开放交换机组网技术和前沿进展介绍
本次分享内容主要有三大部分的内容:
第一部分是开放交换机的前沿进展;
第二部分介绍组网,尤其是云原生数据中心的组网;
第三个部分是金融业对开放交换机所做一些研究以及验证。本文对第一、二部分内容进行分享。
1、网络技术的堆栈
首先谈到了网络技术的堆栈,网络技术堆栈可以分成控制平面和数据平面,在控制平面有,北向接口有Neutron接口,还有K8S CNI接口,以及当前SDN界比较流行的IBN基于意图的声明式接口。开源的网络控制器有ODL和ONOS,商业版有思科ACI、华为AC等。南向接口最著名的是OpenFlow,还有最新的P4 runtime,当然传统设备厂商可能更倾向于BGP、NETCONF、OPFLEX等接口。

再看数据平面,数据平面可以分成交换机操作系统、硬件抽象层和交换芯片。交换机操作系统是当前网络开源的竞争焦点,开源的系统包括SONiC、FBOSS等。对硬件抽象层,现在发展比较好的是SONiC的SAI层。交换芯片目前正在向可编程的方向发展。网络的开放应该还是大势所趋,上图中左侧红色字表示的都是开源项目,可以看到开源软件已经能够实现对网络堆栈的全覆盖,标准硬件加开源软件构成的开放交换机生态也逐渐成形。
2、开放交换机的技术特征
将开放交换机的技术特征归纳为如下三点。第一是小交换机可以组大网,即相对于原来比较复杂的大框交换机,现在用标准的小盒子也能够扩展出一张非常大的网络。第二是标准硬件加上开放控制,也即在整个的硬件体系上,如何能够构建一个更可控、更精简的网络操作系统。第三是交换芯片的可编程,对于SDN来说,芯片可编程才是最彻底的SDN,因为它已经把软件定义的边界下沉到了转发流水线的层次。下面对这三点进行详细介绍。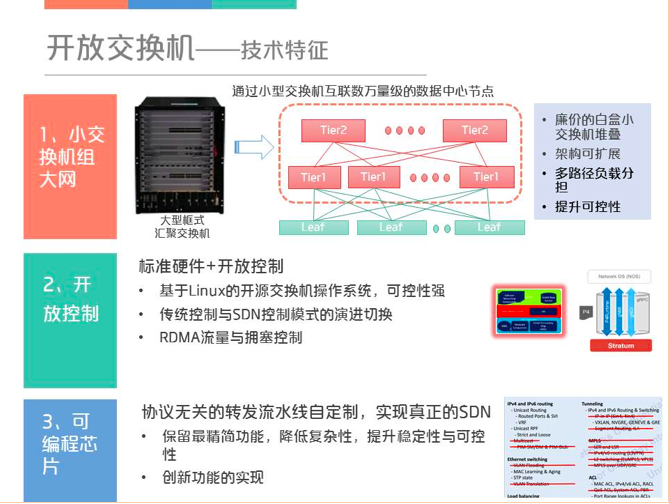
2.1 小交换机组大网
