Unix服务器重点监控指标及算法介绍
作者:王紫琦
文章来自微信公众号:平台人生
Patrol for UNIX产品概述
BPPM Patrol产品支持多种Unix操作系统,包括Linux和HP。在被管机部署Patrol产品(Patrol Agent代理、Unix知识模块KM)后,Patrol Agent监控代理就开始采集本机的CPU、内存、硬盘、进程及操作系统日志文件等参数,同时让Patrol Console端(管理控制台Windows)取走这些参数,Patrol Console将取到的这些数据与配置中相关告警设置进行匹配,满足对应阈值等条件后则发送事件到集中监控平台,告警通知相应运维人员,从而保证了系统的高可用和高可靠性。
注:Web版Patrol Console管理控制台面向系统管理员及平台运维人员,提供集中的用户监控管理界面,对系统性能和可用性进行集中监控,Windows版Patrol Console管理控制台则为监控实施人员提供集中的配置管理界面,对监控策略进行集中的配置和管理。
每台被管机只有一个Patrol Agent代理,但可以有多个应用的KM(为Agent标识管理对象,提供监控指标,并定义监控对象发生变化时所需执行的动作),Patrol对被管机的监控操作就是通过KM for UNIX实现的。
本文主要对不同UNIX操作系统通用的监控指标及计算方法进行简要介绍。
UNIX服务器性能监控指标
CPU
Unix服务器CPU利用率指标-CPUCpuUtil:
监控原理:从/proc/stat的第一行提取数据:用户时间(user)、低优先级用户模式(nice)、系统时间(system)以及空闲的处理器时间(idle)等其他数据。
算法:CPUCpuUtil =(user + nice + system)/CPU时间* 100%
Unix服务器CPU等待IO时间指标-CPUWio
这是一个衡量磁盘IO性能状态的指标,提高命中率简单方式就是增大文件缓存区面积,缓存区越大,预存的页面越多,命中率也越高
监控原理:通过vmstat命令查看wa参数,高过30%时IO压力高。
算法:CPUWio=(CPU IO等待时间 ) /( 总CPU时间) * 100%
Unix服务器CPU占用率指标- CPUSysTime
监控原理:从/proc/stat中提取数据:
算法:CPUSysTime =system/ CPU时间* 100%
内存
监控原理:通过定期采集/proc文件系统内的meminfo文件来获取当前内存使用情况,需要使用的指标有:MemTotal ,MemFree,Buffers,Cached
MemTotal:总内存大小
MemFree: 空闲内存大小
Buffers和Cached:磁盘缓存的大小(Buffers和Cached的区别:
buffers给块设备做缓冲大小,用来存储目录里面有什么内容,权限等,随时都在增加;cached 则是用来给文件做缓冲。)
使用free命令可以看到:
对操作系统而言:MemFree=total-used=15951-8285=7666 (M)
对应用程序而言:
MemFree= buffers+cached+free=351+3900+7666=11917 (M)
所以以“监控应用对物理内存使用情况”为目的,采用如下计算方法:
Unix服务器剩余内存利用率指标- MEMAppUsablePerc
算法:MEMAppUsablePerc=1- free命令中的物理内存使用率
=(total-free-buffers-cached)/total* 100%
Unix服务器可用内存利用率指标- UpAvailabelMemPct
算法:UpAvailabelMemPct =(free命令中剩余物理内存+buffers+cached)/total*100%
=MEMAppUsablePerc+(buffer+cache)/total*100%,
该指标低于10%,表明Unix服务器可用内存利用率很低。
Unix服务器实际可用内存(考虑缓存)二次开发指标-ActualMemFree
算法:ActualMemFree= total-free-buffers-cached,
NTP服务器时钟服务
Unix服务器NTP服务器时钟服务状态指标- NTPStatus
监控原理:执行命令“/usr/sbin/ntpq -p”,首列中存在一个remote server的首字符为“*”,则服务状态正常;否则表示同步未结束。
算法:取值0表示状态正常,1表示同步未结束,2表示服务未启动
NTP服务器时钟服务offset值- Offset
offset值表明主机通过NTP时钟同步与所同步时间源的时间偏移量,单位ms.
