青云QingCloud 对象存储应用与实践
QingStor 对象存储服务提供可无限扩展的存储空间、快速的数据存取性能、高度的可靠性和数据的安全性、细粒度的权限控制及简单易用的接口,以向广大用户提供廉价、可靠的存储系统。 本次分享,QingCloud 系统工程师 Osier 会分享青云QingCloud 对象存储的概念、实际的应用案例及进一步研发计划。
大家好,我是青云QingCloud 系统工程师 Osier Yang。今天我来和大家分享一些对象存储方面的内容。
“QingStor”为“青云对象存储”的项目及产品名称,为行文方便,下文将皆以“QingStor”代指“青云对象存储”。
今天交流内容包括:
- 什么是对象
- 企业 A 的存储方案演化历程
- 什么是对象存储
- 开源方案探讨
- QingStor 的架构及特性
- 如何使用 QingStor
- QingStor 用户案例 (Hash Data Warehouse – HDW)
- QingStor 更进一步的产品规划
1、什么是对象
我们从一个故事开始。在我们的对象存储研发后期,一个潜在客户来交流,他们想了解怎么用对象存储。交流期间,其中的技术负责人问了这样一个问题: “你们这既然是对象存储,那么它的类是怎么定义的?“。由此可见,即便是技术人员,也可能对”对象存储“产生误解。
所以要想讲清楚到底什么是”对象存储“,很有必要先解释“对象存储”这四个字,“存储”二字不必多说,凡 IT 从业者应该都理解,关键点是: 什么是“对象”?
Wikipedia 对“Object”分各领域做了解释(https://en.wikipedia.org/wiki/Object)。别的领域我们不管,我们只看哲学领域的定义,因为哲学领域的定义更具有普遍意义。Wikipedia 对“Object”在哲学领域的定义是:
a thing, being, or concept
在汉语里,和其英文本意最符合的词也就是”东西“了吧?百科里关于”东西“的释义如下:
泛指各种具体或抽象的人、事、物。例如:
- 明朱有炖 《豹子和尚自还俗》:“我又无甚希奇物,我又无甚好东西,他偷我箇甚的?”
- 《红楼梦》第三五回:凤姐笑道:”这一宗东西,家常不大做;今儿宝兄弟提起来了,单做给他吃。“
- 沙汀《闯关》一:“感情真是一种奇怪的东西。”
在计算机领域,“对象”(Object)除了在面向对象编程用来表示一个类(Class)的实例(Instance)外,还被常用来表示一个变量(Variable),一个函数(Function),一个数据结构(Data Structure),一段在内存中的实体,等等,相信计算机领域的研发人员在各种各样的代码或工具里都见过。举个例子,Linux Kernel (Linux操作系统的核心)的模块名以“.ko”为后缀名,“ko”的全称为“Kernel Object”,这里的“Object”和 JAVA/C++ 语言里的“Object”显然不是一回事。
由此可见,在计算机领域,“对象” (Object)这个词也是一个泛指意义的词,其意义也可类比汉语中的“东西”。你可以指任何一个事物为“东西”,也即你可以指任何一个事物为“Object”。具体是什么“东西”,依场景不同而不同。至于到底“对象存储”里的“对象”是什么“东西”,请见后文。
2、企业 A 的存储方案演化历程