在谈小交换机组大网之前,先介绍一下框式和盒式交换的差别,框式交换机通过背板交换连接多块线卡,其内部的连线也是CLOS的结构。因此,一个大框可以通过小交换机进行组合构建,用小交换机的好处有如下几点:1)小交换机比较便宜,可节约成本。2)架构可扩展,因为框式交换机一旦被设计出来,它的整个数量就完全确定了。3)可控性更高,但与此同时管理的难度也会逐渐增加。下图用于比较用框式和盒式堆三层网络,对于框式交换机如果只是组几千个节点,一台框式交换机就可以搞定了,但是如果是几万个节点,就需要框式堆框式,每一个框里面至少3块芯片,一路算下来,从一端到另外一端要经过11跳,而盒式交换机组成三层网络只需要5跳,所以在时延和跳数上是有优势的。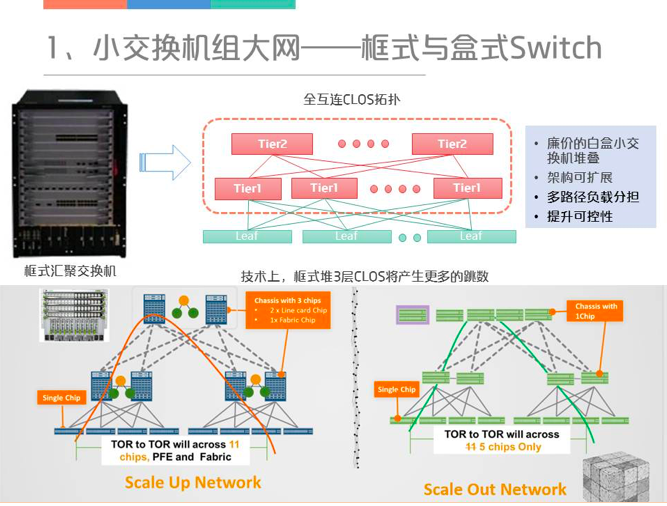
当前盒式交换机单芯片的端口密度已经很大了,最高的12.8T(有128个100G的端口)都已经出来了,所以通过三层的CLOS就可以组一个很大的网。具体计算一下,一个2级CLOS构成基本单元POD,可以挂几千台机器,再扩展到三级CLOS,差不多可以无阻塞互联十万左右的服务器,这对于单个数据中心而言已经足够多了。三级CLOS组网的数量取决于中间层交换机的端口密度。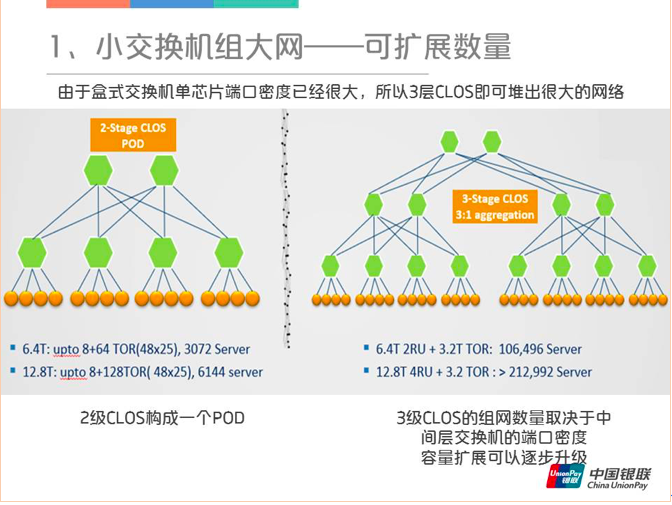
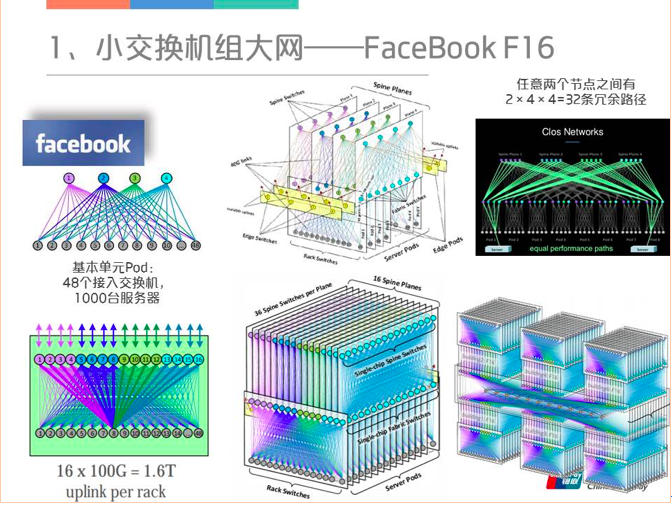
今年OCP,Facebook发布了最新的数据中心网络设计——F16。他的前身是几年前经典的F4组网,该组网的基本单元有48个接入交换机,4个中间层交换机,差不多每个POD可以连接1000台服务器。然后最上层的Spine交换机通过CLOS互联可以扩展互联数万台服务器的规模,并且在任意两个服务器节点之间有多条冗余路径可以做负载分担。当前最新的F16,中间层改成了16*100G的互联,最顶层的Spine交换平面有36个。如果有六栋楼的话,这种互联方式还可以将六个AZ的交换机Fabric进行全互连。
