解析 Ceph: CephFS 进展
CephFS 一直是 Ceph 开发者心头的一块重地,不管是从 Ceph 项目伊始就是为了分布式文件系统打造,还是到现在一个严格意义的 POSIX 接口实现的分布式 NAS 系统存在极大的复杂性挑战,使得 CephFS 从最开始的众星捧月到失去耐心,而在 Inktank 被 RedHat 收购后重新被注入一股强心剂,不管是 RedHat 还是 Inktank 都对支持 CephFS 都有极大的关注度。在通常意义上来讲(也是社区内部的看法),Ceph 目前主要还是活跃于云环境,在其他领域仍处于尝鲜或者存在较大的切入难度,而 CephFS 被社区贯以极大的希望去拓展广泛的 NAS 领域,而新兴的容器不管是 Docker,Kubernetes 还是 Mesos 又或者 Host OS 如 Atomic,CoreOS,Snappy Ubuntu 都有与 CephFS 联手的极大需求。拿 Sage Weil 的话来说,容器存储是 Ceph 需要征讨的下一个领地。
从社区到 Redhat,整体的优先级顺序分别是“性能”,“CephFS”,“跟新兴云平台的合作”,“与大数据平台的合作”,我们从这里看到 CephFS 在社区里面的优先地位。由于 CephFS 存在极大的变动性,本文更多关注于从用户角度理解 CephFS 的概括,进展,对于 IO 或者实际实现并不多涉及。
难度
CephFS 目前所受的广泛关注实际上也是与其本身的复杂性有关,众所周知,一个 Scale Out 的系统本质上在于把所有数据解耦分离,而一个 POSIX 文件系统是很难做到这点:
多个客户端的同时写必须是“成功”或者“完全失败” → 锁机制
Inode 由于目前的层级关系存在依赖性
客户端是带状态的系统
数据丢失将对整个子树造成影响
分布式系统本身的复杂性带来对 POSIX 语意的影响,如文件系统满,客户端/服务器挂了,客户端实现有差异
但正因为一个文件系统实现了众多的特性,使得应用可以非常享受逻辑业务本身。如果 SQL 与 NOSQL 关系一样。
架构
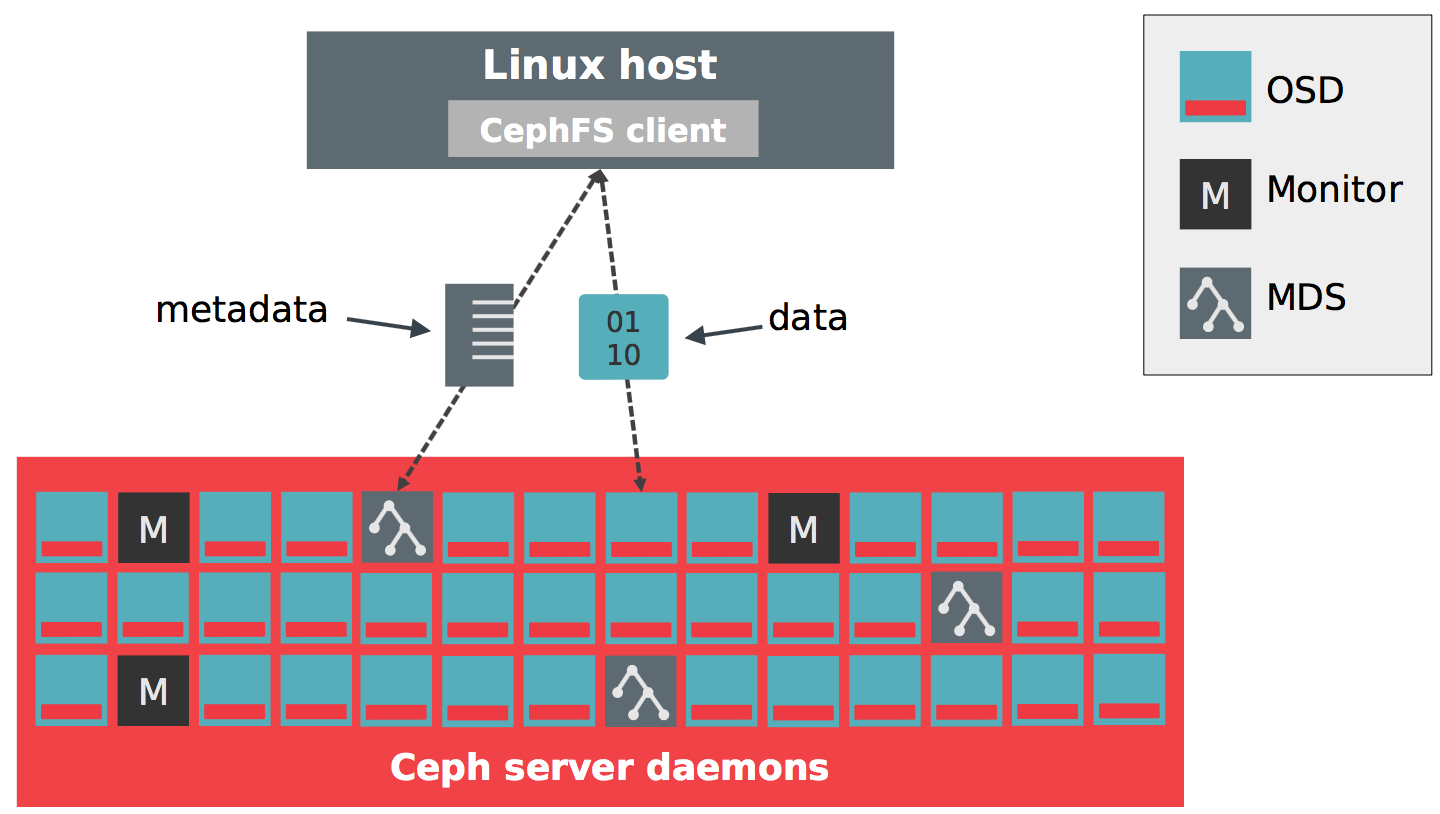
CephFS 继承了 RADOS 的扩展性和恢复能力,使用 MDS 组件管理所有 POSIX 相关的元数据,MDS 不会负责实现任何数据的存储而依赖于 RADOS 本身。
ceph-deploy mds create myserver
ceph osd pool create fs_data
ceph osd pool create fs_metadata
ceph fs new myfs fs_metadata fs_data
mount -t cephfs x.x.x.x:6789 /mnt/ceph这段简单的命令构成了如何在一个 RADOS 集群上构建一个新的 CephFS 集群,我们可以看到每一个 FS 都存在两类 Pool 分别是 Metadata Pool 和 Data Pool,我们可以使用 CRUSH 规则来为 Metadata Pool 使用更快的存储,而 Data Pool 使用更慢的存储。