要想理解什么是对象存储,我们从另外一个故事开始。企业 A 有一个应用,允许用户上传图片及视频,视频和图片的大小都比较小。
2.1 企业 A 存储方案 1
因为业务发展前期用户量很小,产生的数据量也足够小,最简单直接的方案为(实际生产中应该没人用这种方案,但最简单的方案往往更有助于我们看清问题本质):
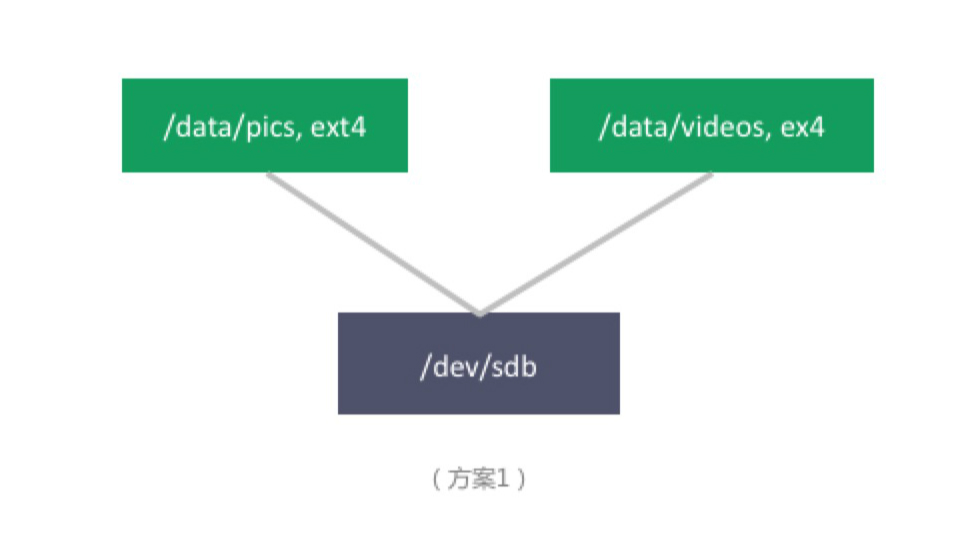
这种最简单直接的方案几乎到处是缺点:
- 单盘容量限制。总存储量及可存储的单个最大文件的大小均受单盘容量限制。
- 无数据冗余。主机宕机会导致服务不可用,甚至数据丢失;硬盘损坏会导致数据丢失。
- 无数据备份。假设企业A的运维人员误删数据,恢复数据将变得困难。
- 文件系统的限制。当存储的文件数目越来越多时,文件系统的目录树会变大,变深,读写性能会越来越差,inode 总数也可能达到限制。
2.2 企业 A 存储方案 2
随着用户上传的数据量不断增加,我们假设容量率先增大了瓶颈,企业 A 为了解决容量问题,将存储架构改变为:
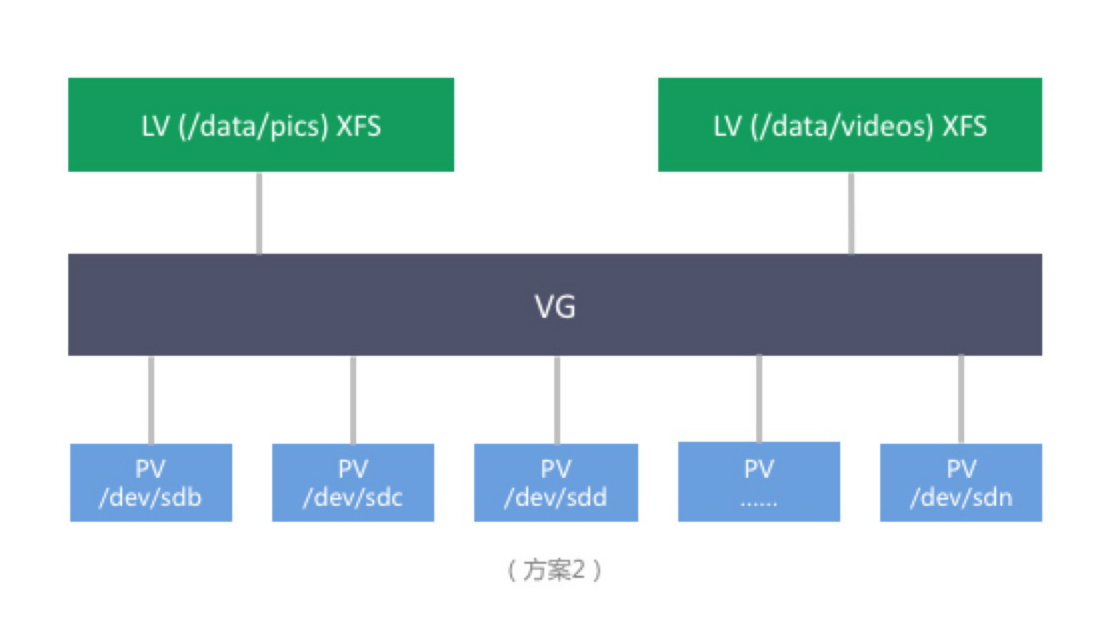
注:
- PV (LVM Physical Volume)
- VG (LVM Volume Group)
- LV (LVM Logical Group)
以上方案的利用 LVM 将众多硬盘空间抽象为一块大硬盘,突破了单个硬盘的容量限制,容量需求增加时,添加硬盘到 VG ,并对 LV 进行扩容即可。支持文件系统级别的 Snapshot , 可将数据回滚至某个点。但仍有缺陷:
- 单机容量限制。可挂的硬盘总数有限制,即总容量仍然有限制。
- 无数据冗余。虽然 LVM 支持文件系统级别 Snapshot ,但 snapshot 只能将数据回滚到某个点。并不能够应对灾难情况,比如物理机宕机,服务仍然不可用,数据也可能丢失;硬盘损坏时,数据仍然可能会丢失。
- 文件系统的限制。当存储的文件数目越来越多时,文件系统的目录树会变大,变深,读写性能会越来越差,inode 总数也可能达到限制。
2.3 企业 A 存储方案 3
假设企业 A 的存储容量需求在短时间内达不到单机的容量限制,但随着业务的发展,企业 A 开始重视数据的安全性。存储方案进一步演化为:
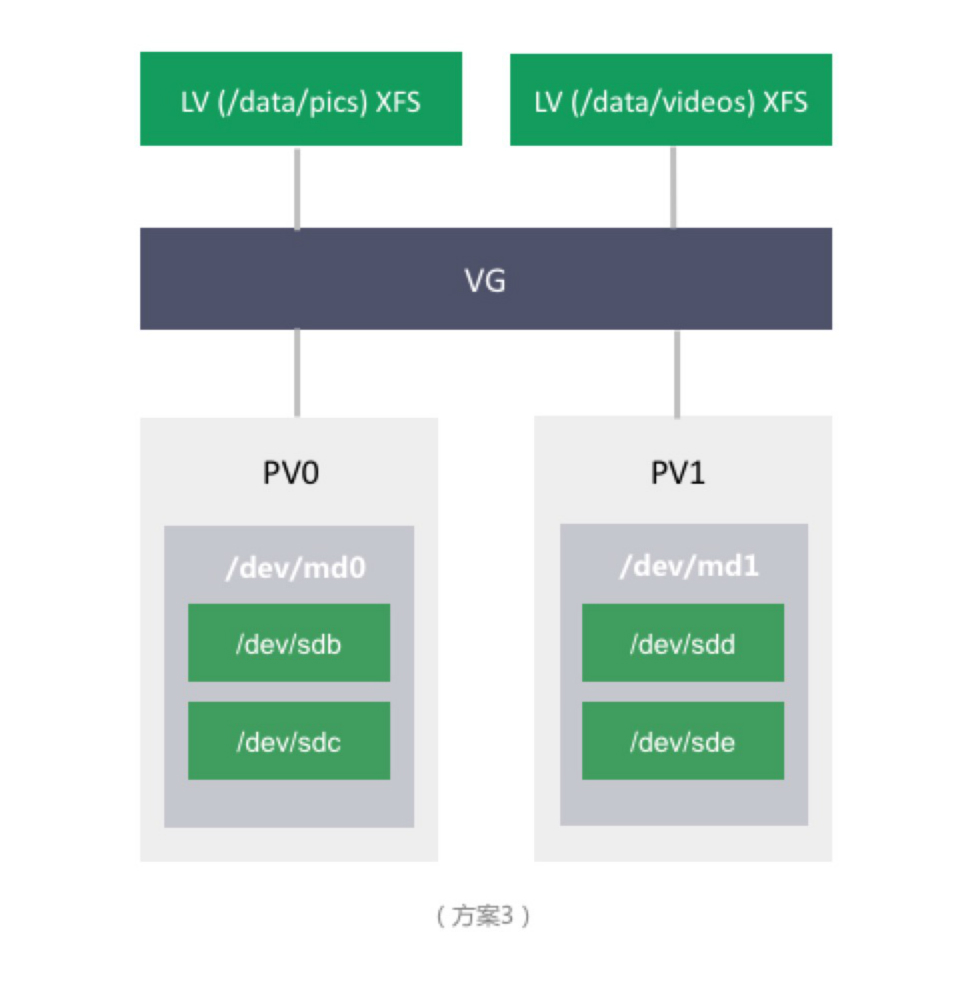
方案三引入了软 RAID 来做数据的冗余,同时保留了 LVM 带来了灵活性。但仍然有缺点:
- 单机容量限制。可挂的硬盘总数有限制,即总容量仍然有限制。
- 文件系统的限制。当存储的文件数目越来越多时,文件系统的目录树会变大,变深,读写性能会越来越差,inode 总数也可能达到限制。
- 不可靠。当宕机时,服务便不可用。
2.4 企业 A 存储方案 4
我们假设企业 A 随着业务的进一步发展,存储容量需求在短时间内仍然达不到单机的容量限制,但开始重视服务的可靠性。故将存储方案进一步演化为:

此方案保留软 RAID 及 LVM 的同时,引入了 DRBD,通过网络来做块设备级别的复制,可靠性提高了一倍。但仍然有缺点:
- 单机容量限制。可挂的硬盘总数有限制,即总容量仍然有限制。
- 文件系统的限制。当存储的文件数目越来越多时,文件系统的目录树会变大,变深,读写性能会越来越差,inode 总数也可能达到限制。