2.2 网络的开放控制
在这一部分中,首先谈到了路由控制,路由控制分两种传统的路由控制和SDN路由控制。对于传统的路由控制,对开源网络操作系统SONiC和Stratum进行了比较。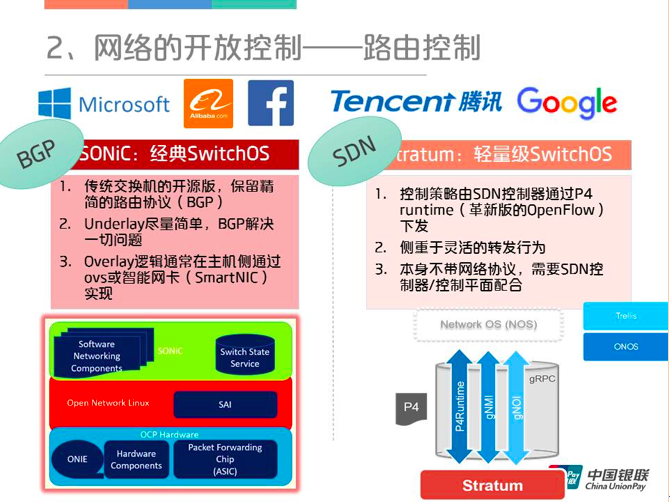
SONiC
对于SONiC来说,下图是一个简单的架构图,控制平面仅实现了最核心的BGP协议以保障云数据中心大规模三层网络的互通。数据平面比较核心的是SAI层,这一层目前比较重要因为它的生态发展比较好,它下面支持的芯片非常多。用户既可以用Switch.p4这样纯可编程的芯片来支持SAI,也可以通过博通、盛科等的芯片来实现SAI的接口,最终映射到物理的Chip Target。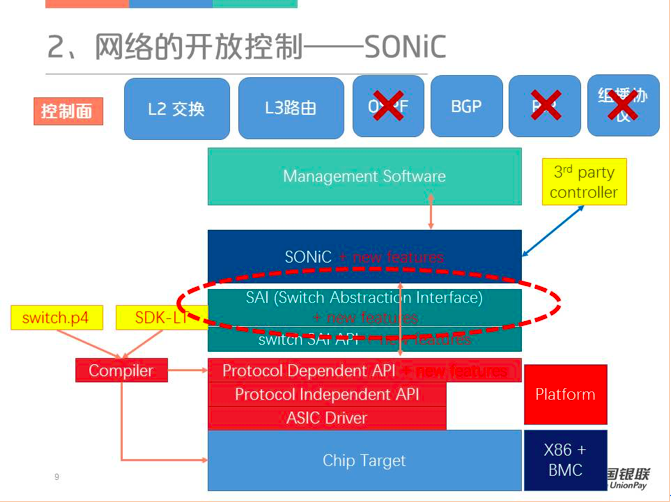
开放交换机创新的技术中不得不提一下去堆叠技术。通常情况下,服务器为了保证高可用性,一般是双连到两台交换机上,如果有一个交换机宕机了,另外一个可以接上。上图中可以看到TOR1和TOR2之间有两条线,这两条堆叠线的作用是同步MAC、ARP等状态。为了达到高可用性,最极端的做法是把两台交换机虚拟成一台控制平面,当用户登上TOR1和TOR2时会发现它们的管理地址是一模一样的,这个虚拟程度是很高,但是额外复杂度、不稳定性也增加了。对此,阿里提出了一种比较创新的去堆叠的技术(VPC-lite),他们的想法是服务器bond口将ARP双发到两条链上,这样TOR1和TOR2就不用同步ARP表了。当链路断了,在显示地通告一下BGP。这种方式达到了原来同样的效果,但原来的堆叠线没有了,交换机也相互独立,实现方面也要简单很多。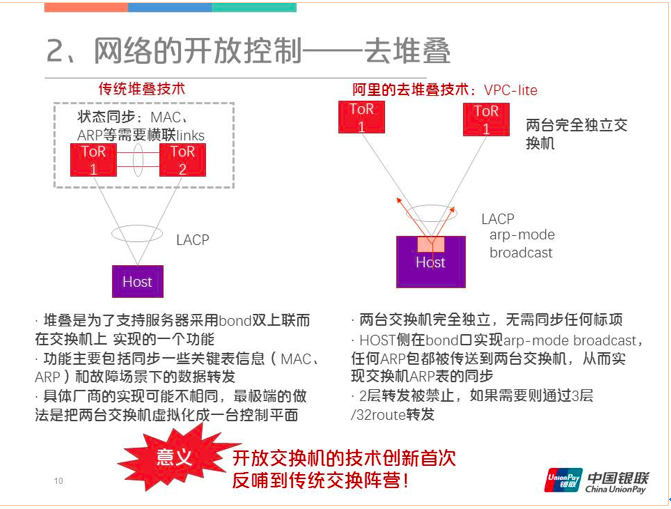
