
HACMP的工作原理及管理
Hacmp双机系统的功能介绍
Hacmp(High Availability Cluster Multi-Processing)双机热备份软件的主要功能是提高客户计算机系统及其应用的可靠性,而不是单台主机的可靠性。
Hacmp双机系统的工作原理
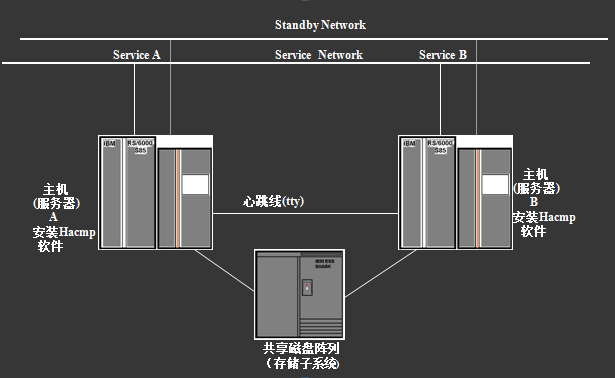
1.作为双机系统的两台服务器(主机A和B)同时运行Hacmp软件
2.服务器除正常运行自机的应用外,同时又作为对方的备份主机
3.两台主机系统(A和B)在整个运行过程中,通过“心跳线”相互监测对方的运行情况(包括系统的软硬件运行、网络通讯和应用运行情况等)
4.一旦发现对方主机的运行不正常(出故障)时,故障机上的应用就会立即停止运行,本机(故障机的备份机)就会立即在自己的机器上启动故障机上的应用,把故障机的应用及其资源(包括用到的IP地址和磁盘空间等)接管过来,使故障机上的应用在本机继续运行
5.应用和资源的接管过程由Ha软件自动完成,无需人工干预
6. 当两台主机正常工作时,也可以根据需要将其中一台机上的应用人为切换到另一台机(备份机)上运行
HACMP双机系统结构图
Hacmp安装配置前需作的准备工作
1. 划分清楚两台服务器主机各自要运行的应用(如A机运行应用,B机作为standby)
2. 给每个应用(组)分配Service_ip、Standby_ip、boot_ip和心跳线tty,
3. 按照各主机的应用的要求,建立好各自的磁盘组,并分配好磁盘空间
4. 根据Ha软件的要求,对服务器操作系统的参数作必要的修改
HACMP的常用命令:
1、查看Cluster的运行情况:
# /usr/sbin/cluster/clinfo –a
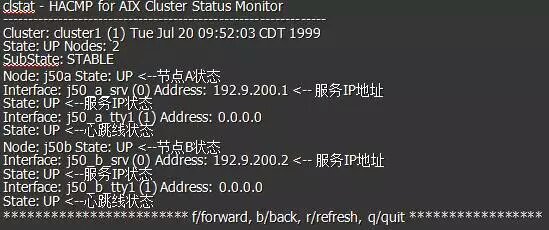
# /usr/sbin/cluster/clstat
/usr/sbin/cluster/clstat可以帮助你查看当前HACMP的节点状态。
屏幕会如下显示:
2、启动HACMP:
# smitty clstart
注:有两种启动HACMP的方式:
now:手工启动HACMP
restart、both:在系统启动时自动启动HACMP
3、停止HACMP:
# smitty clstop
注:有三种停止方式:
graceful:只停止本节点上HACMP的运行,并释放由本节点管理的资源,但允许其它节点接管。
graceful with takeover:停止本节点上HACMP的运行,释放资源,让其他节点接管。
forced:停止本节点上HACMP的运行,但不释放资源。
4、查看Cluster的进程状态:
# ps –ef | grep cluster
注:应有三个HACMP进程:clstrmgr、clinfo、clsnuxpd
5、查看Cluster的日志及错误信息:
# more /tmp/hacmp.out
# more /var/adm/cluster.log
注:可以在启动HACMP时使用 # tail –f /tmp/hacmp.out命令,以查看HACMP的启动是否正常或跟踪启动时的错误信息。
6、查看Cluster运行的历史记录:
# cd /usr/sbin/cluster/history
注:此目录下存放着每天的Cluster运行记录
7、查看Cluster运行时的网络情况及资源组的使用情况:
HACMP启动之前:
# netstat –i
此时应可以看到boot和standby地址
# lsvg –o
此时只能看到本地的VG
HACMP启动之后:
# netstat –i
此时应可以看到service和standby地址
# lsvg –o
此时应可以看到本地的VG及共享VG
HACMP常见故障解决