2.5 企业 A 存储方案 5
随着业务的进一步发展,单机容量已无法满足企业A的存储需求。此时只剩下一条路:分布式存储。企业 A 不想投入人力自己开发分布式存储,而开源分布式存储方案繁多,经反复调研与测试,最终将方案确定为 HDFS :
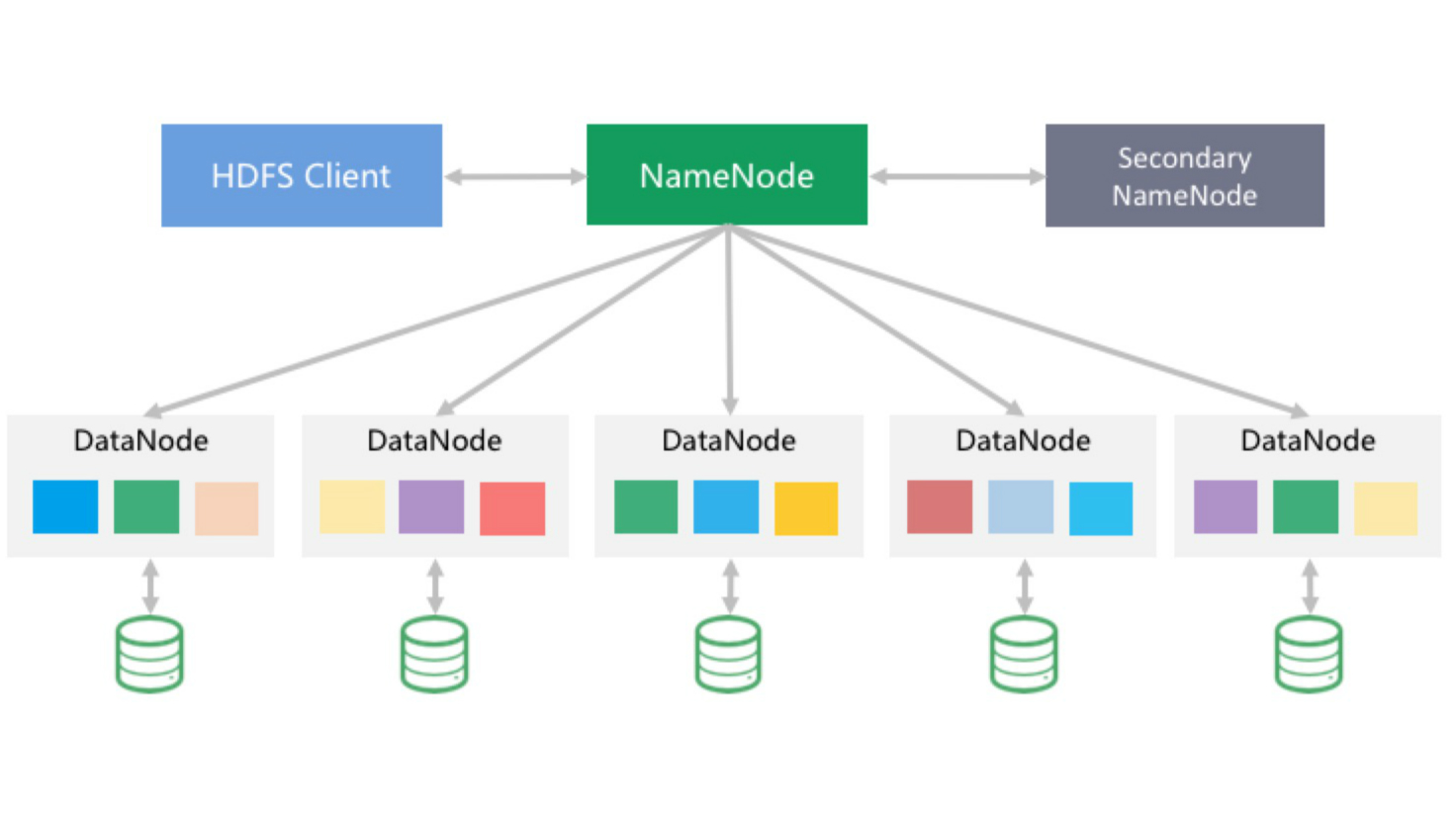
HDFS的引入去除了单机容量的限制,但仍有缺陷:
- Name Node的设计限制了不能够存储太多的文件,当存储的文件为大量小文件时,可存储的文件个数会逐渐到达瓶颈。
3、什么是对象存储
“对象存储”来源于英文“Object Storage”或“Object-based Storage”。有人可能会想,照上文所述,那“Object Storage”岂不是该翻译为“东西存储”?如果谁这么翻译,告诉我,我家里的剑好久不用了。
翻译归翻译,术语归术语,都不妨碍我们将“Object Storage”理解为“存东西的存储”,那么“对象存储”存的到底是什么“东西”?
3.1 对象存储的大致目标
现在我们回顾一下企业A经历的存储方案历程,为了满足不断发展及增长的业务需求,企业 A 不断得在解决容量,数据安全,高可靠,可存储文件多少,读写性能等诸多问题,方案也变的越来越复杂。
像企业 A 这种有大量存储需求的企业不在少数,而不同企业,不同业务的数据特征千差万别。对象存储作为一种面向多租户的公共服务,除应该具备企业A的存储方案演变过程中不断追求的特性外,还应该通用,不能假设用户的数据特征(如类型,大小)。
我们先大致归纳一下对象存储应该有的特性:
- 多租户;
- 不假设数据,包括类型,大小等;
- 存储空间可无限扩展,且性能该随容量水平扩展而线性提升,不然数据量越大,请求越多,性能却不提升,就不好玩儿了。
- 数据安全;
- 高可靠。
3.2 对象存储的索引设计
前面我们以企业 A 的存储方案演进过程中所遇到的问题,归纳出了对象存储的大致目标,但还只局限于在数据存储层讨论。下面我们来看看索引层。
细心的同学可能已经发现,前文中我们一直在提一个问题:文件系统的限制。当存储的文件数目越来越多时,文件系统的目录树会变大,变深,读写性能会越来越差,inode 总数也可能达到限制。
文件系统层次的限制根源在于当前的文件系统的设计是为单机存储而设计的,树状的索引结构在非海量数据时代,很好的完成了数据索引的使命。但在面向海量存储时,就表现出了一些先天性问题,尤其面向海量小文件时。
避免文件系统面对海量数据时的缺陷可以有多种方案,其中最直接有效的方案是构建独立索引层,这样既能避免文件系统索引的问题,同时能利用文件系统的长久以来积累下来的优势。那么怎么设计独立索引层?如前所述,文件系统面对海量数据时的缺陷主要来自于树状索引结构,那新构建的独立索引层就应该将树状索引压扁,能压多扁压多扁,最终的索引结构如下 (其中 Bucket 这一级是不可避免的,无论如何,存储空间总是要区分开的)。

如上图所示,“Service”为顶层命名空间(Namespace),其下可有任意多个 Bucket (存储空间),Bucket 命名空间为第一级命名空间,其下可以有任意多 Object。
3.3 什么是对象
探讨完数据存储层及索引层,我们终于可以回到本节开头的问题了:“对象存储”的“对象”是个什么“东西”?