SONiC现在已经成为OCP的一大招牌,因为OCP基本上是以硬件为主,对于软件方面,现在主推SONiC,也是目前生态最成熟的一个开放交换机操作系统,这套操作系统是微软的华人工程师创建的,设计精简前卫,它里面很多组件的模块性都比较好。在使用案例方面,微软将SONiC部署到了全球44个region,领英当前40%的数据中心大规模在使用SONiC。此外,OCP也特意强调了中国对于SONiC的贡献,由阿里牵头ODCC(中国开放数据中心联盟)专门成立了一个凤凰项目,负责SONiC在中国的推广。阿里是SONiC生产应用最早的也是规模比较大的企业。腾讯、百度包括京东也正在开展密集的验证测试,而且不久也会正式生产上线。
2.3 Stratum
和SONiC相比,Stratum的理念更偏向计算机,它是以IT的方式来管理整个CT系统,也是比较有意思的。整个设计最顶层是远端的控制器,接口端主要分成三类,一个是P4ruetime,然后就是gOMI和gNOI。g代表gRPC,而不是传统网络设备所使用的NETCONF,这可以使得策略的下发效率提升很多。下图蓝色框内便是Stratum的覆盖范围。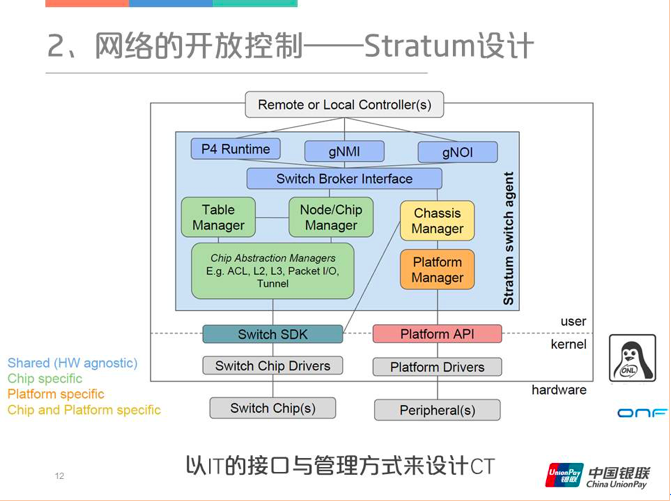
单独的Stratum是没有办法进行组网独立工作的,在上层它需要ONOS或者其他的控制器配合,下层是通过Trellis组件提供Fabric SDN的路由控制。这个系统是纯SDN选路,所以一旦链路端掉线,系统很快就能够响应,重新编制转发表项,由此也不存在去堆叠之类的麻烦。
