FIO测试磁盘iops
FIO是测试IOPS的非常好的工具,用来对硬件进行压力测试和验证,支持13种不同的I/O引擎,包括:sync,mmap, libaio, posixaio, SG v3, splice, null, network, syslet,guasi, solarisaio 等等。
| sync:Basic read(2) or write(2) I/O. fseek(2) is used to position the I/O location. psync:Basic pread(2) or pwrite(2) I/O. vsync: Basic readv(2) or writev(2) I/O. Will emulate queuing by coalescing adjacents IOs into a single submission. libaio: Linux native asynchronous I/O. posixaio: glibc POSIX asynchronous I/O using aio_read(3) and aio_write(3). mmap: File is memory mapped with mmap(2) and data copied using memcpy(3). splice: splice(2) is used to transfer the data and vmsplice(2) to transfer data from user-space to the kernel. syslet-rw: Use the syslet system calls to make regular read/write asynchronous. sg:SCSI generic sg v3 I/O. net : Transfer over the network. filename must be set appropriately to `host/port’ regardless of data direction. If receiving,only the port argument is used. netsplice: Like net, but uses splice(2) and vmsplice(2) to map data and send/receive. Guasi: The GUASI I/O engine is the Generic Userspace Asynchronous Syscall Interface approach to asycnronous I/O. |
FIO安装
进入网页http://freecode.com/projects/fio/

当前是fio-2.1.10版本
| yum install libaio-devel tar -zxvf fio-2.1.10.tar.gz cd fio-2.1.10 make make install |
假设我们要测试的系统如下,其中/home用来存储数据

随机读命令如下(举例):
| fio -filename=/dev/sda5 -direct=1 -iodepth 1 -thread -rw=randread -ioengine=psync -bs=16k -size=200G -numjobs=10 -runtime=1000 -group_reporting -name=mytest |
说明:
| filename=/dev/sda5 测试文件名称,通常选择需要测试的盘的data目录。 direct=1 测试过程绕过机器自带的buffer。使测试结果更真实。 rw=randwrite 测试随机写的I/O rw=randrw 测试随机写和读的I/O bs=16k 单次io的块文件大小为16k bsrange=512-2048 同上,提定数据块的大小范围 size=5g 本次的测试文件大小为5g,以每次4k的io进行测试。 numjobs=30 本次的测试线程为30. runtime=1000 测试时间为1000秒,如果不写则一直将5g文件分4k每次写完为止。 ioengine=psync io引擎使用pync方式 rwmixwrite=30 在混合读写的模式下,写占30% group_reporting 关于显示结果的,汇总每个进程的信息。 此外 lockmem=1g 只使用1g内存进行测试。 zero_buffers 用0初始化系统buffer。 nrfiles=8 每个进程生成文件的数量。 |
FIO提供如下几种读写测试方式

其中随机擦除trim操作需要磁盘的支持,现在有些SSD盘支持这个操作。
顺序读命令:
| fio -filename=/dev/sda5 -direct=1 -iodepth 1 -thread -rw=read -ioengine=psync -bs=16k -size=20G -numjobs=30 -runtime=1000 -group_reporting -name=humidy_read_1 |
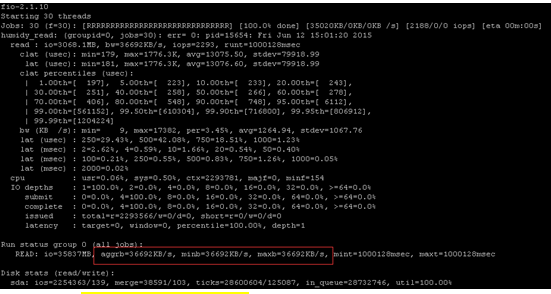
可见这个磁盘顺序读可以达到36MB左右。
随机读命令
| fio -filename=/dev/sda5 -direct=1 -iodepth 1 -thread -rw=randread -ioengine=psync -bs=16k -size=20G -numjobs=30 -runtime=1000 -group_reporting -name=humidy_read_2 |

可见这个磁盘随机读可以达到1.2MB左右
顺序写命令
| fio -filename=/dev/sda5 -direct=1 -iodepth 1 -thread -rw=write -ioengine=psync -bs=16k -size=20G -numjobs=30 -runtime=1000 -group_reporting -name=humidy_write_1 |

可见这个磁盘顺序写可以达到45MB左右
随机写命令
| fio -filename=/dev/sda5 -direct=1 -iodepth 1 -thread -rw=randwrite -ioengine=psync -bs=16k -size=20G -numjobs=30 -runtime=1000 -group_reporting -name=humidy_write_2 |

可见这个磁盘随机写可以达到3MB左右
顺序读写命令
| fio -filename=/dev/sda5 -direct=1 -iodepth 1 -thread -rw=rw -ioengine=psync -bs=16k -size=20G -numjobs=30 -runtime=1000 -group_reporting -rwmixread=50 -name=humidy_rw_1 -ioscheduler=noop |
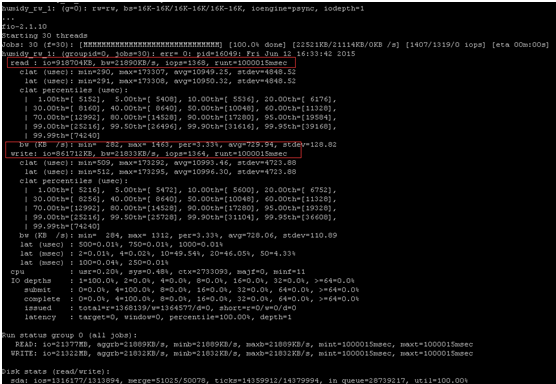
可见这个磁盘顺序读写混合操作,读可以达到21MB左右,写可以达到21MB左右。
随机读写命令
| fio -filename=/dev/sda5 -direct=1 -iodepth 1 -thread -rw=randrw -ioengine=psync -bs=16k -size=20G -numjobs=30 -runtime=1000 -group_reporting -rwmixread=50 -name=humidy_rw_2 -ioscheduler=noop |

