是分离规则,在没有第三仲裁节点时选用,通过预定义两个 Vplex 集群间链路中断后 I/O 一致性组的处理方式来实现防脑裂目的。第二种是 Vplex Witness ,通过整合 Witness 自身的观察与集群定期向 Witness 的报告信息,来区分判断是集群内故障还是集群间链路故障。但该仲裁方式无法和分离规则并用,只能在分离规则设置为“无自动优胜者”时,才能生效。
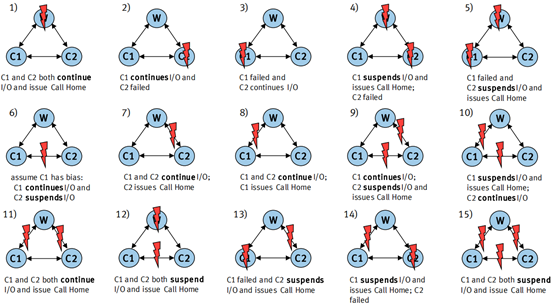
在以下单 / 多故障场景中, C1 和 C2 为两个双活的 Vplex 集群, W 为 Witness 节点,存在有以下 15 种通用的故障场景:( 1 )当 Witness 节点故障时, C1 和 C2 两个 Vplex 集群能够持续提供读写服务;( 2/3 )当单个 Vplex 集群出现故障时, Witness 将进行脑裂仲裁,选举正常的 Vplex 集群为存活集群,存活集群所在站点的主机通过 PowerPath 多路软件配置的 ACTIVE/PASSIVE 路径,访问本地 Vplex 集群,而非存活端的主机则切换跨站点 PASSIVE 路径为 ACTIVE 路径,访问远端存储的 Vplex 集群;( 4/5 )当 Witness 节点和单个 Vplex 集群同时故障时,发生脑裂同时也没有第三方仲裁,所以将读写 I/O 挂起,所有集群读写将全部中断;( 6 )当两个集群间的链路中断时, Witness 将介入仲裁,获胜的 Vplex 集群将继续提供读写服务,且只有该存活集群所在站点的主机能够读写访问,远端主机无法切换多路径跨站点读写;( 7/8 )当任意一个 Vplex 集群与 Witness 节点间的链路发生中断时,两个 Vplex 集群间可以相互通信,无任何读写中断,两个集群继续提供读写服务;( 9/10 )当两个集群间、单个集群到 Witness 节点间的链路同时中断时,发生脑裂现象,但 Witness 节点可以与另一集群正常通讯,由该集群继续提供读写服务,且只有该集群所在站点的主机能够继续访问集群后端存储数据;( 11 )当两个集群和 Witness 节点间的链路同时中断时,类似于 Witness 节点自身故障场景,两个集群可继续提供读写服务;( 12 )当 Witness 节点和两个集群间链路同时故障时,发生脑裂现象,但无第三方仲裁节点对此进行仲裁,所有集群读写服务中断;( 13/14 )当单个 Vplex 集群、 Witness 节点与另一个 Vplex 集群间的链路同时故障时,发生脑裂现象,按规则将选举正常的 Vplex 集群获胜,然而 Witness 节点却无法和该 Vplex 集群正常通信,无法顺利仲裁,造成所有读写服务中断;( 15 )当两个集群间、集群和 Witness 节点间所有的链路中断时,发生脑裂现象,但 Witness 节点无法和任何集群正常通信,无法选举获胜站点,造成所有集群读写服务中断。
另一个需要详细说明的是主机跨集群连接拓扑,合理的主机与本地 Vplex 集群、主机与远端 Vplex 集群连接拓扑,可以防止的故障场景将根据主机光纤通道适配器端口的数量, WAN 和跨集群主机连接通道的数量以及 SAN Fabric 的数量而有所不同。有几种不同类型的 SAN Fabric 拓扑可用于主机与 Vplex 集群间的连接。可以根据以下特征对这些拓扑进行分组:
( 1 )两个或四个 SAN Fabric :对于两个 SAN Fabric 的拓扑,主机的每个 HBA 端口与到本地和远端 Vplex 集群的前端端口做成一个 ZONE ;对于四个 SAN Fabric 的拓扑,将使用一组独立的主机 HBA 端口访问本地 Fabric ,另一组独立的 HBA 端口用于跨数据中心(站点)访问合并的 Fabric 。
( 2 )共享或独立的 WAN 通道:对于共享 WAN 通道,当主机跨集群连接拓扑,配置为与 VPLEX WAN 路径相同的物理 WAN 时被视为共享;对于独立 WAN 通道,当 VPLEX WAN 使用物理上独立的通道连接到交叉连接网络时,交叉连接配置被视为专用配置。
如下表所示为主机跨 Vplex 集群连接 SAN 网络拓扑提供保护的各种高级故障场景。该表根据发生双重故障时的每种拓扑和类型,表明在首选和非首选站点对主机 I/O 的影响。

