
详解两地三中心GDPS双活解决方案
最近“宇宙行”两地三中心同城切换公开观摩的消息看了吗?其技术就是这个——
两地三中心GDPS双活解决方案
A. 为什么采用两地三中心GDPS 双活解决方案?
首先澄清一个概念,如果我们仅仅是指两地三中心GDPS灾备解决方案的话,那么早在七、八年前国内很多大行就已经做到了这一点,具体的实现多是通过同城两个中心的GDPS PPRC解决方案联合异城两个中心的GDPS z/OS Global Mirror或者GDPS Global Mirror解决方案。
我们这里提到的两地三中心GDPS双活解决方案是近三年来很火的一个主题,而且因为今年在某一大行的成功实施,使得这个主题无数次被提及。
那么为什么要采用两地三中心GDPS 双活解决方案呢?哪些场景下可以用到这个解决方案?
想来大家都应该看到过:银行营业网点或者银行官网上会发出因为某系统升级或者故障从凌晨几点到几点无法做交易的消息。事实上无论是计划内的应用,数据库,中间件,系统和硬件升级维护,或者计划外的系统综合休(SYSPLEX)级的故障,还是突如其来的火灾,地震,水灾,以及最要命的恐怖袭击,都有可能造成银行系统的不可用,进而造成业务的中断。各大行都迫切希望减少计划内和计划外停机的业务不可用时间,最好能够在面对各种极端情况时,依然能够保证业务的持续可用性,让用户感觉不到有任何故障存在,故两地三中心GDPS 双活业务持续可用解决方案应运而生。
该解决方案在不同城市的两个数据中心间沿用已经存在的GDPS z/OS Global Mirror灾备解决方案,其核心则在于同城两个数据中心间的GDPS双活方案,从而使得关键应用运行于同城的任一个数据中心,在这两个数据中心之间做到自如地站点级别切换,一个站点的应用故障不会影响到另外一个站点的应用操作。
GDPS双活的英文全称是Geographically Dispersed Parallel Sysplex Active-Active,即地理分散并行系统综合体双活解决方案. 该解决方案由两个分布于不同数据中心的并行系统综合体组成,这两个数据中心的功能分布是1:1模式,同时对外提供服务,数据中心间实现负载均衡,任何一个中心具备100%生产支持能力,具备无缝业务切换能力,减少应用停机时间,从而保证业务的持续可用性。
说到GDPS 双活解决方案的适用场景,我们需要明确GDPS双活解决方案是一个新生的且持续发展的解决方案,总共分成三个阶段,第一阶段为GDPS Active-Standby, 第二阶段为 GDPS Active-Query, 第三阶段为 GDPS Active-Active, 当前处于第二个阶段。
在当前GDPS Active-Query通常的配置中,两个Active 的站点A和B,站点A是生产站点,主要用于运行核心业务,包含OLTP(联机事务处理) 和批量作业,站点B则只用于运行只读的Query(查询),并且随时准备着运行OLTP和批量作业。
如果在站点B上监控到端到端的延时超过预定义的阈值,那么Query能够自动地Switch到站点A去做运行,当然这里我们可以在一分钟内通过SA REXX从监控表里抽几次样,如果几次都超过的话,再做切换,会更为合适。
对于站点A而言,如果行里要对站点A的生产系统进行升级和改造,以前在行里通常需要请求三到五个小时的停机时间窗口(遇到问题的话,可能会更久),在这个过程中,站点A是无法对外界提供服务的。
但是现在采用了GDPS 双活方案后,因为站点 B可以无缝接管站点A的业务,所以可以通过GDPS A-A作站点级切换,把OLTP Workload 定向到站点B,由B站点对外界提供业务,此时所有的OLTP和Query Workload都运行在了站点B,整个过程对于客户而言,都是透明的。
然后对站点A进行升级,可以是升级应用程序,硬件,DB2z版本,甚至z/OS, 到升级完成后,在B站点停OLTP Workload,反向同步站点B改变的数据到站点A, 再把OLTP Workload回切到站点A。
整个过程中,站点切换耗时大概2分钟左右,回切基本上是相近时间,在站点B停OLTP Workload并反向同步数据耗时大概是10分钟,加到一起整个升级过程把对外界不能提供业务的时间控制在了十分钟的级别,与原有的三至五个小时相比有了巨大的改进。
B. GDPS双活解决方案的技术组成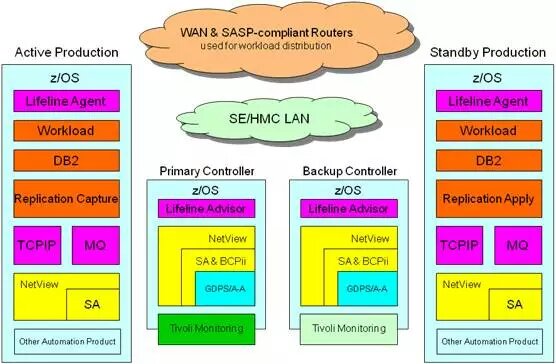
G 1 -- GDPS 双活解决方案架构
GDPS双活解决方案在数据复制上与传统的GDPS解决方案(GDPS PPRC, GDPS z/GM, GDPS GM)有着本质的区别,就在于它不依赖于基于硬件的数据复制,而是基于软件QREP的异步复制技术,在源站点QREP Capture到DB2改变的数据,通过MQ传输到目标站点,再由QREP Apply在目标站点Replay Transactions。
GDPS双活解决方案的自动化控制至少体现在Workload级别,GDPS A-Q Workload由Software, Data,和Network Connectivity组成,分成Update Workload和Query Workload两种类别,这里Query Workload必须关联到Update Workload。
在SA的Policy中,我们会定义相应的Workload以包含CICS TOR, QCAP, QAPP, DB2和CGs。
G2 -- Update Workload & Query Workload
WKL_CICS_P1_Q 里包含所有Query的 CICS TORs
因为要满足传输的性能需要,故引入QREP MCG. 这里MCG全称为Multiple Consistency Group,其名字与Workload名字相对应, 针对每个DB2 Data Sharing Group在SA Policy中定义Workload,在QREP控制表中定义MCG. 如对私业务DB2 DSG的Workload名为WKL_CICS_P1,它在SA Policy中的定义包含所有对私业务的CICS TORs, DB2 Members, LPAR, SYSPLEX, QCAP地址空间, QAPP地址空间和CGs. 一个CG(Consistency Group)对应于在同一个RECVQ复制的所有DB2表的集合.
下面讲一下QREP技术,一言以概之,即Log-Capture/Transaction-Replay.