如果有人了解过文件系统的实现,定会发现文件系统的索引结构里包含了许多元信息,而对于对象存储系统而言,其中很多元信息无意义,我们创建了独立的索引层,自然也不想再带着这些无意义的元信息,我们希望独立的索引层存储的索引不多不少,足够精简,只保留基本且必须的元信息: 如 “类型”,“大小”,“校验值”,“最后修改时间”。
对于多数业务来说,基本的元信息已经足够,但对于某些业务而言,可能还需要更多的元信息。比如一个歌曲文件,除了类型、大小、校验值,最后修改时间,用户的业务还可能需要额外的描述,如:
- 歌手是谁
- 歌曲属于哪张唱片
- 歌曲属于什么风格
- ……
如果对象存储的索引层能够允许用户自定义元数据。用户就不需要单独维护数据库去存储这些信息。
了解了”对象”(Object)的索引构成后,我们终于可以归纳一下”对象”(Object)”到底是什么”东西”了。
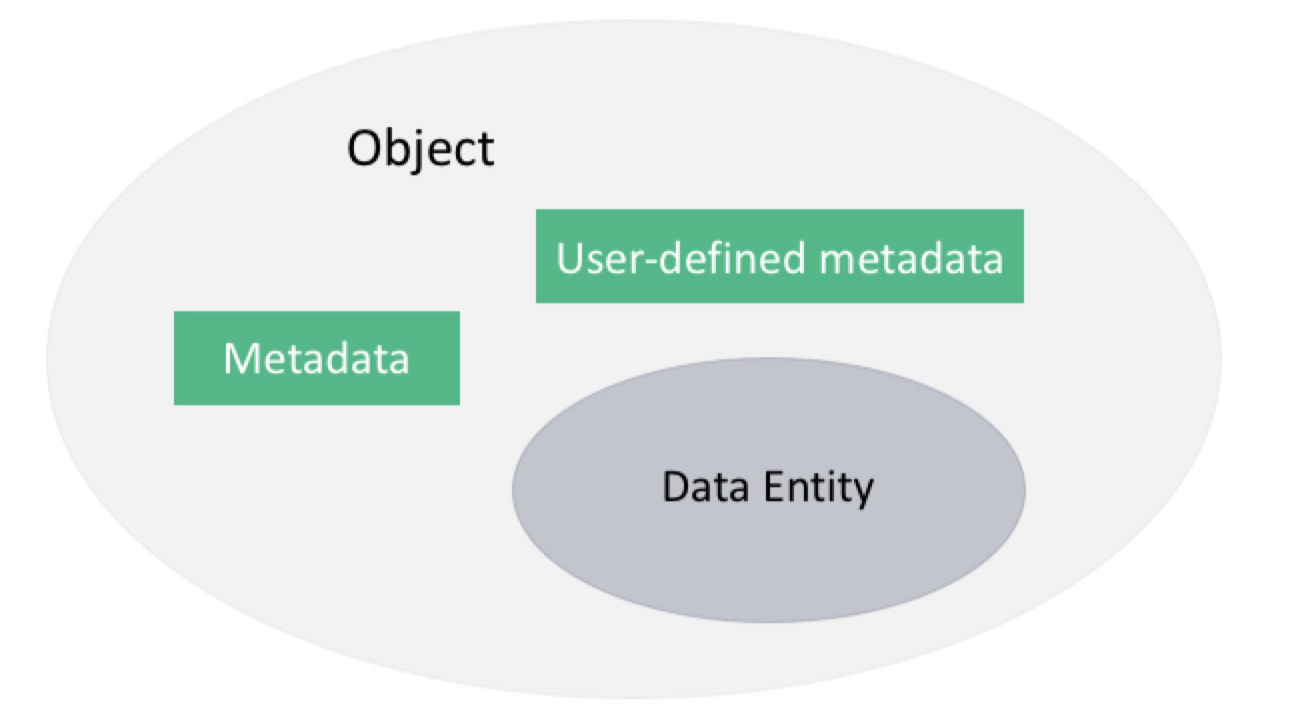
- 数据实体 (Data Entity)
- 数据实体的元数据 (Metadata)
- 数据实体的用户定义元数据 (User defined metadata)
下面是一个文件的元数据示例:
HTTP/1.1 200 OK
Server: QingStor
Date: Sun, 16 Aug 2015 09:05:00 GMT
Last-Modified: Fri, 14 Aug 2015 09:10:39 GMT
ETag: "0c2f573d81194064b129e940edcefe9b"
Content-Type: image/jpeg
Content-Length: 7987
Connection: close
Request-ID: aa08cf7a43f611e5886952542e6ce14
其中的“Last-Modified”, “Content-Type”, “Content-Type”, “ETag”(数据实体的 MD5 值)即为 QingStor 上一个“对象”(Object)的元信息。
4、开源方案探讨
每次交流时,都会有人问到对象存储相关的开源方案,问 Qingstor 为什么我们没有采取开源方案。我们在正式开发 QingStor 前,确实调研及测试过不少开源方案,但无一能够满足我们的目标。下面我们就选几个主流的开源方案探讨一下。
4.1 Openstack Swift
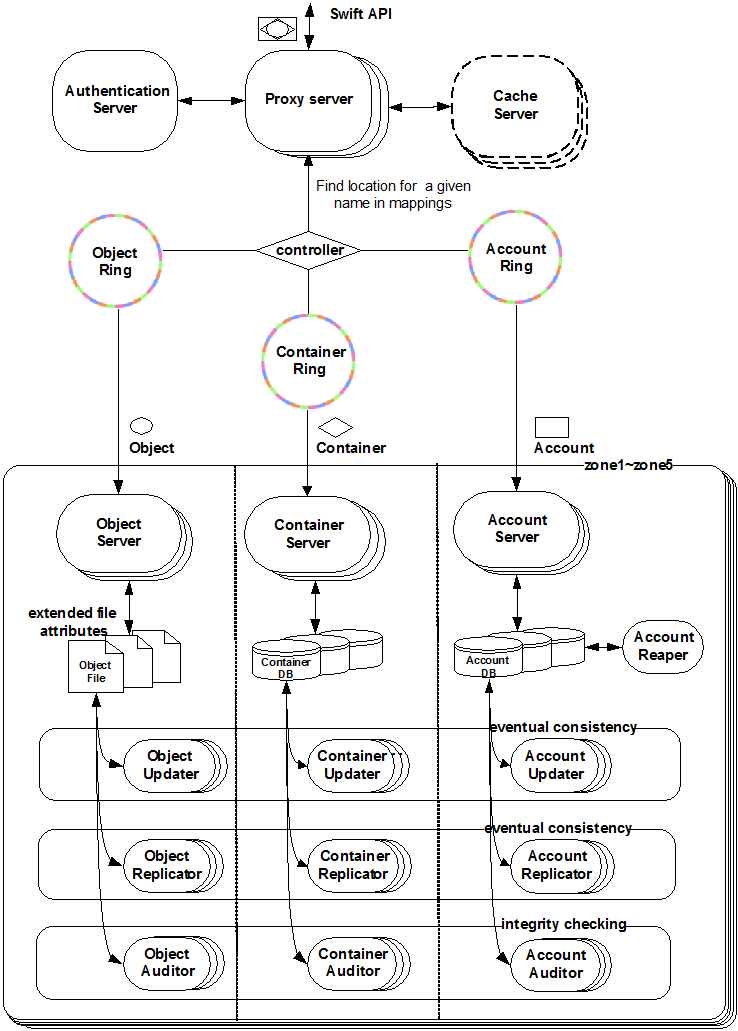
上面是 Openstack Swift 的架构图。下面是 Swift 的问题:
- 未对小文件进行合并。从上面的架构图中我们可以看到,其没有文件合并组件,当存储的小文件数量过多时,系统会在最底层的文件系统这一层就会开始出现瓶颈,读,写,列取,甚至 Swift 自身组件(如 replicator,数据迁移/修复) 都可能会出问题。具体见: http://engineering.spilgames.com/openstack-swift-lots-small-files
