云上的 NAS — 以 CephFS 为例
AWS 于今日发布了其 EFSElastic File System 产品,旨在云环境中提供 NAS 服务,终于填补上了公有云领域最后一块传统存储领地。其主要提供 NFS V4 版本协议,单纯只支持 NFS V4 这个 NFS 中唯一带状态的协议然后考虑到 AWS 目前基础软件现状这点不得不让我思考 Amazon 在云存储上的深厚功底了。
众所周知,DAS、SAN 和 NAS 是传统企业存储对使用方式类型的三种区分,其中 DAS 对应于 EBS(Elastic Block System) 服务,这里的 EBS 虚指所有云厂商的块存储系统,SAN 作为 DAS 的增强在传统企业存储占据主导地位,但是在云环境中的作用并不是这么明显,因为 SAN 相对于 DAS 更多的提供了数据保护、功能增强、更强性能的作用,在云环境下这些特性往往是底层存储系统所提供并附加到虚拟卷上。因此 SAN 只剩下的集中控制器提供的共享存储功能是需要提供的。因此,在云环境下的少部分 EBS 实现会增加多 VM 挂载能力,使得 EBS 同时覆盖了 DAS 和 SAN 的使用场景。当然不同云厂商提供的 EBS 在实现和产品提供上有着巨大差异,因此在云端由 EBS 提供的虚拟卷往往需要根据云厂商本身的 EBS 实现而提供传统 SAN 所具备的能力。
那么,剩下的 NAS 作为传统企业存储的另一支柱在云环境下的展现是不可或缺的,NAS 通常以标准的文件系统协议如 NFS、CIFS 被用户访问,传统企业 NAS 如 EMC 的 Isilon, NetApp 的 FAS。在传统企业存储中 NAS 跟 SAN 同样是主要的数据存储方式,在传统 IT 迁移到云基础架构的阶段中,提供 NAS 服务是不可或缺的迁移基础之一。即使在在面向云基础架构(IAAS, PAAS)的新业务、架构下 NAS 依然有其发挥之处,通过共享目录来解决业务的并发或者控制面的数据存储,大数据场景更是云 NAS 的重要用武之处。
因此,这里会以 OpenStack 作为共享文件服务的控制层,以 Ceph 作为数据平面讲讲具体如何在云基础架构中提供 NAS 服务。
OpenStack Manila & CephFS
OpenStack Manila 项目从 13 年 8 月份开始进入社区视野,主要由 EMC、NetApp 和 IBM 的开发者驱动,是一个提供共享文件系统 API 并封装不同后端存储驱动的孵化项目。目前主要的驱动有 EMC VNX、GlusterFS、IBM GPFS、华为、NetApp 等。而 Ceph 作为目前 Cinder 项目最活跃的开源后端实现,自然希望在 Manila 上仍然提供强有力的支持,何况 CephFS 本就是 Ceph 社区寄以厚望的组件。而从共享文件服务本身考虑,一个能横向扩展的分布式存储支持是其服务本身最重要的支撑,从目前的整个分布式文件存储方案(狭义的 POSIX 兼容)上来看,CephFS 也是佼佼者之一。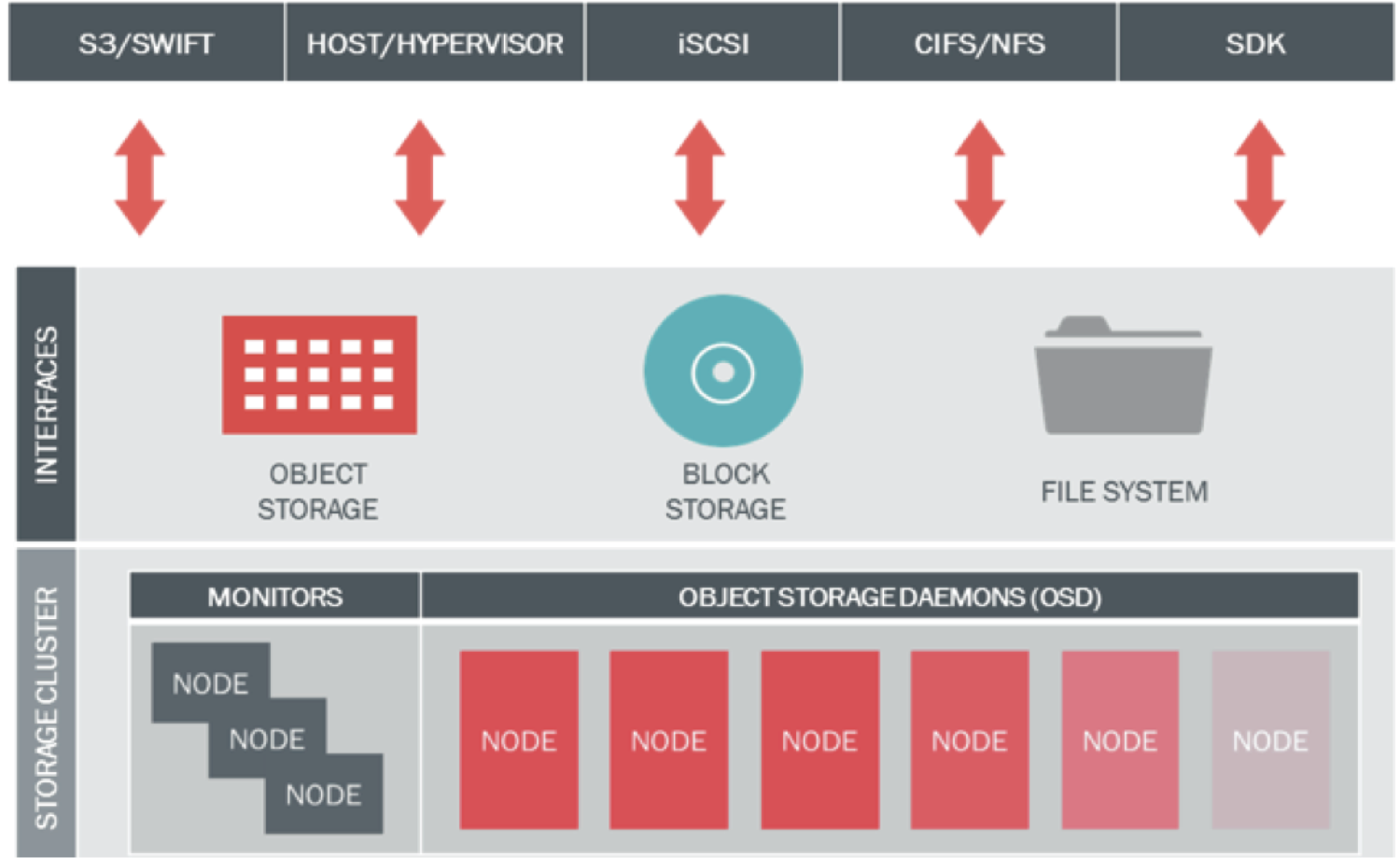