导致集群中节点失效的无反映开关(Deadman Switch)
问题现象:
集群中的节点经历着极端的性能问题,如:大量的I/O传输、过多的错误记录、内存不足等,导致集群管理器(clstrmgr)没有得到足够的CPU处理时间,而引起无反映开关在分配的时间被重置。某个应用程序运行权限高过集群管理器时,会导致此问题。
解决方法:
术语“Deadman Switch”指的是在特定集群条件下,未能及时重置该开关,引起系统宕机和转储的内核扩展部分。无反映开关在超过了特定的时间限制后会宕掉处于挂起状态的节点。此过程导致集群中的其它节点接管处于挂起状态节点的资源。要解决此问题需要解决与之相关的几个性能问题:
1、调整系统I/O pacing
2、增加信息同步(syncd)的频率
3、增加通信子系统使用的内存量
4、更改错误探测速率
调整系统使用I/O的步调:
使用I/O pacing调整系统,使得在大量写操作时,系统资源的分配更合理。为HACMP集群激活I/O Pacing是必要的,尤其是在集群中可能会有大量磁盘数据块写操作的时侯。
按下述步骤修改I/O Pacing设置:
# smitty hacmp
Cluster Configuration
Advanced Performance Tuning Parameters
Change/Show I/O Pacing
修改HIGH water mark for pending write I/Os per file域,推荐值为33,可用值在0-32767之间 。
修改LOW watermark for pending write I/Os per file域,推荐值为24,可用值在0-32767之间。
不同的系统,以上两个值也不同。修改上两个值只能稍微减少写次数,通常能够解决上述问题。
增大syncd的运行频率:
增加syncd的运行频率,使缺省60秒运行一次变为30秒、20秒或10秒运行一次。这样可以强迫增加I/O刷新速率,并减少由于沉重的I/O流量触发无反映开关的可能性。
按下述步骤修改syncd运行频率设置:
# smitty hacmpCluster Configuration
Advanced Performance Tuning Parameters
Change/Show syncd frequency
修改syncd frequency in seconds域,推荐值为10秒,可用值在0-32767之间。
增加通信子系统可用的内存量:
如果运行命令:# netstat –m,发现请求mbuf被拒绝,或运行命令# errpt发现LOW_MBUFS 错误,则应增加网络参数“thewall”的值。Thewall的缺省值为25%的系统实内存。可以将其增加为50%的系统实内存。
按下述步骤修改thewall值的设置:
# vi /etc/rc.net
在此文件的末尾加入:
no -o thewall= xxxxxxxxxx是指你希望设置的供通信子系统使用的实内存值。如:
no -o thewall=10240
修改错误探测速率:
如果激活I/O Pacing或增加Syncd运行频率不能解决无反映开关不能重置的问题时,则修改错误探测速率,将其值该为Slow。这样可以延长一个挂起节点调用无反映开关之前,以及接管节点探测到节点故障并获得挂起节点资源之前所需的时间。
注意:在完成上述步骤之前,I/O Pacing必须先激活。这是因为修改此设置会调整I/O数据的传输量。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞6作者其他文章
评论 1 · 赞 1
评论 0 · 赞 4
评论 1 · 赞 2
评论 0 · 赞 2
评论 0 · 赞 2
添加新评论2 条评论
2021-01-13 16:52
2017-09-04 16:38