Stratum项目最早是由谷歌发起的,所以谷歌在内部肯定已经大规模使用了Stratum(但是谷歌的控制器不是ONOS),整个项目预计今年6月正式开源。国内在去年12月份左右,由腾讯牵头举办了一场Stratum Developer Day,同时 UCloud、阿里、锐捷也都在积极跟进或者密切关注。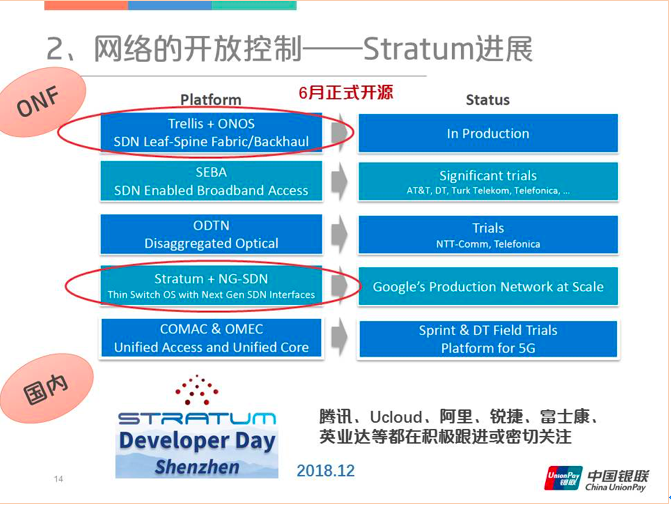
RDMA
在网络的开放控制中SDN解决的是路由控制的问题,而RDMA要解决的是流量控制。要解决什么样的流量呢?首先看下图,如果是点对点两两互打的话,这个对交换机来说并没有什么太大的压力,每两点产生的流量再大,有线速保障的交换芯片都可以处理过来。但是如果碰到多打一的情况,交换机芯片再强大也处理不了。对这种情况只能从源端进行解决,把原来的大流量变成原来的三分之一,出口那边才可能扛住。在源端分流最常用的方法是从TCP的端侧流控,但这有一个缺点,速度比较慢,有可能对端反馈过来的时候在交换机里已经产生丢包了。于是有了RDMA,可以做端到端的全程流控,整个网络都可以参与流量拥塞的反压。
这种多打一的情况经常出现在大数据训练场景下。另外对于25G和100G网络这种情况也非常突出,因为25G和100G网络速度太快了,它的交换机的缓存撑不了很长时间,一旦有拥塞,交换机缓存就会迅速溢出,所以RDMA技术基本上会运用在25G/100G网络中。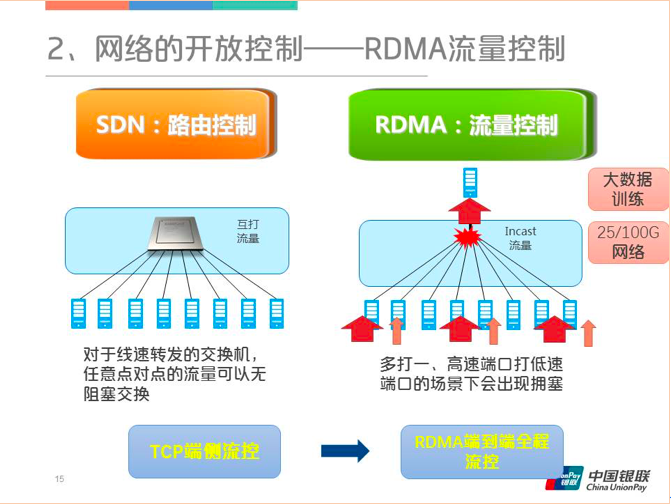
下图是RDMA的技术实现,首先在网络侧需要优化配置PFC和ECN等参数,整个RDMA最难的就是这些参数该怎么配。智能网卡侧实现数据远程搬运,同时可以降低CPU的流控负担。最后,原有的TCP协议栈也要重新改写,替换为RoCEv2 verbs的接口。RDMA最终的目标是高吞吐、低时延和不丢包。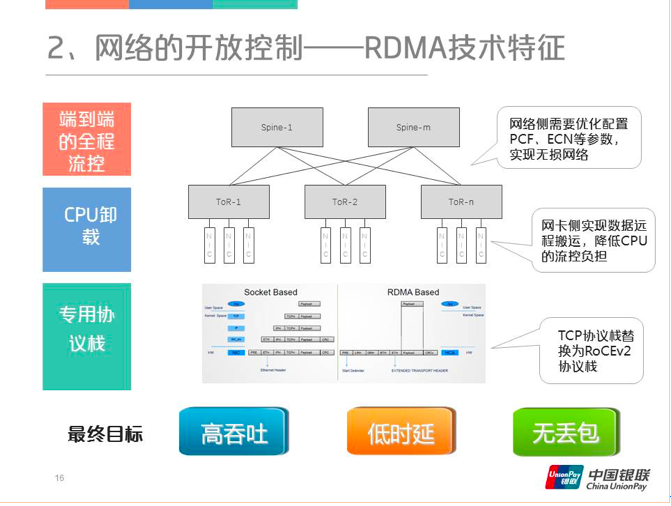