在 14 年初的一次 Ceph Core Standup IRC 会议上,Sage 提到在目前 RadosGW, Ceph RBD 都成功作为 OpenStack 后端存储项目支持后蒸蒸日上的情况,那么 CephFS 是不是也可以考虑进入 OpenStack 存储选项之列。当时的 Manila 已经有所耳闻,社区决定将一些目光投入 Manila。但是随着后来 Redhat 收购 Inktank 的计划,大量精力仍被放在已有成熟体系的完善上,因此暂时没有对 CephFS 与 Manila 整合的动作。从 14 年的下半年开始,本人以及另一位同事开始考虑并设计实现将 CephFS 与 Manila 整合并纳入现有云体系中。在 Redhat 收购 Ceph 后,CephFS 是最大的受益者,更多的开发者和资源投入其中。15年 2 月,Sage 重新在 Maillist 中号召 CephFS 对 Manila 的支持上,大致总结出目前潜在的四种思路:
Default Driver: 使用 RBD 作为 Manila Service VM 的后端,在 VM 上启动 NFS 实例提供服务
Ganesha Driver: 使用 Ganesha 将 CephFS 重新 Reexport 出去
Native CephFS Driver: 在 Guest VM 上直接使用原生 CephFS Module 访问
VirtFS Driver: 将 CephFS 挂载在 Host 端,VM 通过 VirtFS 访问
在 Ceph I 版的 CDS 上讨论这些思路的利弊openstack manila and ceph,毫无疑问第一种是最简单也是性能最低的思路,而第二种仅仅是将 RBD 变成 CephFS,从理论上来将可以一定程度提供更好的性能。而第三种是最直接的方式,但是在云环境下实际上是不太会允许 VM 业务网络 能够直接访问后端的存储网络的,而在 VM 上直接提供对于 CephFS 的访问也暴露了 CephFS 目前简陋的安全隔离性,因此大概也只能在内部小规模私有云中被接受。而第四种在理论上提供了最好的使用模型,完全如果 virtio-block 的模型将文件系统从 Host 上暴露给 Guest VM,利用高效的 virtio 框架作为 guest <-> host 数据传输支撑,Host 直接访问 CephFS 集群来在 Host 端通过聚集效应获得更好的性能支持。
VirtFS & 9p
我们知道 Virtio 提供了一种 Host 与 Guest 交互的 IO 框架,而目前 KVM 的块存储主要使用的就是 virtblk 进行块设备指令交互,那么 VirtFS 作为文件系统指令的交互后端是如何作为呢?