G3--QREP 技术
首先在源端对应于QREP Capture,它会通过DB2 IFI接口,从DB2 Recovery Log捕获改变的数据,并Publish到MQ的SENDQ中,通过MQ把数据无损失地传输到目标端,在目标端QREP APPLY负责从MQ RECVQ中读取数据,并重建SQL,然后把它们Apply到目标端的DB2中Replay Transactions。
之前有提到QREP端到端的延时,这里给一个图以示其组成.为了保证QREP的高性能,在过去的日子里一直致力于提升QREP的吞吐能力,减少CAPTURE_LATENCY, 减少QLATENCY,减少APPLY_LATENCY,从而减少整体的端到端延时,以满足客户OLTP 5S以内,批量30S以内的性能要求。
G4--QREP端到端的延时组成
下面介绍一下IBM Multi-site Workload Lifeline for z/OS, 在GDPS双活解决方案中,Lifeline提供智能路由建议到外部Load Balancers,以选择相应的LPAR去运行Workload。Lifeline由Controllers上的Advisor和Workload所在LPAR上的Agent组成。下面是一个很经典的结构图。
G5--Multi-site Workload Lifeline结构
1.Advisor与Agent 之间的通信
Agent注册并连接到Advisor,Advisor发送其想要Agent监控的所有成员消息,Agent定期发送系统健康状态到Advisor,为了响应DEACTIVATE命令,Advisor发送Server Application清单至Agents,让其重置这些Server Application的连接。
2.Advisor与Load Balancer(负载均衡器)之间的通信
外部Load Balancer建立与Primary Lifeline Advisor的连接,并且通过SASP(Server/Application State Protocol) API从Advisor获得路由建议,这里Advisor仅仅提供建议,不负责实际传输或路由工作.Load Balancer多由Vendor公司提供,如F5, Citrix和Cisco。
3.Advisor与Advisor之间的通信
Secondary Advisor连接到Primary Advisor, Primary Advisor发送它的配置信息和Workload状态信息到Secondary Advisor,当前的Primary Advisor终止,或者所在系统故障时,Secondary Advisor能接管Primary Advisor的角色.这里需要保证两个Advisor的配置是相同的。
4.Advisor与Support Element(SE)之间的通信
Advisor使用BCPii地址空间作为与SEs之间通信的桥梁,获得LPARs的状态信息
5 Advisor与Network Management Application之间的通信
Advisor创建AF_UNIX套接字,通过Network Management Interface(NMI),接收来自网络管理程序的连接,为Server Applications提供Workload状态信息,站点信息,连接的Load Balancer, Agents和Secondary Advisor信息,以及路由建议。
下面我们将介绍GDPS 双活站点切换中的关键步骤,皆由GDPS A-A代码完成。
- 站点包含多个Workloads,故在触发站点切换时,触发多个Workloads的切换

- 开始Workload切换,并对站点A Quiesce Workload,以阻止新的连接

- Deactivate当前的Workload,并对站点A上的DB2 表空间加Softfence保护,以使站点A只有QREP才能去Update表,确保其它的应用都无法更改表的数据。

4.对QREP 发送STOPQ命令,关闭站点B的Softfence保护, Activate 站点B的Workloads.之后将由B站点开始提供外界服务。
5.统计站点切换时间
对于Workload WKL_NOVA_P2,在这次切换中用了1:21:22,同时有其它的Workloads也并行做着切换.整体的站点切换时间在2分钟内完成,满足银行的切换时间需求.
作者:曾脉
邮箱:zengmai@cn.ibm.com
内容声明:文中专业名词因翻译原因,表述中难免存在差异。如有疑惑,请以英文为准。同时数据来源于实验室环境,仅供参考。
来源:https://www.ibm.com/developerworks/community/blogs/IBMzOS/entry/20150101?lang=ru_ru
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞4作者其他文章
评论 1 · 赞 1
评论 0 · 赞 4
评论 1 · 赞 2
评论 0 · 赞 2
评论 0 · 赞 2
添加新评论1 条评论
2017-07-02 01:51