RDMA技术最早应用于科学计算,是一套比较封闭而且价格比较昂贵技术。在以太网中,RDMA主要应用于大数据计算、分布式存储和深度学习网络等大吞吐量,低时延的场景。目前,RDMA的使用其实已经比较广泛了,最早是微软将其应用至云数据中心的场景,BAT等互联网公司主要用于为AI训练任务和分布式存储。华为也推出了AIFabric这种重量级的产品。值得一提的是,整个RDMA网络栈中,有一个单点,那就是迈络思(Mellanox)的智能网卡。迈络思对RDMA贡献很大,它本身就是InfiniBand与RDMA技术的主要发明者。今年3月,英伟达以69亿美金收购了这家以色列半导体公司,今后GPU内存中的数据就可以通过RDMA实现“远程搬运”了。在金融行业,招行和浦发已经分别有生产应用和深度验证,银联也在验证。
2.4 可编程交换芯片
最后是可编程芯片(Programmable Switch Chip)。可编程交换芯片有三个特点,首先它肯定是ASIC,第二要实现可编程的前提是性能不降级,第三要有特定的编程模型。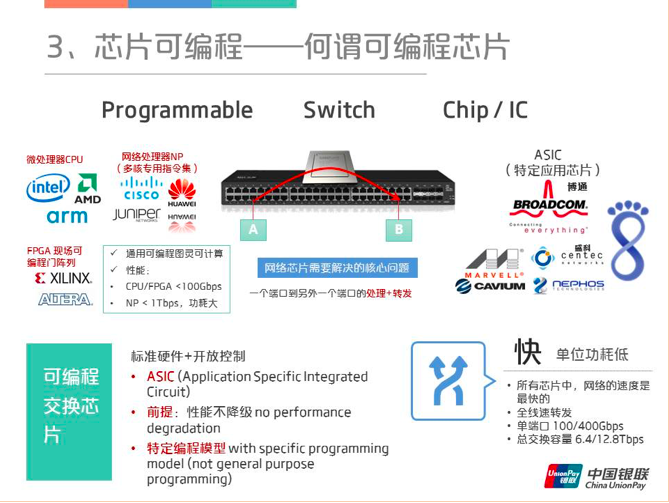
在编程模型方面,以前的交换芯片普遍是固定的流水线,P4的编程模型是PISA,协议无关的交换流水线架构。下图是P4的一个流水线,从图中可以看到每一级都是长的一模一样的,中间是TM,用来缓冲入流水线和出流水线。它的核心仍然是高速交换、处理相关的数据,多了灵活匹配和灵活编辑,小容量的高速存储和查找功能。使用P4语言,用户可以自定义报文头、自定义表项,然后还可以通过控制流把它串起来。当然也有些功能是P4实现不了的,比如变长URL的匹配,新的Hash算法,还有做大容量的存储,这些都不可能在交换芯片上实现。