因此,如上表所示,最佳做法是将跨 Vplex 集群连接的主机增加额外的 HBA 端口(不在站点之间合并 Fabric ),并使用单独的专用通道,以便不与 VPLEX WAN 共享主机交叉连接路径。
三、 IBM SVC
相较于前面两种方案, SVC ESC 和 HyperSwap 两种存储双活方案不能通过设置特定的规则或者静态优先节点来对脑裂后的集群做仲裁,但实际上在未配置第三方仲裁节点的情况下,由 SVC Configuration Node 所在的 SVC 节点作为默认的仲裁获胜者。
IBM SVC ESC 方案,有以下 6 种通用的单 / 多故障场景:( 1/2 )当集群中单个 SVC 节点故障时,由集群中远端的另一个 SVC 节点继续提供读写服务,故障 SVC 节点所在站点主机通过跨站点的多路径继续访问正常的 SVC 节点。但由于集群的一组 I/O Group 中只剩一个 SVC 节点,写缓存将被禁用,主机的写 I/O 将直接透写 SVC 后端存储阵列;( 3 )当第三站点的仲裁磁盘 / 仲裁服务器发生故障时,两个 SVC 节点可继续提供读写服务,此时活动的仲裁磁盘将被移出,由保留了配置信息的 SVC 节点(配置节点)提供仲裁服务;( 4 )当集群中两个 SVC 节点间的链路发生中断时,发生脑裂现象,由第三站点的仲裁节点选举获胜的 SVC 节点。链路中断时,第一个和仲裁节点建立访问关系的 SVC 节点存活,另一个则自动脱机。由存活的 SVC 节点对两个站点的主机提供读写服务;( 5/6 )当集群中单个 SVC 节点和仲裁节点同时故障时,由于另一个 SVC 节点无法判断是链路中断还是 SVC 节点故障,且没有第三方仲裁节点对此进行仲裁判断,因此所有 SVC 节点的读写访问中断,集群停止。

除了以上场景之外, SVC ESC 方案在后端存储出现故障后,具有以下故障转移机制特性:( 1 )当 SVC ESC 集群后端的单个存储阵列发生故障时,故障存储所在站点的 SVC 节点将前端主机读写转移到远端存储阵列,继续提供读写服务。主机端的多路径无需进行跨站点切换,维持原有 I/O 访问路径,仅仅只有 SVC 节点的路径切换到访问远端存储。在该场景下,本地存储不可用时,对于读请求,通过本地 SVC 节点从远端站点存储读。对于写请求,先将写数据落入本地 SVC 节点,并镜像同步至远端 SVC 节点缓存,待本地 SVC 节点缓存达到高水位时,联动远端 SVC 节点将缓存数据刷入远端存储。


( 2 )在两组 SVC I/O Group 的四节点 SVC 集群架构中,当某组 I/O Group
中的一个 SVC 节点出现故障不可用时,将进行脑裂仲裁, I/O 短暂中断,故障 SVC 节点所在站点的主机将通过多路径软件切换 I/O 路径至远端 SVC 节点。在配置了 SVC 无缝卷迁移( NDVM )技术时,原本属于故障 SVC 节点 I/O Group 的后端存储 LUN 将无缝迁移至另一组 I/O Group ,由它来处理读写请求。对于写请求,由于单个节点故障,写缓存将被禁止,将先写远端 SVC 节点,由远端 SVC 将写 I/O 转发到另一组 I/O Group 中的正常的 SVC 节点,最后刷入两个后端存储。对于读请求,直接读远端 SVC 节点的后端存储,不再通过远端 SVC 节点转发读请求至本地后端存储,减少读访问路径长度。

( 3 )同样在四节点 SVC ESC 集群架构下,当某远端 SVC 节点故障不可用时,同样进行脑裂仲裁, I/O 短暂中断,写缓存被禁用,但不影响本地主机正常读取本地 SVC 节点和后端存储阵列。对于写请求,将进入后端存储透写模式,不经过缓存,由本地存储直接写入。对于远端后端存储 LUN 的透写,同样经过 NDVM 迁移后,转发至另一组 I/O Group 中正常的 SVC 节点,由它处理后端存储透写。