VirtFS 是 IBM 于 2010 年提交的 PaperVirtFS—A virtualization aware File System pass-through的主要成果,其主要利用 9P 作为 virtfs 的协议指令在 Host 与 VM 中交互,9p协议并不是一种面向普通文件系统场景更不是面向虚拟化设计的文件系统协议,主要以简单和面向对象为特点,而 9p 在 Linux 内核中早有相应的驱动从而可以减少客户端内核工作量,而为了支持现有 Unix/Linux 下 VFS 复杂的文件指令语意,VirtFS 专门扩展了 9p 协议使得支持扩展属性和 Linux 文件权限体系命名为 9P2000.L。而 VirtFS 目前在 Host 上的后端主要是 Local FileSystem,这时候我们既可以通过 Mount CephFS 目录到 Host 系统或者直接通过 libcephfs userspace library 来直接通过 QEMU 访问来绕过 Host Kernel。虽然目前 libcephfs 在 IO 带宽上内媲美内核实现,但是在多文件压测上仍然逊色于内核模块,而 libcephfs 理论上是能提供更完美的 IO 路径。
因此,在基于 OpenStack 的云平台下,使用 CephFS 作为共享文件服务的存储后端,利用 VirtFS 作为 Guest 到 Host 的管道我们可以拥有一个理想的 IO 路径,提供高效的性能、充分的隔离性和客户端支持。最后一步实际上是 9p 协议在 VirtFS 实现上的低效性,通过简单阅读 9p 协议和其实现,我们可以了解到 9p 作为简单文件系统协议,在 Linux 典型的 IO 场景下缺乏控制流缓存这一本质缺陷,完全不在客户端实现任何结构缓存或者类似优化机制,而 QEMU 端虽然存在一定的结构缓存,但是因为其对后端共享文件系统的未知性,依然不会缓存。因此,VirtFS 已然可以提供超过本地块设备的单文件 IO 读写性能,但在大量文件控制加数据流这一典型场景下仍存在大量问题,解决好从 Guest 到 QEMU 的 9p 协议性能问题是这一方案目前最后的一公里。参考在 CDS 这个 Topic 的讨论
最后,虽然上述主要讲述 Ceph 在文件共享服务中的情况,但是应用到其他存储后端甚至是其他 Hypervisor 依然有可参考性,比如目前火热的 Docker(这个方向是 Sage 和作者本人在今年的合作点之一)!
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞0作者其他文章
评论 0 · 赞 2
评论 0 · 赞 1
评论 0 · 赞 3
评论 0 · 赞 0
评论 0 · 赞 0
添加新评论0 条评论