- Object 索引是在文件扩展属性里的,获取 Object 元信息慢,尤其当文件数目过多时。
- Object 索引是在文件扩展属性里的,支持用户自定义 Object 元数据会进一步加剧元信息获取性能问题。
- Object 索引存储在文件扩展属性里的,除此之外没有别的索引。一个 Container (存储空间)的元信息对应一个 Sqllite 数据库,其中维护着该 Container 下的 Object 列表信息,这是为了 Workaround 从文件系统列取 Container 下 Objects 时糟糕的性能。但问题是当一个 Container 下 Object 过多时,Sqllite 数据库撑不住。即单个 Container 下存储不了多少 Object。
4.2 Ceph Radosgw
Ceph Radosgw 看起来很美好,但其糟糕的索引设计注定完全不能用于生产。这里不展开说了,感兴趣的可以看下面的链接:
https://github.com/ceph/ceph/pull/2187
4.3 Gluster
Gluster 的设计非常工程派。无单独所应;未对文件进行任何切割或合并操作;所做的所有事情都是为了一个目的:一个更大的文件系统。
这种设计带来的问题是,它并未解决文件系统本身的限制,因为它未对文件系统的语义做任何修改。当存储海量小文件时,性能会变的很差,尽管 Gluster 为此做了各种优化(有兴趣的可以查找 Gluster 关于小文件读写性能优化的各种 translator ),但并不能改变其根本。
5、QingStor 的架构与实现
5.1 接入层
在章节“3”中我们逐步探讨了数据存储层,索引层,及对象。但为了循序渐进,企业A的存储演化过程中,我们刻意省略掉了一个组件: 接入层。
传统存储的访问接口各不相同。块存储暴露给用户的是一个一个的 Block 。文件系统或网络文件系统(如 NFS )暴露给用户的是 POSIX 文件系统接口。但无论是哪一种接口,都有一个共通的问题: 数据流转不便。
而对象存储通过将资源 URL 化,数据的流转方式就方便多了。
对象存储接收请求的协议为 HTTP ,所有一定有 HTTP Server ,接收到用户的文件上传和下载请求后,需要有相应的处理方法。且作为面向多租户的公有服务,无法假设用户的请求行为,所有用户加起来的并发请求可能会很大。另外,接入层得高可用。所以得引入负载均衡。
我们把最前端的负载均衡,后端的 HTTP Server ,及各种处理方法,统称为接入层。接入层作为QingStor的最外层建筑,向用户暴露 RESTful 的 API 。
5.2 多区域(Zone)部署
青云QingCloud IaaS 服务为多区域部署,用户可根据自己的需求选择适合自己的区域部署服务。而 QingStor 作为存储服务,不应该远离计算资源(简单计算资源如主机,复杂计算资源如 QingCloud 的大数据平台, Spark、Storm、 Hadoop、etc)。所以我们把决定权交给了用户,由用户决定如何部署计算及存储资源。