对于 IBM SVC HyperSwap 方案,以上 6 种通用的站点级单 / 多故障场景也适用,这里不再详细描述这些故障场景和仲裁恢复过程,仅列举 SVC 单节点和双节点故障的场景:( 1 )当某站点 SVC I/O Group 中的单个 SVC 节点故障时,如下图所示,该站点主机的 I/O 将转向 I/O Group 内的 Partner 节点,写缓存被禁止,写 I/O 进入直写模式,透写后端存储阵列,并通过 Metro Mirror 镜像同步写 I/O 至远端 SVC I/O Group 。而远端 I/O Group 的转发读写机制保持不变,所有远端主机的读写,仍需要转发至 MASTER 卷所在 I/O Group 进行。

( 2 )当某站点 SVC I/O Group 内双 SVC 节点同时故障时,如下图所示,将造成脑裂仲裁,第三仲裁节点介入,由远端另一组 SVC I/O Group 接管, I/O 短暂挂起,然后所有读写请求转向远端 I/O Group 内 AUX 卷的 Owner 节点。写 I/O 缓存由远端 I/O Group 提供并做双节点镜像保护,性能无影响。 SVC 集群负责在远端 I/O Group 上伪装 Master 卷的 ID 给主机端,因此主机端外置存储继续提供服务。 Metro Mirror 的关系也将反向切换为 AUX->Master 。
四、 HDS GAD
下图为 HDS GAD 的 15 个通用故障场景,涉及该存储跨中心双活架构几乎所有的故障场景,包括主机、 I/O 路径、链路、存储卷、存储池、站点和仲裁等故障场景。下面主要列举几个有代表性,能体现 GAD 故障切换机制的场景详细介绍。

1 、主机与主 / 从存储系统间的路径丢失
下图一二为主机与两个主 / 从存储系统间的 I/O 访问路径中断的故障区域和恢复过程。故障发生时,主机将通过多路径将 I/O 切换至远端 VOL ,继续读写。 P-VOL 和 S-VOL 的复制关系保持不变,都可提供读写服务, GAD Pair 的状态依旧为 PAIR, 恢复过程较为简单:( 1 )恢复主机 I/O 访问路径;( 2 )重新启用主机与主 / 从存储间的 I/O 路径。


2 、 P-VOL 或 S-VOL 故障( GAD 状态为: Mirrored )
下图显示了由于 P-VOL 或者 S-VOL 故障而导致 GAD Pair 挂起时的故障区域和恢复过程。单个 VOL 故障则无法继续提供读写,而远端 VOL 的 I/O 模式将变为 Local ,继续提供读写。故障恢复过程如下:( 1 )删除故障 VOL 所在站点主机与 VOL 间的多路径连接,主机通过跨站点链路访问远端 VOL ;( 2 )在正常 VOL 所在存储系统上删除 GAD Pair ;( 3 )在故障 VOL 所在存储系统上尝试恢复 VOL ;( 4 )如果故障 VOL 无法恢复,则只能重建 VOL ;( 5 )在正常 VOL 所在存储系统中重建 GAD Pair ,并等待数据同步完成;( 6 )待 GAD Pair 状态变为 PAIR 时,原故障 VOL 已经可以接收读写 I/O ,可恢复主机到原故障 VOL 的 I/O 路径并启用。


3 、主存储和从存储系统间通讯链路中断( GAD 状态为: Mirrored )
下图显示了由于主存储到从存储系统或者从存储到主存储系统的链路路径故障,而导致 GAD Pair 挂起时的故障区域和恢复过程。主到从的链路路径故障,将导致 S-VOL 不可读写, P-VOL 的 I/O 模式变为 Local ;而从到主的链路路径故障,将导致 P-VOL 不可读写, S-VOL 的 I/O 模式变为 Local 。 GAD Pair 挂起后的恢复过程如下 : ( 1 )恢复主从存储系统间的链路路径;( 2 )在可读写的一方 VOL 所在存储系统中重新同步 GAD Pair ;( 3 )恢复不可读写一方 VOL 的 I/O 。