从体系架构的视角来看,更高性能始终是体系架构永恒的追求。从最早的单核再到多核,如今摩尔定律已经到了极限,于是各种领域相关的芯片(例如GPU、TPU和FPGA)将发挥重要作用,体系架构也将迎来一个新的黄金时代。对于P4使能的交换芯片来说,它可以用于多节点分布式的协作,像原来的两两单播可以变成组播加速,还有就是服务器部分逻辑到可编程交换芯片等等。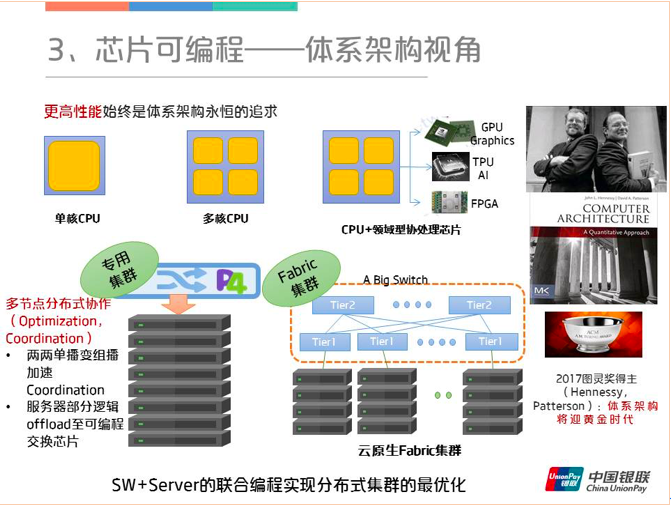
整个P4应用场景差不多可以归纳为四个虚拟的P4程序,第一个Telemetry是INT的功能,这个是当时P4的主打功能,还是很惊艳的。其次是NFV,然后是Cluster,它可以实现可编程SW+服务器集群的架构。最后一个是Fabric的P4,它可以做到服务和通信的卸载。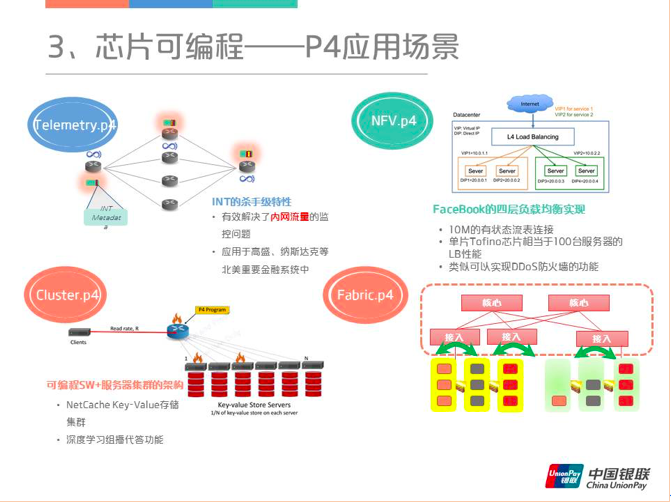
P4的应用案例基本上是从去年P4 Summit上收集到的,用的最早的还是阿里,当时介绍的是负载均衡的应用,一个单片的Tofino芯片是相当于100台服务器的软LB的性能,而且已经接受了2018双十一场景的严酷考验。UCloud在P4方面挖掘得很深,主要场景是在云网关,或者说是vPC的网关,P2V网关,腾讯京东也有涉及。另外就是INT功能,普遍是用在SONIC的集群当中,实现流量的可视化。
上述内容是第一部分内容。下面介绍第二部分云原生时代的开放交换机组网。
从2015年开始容器化、微服务等等就开始火了,随之云原生一词也渐渐传入大家耳中。云原生的目标是“业务”极速上线,这是整个的数据中心未来的一个发展方向。数据中心最早使用的是资源池化(Iaas的编排系统),对网络存储资源进行统一的管理。但是对于从应用的构建、部署的方式、弹性伸缩和高可用保障方面它并没有本质性的改变,所以当时很多大佬们就提出来了云原生的概念,就是说明原来的应用其实并不是原生的,所以说现在提出的Paas服务化的理念是什么呢?就是整个系统的能力都是下沉到平台级层面,应用主要关注业务逻辑,不再需要顾及负载均衡、弹性伸缩和高可用之类的运维能力。