QingStor 的多区域部署示意图如下: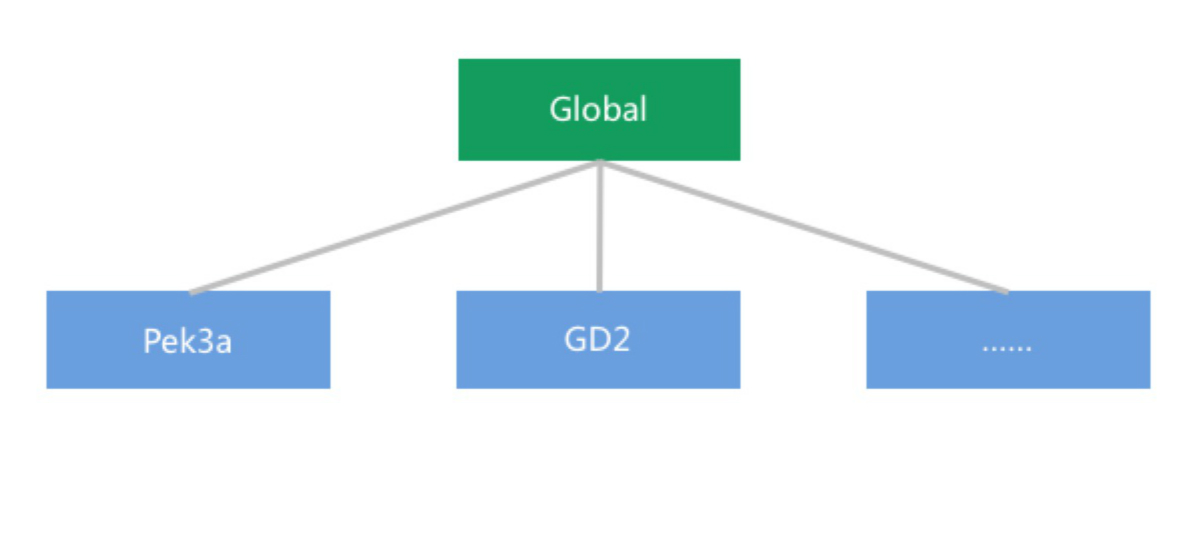
为了进一步拉近计算与存储的距离。同一区域的计算资源访问 QingStor 走内部网络。
5.3 单区域(Zone)架构
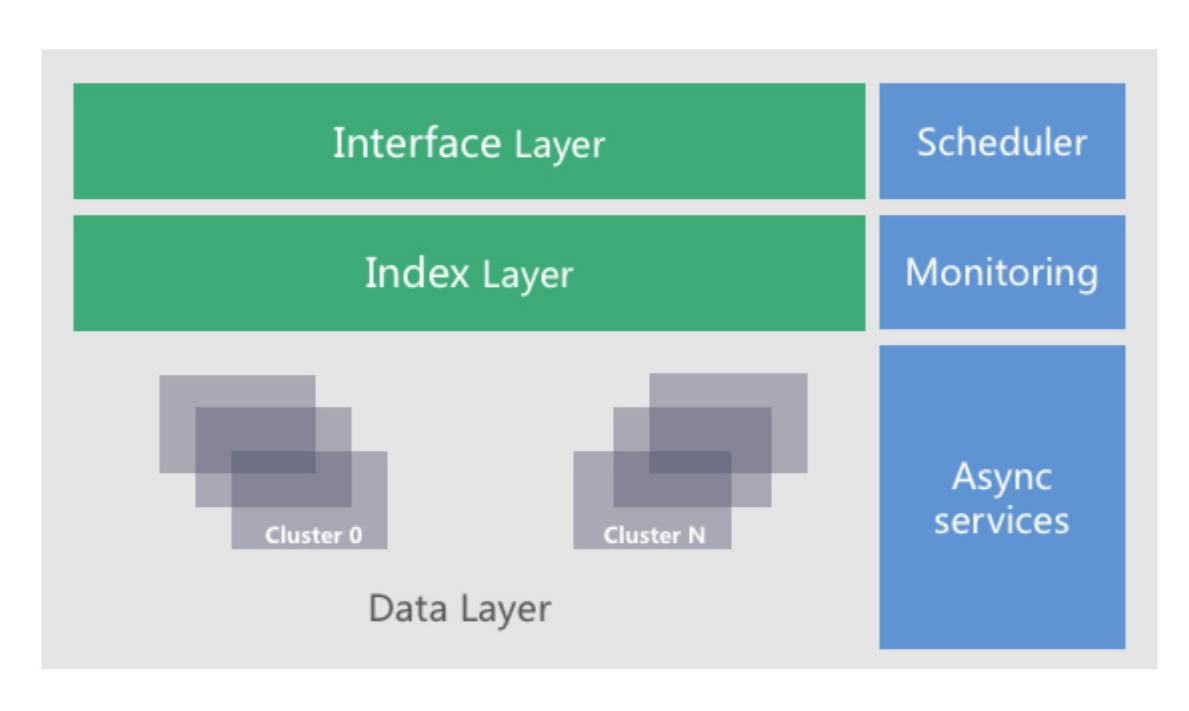
文中已分别就“接入层”,“索引层”,及“数据存储层”进行了探讨。这里进一步阐述一下QingStor架构设计的核心思想:
- 数据安全;
- 各层次均须具备水平扩展能力。
各层次的具体设计如下:
- 接入层: 无状态,意味着接入层可以任意水平扩展。
- 索引层: 多slave,保证索引数据不丢失,且高可靠; 分库,分表; 二级索引; sharding,做到可任意水平扩展。
- 数据存储层: 多副本 (3份),保证数据不丢;单集群可水平扩展; 为避免单集群过大时的通讯风暴,支持多集群调度进一步提高数据存储层扩展性,以达到容量可无限扩展。
“接入层”,“索引层”,及“数据层”构成了QingStor的架构主干。此外,还有“调度器”,”监控服务“,及异步服务如“垃圾回收”,“文件合并”,“碎片整理”等。
5.4 QingStor 特性
- 无限水平扩展:系统可无限水平扩展,且在存储容量水平扩展时,数据存取的性能线性提升。
- 多区域:和 QingCloud IaaS 一样,QingStor 亦为多区域部署的服务。用户可根据自己的业务需求在不同区域创建存储空间(Bucket)。
- 高可靠:无单点故障,支持实时多副本,具备无条件的数据恢复能力。
- 通用数据存储:每个用户可拥有多个存储空间。单个存储空间(Bucket)容量不限,可存对象(Object)数量不限,可存对象(Object)类型不限。普通对象(Object)最大可达 5G ,通过分段上传 API 上传的单个对象(Object)大小最大可达 50T ,每个分段最大 5G 。
- 与计算资源紧密结合:与 QingCloud IaaS 资源可通过内网进行数据传输,保证高效的数据传输与处理,并节省用户的成本。
- 标准用户接口:向用户提供标准、规范且简单的 API 接口和 SDK 工具包,并提供详尽的 API 文档。
- 分段上传:支持对文件进行分段上传,最大支持 10000 段,每段大小最大可达 5G 。以允许用户将大文件在尽可能短的时间内上传。
- 断点续传:下载支持断点续传,以允许用户在网络质量较差的环境中仍能够下载资源。
- 安全认证模式:基于对称加密的请求认证方式;存储空间(Bucket)级别的访问控制,用户可将存* 储空间的读或写权限开放给单个或多个 QingCloud 用户,或所有人;支持通过 SSL 加密数据传输。
- 多维度监控:监控条目包括内网出/入流量、外网出/入流量、容量、内网 API 调用次数、外网 API 调用次数,及容量。各条目监控最小粒度均为 1 小时。
6、如何使用QingStor