监控原理:执行命令“/usr/sbin/ntpq -p”,提取“*”行中的offset进行展示
offset越接近0,说明主机和ntp服务器的时间越接近,offset值大于50应当予以关注。
文件系统
Unix服务器文件系统空间占用率指标-FSCapacity
算法:文件系统占用磁盘空间比率。
监控原理:执行命令“df -h”,提取对应文件系统第5列数据(Use%),如图:
可知/home/ap/patrol的文件系统空间占用率为29%。
注:文件系统空间占用率FSCapacity高于70%则需要告知系统管理员予以关注。
Unix服务器文件系统Inode占用率指标-FSInodeUsedPercent
算法:inode也会消耗硬盘内存,inode占用率指硬已使用的inode数量占硬盘分区inode总数的比率。
监控原理:执行命令“df -i”,提取对应文件系统第5列数据(IUse%),如图:
可知/home/ap/patrol的文件系统Inode占用率为3%
注:文件系统Inode占用率FSInodeUsedPercent高于70%则需要告知系统管理员予以关注。
进程
监控原理: BMC监控代理Patrol agent在DCM采集模式下,通过在UNIX服务器上加载“进程监控KM”来实时监控服务器上的进程数、僵尸进程数是否正常以及进程占用CPU和内存比率。
其中进程占用CPU(PROCPPCPUPerc)和内存比率(PROCPPMem)指标不设固定阈值,管理员可根据系统情况自行设置。
接下来,以“发现Linux主机patrol agent进程占内存高”为例,阐述Patrol所提供的进程监控KM模块的在查询内存占比的便捷性。
发现问题:收到某Linux主机”PatrolAgent进程占内存高”的次要告警邮件,告警指标为:PROCPRES/PatrolAgent/PROCPPMem。
查看和问题只需登录BMC Patrol Central控制台查看该监控指标的采值情况,指标节点位置以及当前值如图: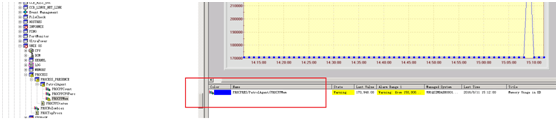
上述操作相当于登录到被管主机执行如下命令查看各进程的资源占用:
$ps -ef|grep 3181
获取patrol进程号PID,然后
$pmap -d PID//最后一行会显示实际的内存占用
或者登录到被管主机执行top命令查看各进程的资源占用:
$top –u patrol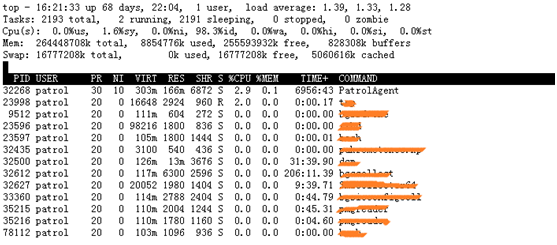
日志
对操作系统日志的监控主要包括:
1) 对日志文件状态(LOGStatus)、大小、增长率进行监控。
LOGStatus算法:1 = OK; 2 = modified; 3 = read error; 4 = inactive; 5 = missing message error;
注:配置文件监控阀值设2-2,日志文件监控阀值只设3-5,即,配置文件被修改则告警,日志文件是发生读取错误,非活动状态,信息丢失则告警。
状态3通常是由读权限或者日志路径改变引起。
2) 匹配日志中的关键字,出现设定的错误关键字则告警,并将关键字所在的整行信息以文本形式输出。
日志关键字监控指标主要包括无变量日志文件监控指标-LOGSearchString和带变量日志文件监控指标-StringMatchs,取值均为服务器日志文件匹配到错误关键字次数。
例如:Patrol扫描被管服务器的/var/log/messages日志,当匹配到“error“、”failed”关键字时,默认发出次要告警;匹配到"Remounting filesystem read-only"、"EXT3-fs error"、"NIC Link is down"、"Firmware hang detected"、"SCSI error"则默认发出主要告警。
TCP端口连接数
如果服务器网络连接过多,那么会造成大量的数据包在缓冲区长时间得不到处理,一旦缓冲区不足,便会造成数据包丢失问题,对于TCP,数据包丢失便会进行重传,这有会导致大量的重传;对于UDP,数据包丢失不会进行重传,那么数据便会丢失。因此,服务器的网络连接不宜过多,需要进行监控。
Patrol for Unix可监控8种端口状态:establish、time_wait、fin_wait1、fin_wait2、close wait、SYN_RCVD、SYN_SENT、LAST_ACK状态。
查看命令:netstat
Proto:协议名
Recv-Q:内存中的接收队列,如果该值很大说明接受包的速度大于CPU处理速度,可能由CPU负载过高引起。Recv-Q正常值为0。
Send-Q:内存中的数据包发送队列,该值过大说明可能网络状况负载较大,也可能因等待对方主机ACK时间过长导致。Send-Q正常值为0。
Local Address:本地地址与端口
Foreign Address:远程地址与端口
State:状态
PID/Program name:进程ID与进程名
端口连接数指标- 当前连接数(connectionnum)和最大连接数(TopconnNum)
端口状态指标- portstate:监控端口listen状态,状态0为正常,1为异常。
此外Patrol for UNIX还可以实现对Unix服务器磁盘、内核参数、Swap空间占比、通断性IP地址、HP双机服务等指标的监控,这里就不再分开一一赘述。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞0本文隶属于专栏

作者其他文章
评论 0 · 赞 2
评论 0 · 赞 3
评论 2 · 赞 9
评论 7 · 赞 25
评论 0 · 赞 3
添加新评论0 条评论