从七层网络架构来看云原生网络对组网的要求,介绍了CNI接口和ServiceMesh(服务网格)。CNI接口是基础的二三层网络联通,它的接口非常简单,就是下图中列举的四个方法,主要就是要实现一个虚拟隔离的vPC网络。四到七层高级网络功能通过ServiceMesh(服务网格)实现,其中四到七层中的云原生更加强调以服务为中心的想法,就是把原来的实例IP给弱化了,更加关注服务的IP,其实就是一个虚IP或者是EIP。四到七层的网络还提供安全可靠灵活高效的服务间通信。
3个云原生组网的案例,其中之一是Istio服务网格原生的K8S处理服务间通信主要是通过Iptables规则的概率匹配进行服务间的负载均衡,当规模一大iptables链式匹配会出现瓶颈,而且很多高级功能无法实现。Istio则是在一个POD里面加入了一个sidecar容器。sidecar将流量“劫持”后,就可以实现流量限制、熔断、AB发布、分布式追踪等一系列的高级功能。右上是整个Istio的控制平面,和前面的Stratum有点像,都有配置策略下发和搜集网络数据部分。整个Istio周围还有非常丰富的组件,用于监控的Prometheus+Grafana,用于分布式追踪的Kiali和Jaeger,可以构成一个完整的闭环功能非常强大。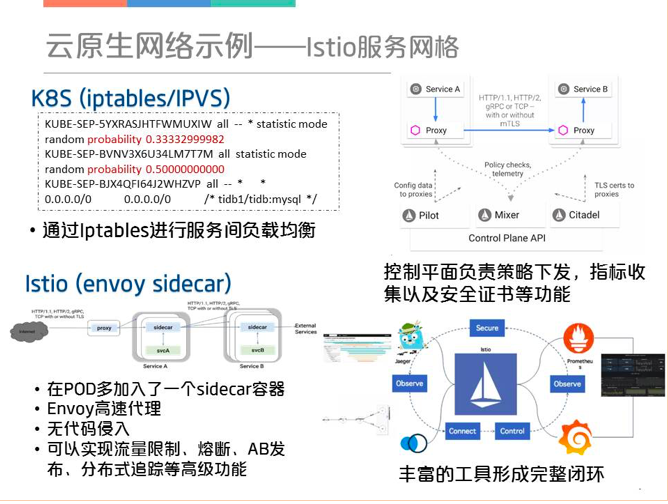
开放交换机的生态已经成型了,相关技术还是有非常大的创新活力。云原生将成为未来DC网络的重要驱动力。整个开放交换机市场成熟度还需要进一步打磨,企业用户有义务积极试用,创新更多的应用场景。
作者:中国银联电子商务与电子支付国家工程实验室周雍恺博士!
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞10
添加新评论1 条评论
2021-02-17 23:28