除 API 及用户指南文档外,目前我们支持 Python SDK,控制台图形化界面,命令行工具:
- 用户指南:https://docs.qingcloud.com/guide/object_storage.html
- API 文档: https://docs.qingcloud.com/qingstor/api/index.html
- SDK 文档: https://docs.qingcloud.com/qingstor/api/sdk/index.html
- CLI 文档: https://docs.qingcloud.com/qingstor/api/cli/index.html
- 控制台: https://console.qingcloud.com
7、用户案例 (Hash Data Warehouse – HDW)
HDW(Hash Data Warehouse)是由北京酷克数据科技有限公司开发,类似 AWS Redshift 的云端数据仓库服务,产品将于今年 3 月底在青云QingCloud 上线。
HDW 基于 Greenplum Database ,为云计算平台做了大量的系统架构及工程优化。除了具有快速部署,简单易用和零前期投入(按使用量收费)等商业优势外,还有如下技术优势:
- 标准SQL数据库:ANSI SQL 2008标准,OLAP、JDBC/ODB
- 支持ACID,分布式事务
- 分布式数据库:线性扩展,支持上百个物理节点
- 与开源数据库兼容,良性生态系统
- 支持多种语言用户自定义函数(UDF):PLPGSQL、PLPython、PLR、PLJava
- 内置常用机器学习算法
- 兼容常用ETL和BI工具,充分利用企业已有投入
- 软硬一体优化,极高的性价比
- 无缝集成IaaS云平台数据服务,融入云生态系统
下面演示 HDW 如何与 QingStor 集成。在这个演示中,我们将把数据从 QingStor 中导入到数据仓库,并将最终的查询结果回导至 QingStor 。
7.1 创建 Bucket (存储空间)
创建一个Bucket,名为”hdw-hashdata-cn”,并在其下创建两个目录“input”和”output”。

7.2 创建 API 密钥以访问 QingStor

7.3 创建输入文件
在本地创建文件 “persons.txt” 和 “orders.txt”,并将其上传至前面创建的 Bucket “hdw-hashdata-cn” 的 “input”目录里。
“persons.txt”内容:
1,Adams,John,Oxford Street,London
2,Bush,George,Fifth Avenue,New York
3,Carter,Thomas,Changan Street,Beijing
orders.txt 内容
1,77895,3
2,44678,3
3,22456,1
4,24562,1
5,34674,65
7.4 创建数据表
