Db2 pureScale GDPC如何保障数据高可用,数据复本如何设计?
在Db2 pureScale GDPC数据库双活技术方案设计的高可用设计环节中,为了达到数据高可用,对于同一笔数据,存在多少个复本,如何从架构层面来规划和设计这些数据复本?例如对于2地3中心,同城双活的GPFS在双中心建立了单独的failuregroup,这两组之间的数据是完全保持一致的;每个中心还有HADR的本地保护;还有数据库本身的备份;还有存储双活等?
在Db2 pureScale GDPC数据库双活技术方案设计的高可用设计环节中,为了达到数据高可用,对于同一笔数据,存在多少个复本,如何从架构层面来规划和设计这些数据复本?例如对于2地3中心,同城双活的GPFS在双中心建立了单独的failuregroup,这两组之间的数据是完全保持一致的;每个中心还有HADR的本地保护;还有数据库本身的备份;还有存储双活等?

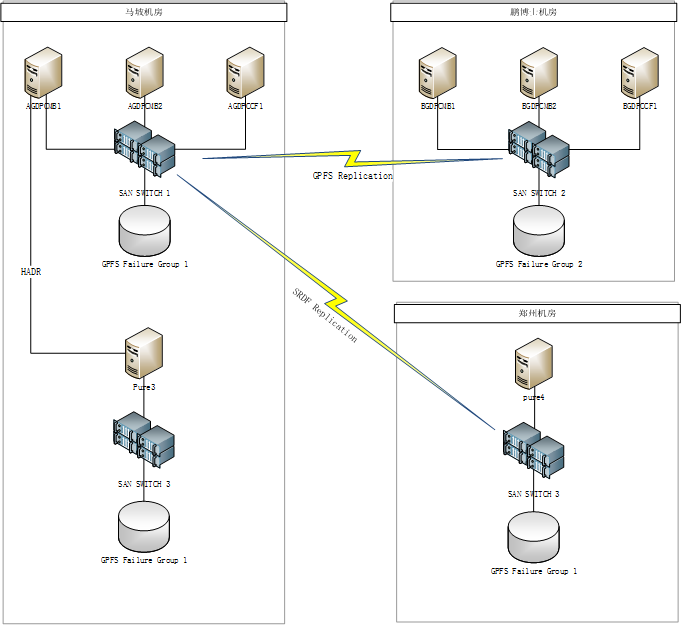 image.png参考我发的这个图。在双活集群,成员CF所在的每个机房的存储被划分为一个副本(单独的failuregroup),这样就有双副本。仲裁站点没画,因为不放数据副本。 本地HADR保护只有一个,存储是单副本,不过是通过HADR复制日志的方式同步数据。异地机房则是通过存储硬件复制的方式从...
image.png参考我发的这个图。在双活集群,成员CF所在的每个机房的存储被划分为一个副本(单独的failuregroup),这样就有双副本。仲裁站点没画,因为不放数据副本。 本地HADR保护只有一个,存储是单副本,不过是通过HADR复制日志的方式同步数据。异地机房则是通过存储硬件复制的方式从...