可见这个磁盘随机读写混合操作,读可以达到922KB左右,写可以达到886KB左右。
磁盘阵列吞吐量与IOPS两大瓶颈分析
1、吞吐量
吞吐量主要取决于阵列的构架,光纤通道的大小(现在阵列一般都是光纤阵列,至于SCSI这样的SSA阵列,我们不讨论)以及硬盘的个数。阵列的构架与每个阵列不同而不同,他们也都存在内部带宽(类似于pc的系统总线),不过一般情况下,内部带宽都设计的很充足,不是瓶颈的所在。
光纤通道的影响还是比较大的,如数据仓库环境中,对数据的流量要求很大,而一块2Gb的光纤卡,所能支撑的最大流量应当是2Gb/8(小B)=250MB/s(大B)的实际流量,当4块光纤卡才能达到1GB/s的实际流量,所以数据仓库环境可以考虑换4Gb的光纤卡。
最后说一下硬盘的限制,这里是最重要的,当前面的瓶颈不再存在的时候,就要看硬盘的个数了,我下面列一下不同的硬盘所能支撑的流量大小:
| 10 K rpm 15 K rpm ATA ——— ——— ——— 10M/s 13M/s 8M/s |
那么,假定一个阵列有120块15K rpm的光纤硬盘,那么硬盘上最大的可以支撑的流量为120*13=1560MB/s,如果是2Gb的光纤卡,可能需要6块才能够,而4Gb的光纤卡,3-4块就够了。
2、IOPS
决定IOPS的主要取决与阵列的算法,cache命中率,以及磁盘个数。阵列的算法因为不同的阵列不同而不同,如我们最近遇到在hds usp上面,可能因为ldev(lun)存在队列或者资源限制,而单个ldev的iops就上不去,所以,在使用这个存储之前,有必要了解这个存储的一些算法规则与限制。
cache的命中率取决于数据的分布,cachesize的大小,数据访问的规则,以及cache的算法,如果完整的讨论下来,这里将变得很复杂,可以有一天好讨论了。我这里只强调一个cache的命中率,如果一个阵列,读cache的命中率越高越好,一般表示它可以支持更多的IOPS,为什么这么说呢?这个就与我们下面要讨论的硬盘IOPS有关系了。
硬盘的限制,每个物理硬盘能处理的IOPS是有限制的,如
| 10 K rpm 15 K rpm ATA ——— ——— ——— 100 150 50 |
同样,如果一个阵列有120块15K rpm的光纤硬盘,那么,它能撑的最大IOPS为120*150=18000,这个为硬件限制的理论值,如果超过这个值,硬盘的响应可能会变的非常缓慢而不能正常提供业务。www.jbxue.com
在raid5与raid10上,读iops没有差别,但是,相同的业务写iops,最终落在磁盘上的iops是有差别的,而我们评估的却正是磁盘的IOPS,如果达到了磁盘的限制,性能肯定是上不去了。
那我们假定一个case,业务的iops是10000,读cache命中率是30%,读iops为60%,写iops为40%,磁盘个数为120,那么分别计算在raid5与raid10的情况下,每个磁盘的iops为多少。
| raid5: 单块盘的iops = (10000*(1-0.3)*0.6 + 4 * (10000*0.4))/120 = (4200 + 16000)/120 = 168 |
这里的10000*(1-0.3)*0.6表示是读的iops,比例是0.6,除掉cache命中,实际只有4200个iops
而4 * (10000*0.4) 表示写的iops,因为每一个写,在raid5中,实际发生了4个io,所以写的iops为16000个
为了考虑raid5在写操作的时候,那2个读操作也可能发生命中,所以更精确的计算为:
| 单块盘的iops = (10000*(1-0.3)*0.6 + 2 * (10000*0.4)*(1-0.3) + 2 * (10000*0.4))/120 = (4200 + 5600 + 8000)/120 = 148 |
计算出来单个盘的iops为148个,基本达到磁盘极限
| raid10 单块盘的iops = (10000*(1-0.3)*0.6 + 2 * (10000*0.4))/120 = (4200 + 8000)/120 = 102 |
可以看到,因为raid10对于一个写操作,只发生2次io,所以,同样的压力,同样的磁盘,每个盘的iops只有102个,还远远低于磁盘的极限iops。
在一个实际的case中,一个恢复压力很大的standby(这里主要是写,而且是小io的写),采用了raid5的方案,发现性能很差,通过分析,每个磁盘的iops在高峰时期,快达到200了,导致响应速度巨慢无比。后来改造成raid10,就避免了这个性能问题,每个磁盘的iops降到100左右。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞8作者其他文章
评论 0 · 赞 1
评论 0 · 赞 0
评论 3 · 赞 3
评论 0 · 赞 1
评论 0 · 赞 1
添加新评论3 条评论
2017-09-18 09:55
2017-09-17 23:48
2017-09-17 22:29