连接 HDW 数据仓库进入 Postgres 数据库,执行如下图所示命令创建相应的数据表(请将里面的 access_key_id 和 secret_access_key 换成你的 API 密钥)。
外部表 e_persons 对应前面上传的 persons.txt 文件,e_orders 对应 orders.txt 文件,e_result 对应 Bucket hdw-hashdata-cn 的 output 目录。
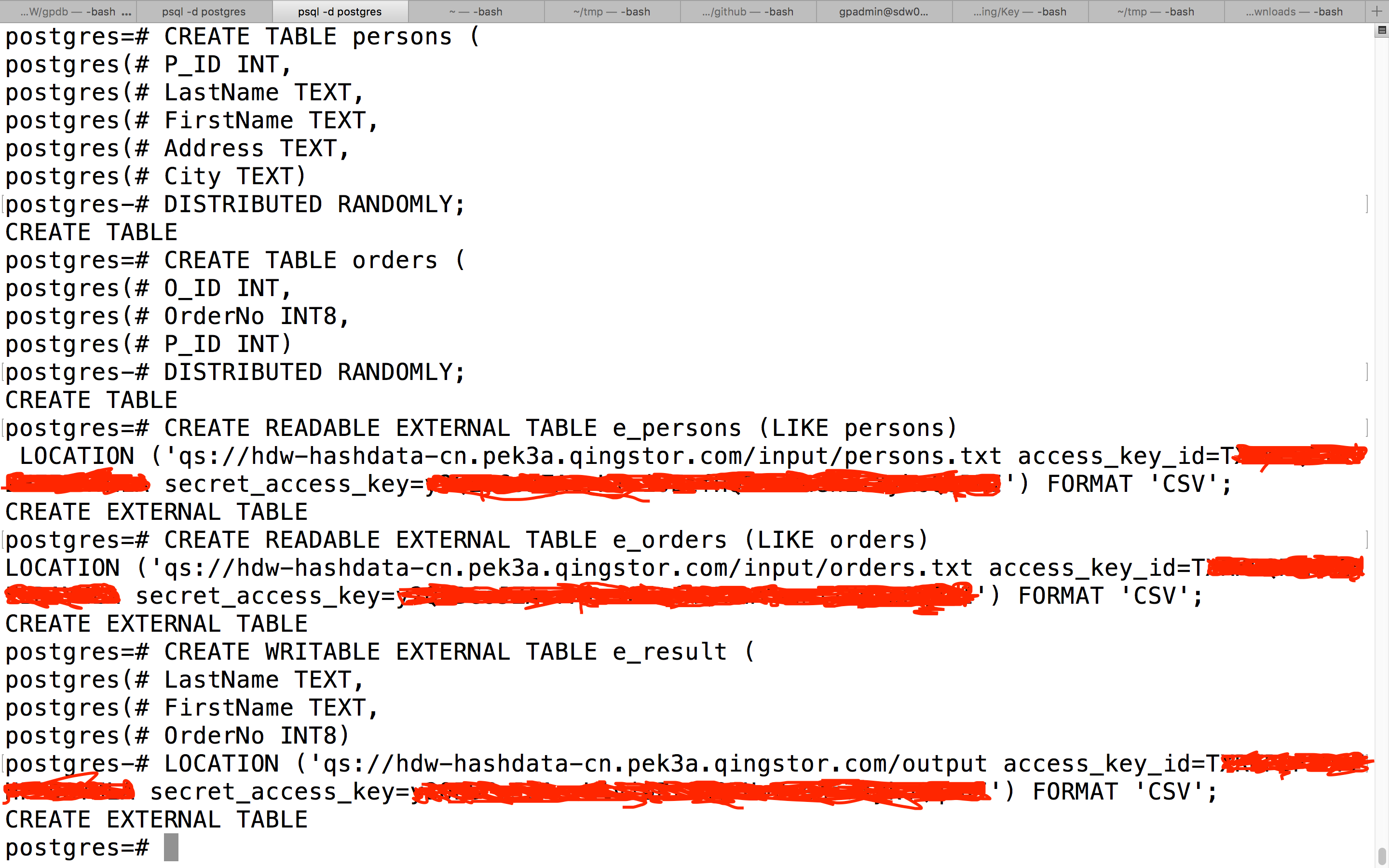
7.5 数据迁移
执行如下命令将数据从外部表(对应青云对象存储的 input 目录)导入到数据仓库中: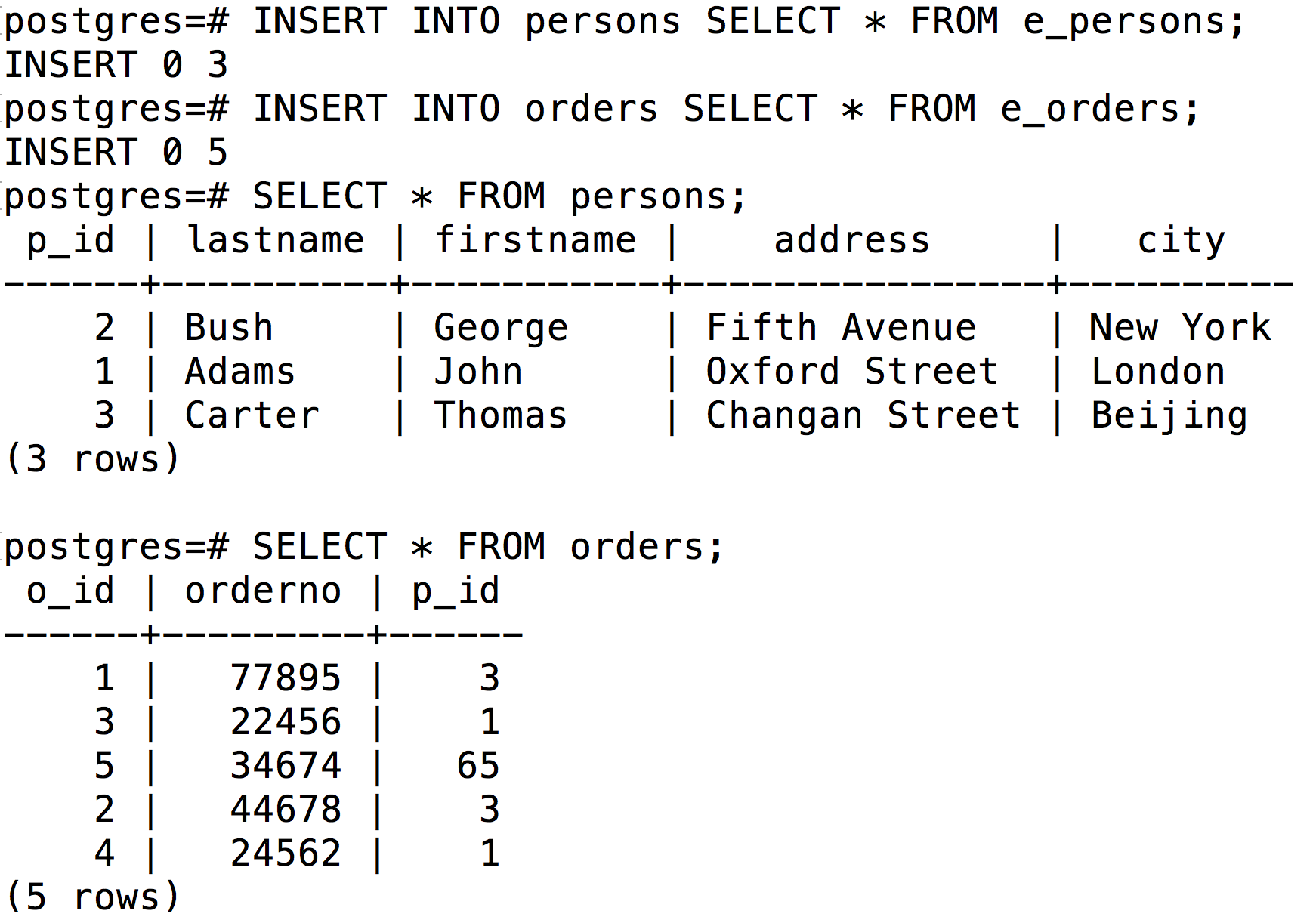
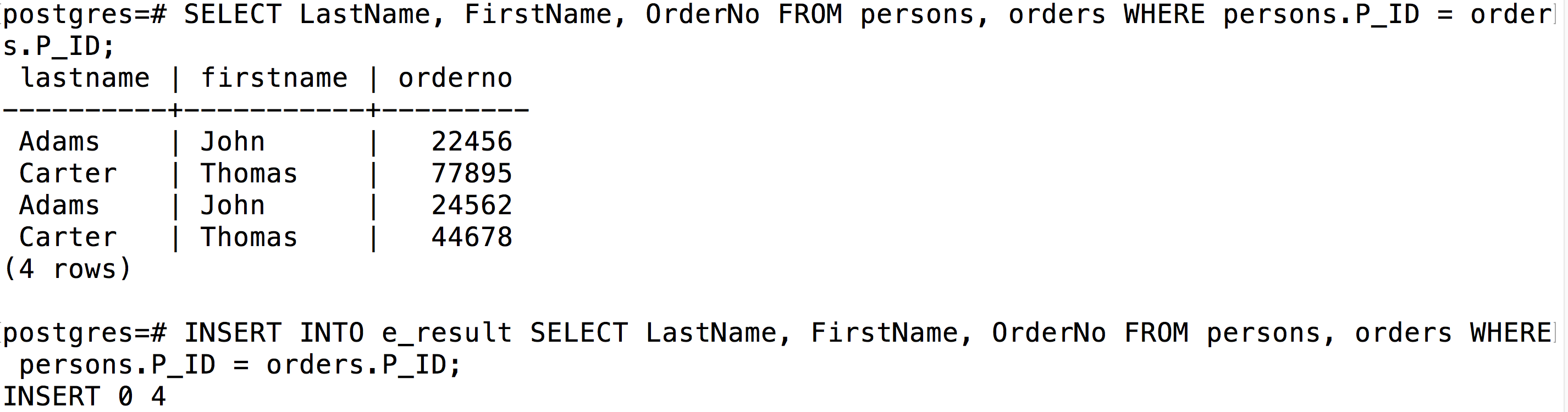
7.6 执行如下命令将查询结果导出到外部表(对应青云对象存储的 output 目录)
此时,可以看到 output 目录下多了两个文件(这是因为演示系统中用了两个 workers ,每个 worker 往外写一个文件对象):gpqsext.0.0 和 gpqsext.1.0 。
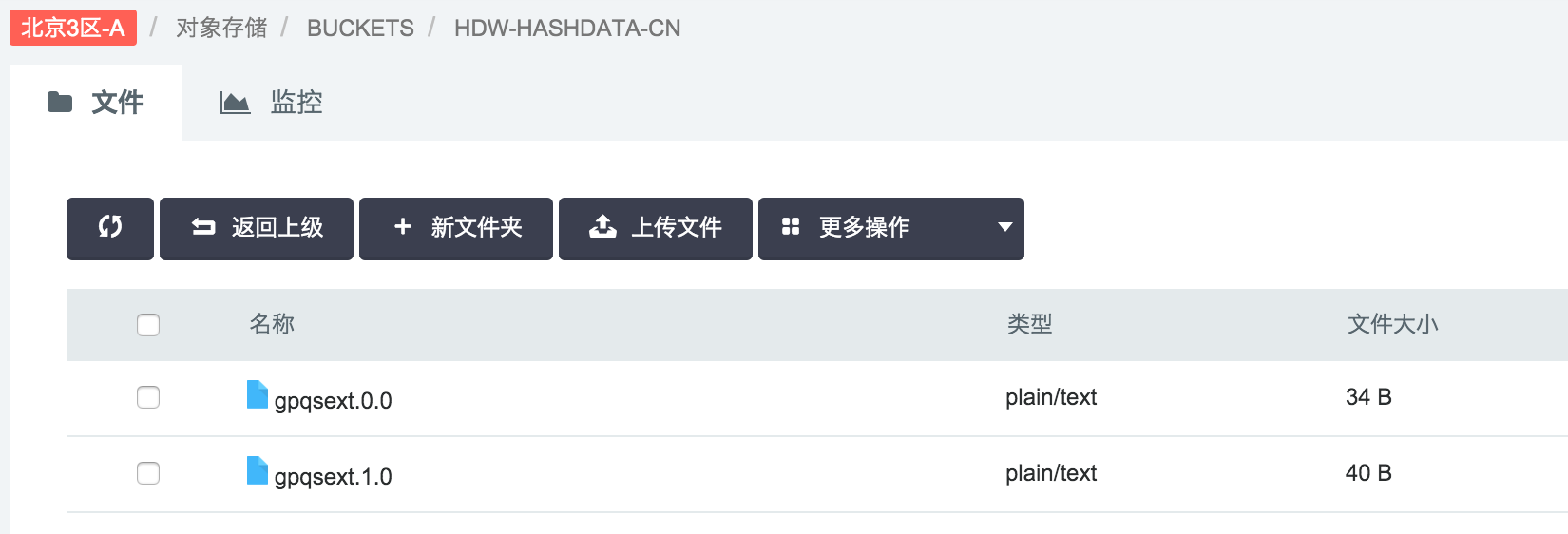
下载 gpqsext.0.0 和 gpqsext.1.0 ,查看内容:

在这个例子中,我们演示了如何将数据从 QingStor 里导入到 HDW 数据仓库中,并将查询结果回导至青云对象存储里。基于这两个基本功能,我们可以构建更复杂的数据仓库管理功能,如在数据仓库空闲的时候,将元数据和用户数据备份到对象存储中,释放计算资源和存储资源,节省成本;当下次需要的时候,利用备份到对象存储中的数据恢复数据仓库,继续正常使用。
8、QingStor 的进一步产品规划
各种 Feature 这里就不多说了,主要说一下两个大个方向。
第一个方向面向性能。纵然我们在系统架构设计时就在各方面考虑了性能,比如多区域部署,同区域计算资源内网访问 QingStor。但为了应对更加复杂的场景,我们在性能方面会同时兼顾内外网。内网方面,我们在做内网加速,外网方面我们在做 CDN 。两者将兼于近期上线。
第二个方向面向数据处理。QingStor 作为海量数据存储池,将会与青云QingCloud 平台上的计算资源紧密整合,尤其是青云QingCloud 大数据平台,如 Hadoop、Spark、 Storm 等。同时我们非常欢迎第三方数据处理服务在青云QingCloud 平台上构建服务,如第 7 章节中的 HDW。
另外,我们也将开发一些特定的数据处理服务,比如图形图像处理,音视频处理等。
我的分享就到此结束,谢谢大家,谢谢北京酷克数据科技有限公司提供的 HDW 案例。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞2作者其他文章
评论 0 · 赞 0
评论 0 · 赞 0
评论 0 · 赞 0
评论 0 · 赞 0
评论 0 · 赞 0
添加新评论1 条评论
2018-12-17 15:55