4 、主 / 从存储系统到第三方仲裁磁盘的链路中断( GAD 状态为: Mirrored )
下图一二显示了由于主 / 从存储系统到外部存储系统的链路路径故障而导致 GAD Pair 挂起时的故障区域和恢复过程。当 GAD Pair 状态为 PAIR 时,由于仲裁磁盘故障将导致 GAD Pair 挂起, P-VOL 的 I/O 模式变为 Local ,主机可以继续读写 P-VOL ,但 S-VOL 不能继续读写。 GAD Pair 挂起后的恢复过程如下:( 1 )恢复主 / 从存储到仲裁磁盘的链路路径;( 2 )重新同步 GAD Pair ;( 3 )重新启用 S-VOL 的 I/O 读写。


5、 第三方仲裁磁盘故障( GAD 状态为: Mirrored )
当 GAD Pair 状态为 PAIR 时,由于仲裁磁盘故障将导致 GAD Pair 挂起, P-VOL 的 I/O 模式变为本地,主机可以继续读写 P-VOL ,但 S-VOL 不能继续读写。下图显示了 GAD Pair 挂起时的故障区域和仲裁磁盘故障恢复过程:( 1 )恢复第三方外部仲裁磁盘;( 2 )重新同步 GAD Pair 或者重建 GAD Pair ;( 3 )待 P-VOL 和 S-VOL 数据同步完成, GAD Pair 状态变为 PAIR 时, S-VOL 可继续恢复读写。

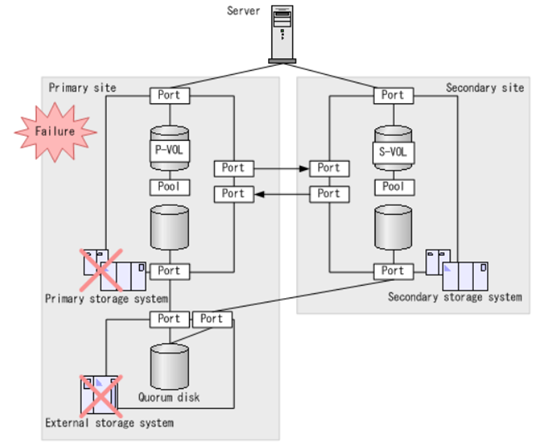
6 、主存储系统和第三方仲裁磁盘全部故障
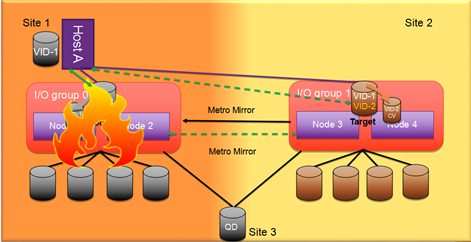
如果第三方仲裁磁盘的外部存储系统部署于主站点,主站点发生故障,则该故障可能同时影响主存储系统和外部存储系统。在这种情况下, GAD Pair 状态变为暂停,主机对 GAD 卷的读写访问全部停止,待人工恢复外部存储和主存储系统,并重建或同步 GAD Pair 后,才能恢复 P-VOL 和 S-VOL 的访问。
五、 NetApp MetroCluster
下图为 NetApp MetroCluster 高可用保护和灾难恢复架构总览图,该架构方案的保护能力可以从三个故障级别的防范角度切入,分别是集群内失效切换、磁盘 RAID 数据保护、集群间 SyncMirror 数据同步保护。每个防范角度能够防范不同的故障场景,并作出相应的处理机制。集群失效场景如下图 1-4 号场景所示,包括单存储处理器故障,将切换至另一存储处理器;磁盘架间级联单链路故障,将切换至另一冗余级联链路;单磁盘架的控制模块故障,将由另一冗余保护控制模块接管;存储处理器单个接口端口故障,包括光纤端口,另一个接口将继续接管进行各类数据通信等。磁盘阵列内故障场景如下图 5-7 号场景所示,包括单磁盘故障、同 RAID 组双磁盘故障、单磁盘损坏 + 单磁盘读写错误等级别的故障均通过 RAID 保护技术,防范数据丢失,迅速通过热备盘重建 RAID 恢复完整数据。集群间的故障场景主要发生在单个站点集群内,出现故障将造成整个集群不可用,需全部切换到远端站点的集群,由远端集群继续提供读写服务。 SyncMirror 提供了跨集群间的实时复制技术,保证在切换后,接管的集群中数据的一致性。可以防范的故障场景如下图 8-13 号场景所示,包括单磁盘架背板完全故障,单磁盘架中的两个控制模块或两个电源模块全部故障,单磁盘架的整个操作面板故障,盘架间的两个光纤级联线缆全部故障,以及两个光纤 LOOP 完全故障等。