CephFS 的元数据中每个目录会作为一个或者多个 Object 存储,类似 . 的命名方式。同时每个 inode 和 dentry 信息也会被内置其中,该类 Object 会被存储到 Metadata Pool 中。而文件实际数据也以类似的 . 存储到 Data Pool 中。同时还会像 XFS Log 一样存在 Log Object 存在于 Metadata Pool,是为了实现涉及多个 Object 的事务性操作准备,因为 RADOS 并不提供多对象的原子性。该 Log Object 包含了最近的所有元数据操作,在存在意外时可以使用 Log Object Replay 之前的数据。
除了本地文件系统都具备的典型结构外,CephFS 还有另外一类 MDSTable Object 用来存储每个 MDS 的 Session,Inode 分配情况,Snapshot ID 和状态等等。这些对象也是存在于 Metadata Pool。
现状和发展
Firefly 依赖所有的 CephFS 工作分成以下部分:
- 优雅的错误处理
- 集群问题的监测和汇报
- 提供恢复工具
- 大量的 QA 测试集
从实际的变化来看,比如 cephfs-journal-tool 用来对被损害的对象做恢复,同时改变了之前的日志格式,使得能够跳过日志数据被破坏的片段。而 cephfs-table-tool 用来修复 session/inode/snap 相关的对象恢复。在文件系统快写满时,会允许 Delete 相关操作继续同时会拒绝其他操作包括 fsync 等。同时支持对于客户端的管理,如:
ceph osd blacklist add
ceph daemon mds. session evict
ceph daemon mds. osdmap barrier未来的主要进展主要是在提供一个完整的 FSCK & Repair 工具,同时对 多 MDS 协同,快照等功能进行加固。FSCK 能力被社区及其重视,这实际上是其他几乎所有分布式文件系统所不能提供的,Sage 也将此看做是标记 CephFS 为 “Production Ready” 的标志,他希望在 J 版能够做到这点。拥有 FSCK 意味着 CephFS 能够经受更多的数据破坏和潜在的 Bug,使得文件系统受影响的危害性大大减少。但是对于 CephFS FSCK 难度也是显而易见的,因为我们需要修复一个 RADOS 集群数据而不是一块磁盘,大量的数据使得我们几乎不可能将修复情况全部存储在内存中,集群的庞大性使得对于修复的时间也是一个亟待考验的事情。
整个修复方案分为两部分,第一部分是从整个文件系统角度,至上而下。在修复过程中,会使用深度优先算法检查每个文件对象的正确性,目录对象是不是正确描述了整个目录情况,同时提供一些额外的 Scrub Stamp 来标记过往的检查时间。而第二部分是从文件或者目录角度去回溯每个文件或者给定目录的正确性,去 RADOS 做数据遍历。
小结
总而言之,CephFS 是 Ceph 世界里下一个被期待的重大事件,它使得 Ceph 在统一存储的路上可以跨出一大步来完成庞大生态系统的闭环化。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞0作者其他文章
评论 0 · 赞 2
评论 0 · 赞 0
评论 0 · 赞 1
评论 0 · 赞 3
评论 0 · 赞 0
添加新评论0 条评论