下面详细描述其中五种主要的故障失效场景:
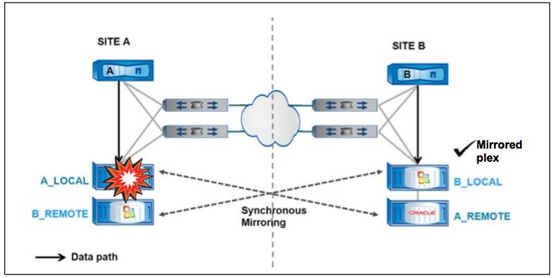
1 、控制器故障
如下图所示,当某站点内集群控制器完全故障时,将触发自动化切换或需人工介入切换,切换后,站点 A 的所有 Local Plex 将由站点 B 的集群控制器接管,两个站点的主机需要经过站点 B 集群控制器读写存储,对于原本为 B 站点的 Local Plex 将继续本地读写,而 A 站点的 Local Plex 的读写需要通过跨站点的光纤链路路径实现。

2、 磁盘架故障
在以下磁盘架( Plex 或 Aggregate )故障场景,将自动和无缝故障转移到镜像 Plex 。在正常的 MetroCluster 操作中,主机的读 I/O 从 Local Plex 处理读取,并将写 I/O 发送到 Local 和 Remote Plex 。如果站点 A 控制器上的磁盘架出现故障,如下图所示,则读请求将重定向到 Remote Plex ,在下图中为 Plex A_REMOTE 。写 I/O 也将仅发送到 Remote Plex ,直到 A 控制器上的磁盘架完成修复或更换备件。 可以通过 TieBreak 仲裁软件,使该读写切换过程无缝自动进行。
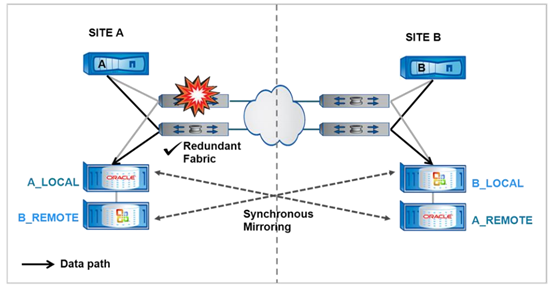
3 、交换机故障
在以下交换机故障场景,将自动切换到冗余 FC Fabric 。在通用的 Fabric MetroCluster 配置中,每个 MetroCluster 配置使用了四个光纤交换机( Brocade 或 Cisco ),在站点之间创建两个光纤网。一个 Fabric 或交换机的故障只会导致故障转移到另一组 Fabric ,整个故障转移是完全自动的。
4 、站点完全故障
如下图所示,站点级故障可以通过手动使用 CFOD 命令,让远端站点集群接管所有 Plex 的读写请求。也可以在两个集群间添加 MetroCluster TieBreaker ( MCTB ),来区分是站点间链路故障,还是某个站点故障的场景,以消除这两种灾难场景的模糊性。因为在未配置 MCTB 时, MetroCluster 无法区分这两种情况。通过 MCTB 可以实现站点级故障的自动故障转移。

5 、站点间链路中断
在以下站点间链路完全中断场景,除了暂停 SyncMirror 镜像同步外, MetroCluster 不会执行其他任何操作和措施。每个控制器继续正常提供存储读写,但本地 Plex 不会镜像写入到远端 Plex ,因为它们间的通信链路已经中断。

6 、多节点滚动故障
前面的故障场景包括单个组件故障和完全站点灾难的场景。多个组件顺序失败的场景称为滚动失败。例如,在下图的场景中,先是控制器故障,然后是 Fabric 故障,最后是磁盘架故障。 MetroCluster 的故障处理是顺序进行,先导致集群间控制器切换,再是 Fabric 冗余保护, A_LOCAL 的读写通过另一组 Fabric 跨站点实现,最后通过手动或自动切换,读写请求全部由站点 B 的集群提供,由事前 SyncMirror 同步机制保证切换后 A_LOCAL 和 B_REMOTE 的数据一致性。通过以上一系列顺序动作防止整个 MetroCluster 停机和数据丢失。最终主机的所有读写将全部由站点 B 的集群控制器和磁盘架提供。

如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞15本文隶属于专栏

作者其他文章
评论 17 · 赞 79
评论 8 · 赞 42
评论 0 · 赞 2
评论 1 · 赞 1
评论 0 · 赞 1
添加新评论0 条评论